【EMNLP2024】面向长文本的文视频表征学习与检索模型 VideoCLIP-XL
近日,阿里云人工智能平台PAI与华南理工大学金连文教授团队合作,在自然语言处理顶级会议EMNLP 2024 上发表论文《VideoCLIP-XL: Advancing Long Description Understanding for Video CLIP Models》。该工作提出了一个名为VideoCLIP-XL的视频CLIP模型,旨在提升对视频的长文本描述的理解能力。这一工作构建了一个大规模的长视频描述数据集VILD,并在预训练阶段提出了一种文本相似度引导的主成分匹配方法(TPCM)来优化特征空间的学习。此外,该工作还引入了细节描述排序(DDR)和幻觉描述排序(HDR)两个新任务来进一步提升模型对长描述的理解,也建立了一个新的长视频描述排序基准测评集(LVDR)来更全面地评估模型性能。
背景
CLIP模型(Contrastive Language-Image Pre-training)在视觉-语言预训练领域已经取得了重要进展。然而,CLIP的一个显著局限性是处理长文本描述的能力受限,由于其文本编码器依赖于最大的位置嵌入向量长度(为77)。且已有研究发现其实际有效的词元(token)位置嵌入长度仅约为20。此外,原始CLIP训练过程中对简短的摘要性文本的强调迫使文本/视觉编码器主要关注文本/视觉输入中的主要特征,常常忽视一些较小但潜在关键的细节。在这种情况下,现有的视频CLIP模型采用原始的CLIP训练方法可能难以准确捕捉复杂关系和属性。为了解决这些限制,加强模型理解长文本描述的能力至关重要。
视频-长描述数据集VILD
训练 CLIP 模型通常需要大量的视觉-文本数据对。在开放领域中,具备长描述的文本-视频数据集仍然非常稀缺。因此,我们首先设计了一个自动数据收集系统,如下图所示。我们的方法利用多个数据来源,主要包括视频叙述数据、视频指令微调数据、原始视频、可用视频及长描述配对数据。
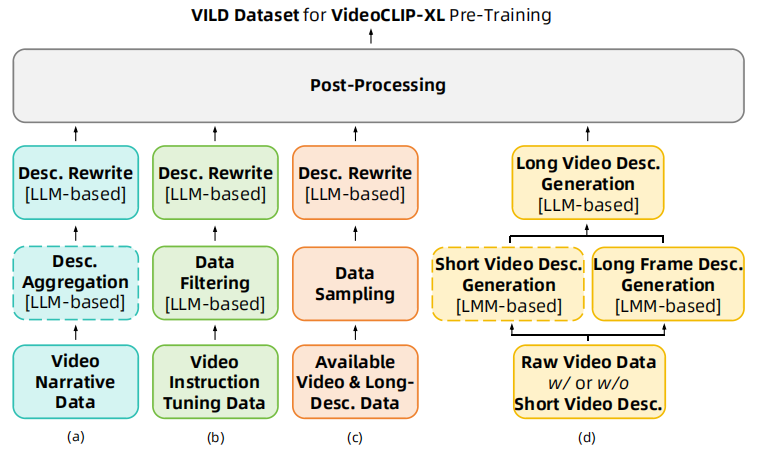
(a) 视频叙述数据。视频叙述数据通常包含由人工标注者生成的描述,能够描述整个场景、主要活动以及涉及多个角色和物体的事件。我们采用 VidLN数据集,该数据集包含每个视频中主要人物/动物/物体及背景的个体级描述。为了使数据符合我们的目的,我们采用大语言模型(LLM)通过提示词工程将个体级叙述整合为整体描述(即描述聚合步骤)。最后,考虑到训练的鲁棒性,我们进一步利用LLM重写整体级的描述(即描述重写步骤)。该过程涉及生成语义相同但表述不同的多个文本描述,同时保持主要内容和细节属性不变。
(b) 视频指令微调数据。随着多模态大模型(LMM)的出现,大量视频指令微调数据集也已公开可用。例如,VideoInstruct100K包含与视频描述、基于描述的问答以及创意/生成问答相关的数据对。VideoChat包含详细的视频描述和对话,通过采用视频指令中的时间和因果内容来增强数据的多样性。这些数据集最初是为了训练一个通用的视频理解大模型,而不是只为了视频描述任务。因此,我们的方法利用LLM进行数据过滤,以排除与视频描述无关的样本。我们采用提示词工程,并提供一些示例来帮助LLM取得更好的效果。最后,我们还会进行描述重写步骤。
(c) 可用视频及长描述配对数据。如前所述,现有的视频-长文本描述配对数据往往受限于数量或视频的领域/主题。在这方面,我们对这些数据集进行数据抽样操作。具体来说,MiraData中的 5.78 万个均来自游戏及城市/风景探索场景的视频片段全部被包含。我们也从Open-Sora-Dataset随机采样了5 万条描述自然风景的长描述。
(d) 原始视频数据。为了进一步扩展训练数据的数量,我们利用LMM和LLM生成原始视频的长描述(部分原始视频数据提供了相应的短标题)。为了数据生成的效率,我们从 Panda-70M中随机抽取了200万个视频片段,这些视频片段的高质量短标题是由多个教师模型和精调的标题选择模型生成的。然后,我们从每个视频片段以相等的间隔抽取3帧作为关键帧,并使用LMM对它们进行长描述的标注。我们没有对每一帧都进行操作,因为这将极其费时费力。接下来,在给定视频的短描述和关键帧的长描述后,我们使用LLM将它们整合为整个视频的长描述。短视频描述的辅助可以减轻帧描述中的幻觉现象。
最后,我们也采用了后处理步骤,来过滤掉有害的样例。接下来,我们利用ViCLIP和Long-CLIP滤除视频-文本相似度平均值小于 0.20 的低质量的样例。最终,我们收集了超过 200 万对视频及长描述数据作为我们用于模型预训练的 VILD 数据集。一些统计信息的对比如下所示:
文本相似度引导的主成分匹配
CLIP模型的预训练使用视觉-文本数据对 作为输入,
可以是图像或视频,其不对具体的单模态编码器的架构做任何假设。给定一个视觉编码器
和一个文本编码器
,该方法首先提取单模态的特征,分别为
和
。然后,CLIP通常采用对比学习方法和 InfoNCE损失来学习视觉与文本之间的对应关系。具体而言,可以将其表述为:
其中 N 是训练批次的大小,且
反之同理。为了扩展 CLIP 模型的长描述理解能力,Long-CLIP工作提出了使用主成分匹配来针对图像领域改进 CLIP模型。给定短描述、长描述和视觉输入,其损失函数被表述为:
其中 是损失函数比例,
。这里, PCE 是主成分提取的简称,包含三个部分:成分分解函数 F(将特征分解为不同属性的向量及其重要性)、成分过滤函数 E(过滤掉不够重要的属性)、以及成分重构函数 F−1(重构特征)。在 E 的实现中,Long-CLIP 选择了最重要的 32 个属性作为保留的属性。然而,当将其扩展到视频预训练时,我们发现由于视频通常包含比图像更丰富的内容和更多的细节,这种固定策略无法在学习过程中动态的适应视频 CLIP 模型高维特征空间的变化。因此,我们使用
和
之间的文本特征余弦相似度作为指导 PCE 过程的信号,如下图所示:
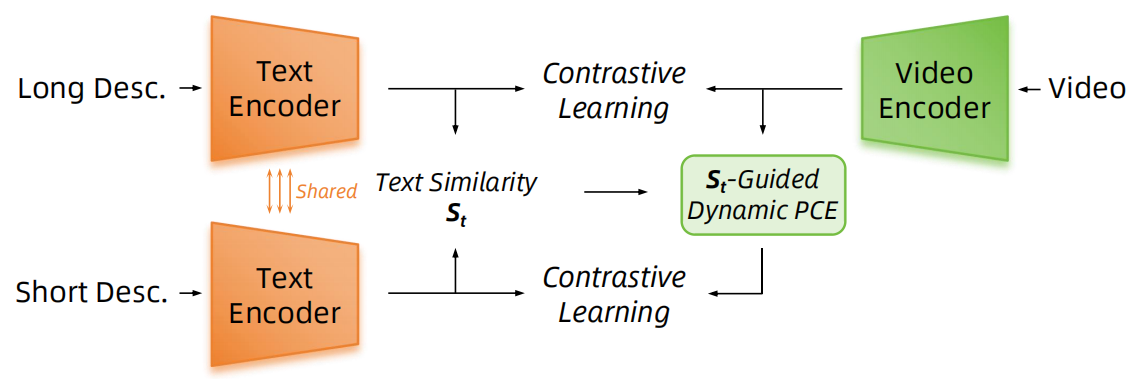
因此,我们将 重新写为:
其中 表示我们按照重要性降序保留属性的操作,直到
和
之间的相似度达到
和
之间的相似度。
描述排序任务
我们认为,能够理解长描述的视频 CLIP 模型应当体现两个特征:给定一个视频及其相关描述,模型应该对(1)具有更丰富和更精确的细节描述以及(2)在相同细节水平下更准确即幻觉更少的描述赋予更高的分数。为此,我们提出两个新的预训练任务:细节描述排序(DDR)和幻觉描述排序(HDR)。我们的准备工作包括使用句法分析工具如 NLTK和 spaCy对原始的长描述进行词性标注和句法结构解析。
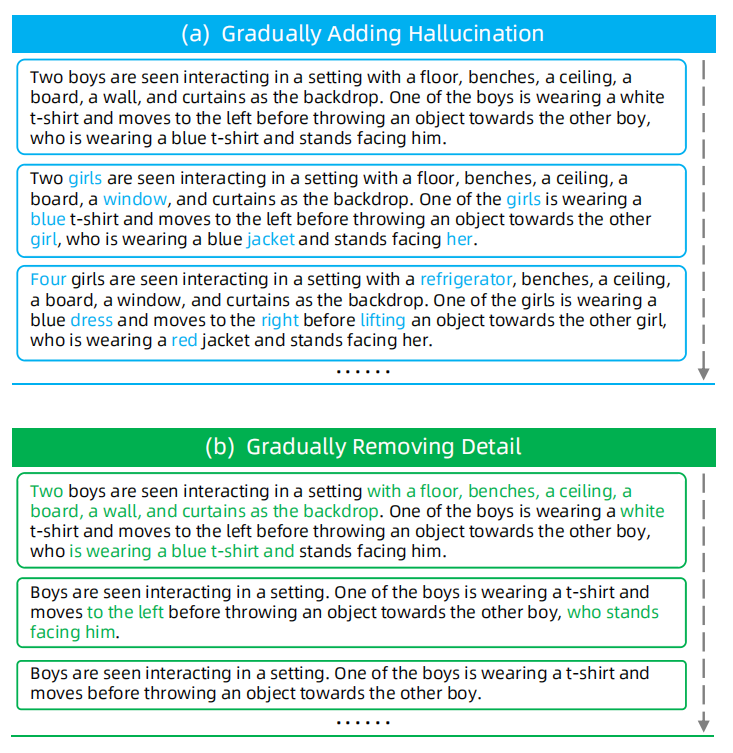
接着,我们为每个视频合成多个长描述,以便进行DDR和HDR训练。如上图(a)所示,对于HDR任务,在每一步中,我们有选择性地将特定单词(名词、数字、颜色或与方向相关的术语、动词)替换为同一句法类别下的语义相异的对应词(例如,将“男孩”替换为“女孩”,将“白色”替换为“蓝色”,将“扔”替换为“举”),并进行 m−1 次这样的替换。该方法生成一系列幻觉越来越严重的描述,记为 。
类似地,如上图(b)所示,对于DDR任务,我们在每一步随机删除当前长描述中的子句、形容词、数字或句法子树。这一过程递归生成 m−1 个细节逐渐减少的描述,表示为。对于
或
,给定相同的对应视频,我们希望模型能够对描述序列中较早出现的描述生成更高的相似度分数。例如,对于 DDR 任务,我们将损失函数公式化如下:
其中 是相似度差异的阈值,且
同样,对于 HDR任务,我们有以下损失函数:
预训练过程中总损失函数为:
其中和
是损失函数比例的超参数。
视频长描述排序任务及测评集 LVDR
幻觉在当代大语言模型(LLM)和多模态大模型(LMM)领域都是值得关注的问题。对于一个视频,具备理解长文本能力的视频 CLIP 模型理所应当地应该具备辨别长描述中正确与错误文本的能力。为了更好地评估这种能力,我们提出了视频长描述排序(LVDR)测评集。我们首先从 Shot2Story中随机抽取了 2000 对视频和对应的长描述。接着,我们执行一个类似于HDR任务的数据合成过程,迭代 p-1 次,并在每次迭代中更改 q 个单词,最终产生了 p 个长描述,其幻觉程度逐渐增加。我们将这样的子集表示为 p × q,并构建了五个子集:{4 × 1, 4 × 2, 4 × 3, 4 × 4, 4 × 5}。下图中提供了代表性的示例:

视频CLIP模型需要能够根据视频内容正确地按相似度降序排列这些长描述。
实验结果
我们的方法在常见的文本-视频检索测评集上的zero-shot结果如下表所示:
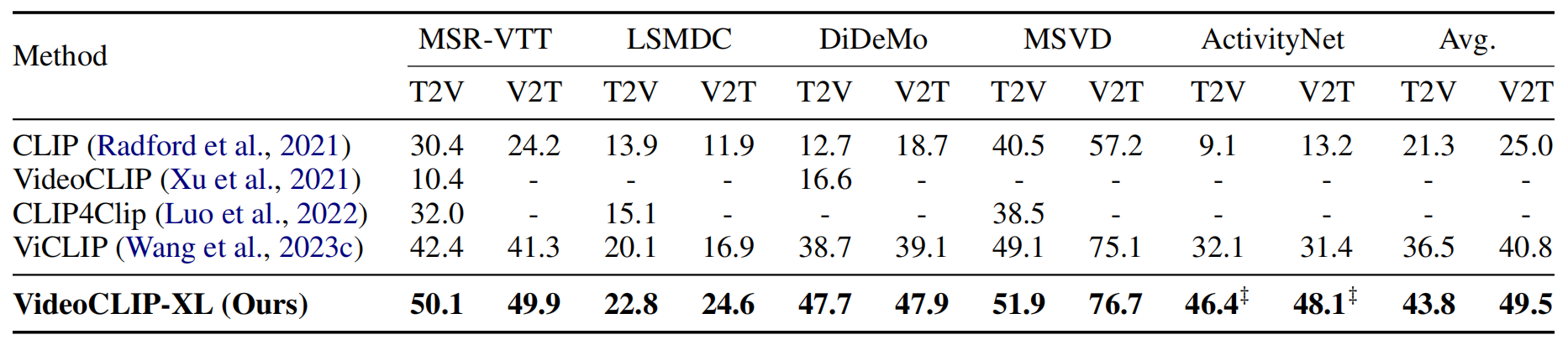
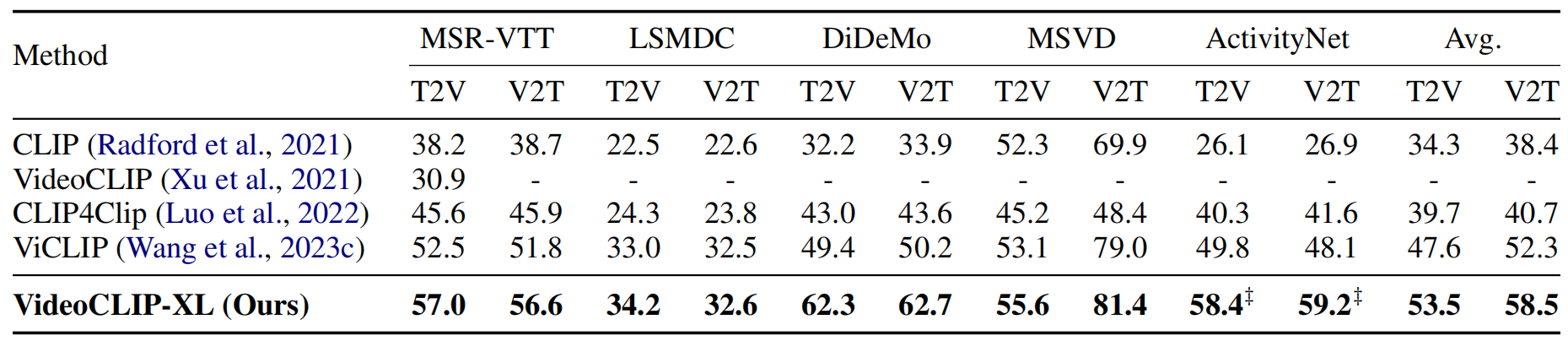
而在常见的文本-视频检索测评集上的fine-tuned结果如下表所示:
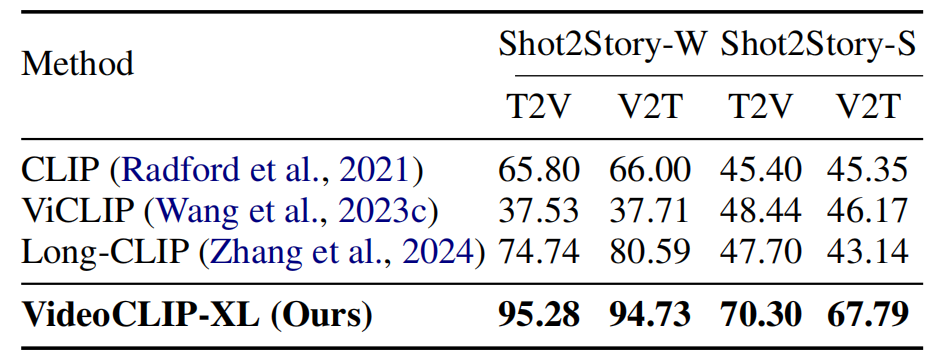
可以看出,我们的方法相比同类的模型而言具有显著的优越性。在长描述的文本-视频检索测评集Shot2Story上的zero-shot结果如下:
在我们提出的LVDR测评集上的效果表现如下:

可以发现,我们的模型在各个任务和数据集上都能取得较好的表现。
一些文到视频检索任务的例子如下所示:

参考文献
-
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. 2021. Learning transferable visual models from natural language supervision. In ICML, volume 139, pages 8748– 8763.
-
Yi Wang, Yinan He, Yizhuo Li, Kunchang Li, Jiashuo Yu, Xin Ma, Xinhao Li, Guo Chen, Xinyuan Chen, Yaohui Wang, et al. InternVid: A large-scale video-text dataset for multimodal understanding and generation. arXiv preprint arXiv:2307.06942.
-
Beichen Zhang, Pan Zhang, Xiaoyi Dong, Yuhang Zang, and Jiaqi Wang. 2024. Long-CLIP: Unlocking the long-text capability of CLIP. arXiv preprint arXiv:2403.15378.
-
Mingfei Han, Linjie Yang, Xiaojun Chang, and Heng Wang. 2023. Shot2Story20K: A new benchmark for comprehensive understanding of multi-shot videos. arXiv preprint arXiv:2311.17043.
论文信息
论文名字:VideoCLIP-XL: Advancing Long Description Understanding for Video CLIP Models
论文作者:汪嘉鹏、汪诚愚、黄坤哲、黄俊、金连文
论文pdf链接:https://arxiv.org/abs/2410.00741
阿里云人工智能平台PAI长期招聘研究实习生。团队专注于深度学习算法研究与应用,重点聚焦大语言模型和多模态AIGC大模型的应用算法研究和应用。简历投递和咨询:chengyu.wcy@alibaba-inc.com。