Yarn介绍 | 组成 | 工作流程
1、理论
Apache YARN(Yet another Resource Negotiator的缩写)是Hadoop集群的资源管理系统,负责为计算程序提供服务器计算资源,相当于一个分布式的操作系统平台,而MapReduce等计算程序则相当于运行于操作系统之上的应用程序。
YARN被引入Hadoop2,最初是为了改善MapReduce的实现,但是因为具有足够的通用性,同样可以支持其他的分布式计算模式,比如Spark,Tez等计算框架。

2、组成部分

ResourceManager:
是在系统中的所有应用程序之间管理资源的最终权威,即管理整个集群上的所有资源分配,内部含有一个Scheduler(资源调度器)
NodeManager:
是每台机器的资源管理器,也就是单个节点的管理者,负责启动和监视容器(container)资源使用情况,并向ResourceManager及其 Scheduler报告使用情况.
container:
即集群上的可使用资源,包含cpu、内存、磁盘、网络等(虚拟机,或者Docker)
AppMaster(项目经理):
实际上是框架的特定的库,每启动一个应用程序,都会启动一个AM,它的任务是与ResourceManager协商资源,并与NodeManager一起执行和监视任务。3、Yarn的工作流程(重点)
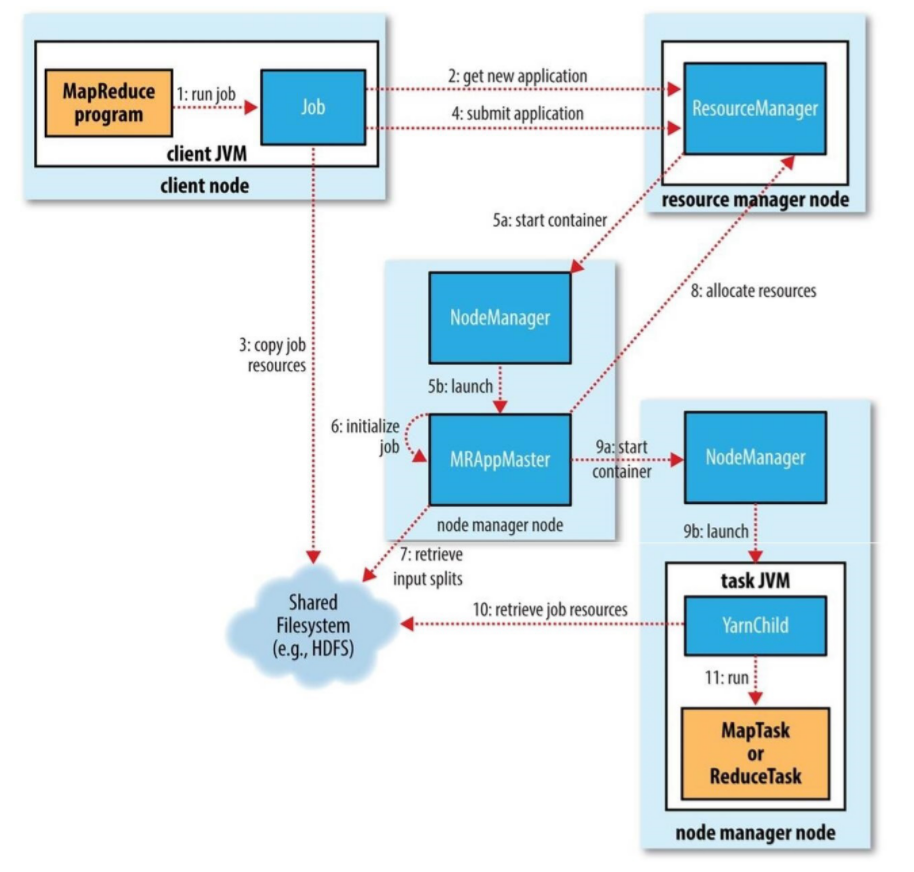
1. 调用waitForCompletion方法每秒轮询作业的进度,内部封装了submit()方法,用于创建JobCommiter实例,并且调用其的submitJobInternal方法。提交成功后,如果有状态改变,就会把进度报告到控制台。错误也会报告到控制台。
2. JobCommiter实例会向ResourceManager申请一个新应用ID,用于MapReduce作业ID。这期间JobCommiter也会进行检查输出路径的情况,以及计算输入分片。
3. 如果成功申请到ID,就会将运行作业所需要的资源(包括作业jar文件,配置文件和计算所得的输入分片元数据文件)上传到一个用ID命名的目录下的HDFS上。此时副本个数默认是10.
4. 准备工作已经做好,再通知ResourceManager调用submitApplication方法提交作业。
5. ResourceManager调用submitApplication方法后,会通知Yarn调度器(Scheduler),调度器分配一个容器,在节点管理器的管理下在容器中启动 application master进程。
6. application master的主类是MRAppMaster,其主要作用是初始化任务,并接受来自任务的进度和完成报告。
7. 然后从HDFS上接受资源,主要是split。然后为每一个split创建MapTask以及参数指定的ReduceTask,任务ID在此时分配
8. 然后Application Master会向资源管理器请求容器,首先为MapTask申请容器,然后再为ReduceTask申请容器。
9. 一旦ResourceManager中的调度器(Scheduler),为Task分配了一个特定节点上的容器,Application Master就会与NodeManager进行通信来启动容器。
10. 运行任务是由YarnChild来执行的,运行任务前,先将资源本地化(jar文件,配置文件,缓存文件)
11. 然后开始运行MapTask或ReduceTask。
12. 当收到最后一个任务已经完成的通知后,application master会把作业状态设置为success。然后Job轮询时,知道成功完成,就会通知客户端,并把统计信息输出到控制台