DPI-MoCo:基于深度先验图像约束的运动补偿重建用于四维锥形束CT (4D CBCT)|文献速递-基于深度学习的病灶分割与数据超分辨率
Title
题目
DPI-MoCo: Deep Prior Image ConstrainedMotion Compensation Reconstruction for 4D CBCT
DPI-MoCo:基于深度先验图像约束的运动补偿重建用于四维锥形束CT (4D CBCT)
01
文献速递介绍
安装在直线加速器上的N板锥束计算机断层扫描(CBCT)是图像引导放射治疗(IGRT)中的有效成像工具,因为它可以灵活地提供三维解剖信息,并纠正患者定位或靶区定位的任何变化。然而,由于呼吸运动,CBCT会受到运动引起的伪影严重降解的影响。
随后,四维CBCT(4D CBCT)被引入以解决运动模糊伪影的问题。由于其能够实时追踪器官和组织的运动,4D CBCT在肺癌的适应性放射治疗(ART)中发挥了重要作用。然而,这也会导致4D CBCT中出现严重的条纹伪影,因为每个相位分辨图像(PRI)的投影数据极其稀疏,这无疑降低了其临床价值。目前,如何在重建高质量PRI的同时保留呼吸运动的动态变化是4D CBCT的主要挑战。许多研究致力于解决这个问题,它们大致可以分为三类:迭代(IR)方法、运动补偿(MoCo)方法和基于深度学习(DL)的方法。
通过将各种正则化项纳入优化过程中,IR方法的表现优于典型的Feldkamp-David-Kress(FDK)算法。在这些方法中,总变差(TV)是最广泛使用的约束函数。通过最小化PRI的梯度图像的幅度,TV方法成功地促进了4D CBCT图像的噪声和伪影抑制。接下来,为了充分利用相邻PRI之间的时间相关性,一些研究提出在空间序列域中正则化重建图像的4D TV。此外,基于先验图像指导的TV算法是4D CBCT重建的另一种流行方案。这些研究的驱动力在于观察到个别PRI与从全采样投影数据重建的先验图像之间的差异图在运动区域是稀疏的,这可以大大提升最终重建结果,相比于经典的TV方法。然而,基于IR的方法往往导致过度平滑的结果和小细节的丧失。
Aastract
摘要
4D cone-beam computed tomography (CBCT) plays a critical role in adaptive radiation therapy for lung cancer. However, extremely sparse sampling projection data will cause severe streak artifacts in 4D CBCT images. Existing deep learning (DL) methods heavily rely on large labeled training datasets which are difficult to obtain in practical scenarios. Restricted by this dilemma, DL models often struggle with simultaneously retaining dynamic motions, removing streak degradations, and recovering fine details. To address the above challenging problem, we introduce a Deep Prior Image Constrained Motion Compensation framework (DPI-MoCo) that decouples the 4D CBCT reconstruction into two sub-tasks including coarse image restoration and structural detail fine-tuning. In the first stage, the proposed DPI-MoCo combines the prior image guidance, generative adversarial network, and contrastive learning to globally suppress the artifacts while maintaining the respiratory movements. After that, to further enhance the local anatomical structures, the motion estimation and compensation technique is adopted. Notably, our framework is performed without the need for paired datasets, ensuring practicality in clinical cases. In the Monte Carlo simulation dataset, the DPI-MoCo achieves competitive quantitative performance compared to the state-ofthe-art (SOTA) methods. Furthermore, we test DPI-MoCo in clinical lung cancer datasets, and experiments validate that DPIMoCo not only restores small anatomical structures and lesions but also preserves motion information.
4D锥束计算机断层扫描(CBCT)在肺癌的适应性放射治疗中发挥着关键作用。然而,极其稀疏的采样投影数据会导致4D CBCT图像中出现严重的条纹伪影。现有的深度学习(DL)方法在很大程度上依赖于大量标注的训练数据集,而这些数据在实际场景中难以获得。受此困境的限制,DL模型通常难以同时保留动态运动、去除条纹降解以及恢复细微细节。为了解决上述挑战性问题,我们提出了一种深度先验图像约束运动补偿框架(DPI-MoCo),将4D CBCT重建解耦为两个子任务,包括粗略图像恢复和结构细节微调。在第一阶段,DPI-MoCo结合了先验图像指导、生成对抗网络和对比学习,以全球范围内抑制伪影,同时保持呼吸运动。随后,为了进一步增强局部解剖结构,采用了运动估计和补偿技术。值得注意的是,我们的框架在不需要配对数据集的情况下执行,确保了在临床案例中的实用性。在蒙特卡罗模拟数据集中,DPI-MoCo在定量性能上与最先进(SOTA)方法相比具有竞争力。此外,我们在临床肺癌数据集中测试了DPI-MoCo,实验验证了DPI-MoCo不仅恢复了小的解剖结构和病变,而且保留了运动信息。
Conclusion
结论
It remains a challenging problem to reconstruct high-qualityclinical 4D CBCT images due to the extremely sparse-view projection data. To tackle this issue, traditional methods represented by PICCS and MoCo are proposed, and bring improvement in artifact reduction and detail recovery to a certain extent. Meanwhile, DL-based methods have attracted great attention in various medical imaging tasks and show superiority over conventional methods. However, two factors hamper the application of DL in real 4D CBCT. First, because the ground truth 4D CBCT images are inaccessible in real applications, some classical supervised learning methods, such as DDNet, and CycN-Net, have to be transferred from the simulated dataset to the clinical dataset. It is very difficult to make the simulated data similar to the real ones, which always results in domain gaps, so the performances of these methodsare expected to decrease. Second, unlike image denoising, unsupervised learning or self-supervised learning have not been widely employed for sparse-view CBCT imaging, therefore, their applications in 4D CBCT are yet mature.Latest, [33] offers a potential approach to overcome the above-mentioned dilemma of DL by constructing novel pseudo-average datasets. Inspired by it, this work proposes a DPI-MoCo framework to further promote PRIs. It consists of four steps, which sequentially are high-quality pseudo-average dataset construction, effective RestoreNet network training, motion estimation and compensation, and DenoiseNet optimization. Each of them can push the final results toward a more optimal solution. Particularly, the first two stages aim to provide coarse artifact-free results. Then, the next two stepsconcentrate on local structure fine-tuning and slight artifact removal. Unlike most existing deep models in 4D CBCT imaging, our DPI-MoCo breaks through the limitation of relying on ground truth data for training. Compared to conventional MoCo, the proposed method leads to more accurate anatomical features. Both simulated and clinical datasets validate the effectiveness of the proposed DPI-MoCo in concurrently reducing artifacts and maintaining the motion information.Nevertheless, it still has two defects for DPI-MoCo that should be noticed. When making the pseudo-average datasets,however, on account of the different projection sampling trajectories, 𝑥𝑥𝑛𝑛 𝑎𝑎 and 𝑥𝑥𝑛𝑛 may contain slightly different degradation patterns in practical cases. Besides, the PI also has some motion artifacts in relatively stationary areas. These factors will result in a few artifacts left in the final images even though applying the DenoiseNet. At the same time, as indicated by CycN-Net and PRIOR-Net, although the utilization of prior images in the PIGAE module generates more effective pseudoaverage datasets, it will negatively introduce some motionblurred phenomena. Therefore, how to build a more reasonable pseudo-average dataset should be further explored. Very recently, the Neural Radiance Field (NeRF) has been applied to medical imaging with patient-specific mode, so the combination of NeRF and our MoCo can be considered in the future.
重建高质量的临床4D锥束计算机断层扫描(CBCT)图像仍然是一个具有挑战性的问题,主要原因在于极其稀疏的视图投影数据。为了解决这个问题,传统方法如PICCS和MoCo被提出,并在伪影减少和细节恢复方面取得了一定的进展。同时,基于深度学习(DL)的方法在各种医学成像任务中受到了极大关注,并显示出优于传统方法的优势。然而,两个因素限制了DL在真实4D CBCT中的应用。首先,由于真实应用中无法获得真实的4D CBCT图像,一些经典的监督学习方法,如DDNet和CycN-Net,必须从模拟数据集转移到临床数据集中。使模拟数据与真实数据相似非常困难,这通常会导致领域差距,因此这些方法的性能预计会下降。其次,与图像去噪不同,无监督学习或自监督学习尚未广泛应用于稀疏视图CBCT成像,因此它们在4D CBCT中的应用尚不成熟。
最新的研究[33]提供了一种潜在的方法,通过构建新型伪平均数据集来克服上述DL困境。受到这一启发,本研究提出了DPI-MoCo框架,以进一步促进相位分辨图像(PRI)的重建。该框架包括四个步骤,依次为高质量伪平均数据集构建、有效的RestoreNet网络训练、运动估计和补偿,以及DenoiseNet优化。每个步骤都能推动最终结果朝着更优解发展。特别是,前两个阶段旨在提供粗略的无伪影结果。接下来的两个步骤则集中在局部结构的微调和轻微伪影的去除。与现有大多数4D CBCT成像的深度模型不同,我们的DPI-MoCo突破了对真实数据进行训练的限制。与传统的MoCo相比,所提方法能够生成更准确的解剖特征。无论是在模拟数据集还是临床数据集上,DPI-MoCo在同时减少伪影和保持运动信息方面的有效性得到了验证。
尽管如此,DPI-MoCo仍然存在两个需要注意的缺陷。在构建伪平均数据集时,由于不同的投影采样轨迹,xnnx{nn}xnn和xnnx{nn}xnn在实际案例中可能包含稍微不同的降解模式。此外,先验图像在相对静止区域也存在一些运动伪影。这些因素将导致即使应用了DenoiseNet,最终图像中仍会留下少量伪影。同时,正如CycN-Net和PRIOR-Net所指出的,虽然在PIGAE模块中利用先验图像生成了更有效的伪平均数据集,但它也会引入一些运动模糊现象。因此,如何构建更合理的伪平均数据集仍需进一步探索。最近,神经辐射场(NeRF)已被应用于具有患者特定模式的医学成像,因此在未来可以考虑将NeRF与我们的MoCo结合。
Figure
图
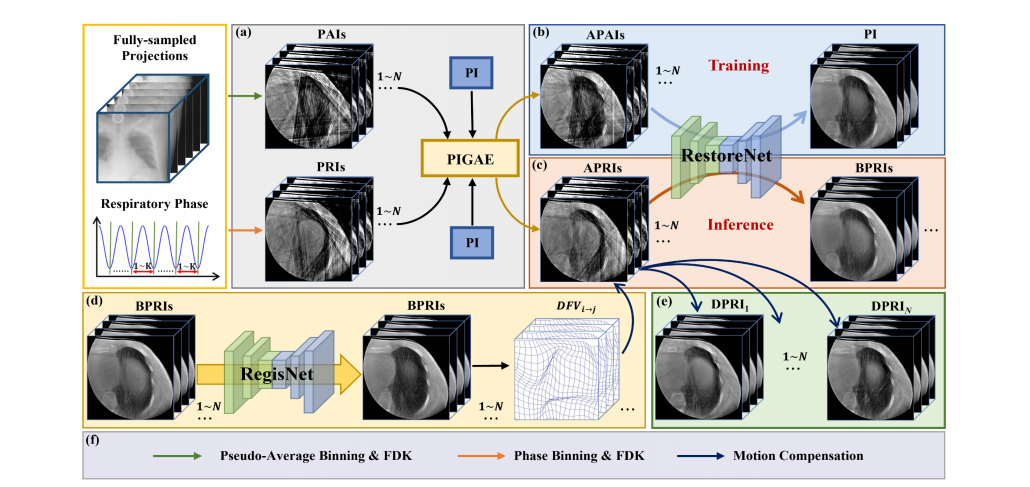
Fig 1. The overview of the proposed DPI-MoCo framework. (a) Prior-image guided artifact estimation module. (b) RestoreNet training on the pseudo-paired dataset. (c) Global artifact removal inference for APRIs. (d) Motion estimation between arbitrary BPRIs. (e) Motion compensation and denoising. (a)-(c) Coarse image generation. (d)-(e) Anatomical structure fine-tuning. PAI: Pseudo-average image, PI: Prior-Image, PRI: Phase-Resolved Image, APAI: Artifact-reduced PAI, APRI: Artifact-reduced PRI, BPRI: Boosted PRI, DPRI: Denoised PRI.
图1. 提出的DPI-MoCo框架概述。(a) 基于先验图像的伪影估计模块。(b) 在伪配对数据集上训练RestoreNet。(c) 针对APRIs的全局伪影去除推断。(d) 任意BPRIs之间的运动估计。(e) 运动补偿和去噪。(a)-(c) 粗略图像生成。(d)-(e) 解剖结构微调。PAI: 伪平均图像,PI: 先验图像,PRI: 相位分辨图像,APAI: 降伪影的PAI,APRI: 降伪影的PRI,BPRI: 增强PRI,DPRI: 去噪PRI。
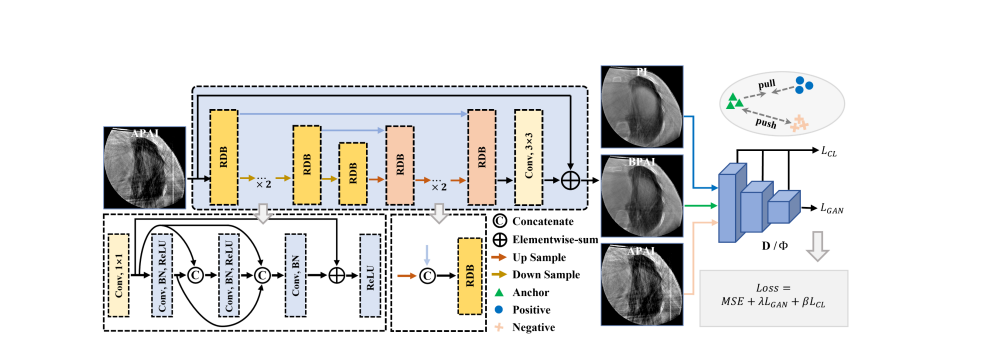
Fig.2. The architecture of the proposed RestoreNet.
图2. 提出的RestoreNet的架构。
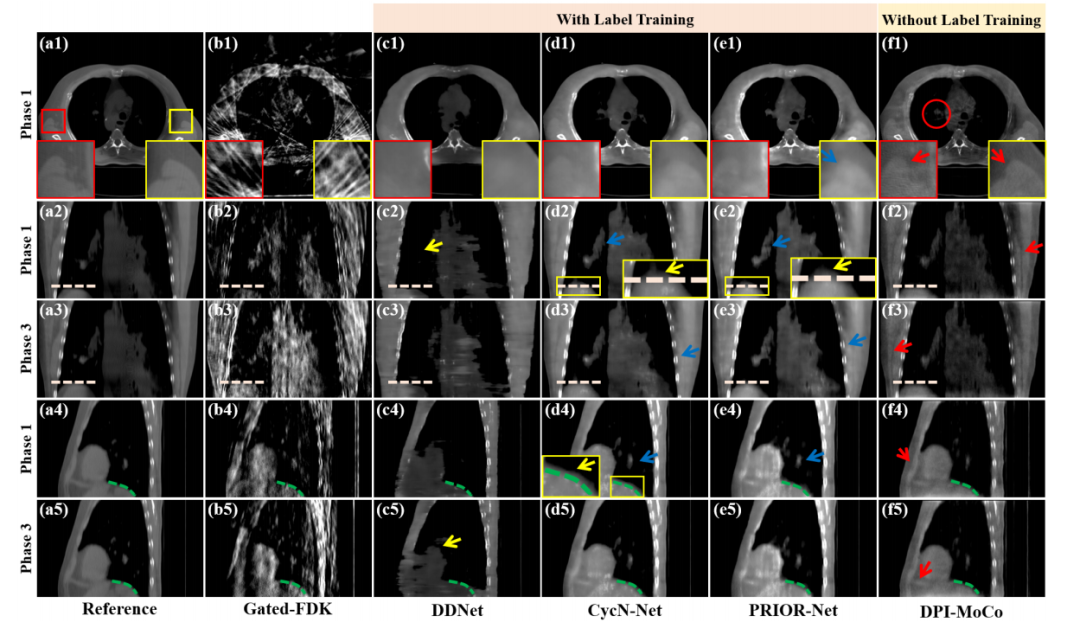
Fig. 3. Reconstructed results from selected Phases 1 and 3 on the simulated dataset for different methods, including reconstructed images and magnified regionsof-interest (ROIs). Reference images are reconstructed from full-sampled projections. (a1)-(f1) Axial results at Phase 1, (a2)-(f2) Coronal results at Phase 1, (a3)-(f3) Coronal results at Phase 3, (a4)-(f4) Sagittal results at Phase 1, (a5)-(f5) Sagittal results at Phase 3. The display window is [0.004, 0.018] mm-1 .
图3. 在模拟数据集中,不同方法在选定相位1和3的重建结果,包括重建图像和放大感兴趣区域(ROIs)。参考图像是从全采样投影重建的。(a1)-(f1) 相位1的轴向结果,(a2)-(f2) 相位1的冠状结果,(a3)-(f3) 相位3的冠状结果,(a4)-(f4) 相位1的矢状结果,(a5)-(f5) 相位3的矢状结果。显示窗口为 [0.004, 0.018] mm^-1。
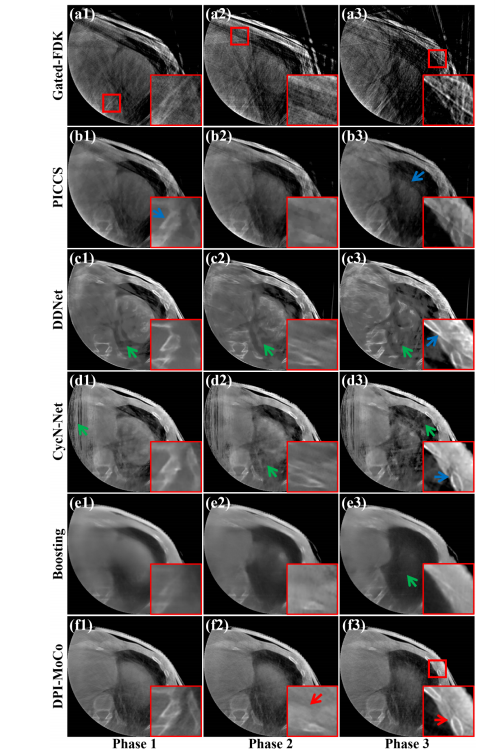
Fig. 4. Reconstructed axial results from three selected phases on the LinaTech dataset for different methods. (a1)-(f1) Reconstructed results at Phase 1, (a2)-(f2) Reconstructed results at Phase 2, (a3)-(f3) Reconstructed results at PhaseThe display window is [0.004, 0.022] mm-1 .
图4. 在LinaTech数据集上,不同方法在三个选定相位的重建轴向结果。(a1)-(f1) 相位1的重建结果,(a2)-(f2) 相位2的重建结果,(a3)-(f3) 相位3的重建结果。显示窗口为 [0.004, 0.022] mm^-1。
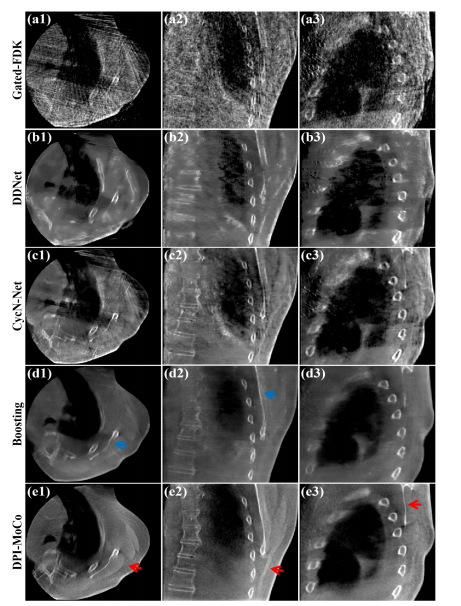
Fig. 5. Reconstructed results on the Elekta dataset for different methods atPhase 5. (a1)-(a3) Images reconstructed by Gated-FDK, (b1)-(b3) Images processed by DDNet, (c1)-(c3) Images processed by CycN-Net, (d1)-(d3) Images processed by Boosting, (e1)-(e3) Images processed by DPI-MoCo. The display window is [0.006, 0.018] mm-1 .
图5. 在Elekta数据集上,不同方法在相位5的重建结果。(a1)-(a3) 由Gated-FDK重建的图像,(b1)-(b3) 由DDNet处理的图像,(c1)-(c3) 由CycN-Net处理的图像,(d1)-(d3) 由Boosting处理的图像,(e1)-(e3) 由DPI-MoCo处理的图像。显示窗口为 [0.006, 0.018] mm^-1。
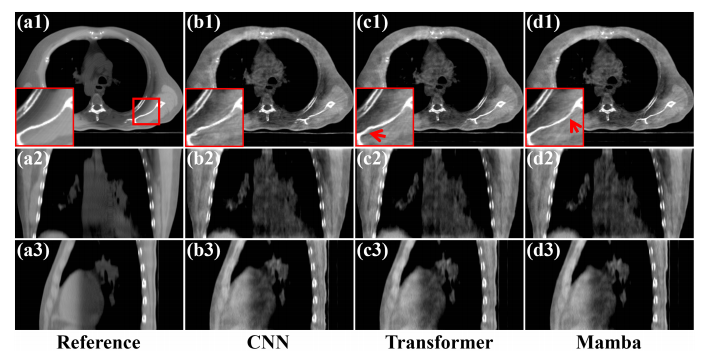
Fig. 6. Reconstructed results from Phase 2 on the simulated dataset. (a1)-(a3) Reference images reconstructed from full-sampled projections, (b1)-(b3) Images processed by CNN networks, (c1)-(c3) Images processed byTransformer networks, (d1)-(d3) Images processed by Mamba networks. The display window is [0.004, 0.014] mm-1 .
图6. 在模拟数据集中,相位2的重建结果。(a1)-(a3) 从全采样投影重建的参考图像,(b1)-(b3) 由CNN网络处理的图像,(c1)-(c3) 由Transformer网络处理的图像,(d1)-(d3) 由Mamba网络处理的图像。显示窗口为 [0.004, 0.014] mm^-1。
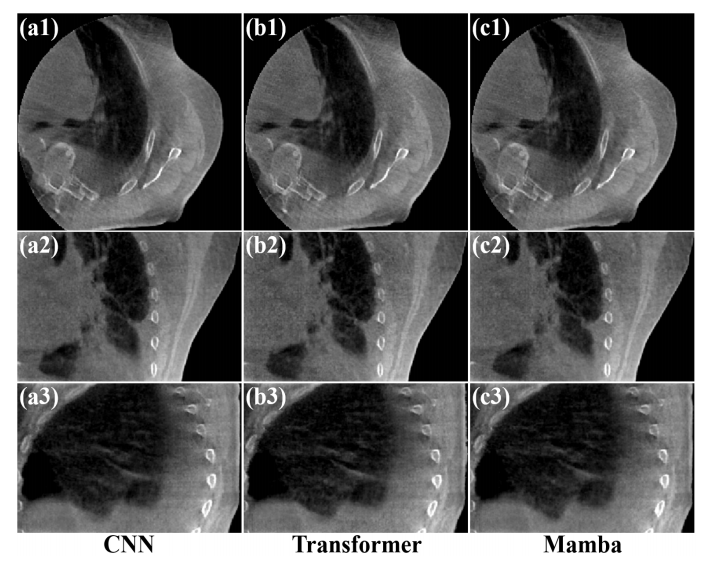
Fig. 7. Reconstructed results from Phase 2 on the Elekta dataset. (a1)-(a3) Images processed by CNN entworks, (b1)-(b3) Images processed by Transformer networks, (c1)-(c3) Images processed by Mamba networks. The display window is [0.004, 0.018] mm-1 .
图7. 在Elekta数据集上,相位2的重建结果。(a1)-(a3) 由CNN网络处理的图像,(b1)-(b3) 由Transformer网络处理的图像,(c1)-(c3) 由Mamba网络处理的图像。显示窗口为 [0.004, 0.018] mm^-1。
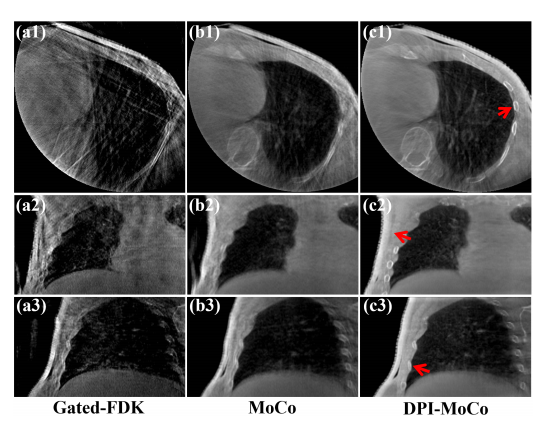
Fig. 8. Reconstruction images of different methods on the LinaTech dataset at Phase 1. (a1)-(a3) Images reconstructed by FDK, (b1)-(b2) Images reconstructed by MoCo, (c1)-(c3) Images processed by DPI-MoCo. The display window is [0.004, 0.022] mm-1 .
图8. 在LinaTech数据集上,相位1的不同方法重建图像。(a1)-(a3) 由FDK重建的图像,(b1)-(b2) 由MoCo重建的图像,(c1)-(c3) 由DPI-MoCo处理的图像。显示窗口为 [0.004, 0.022] mm^-1。

Fig. 9. Reconstructed tumor ROI results of different methods on the LinaTech dataset with continuous ten phases. (a1)-(a10) Coronal views of Gated-FDK from Phase 1 to Phase 10, (b1)-(b10) Coronal views of DPI-MoCo from Phase 1 to Phase 10, (c1)-(c10) Sagittal views of Gated-FDK from Phase 1 to Phase 10, (d1)-(d10) Sagittal views of DPI-MoCo from Phase 1 to Phase 10. The display window is [0.006, 0.2] mm-1 .
图9. 在LinaTech数据集上,不同方法在连续十个相位的肿瘤ROI重建结果。(a1)-(a10) Gated-FDK在相位1到相位10的冠状视图,(b1)-(b10) DPI-MoCo在相位1到相位10的冠状视图,(c1)-(c10) Gated-FDK在相位1到相位10的矢状视图,(d1)-(d10) DPI-MoCo在相位1到相位10的矢状视图。显示窗口为 [0.006, 0.2] mm^-1。
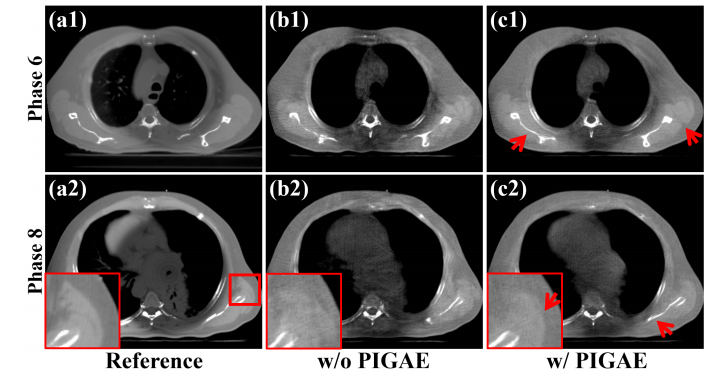
Fig. 10. Reconstructed results from Phases 6 and 8 on the simulated dataset.(a1)-(a2) Reference images reconstructed from full-sampled projections, (b1)-(b2) Images processed by RestoreNet without PIGAE module, (c1)-(c2) Images processed by RestoreNet with PIGAE module. The display window is [0.004, 0.014] mm-1 .
图10. 在模拟数据集中,相位6和8的重建结果。(a1)-(a2) 从全采样投影重建的参考图像,(b1)-(b2) 由不带PIGAE模块的RestoreNet处理的图像,(c1)-(c2) 由带PIGAE模块的RestoreNet处理的图像。显示窗口为 [0.004, 0.014] mm^-1。
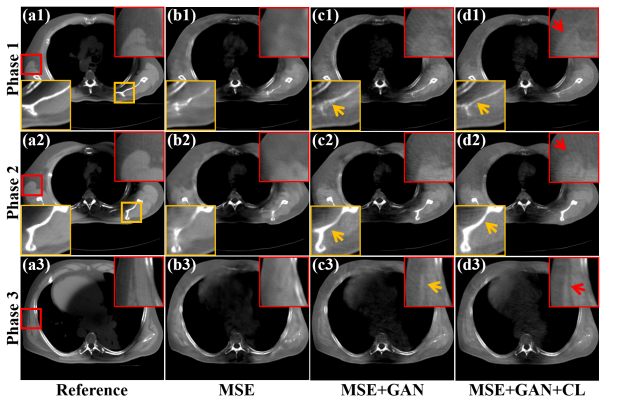
F (a1) ig. - 11 (a3 . Reconstructed results from ) Reference images reconstructed from full Phases 1, 2, and 3 -sampled projections, (b1) on the simulated dataset. -(b3) Images optimized by MSE loss, (c1)-(c3) Images optimized by MSE+GAN loss, (d1)-(d3) Images optimized by MSE+GAN+CL loss. The display window is [0.005, 0.014] mm-1 .
图11. 在模拟数据集中,相位1、2和3的重建结果。(a1)-(a3) 从全采样投影重建的参考图像,(b1)-(b3) 通过MSE损失优化的图像,(c1)-(c3) 通过MSE+GAN损失优化的图像,(d1)-(d3) 通过MSE+GAN+CL损失优化的图像。显示窗口为 [0.005, 0.014] mm^-1。
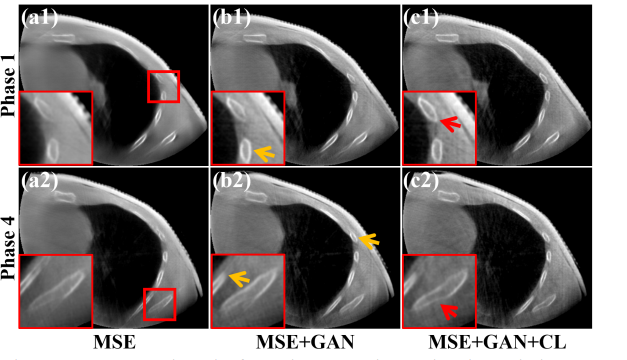
Fig. 12. Reconstructed results from Phases 1 and 4 on the LinaTech dataset. (a1)-(a2) Images optimized by MSE loss, (b1)-(c2) Images optimized by MSE+GAN loss, (c1)-(c2) Images optimized by MSE+GAN+CL loss. The display window is [0.006, 0.02] mm-1 .
图12. 在LinaTech数据集上,相位1和4的重建结果。(a1)-(a2) 通过MSE损失优化的图像,(b1)-(b2) 通过MSE+GAN损失优化的图像,(c1)-(c2) 通过MSE+GAN+CL损失优化的图像。显示窗口为 [0.006, 0.02] mm^-1。
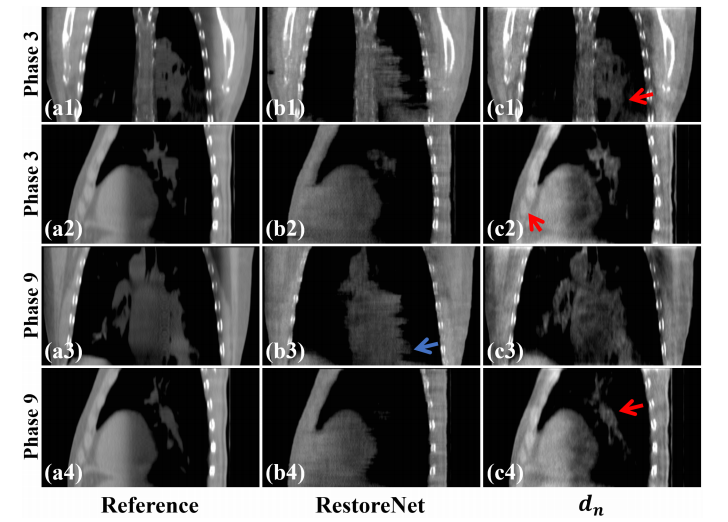
Fig. 13. Reconstructed results from Phases 3 and 9 on the simulated dataset. (a1)-(a4) Reference images reconstructed from full-sampled projections, (b1)-(b4) Images processed by RestoreNet, (c1)-(c4) Images provided by 𝑑𝑑𝑛𝑛. The display window is [0.004, 0.014] mm-1 .
图13. 在模拟数据集中,相位3和9的重建结果。(a1)-(a4) 从全采样投影重建的参考图像,(b1)-(b4) 由RestoreNet处理的图像,(c1)-(c4) 由DDNet提供的图像。显示窗口为 [0.004, 0.014] mm^-1。

Fig. 14. Reconstruction results and zoomed ROIs on the LinaTech dataset at Phase 1, which are deformed from 𝑥𝑥𝑛𝑛, 𝑐𝑐𝑛𝑛, and 𝑏𝑏𝑛𝑛, respectively. The display window is [0.008, 0.02] mm-1 .
图14. 在LinaTech数据集上,相位1的重建结果和放大感兴趣区域(ROIs),分别由xnnx{nn}xnn、cnnc{nn}cnn和bnnb_{nn}bnn变形而成。显示窗口为 [0.008, 0.02] mm^-1。
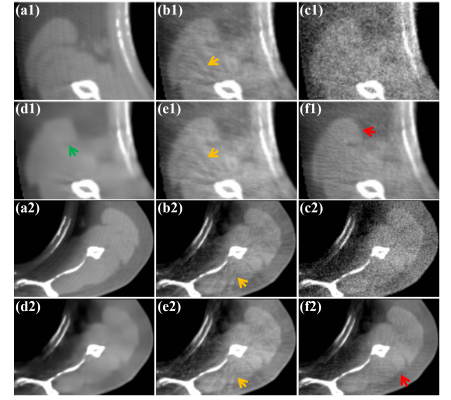
Fig. 15. Denoised ROI results on the simulated dataset of different methods at Phase 1. (a1)-(a2) Reference images reconstructed from full-sampled Denoised images processed by KSVD from (b1) projections, (b1)-(b2) 𝑑𝑑1 images, (c1)-(c2) Noisy -(b2), (e1) 𝑑𝑑1 images, (d1) -(e2) Denoised -(d2) images processed by Nb2Nb from (b1)-(b2), (f1)-(f2) Denoised images processed by DenoiseNet from (c1)-(c2). The display window is [0.005, 0.014] mm-1 .
图15. 在模拟数据集中,相位1的不同方法的去噪ROI结果。(a1)-(a2) 从全采样投影重建的参考图像,(b1)-(b2) 由KSVD处理的去噪图像,(c1)-(c2) 嘈杂的dd1d{d1}dd1图像,(d1)-(d2) 由Nb2Nb处理的去噪图像,(e1)-(e2) 由dd1d{d1}dd1处理的去噪图像,(f1)-(f2) 由DenoiseNet处理的去噪图像。显示窗口为 [0.005, 0.014] mm^-1。
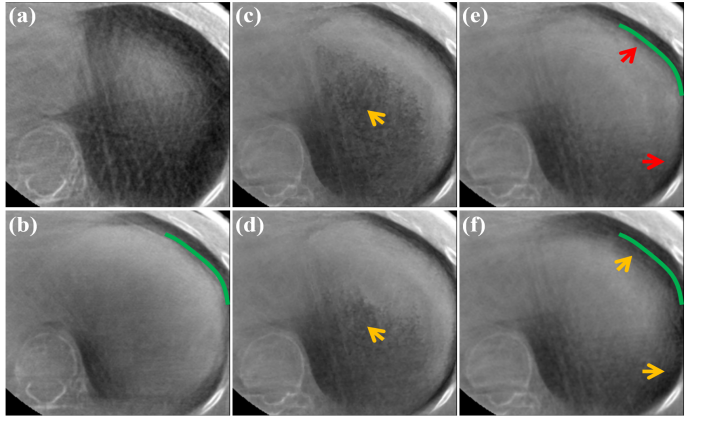
Fig. 16. Registration ROI results on the LinaTech dataset with different 𝜎𝜎values. (a) Moving ROI image at Phase 5, (b) Fixed image at Phase 1, (c) Registrated image deformed from (a) with 𝜎𝜎 = 0.1, (d) Registrated image deformed from (a) with 𝜎𝜎 = 1, (e) Registrated image deformed from (a) with 𝜎𝜎 = 4, (f) Registrated image deformed from (a) with 𝜎𝜎 = 10. The display window is [0.004, 0.018] mm-1 .
图16. 在LinaTech数据集中,不同σ\sigmaσ值的配准ROI结果。(a) 相位5的移动ROI图像,(b) 相位1的固定图像,(c) 由(a)变形而来的配准图像,σ=0.1\sigma = 0.1σ=0.1,(d) 由(a)变形而来的配准图像,σ=1\sigma = 1σ=1,(e) 由(a)变形而来的配准图像,σ=4\sigma = 4σ=4,(f) 由(a)变形而来的配准图像,σ=10\sigma = 10σ=10。显示窗口为 [0.004, 0.018] mm^-1。
Table
表
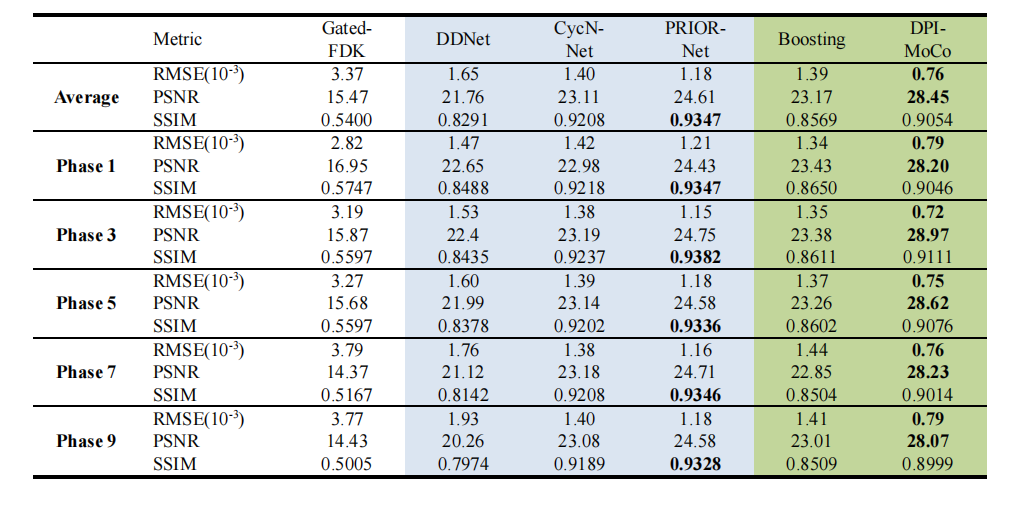
Table I quantitative evaluations of different methods for the simulated dataset (rmse: mm-1). blue and green respectively represent methods trained with and without label data.
表 I 不同方法在模拟数据集上的定量评估(RMSE: MM^-1)。蓝色和绿色分别表示使用和不使用标签数据训练的方法。

Table II the configurations of different backbones for restorenet and regisnet.
表 II 不同骨干网络的配置用于RestoreNet和RegisNet。

Table III average quantitative evaluations of different backbones for restorenet and regisnet on the simulated dataset (rmse: mm-1).
表 III 不同骨干网络在模拟数据集上对RestoreNet和RegisNet的平均定量评估(RMSE: MM^-1)。

Table IV average quantitative evaluations of pigae module on the simulated dataset (rmse: mm-1).
表 IV PIGAE模块在模拟数据集上的平均定量评估(RMSE: MM^-1)。
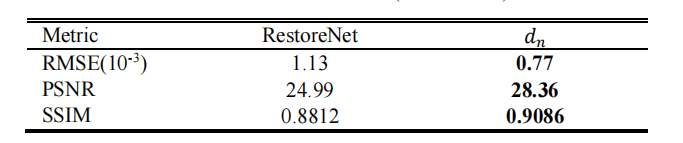
Table V average quantitative evaluations between restorenet and 𝑑𝑑𝑛𝑛 on the simulated dataset (rmse: mm-1).
表 V RestoreNet与DDNet在模拟数据集上的平均定量评估(RMSE: MM^-1)。

Table VI computational cost of different methods on the linatech dataset (unit: second).
表 VI 不同方法在LinaTech数据集上的计算成本(单位:秒)。
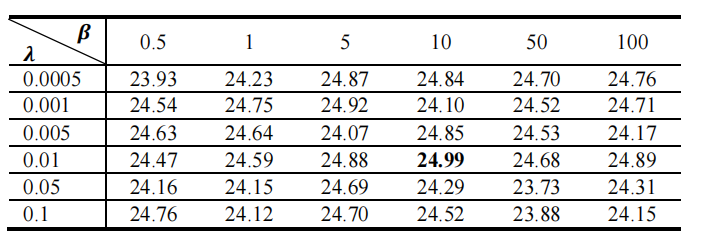
Table VII average psnr evaluations of different hyper-parameters on the simulated dataset.
表 VII 不同超参数在模拟数据集上的平均PSNR评估。