CVPR力推!预训练+医学图像这么玩,审稿人都得为你让条路!
最近发现Nature、CVPR、NeurIPS等顶会顶刊上,涌现了不少预训练+医学图像的文章,不仅效果拔群,思路也很有启发性。
像是Nature上的REFERS,便颠覆了传统方法,使标注数据量直降90%!此外还有CVPR24上参数量狂降33倍的SegFormer3D、性能飙升63.46%的SaLIP……
可见该方向的受欢迎程度!主要在于,医学图像领域一直都面临数据收集复杂且昂贵,难以构建大规模、高质量的标注数据集等挑战!而预训练模型的引入,则为解决这一问题提供了强大的支撑。其可以利用大规模的无标注或弱标注数据进行预训练,使模型能够自动学习病灶的特征和潜在表示,从而提高诊断准确率。
为让伙伴们能够紧跟领域前沿,找到更多idea启发,我给大家梳理了10种创新思路和源码!
Unified Medical Image Pre-training in Language-Guided Common Semantic Space
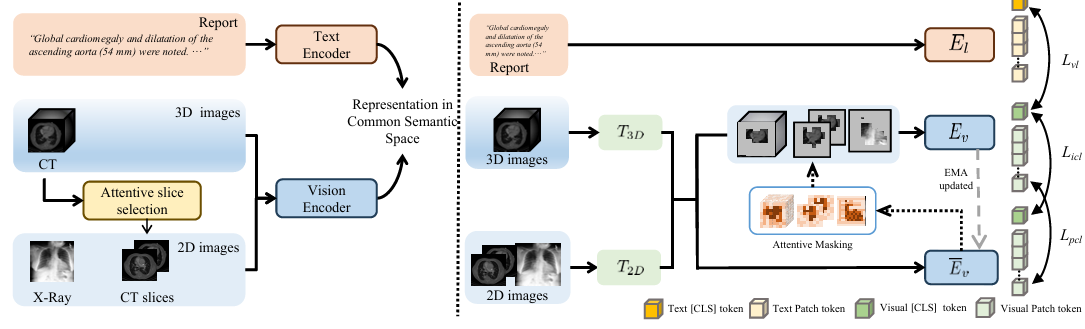
内容:文章介绍了一个名为UniMedI的统一医学图像预训练框架,该框架利用诊断报告作为共同的语义空间,为不同模态的医学图像(特别是2D和3D图像)创建统一的表示。UniMedI通过文本引导选择与文本相关的2D切片,将它们作为伪配对,以桥接2D和3D数据,增强了不同医学成像模态之间的一致性。实验结果表明,UniMedI在分类、分割和检索等多个下游任务中表现出色,证明了其在建立通用医学视觉表示方面的有效性。
Generalized Radiograph Representation Learning via Cross-supervision between Images and Free-text Radiology Reports
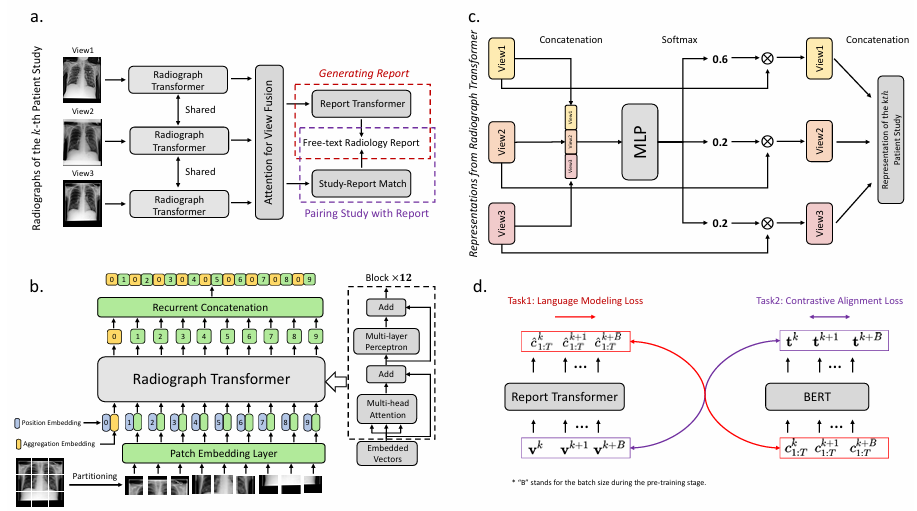
内容:文章提出了一种名为REFERS的跨监督学习方法,该方法直接从放射科报告中获取自由监督信号,用于学习X光图像的联合表示。REFERS使用视觉Transformer作为骨干网络,通过从多个视角学习每个患者研究的联合表示,并在有限监督下在四个知名的X光数据集上超越了传统的迁移学习和自监督学习方法。此外,REFERS甚至超过了基于人类辅助结构化标签的源域方法,显示出在实际应用中减少医学图像分析中对标注数据需求的潜力。
FreMIM: Fourier Transform Meets Masked Image Modeling for Medical Image Segmentation
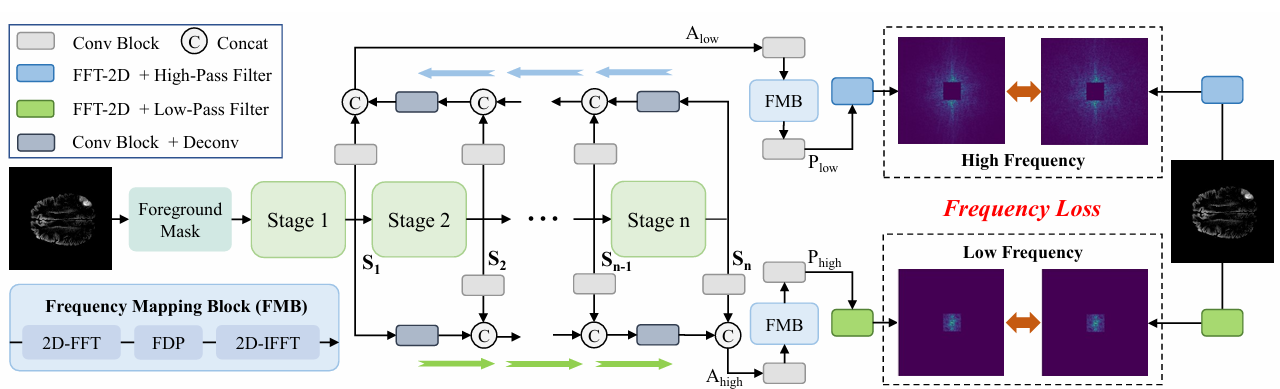
内容:文章介绍了一种名为FreMIM的新型自监督预训练框架,它结合了傅里叶变换和掩码图像建模(MIM),用于医学图像分割任务。FreMIM通过在频域中对图像的局部细节和全局结构信息进行建模,利用多阶段监督来指导表示学习,从而提高了模型在医学图像分割任务中的性能。
VoCo: A Simple-yet-Effective Volume Contrastive Learning Framework for 3D Medical Image Analysis
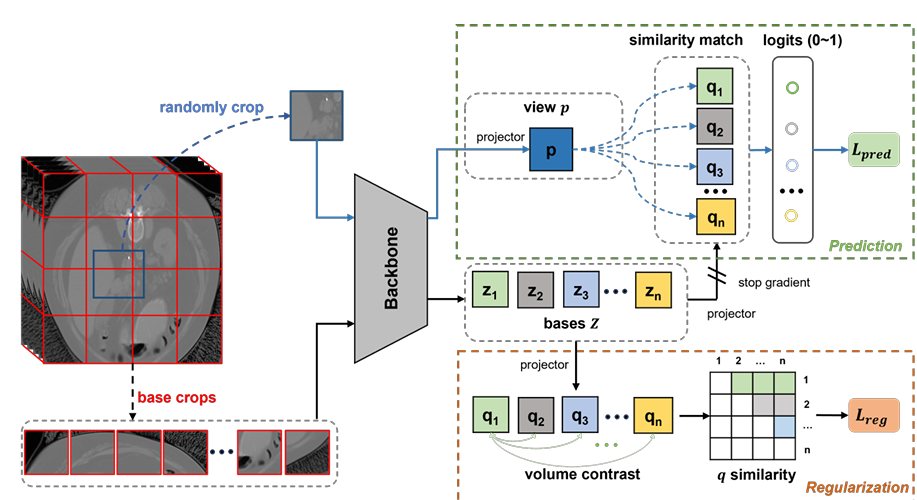
内容:文章介绍了一个名为VoCo的自监督学习框架,用于3D医学图像分析。VoCo通过利用3D医学图像中不同器官间相对一致的上下文位置信息,提出了一个简单的上下文位置预测任务,通过对比随机裁剪体积与不同基准体积的相似性来预测其上下文位置,从而在预训练阶段隐式地编码上下文位置先验到模型表示中,有效提高了需要高级语义的下游任务的性能。
码字不易,欢迎大家点赞评论收藏!
关注下方《AI科研技术派》
回复【预训练医学】获取完整论文
👇