使用概率表示和原型学习的有效半监督医学图像分割|文献速递-基于深度学习的病灶分割与数据超分辨率
Title
题目
Effective Semi-Supervised Medical ImageSegmentation with Probabilistic Representations and Prototype Learning
使用概率表示和原型学习的有效半监督医学图像分割
01
文献速递介绍
尽管基于深度学习的方法在有监督的医学图像分割任务中取得了巨大成功,但在半监督设置中,由于三大常见挑战,其性能显著下降:(1)标签稀缺。由于高昂的时间成本和对专业知识的高度需求,医疗领域很难获得高质量的标注。(2)类别不平衡。在多目标分割任务中(如心脏亚结构分割),不同解剖结构的体积大小差异较大,通常会出现严重的类别不平衡问题。(3)数据高度不确定性。由于医学图像的内在特性,包括器官结构与周围组织之间的低对比度导致的模糊边界,以及MRI或CT成像中的伪影引起的固有噪声,医学数据本身就表现出高度的不确定性。这种不确定性在半监督的情况下,标注数据有限,给准确分割带来了显著的挑战。
为应对这些挑战,最近的研究致力于开发更为鲁棒的框架。例如,方法和被提出用于同时解决标签稀缺和类别不平衡问题。具体而言,这两种方法基于两种流行的半监督框架,即mean-teacher和伪标签方法,充分利用大量未标注的数据来弥补有限的标注数据。此外,为缓解类别不平衡问题,它们利用原型学习[7]在解决类别不平衡问题中的优势,引入了一个额外的分类器,即基于原型的分类器,与传统的线性分类器并行,以增强模型性能。基于原型的分类器通过比较像素表示与一组对应目标类别的等量表达的原型之间的距离来进行预测,大大缓解了每个样本中存在的类别偏差。
尽管先前的方法有效地解决了标签稀缺和类别不平衡问题,并在半监督医学图像分割中获得了显著的性能提升,但它们仍然忽视了医学图像中存在的数据高度不确定性问题。结果是,我们观察到方法[3]在模糊的器官边界上生成了次优结果(见图1)。这种限制了算法在实际医疗场景中的适用性,因为器官轮廓为疾病诊断提供了重要依据。为更好地理解该问题的根本原因,我们进行了深入分析。正如图2(a)所示,方法将每个像素xi映射为嵌入空间中的确定性嵌入p(f(xi)),即嵌入空间中的一个单一的点。然而,对于任何嵌入空间Z,考虑到输入数据中可能存在的模糊性或噪声,精确还原z是不现实的,数据的嵌入点将不可避免地偏离其本质z 。一旦这种偏移没有被限制,导致类内距离超过类间距离,模型将倾向于产生错误结果,因为它高度依赖于表示距离进行分类。我们的分析表明,确定性表示无法捕捉由分布外输入(如噪声)或标签模糊性(如模糊边界)引起的数据不确定性,从而限制了模型在高不确定性数据上的认知能力。受到这些观察的启发,我们旨在探索一种更有效的范式来处理这一问题,即在数据层面使用概率建模来显式估计数据不确定性。
Aastract
摘要
Label scarcity, class imbalance and data uncertainty are three primary challenges that are commonlyencountered in the semi-supervised medical image segmentation. In this work, we focus on the data uncertaintyissue that is overlooked by previous literature. To addressthis issue, we propose a probabilistic prototype-based classifier that introduces uncertainty estimation into the entirepixel classification process, including probabilistic representation formulation, probabilistic pixel-prototype proximity matching, and distribution prototype update, leveraging principles from probability theory. By explicitly modeling data uncertainty at the pixel level, model robustness of our proposed framework to tricky pixels, such asambiguous boundaries and noises, is greatly enhancedwhen compared to its deterministic counterpart and otheruncertainty-aware strategy. Empirical evaluations on threepublicly available datasets that exhibit severe boundaryambiguity show the superiority of our method over severalcompetitors. Moreover, our method also demonstrates astronger model robustness to simulated noisy data.
标签稀缺、类别不平衡和数据不确定性是半监督医学图像分割中常见的三大挑战。在这项工作中,我们专注于以往文献中被忽视的数据不确定性问题。为了解决这一问题,我们提出了一种基于概率原型的分类器,将不确定性估计引入到整个像素分类过程中,包括概率表示的构建、概率像素与原型的距离匹配以及分布原型的更新,借鉴了概率论的原理。通过在像素级明确建模数据不确定性,与确定性模型及其他不确定性处理策略相比,我们提出的框架在处理模糊边界和噪声等难处理像素时的鲁棒性得到了显著提升。在三个具有严重边界模糊的公共数据集上进行的实证评估显示了我们方法的优越性。此外,我们的方法在应对模拟噪声数据时也展现了更强的模型鲁棒性。
Method
方法
Fig. 3 illustrates the framework of the proposed method.Building on top of the mean-teacher architecture [5] andpseudo-labeling method [10], the framework learns throughthe student branch only, which is supervised by the groundtruths for the labeled data and pseudo labels generated bythe teacher model for the unlabeled data. The weights ofthe teacher model is the exponential moving average (EMA)of the student model weights. Following [2], we adopt theweak-strong augmentation paradigm by feeding the teachermodel with weakly-augmented images (i.e., random cropping,rotation and flipping of the input image) and the studentmodel with strongly-augmented images (i.e., CutMix [26]),respectively. During the training, images are firstly fed into anencoder-decoder network, i.e., f, to extract features. Then, theextracted features are simultaneously passed into two classifiers, i.e., a linear classifier (LC) and a probabilistic prototypebased classifier (PPC). The linear classifier, denoted as g, isa convolutional layer parameterized by W = {w1, · · · , wC },where C is the number of the object classes. The linear classifier primarily focuses on segmenting distinct target regions.While the probabilistic prototype-based classifier, on the otherhand, is delicately designed to deal with tricky pixels with highuncertainty. Different from the deterministic prototype-basedclassifier [2], [3], the probabilistic prototype-based classifiercontains the following three specific modules: a) Probabilisticrepresentation formulation.* PPC models pixel representationas a multivariate Gaussian distribution instead of a pointembedding. Likewise, prototypes in PPC are also estimated asdistributions by using Bayesian Estimation taking probabilisticpixel-wise representations as observations. b) Probabilistic**pixel-prototype matching. We exploit mutual likelihood score(MLS) [9] to measure the proximity between probabilisticpixel representations and distribution prototypes, by considering not only representation distance but also representationuncertainty. c) Distribution prototype update. We propose theBayesian Estimation-based update strategy tailored for distribution prototype update. In addition, an effective samplingrule and an empirical training trick called Lazy Update areexploited to facilitate the update process.
图3展示了所提出方法的框架。基于mean-teacher架构和伪标签方法,该框架仅通过学生分支进行学习,已标注数据由真实标签监督,而未标注数据则由教师模型生成的伪标签监督。教师模型的权重是学生模型权重的指数移动平均(EMA)。参考[2],我们采用了弱-强增强范式,即将弱增强图像(如随机裁剪、旋转和翻转)输入教师模型,将强增强图像(如CutMix[26])输入学生模型。在训练过程中,图像首先被输入编码-解码网络,即f,以提取特征。然后,提取的特征同时传递到两个分类器,即线性分类器(LC)和概率原型分类器(PPC)。线性分类器,记为g,是一个由W = {w1, · · · , wC }参数化的卷积层,其中*C是目标类别的数量。线性分类器主要聚焦于分割明确的目标区域。
而概率原型分类器则精心设计用于处理具有高不确定性的棘手像素。与确定性原型分类器不同,概率原型分类器包含以下三个特定模块:a) 概率表示构建。PPC将像素表示建模为多元高斯分布,而非点嵌入。同样,PPC中的原型也通过贝叶斯估计,利用概率像素表示作为观测值来估计分布。b) 概率像素-原型匹配。我们利用互似然得分(MLS)[9]来衡量概率像素表示和分布原型之间的接近度,考虑了表示距离和表示不确定性。c) 分布原型更新。我们提出了一种基于贝叶斯估计的更新策略,专用于分布原型更新。此外,为了促进更新过程,我们还引入了一种有效的采样规则和一种称为Lazy Update的经验训练技巧。
Conclusion
结论
In this work, to further address the data uncertainty issue(e.g., ambiguous boundary, inherent noise) ignored by previous methods [2], [3] that mainly focus on dealing withthe label scarcity and class imbalance issue in the semisupervised medical image segmentation, we propose the probabilistic prototype-based classifier that incorporates uncertainty estimation into the entire pixel classification process,including probabilistic representation formulation, probabilistic pixel-prototype proximity matching, and distribution prototype updating. Compared to its deterministic counterpart andother uncertainty-aware strategy, the proposed probabilisticprototype-based classifier demonstrates stronger robustness tohigh uncertainty data. As a result, the proposed method setsa new record on the semi-supervised segmentation on threepublicly available datasets which both exhibit severe dataambiguity.
在本研究中,为了进一步解决以往方法[2], [3]主要聚焦于半监督医学图像分割中的标签稀缺和类别不平衡问题而忽略的数据不确定性问题(如模糊边界、固有噪声),我们提出了基于概率原型的分类器,将不确定性估计引入整个像素分类过程,包括概率表示构建、概率像素-原型接近度匹配和分布原型更新。与其确定性模型和其他不确定性感知策略相比,所提出的基于概率原型的分类器对高不确定性数据表现出更强的鲁棒性。最终,该方法在具有严重数据模糊的三个公开数据集上的半监督分割任务中创下了新纪录。
Figure
图

Fig. 1: Suboptimal results on ambiguous organ boundariesproduced by method . Red and green contours representthe ground truths and predicted results respectively
图1:方法在模糊器官边界上产生的次优结果。红色和绿色轮廓分别表示真实值和预测结果。
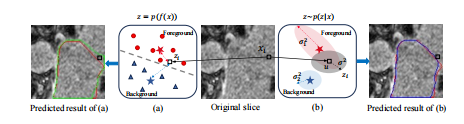
Fig. 2: Motivation of our method. (a) Deterministic representations (red circle and blue triangle) and point prototypes (blueand red star). (b) Probabilistic representations (grey ellipse)and distribution prototypes (blue and red ellipse). Red, greenand blue contours indicate the ground truth, predicted resultsfrom (a) and (b), respectively. Pixels within red contour belongto foreground class, otherwise belong to background class.
图2:我们方法的动机。(a)确定性表示(红色圆圈和蓝色三角形)和点原型(蓝色和红色星形)。(b)概率表示(灰色椭圆)和分布原型(蓝色和红色椭圆)。红色、绿色和蓝色轮廓分别表示真实值、(a)中的预测结果和(b)中的预测结果。红色轮廓内的像素属于前景类,其他像素属于背景类。
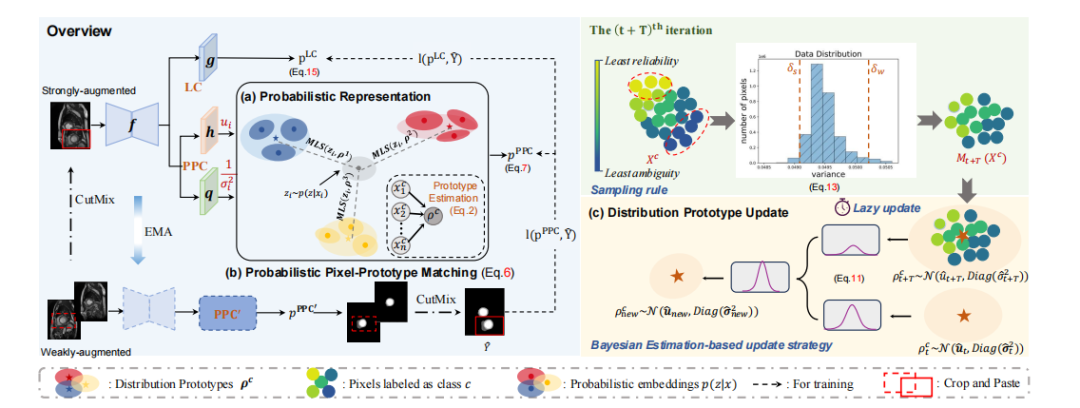
Fig. 3: Overview of the proposed method. It is built upon the mean-teacher framework with pseudo labeling method, whichcontains two classifier heads, i.e., linear classifier (LC) and probabilistic prototype-based classifier (PPC), for simultaneoussupervision. LC primarily focuses on segmenting distinct target regions, while PPC is designed to deal with pixels with highuncertainty. PPC consists of three key modules: (a) Probabilistic Representation Formulation. PPC estimates both pixel andprototype as Gaussian distributions. (b) Probabilistic Pixel-Prototype Matching. Mutual likelihood score (MLS) is utilizedto measure the proximity between probabilistic pixel representations and distribution prototypes. (c) Distribution PrototypeUpdate. Distribution prototypes are updated by using Bayesian Estimation-based strategy, a sampling rule and an empiricaltrick called lazy update are exploited to facilitate the update.
图3:所提方法的概述。该方法基于mean-teacher框架,并结合伪标签方法,包含两个分类器头,即线性分类器(LC)和概率原型分类器(PPC),用于同时监督。LC主要聚焦于分割明确的目标区域,而PPC则设计用于处理具有高不确定性的像素。PPC由三个关键模块组成:(a)概率表示构建。PPC将像素和原型估计为高斯分布。(b)概率像素-原型匹配。利用互似然得分(MLS)来衡量概率像素表示与分布原型之间的接近度。(c)分布原型更新。分布原型通过基于贝叶斯估计的策略进行更新,并引入了采样规则和称为lazy update的经验技巧来促进更新过程。

Fig. 4: Illustration of the proposed sampling rule for thebackground class sampling (region beyond the red contour).Here, we simply use pct.(δ) to represent δ th percentile ofthe whole candidate, and set δ**s, δ**w as 20, 80. (a) Theoriginal slice to be sampled. (b) Pixels with little ambiguity(pink). Nearly all the sampled pixels reflect only a singlepattern of background class (i.e., black color) yet ignore otherexisting patterns. (c) Pixels with high ambiguity (blue). Pixelrepresentations are indistinguishable between background andforeground class. (d) Pixels with adequate reliability andreasonable ambiguity (purple, adopted in our method). Thesampled pixels are reliable enough to represent backgroundclass and cover different patterns of a class, which is the mosteffective to improve the representative capability of prototypes.
图4:所提出的背景类采样规则示意图(红色轮廓以外的区域)。这里,我们用pct(δ)表示所有候选像素中第δ百分位,并将δs和δw设置为20和80。(a)待采样的原始切片。(b)低模糊度像素(粉色)。几乎所有采样像素仅反映了背景类的一种模式(即黑色),忽略了其他存在的模式。(c)高模糊度像素(蓝色)。像素表示在背景类和前景类之间难以区分。(d)具备足够可靠性和合理模糊度的像素(紫色,为本方法所采用)。采样的像素足够可靠以代表背景类,并覆盖了类的不同模式,这对于提高原型的代表性能力最为有效。
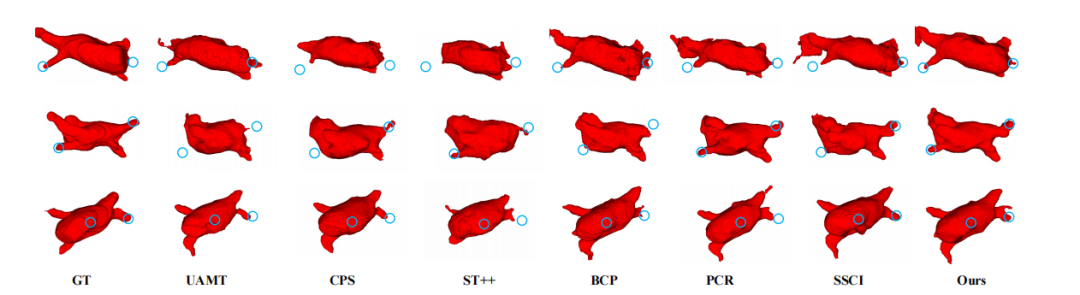
Fig. 5: Segmentation results of LA scans produced by several comparison methods and our proposed method when trainedwith 8 labeled scans. As observed, the outputs of our proposed method have a closer anatomical shape to the ground truths.
图5:在使用8个标注扫描训练时,不同比较方法和我们提出的方法在LA扫描上的分割结果。可以观察到,我们提出的方法输出的结果在解剖形状上更接近于真实值。
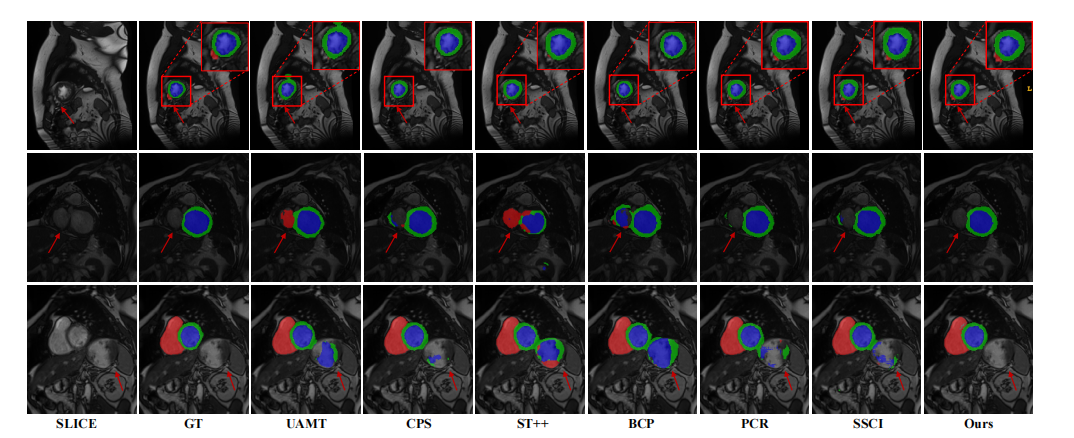
Fig. 6: Segmentation results of ACDC slices produced by several comparison methods and our proposed method when trainedwith 7 labeled scans. As observed, our proposed method is able to segment the organ with small size and fuzzy boundary(row1), and can well distinguish irrelevant tissues that have similar intensities to target organs.
图6:在使用7个标注扫描训练时,不同比较方法和我们提出的方法在ACDC切片上的分割结果。可以观察到,我们的方法能够分割小尺寸且边界模糊的器官(第1行),并且能够很好地区分与目标器官具有相似强度的无关组织。
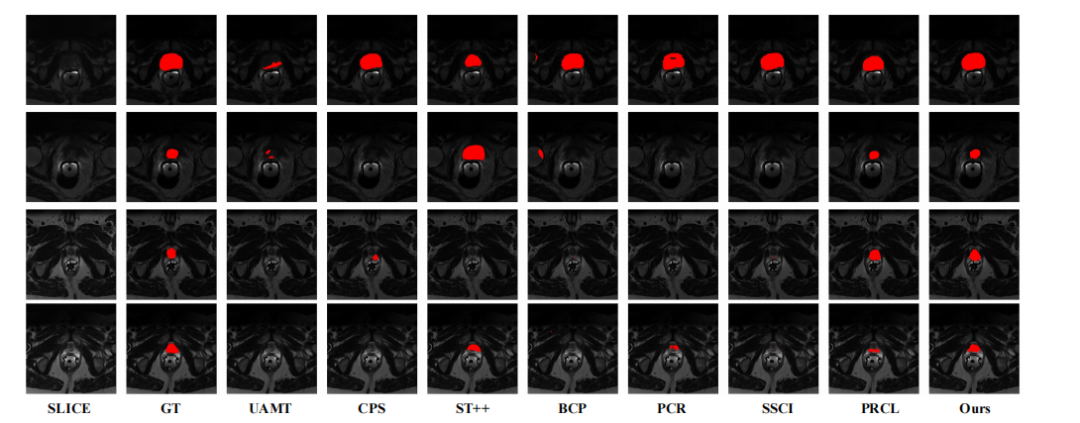
Fig. 7: Segmentation results of slices extracted from PROMISE12 scans. As observed, our method can better deal with theprostate segmentation task, especially in some challenging cases such as large organ size variation, ambiguous boundaries andorgan intensity variation.
图7:从PROMISE12扫描中提取的切片分割结果。可以观察到,我们的方法在前列腺分割任务中表现更好,尤其在一些具有挑战性的情况下,如器官大小的显著变化、模糊边界和器官强度变化等。
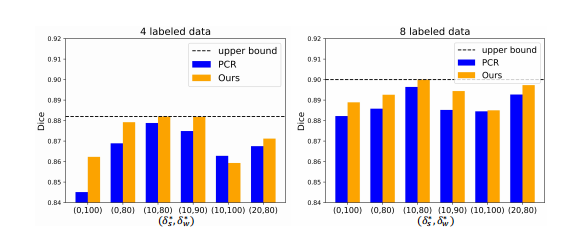
Fig. 8: Comparison results of PCR [2] and our method on twolabel ratios with different (δ , δw ) pairs.
图8:PCR [2]和我们的方法在两种标签比例及不同(δs , δw )组合下的比较结果。
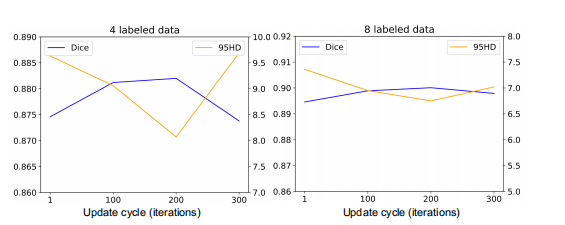
Fig. 9: Model performance versus different update cycles (T).
图9:模型性能与不同更新周期 (T) 的关系。
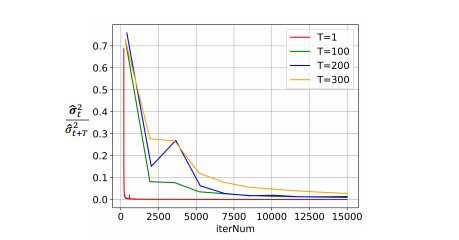
Fig. 10: The variance ratio of cumulative and incrementalprototypes ( ˆσ2σˆ 2 tt+T) varies with the training iteration number(i.e., iterNum) in different update cycles (T). Larger proportionmeans more incorporated incremental information.
图10:累计和增量原型的方差比 (ˆσ2σˆ 2 tt+T) 随不同更新周期 (T) 中训练迭代次数(即 iterNum)的变化。较大比例表示包含了更多的增量信息。
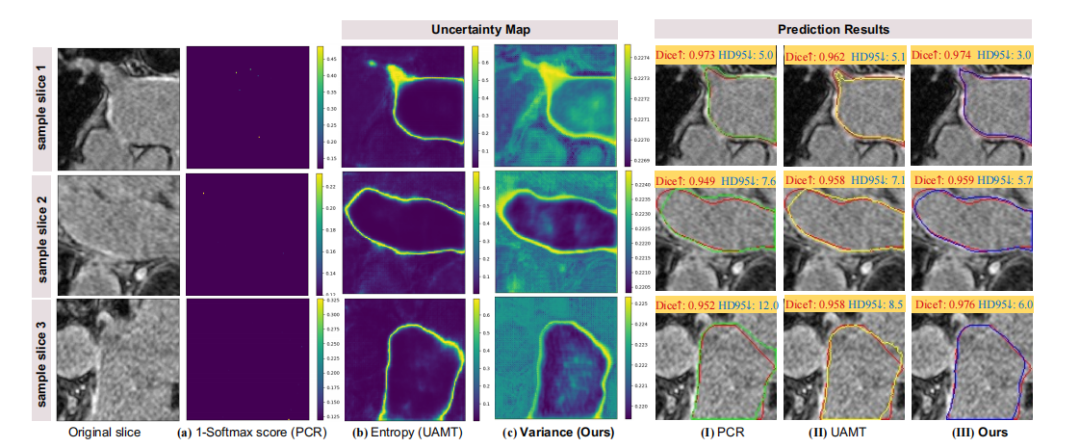
Fig. 11: Visualization of prediction uncertainty indicated by (a) 1−Softmax score, (b) entropy, and (c) variance, respectively.Brighter color indicates higher uncertainty of the prediction. Right part shows the prediction results of: (I) PCR [2], (II)UAMT [18], and (III) Ours that accordingly adopt (a), (b) and (c) to filter out unreliable predictions in the model learning.Red contours represent the ground truths, while green, yellow and blue ones represent the corresponding predicted results,respectively
图11:预测不确定性可视化,分别通过(a) 1−Softmax分数、(b) 熵和(c) 方差表示。颜色越亮表示预测不确定性越高。右侧展示了以下方法的预测结果:(I) PCR [2],(II) UAMT [18],(III) 我们的方法,这些方法分别采用(a)、(b) 和(c) 来过滤模型学习中的不可靠预测。红色轮廓表示真实值,绿色、黄色和蓝色轮廓分别表示对应的预测结果。
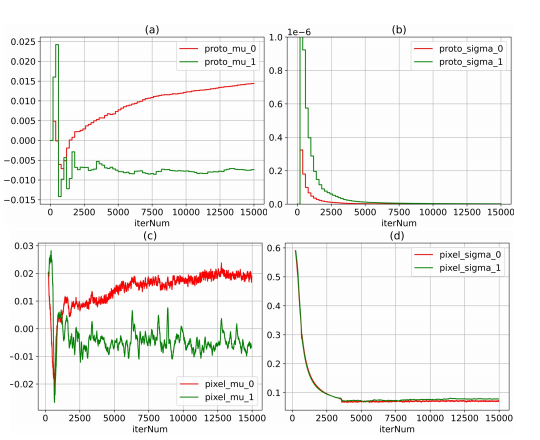
Fig. 12: Changes of mean and variance (denoted as mu andsigma in the figure) of two distribution prototypes (a-b) andpixels of two classes (c-d) in LA dataset. The plotted meanand variance values are averaged along the feature dimensionas well as the population.
图12:LA数据集中两个分布原型(a-b)及两个类别像素(c-d)的均值和方差变化(图中分别表示为mu和sigma)。绘制的均值和方差值是在特征维度和样本总量上进行平均后的结果。
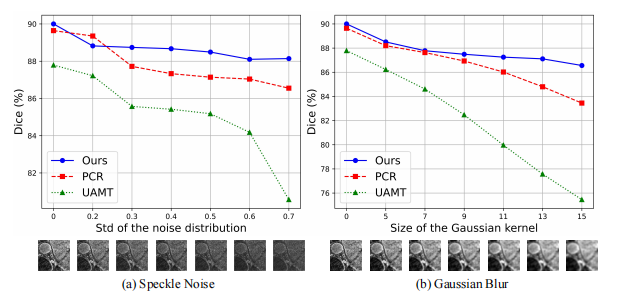
Fig. 13: Model robustness to noisy data.
图13:模型对噪声数据的鲁棒性。
Table
表
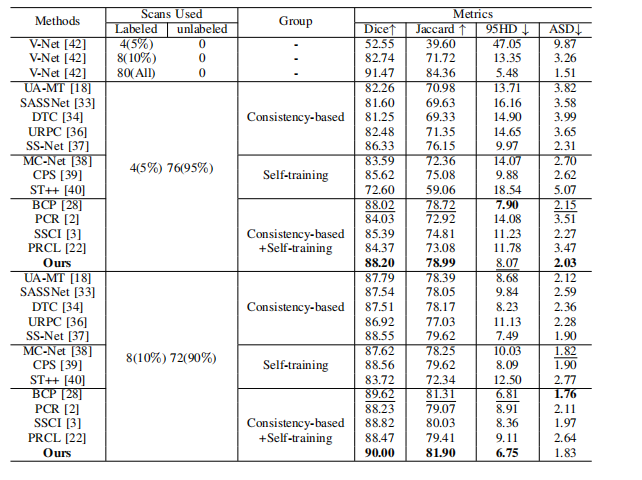
TABLE I: Comparison with SOTA SSL methods on LAdataset.
表1:与最新半监督学习(SSL)方法在LA数据集上的比较。
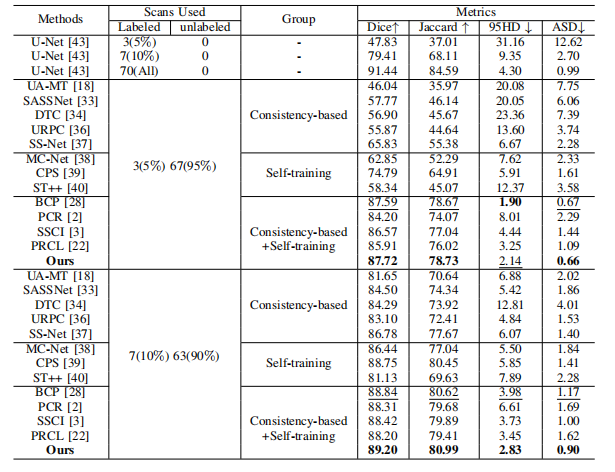
TABLE II: Comparison with SOTA SSL methods on ACDCdataset.
表2:与最新半监督学习(SSL)方法在ACDC数据集上的比较。
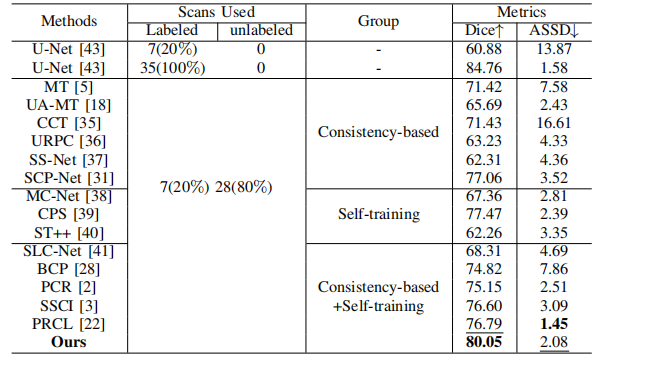
TABLE III: Comparison with SOTA SSL methods onPROMISE12 dataset.
表3:与最新半监督学习(SSL)方法在PROMISE12数据集上的比较。
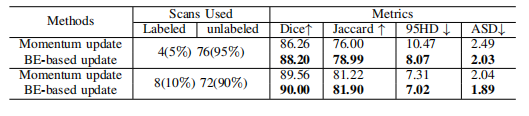
TABLE IV: Comparison results of methods by adopting twodifferent prototype update strategies.
表4:采用两种不同原型更新策略的方法比较结果。