7天用Go从零实现分布式缓存GeeCache(总结)
1. Lru包
1.1 lru算法简要概述
(作者:豆豉辣椒炒腊肉/链接:https://juejin.cn/post/6844904049263771662)
LRU算法全称是最近最少使用算法(Least Recently Use),广泛的应用于缓存机制中。当缓存使用的空间达到上限后,就需要从已有的数据中淘汰一部分以维持缓存的可用性,而淘汰数据的选择就是通过LRU算法完成的。
LRU算法的基本思想是基于局部性原理的时间局部性:
如果一个信息项正在被访问,那么在近期它很可能还会被再次访问。
所以顾名思义,LRU算法会选出最近最少使用的数据进行淘汰。
1.2 原理
一般来讲,LRU将访问数据的顺序或时间和数据本身维护在一个容器当中。当访问一个数据时:
- 该数据不在容器当中,则设置该数据的优先级为最高并放入容器中。
- 该数据在容器当中,则更新该数据的优先级至最高。
当数据的总量达到上限后,则移除容器中优先级最低的数据。下图是一个简单的LRU原理示意图:

如果我们按照7 0 1 2 0 3 0 4的顺序来访问数据,且数据的总量上限为3,则如上图所示,LRU算法会依次淘汰7 1 2这三个数据。
1.3 朴素的LRU算法
那么我们现在就按照上面的原理,实现一个朴素的LRU算法。下面有三种方案:
-
基于数组
方案:为每一个数据附加一个额外的属性——时间戳,当每一次访问数据时,更新该数据的时间戳至当前时间。当数据空间已满后,则扫描整个数组,淘汰时间戳最小的数据。
不足:维护时间戳需要耗费额外的空间,淘汰数据时需要扫描整个数组。
-
基于长度有限的双向链表
方案:访问一个数据时,当数据不在链表中,则将数据插入至链表头部,如果在链表中,则将该数据移至链表头部。当数据空间已满后,则淘汰链表最末尾的数据。
不足:插入数据或取数据时,需要扫描整个链表。
-
基于双向链表和哈希表
方案:为了改进上面需要扫描链表的缺陷,配合哈希表,将数据和链表中的节点形成映射,将插入操作和读取操作的时间复杂度从O(N)降至O(1)
lru简要概述转自(作者:豆豉辣椒炒腊肉/链接:https://juejin.cn/post/6844904049263771662)
geecache选用的第三种方案,双向链表结合哈希表,容器在代码中表现为最大字节数
1.4 设计思路:
- LRU 策略: 使用双向链表(
container/list)和哈希映射实现高效的最近最少使用缓存。链表的前端表示最近使用的条目,后端表示最久未使用的条目。 - 内存管理: 通过
maxBytes和nbytes控制缓存的最大内存使用,当超过限制时自动移除最久未使用的条目。 - 回调机制: 提供
OnEvicted回调函数,当条目被驱逐时执行特定操作,增强灵活性。
核心数据结构
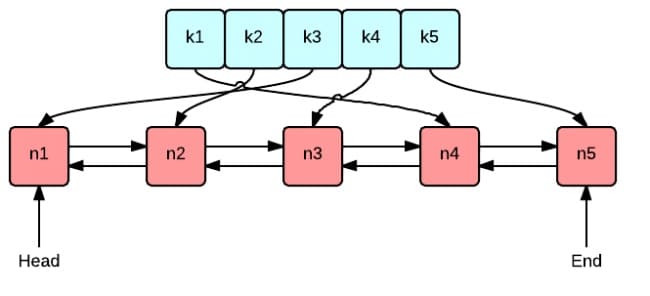
这张图很好地表示了 LRU 算法最核心的 2 个数据结构
- 绿色的是字典(map),存储键和值的映射关系。这样根据某个键(key)查找对应的值(value)的复杂是O(1),在字典中插入一条记录的复杂度也是O(1)
- 红色的是双向链表(double linked list)实现的队列。将所有的值放到双向链表中,这样,当访问到某个值时,将其移动到队尾的复杂度是
O(1),在队尾新增一条记录以及删除一条记录的复杂度均为O(1)。
1.5 代码:
package lru
import "container/list"
// Cache 是一个 LRU 缓存。它不支持并发访问。
type Cache struct {
maxBytes int64 // 缓存的最大字节数
nbytes int64 // 当前缓存的字节数
ll *list.List // 双向链表,用于维护访问顺序
cache map[string]*list.Element // 哈希表,键对应链表中的元素
// 可选,当条目被清除时执行的回调函数
OnEvicted func(key string, value Value)
}
type entry struct {
key string
value Value
}
// Value 使用 Len 方法来计算其占用的字节数
type Value interface {
Len() int
}
// New 是 Cache 的构造函数
func New(maxBytes int64, onEvicted func(string, Value)) *Cache {
return &Cache{
maxBytes: maxBytes,
ll: list.New(),
cache: make(map[string]*list.Element),
OnEvicted: onEvicted,
}
}
// Add 向缓存中添加一个值。如果键已经存在,则更新其值并将其移到链表前端。
// 如果缓存超出最大字节数,则移除最旧的条目。
func (c *Cache) Add(key string, value Value) {
if ele, ok := c.cache[key]; ok {
c.ll.MoveToFront(ele) // 将已存在的元素移到前端
kv := ele.Value.(*entry)
c.nbytes += int64(value.Len()) - int64(kv.value.Len()) // 更新当前字节数
kv.value = value // 更新值
} else {
ele := c.ll.PushFront(&entry{key, value}) // 添加新元素到前端
c.cache[key] = ele
c.nbytes += int64(len(key)) + int64(value.Len()) // 更新当前字节数
}
for c.maxBytes != 0 && c.maxBytes < c.nbytes { // 检查是否超出最大字节数
c.RemoveOldest() // 移除最旧的条目
}
}
// Get 查找键对应的值。如果找到,将该元素移到链表前端。
func (c *Cache) Get(key string) (value Value, ok bool) {
if ele, ok := c.cache[key]; ok {
c.ll.MoveToFront(ele) // 将元素移到前端
kv := ele.Value.(*entry)
return kv.value, true // 返回值和存在标志
}
return
}
// RemoveOldest 移除最旧的条目(链表尾部的元素)。
func (c *Cache) RemoveOldest() {
ele := c.ll.Back() // 获取链表尾部的元素
if ele != nil {
c.ll.Remove(ele) // 从链表中移除元素
kv := ele.Value.(*entry)
delete(c.cache, kv.key) // 从哈希表中删除键
c.nbytes -= int64(len(kv.key)) + int64(kv.value.Len()) // 更新当前字节数
if c.OnEvicted != nil { // 如果有回调函数,执行它
c.OnEvicted(kv.key, kv.value)
}
}
}
// Len 返回缓存中条目的数量。
func (c *Cache) Len() int {
return c.ll.Len()
}
测试
package lru
import (
"reflect"
"testing"
)
type String string
func (d String) Len() int {
return len(d)
}
func TestGet(t *testing.T) {
lru := New(int64(0), nil)
lru.Add("key1", String("1234"))
if v, ok := lru.Get("key1"); !ok || string(v.(String)) != "1234" {
t.Fatalf("cache hit key1=1234 failed")
}
if _, ok := lru.Get("key2"); ok {
t.Fatalf("cache miss key2 failed")
}
}
func TestRemoveoldest(t *testing.T) {
k1, k2, k3 := "key1", "key2", "k3"
v1, v2, v3 := "value1", "value2", "v3"
cap := len(k1 + k2 + v1 + v2)
lru := New(int64(cap), nil)
lru.Add(k1, String(v1))
lru.Add(k2, String(v2))
lru.Add(k3, String(v3))
if _, ok := lru.Get("key1"); ok || lru.Len() != 2 {
t.Fatalf("Removeoldest key1 failed")
}
}
func TestOnEvicted(t *testing.T) {
keys := make([]string, 0)
callback := func(key string, value Value) {
keys = append(keys, key)
}
lru := New(int64(10), callback)
lru.Add("key1", String("123456"))
lru.Add("k2", String("k2"))
lru.Add("k3", String("k3"))
lru.Add("k4", String("k4"))
expect := []string{"key1", "k2"}
if !reflect.DeepEqual(expect, keys) {
t.Fatalf("Call OnEvicted failed, expect keys equals to %s", expect)
}
}
func TestAdd(t *testing.T) {
lru := New(int64(0), nil)
lru.Add("key", String("1"))
lru.Add("key", String("111"))
if lru.nbytes != int64(len("key")+len("111")) {
t.Fatal("expected 6 but got", lru.nbytes)
}
}
- 测试
package lru
import (
"reflect"
"testing"
)
// 定义一个 String 类型,并实现 Value 接口中的 Len 方法
type String string
// Len 方法返回字符串的长度
func (d String) Len() int {
return len(d)
}
// TestGet 测试 LRU 缓存的 Get 方法
func TestGet(t *testing.T) {
// 创建一个新的 LRU 缓存,容量为 0,没有淘汰回调函数
lru := New(int64(0), nil)
// 添加键值对 "key1":"1234" 到缓存中
lru.Add("key1", String("1234"))
// 尝试获取 "key1",并检查是否获取成功且值正确
if v, ok := lru.Get("key1"); !ok || string(v.(String)) != "1234" {
t.Fatalf("cache hit key1=1234 failed")
}
// 尝试获取不存在的 "key2",应返回未命中
if _, ok := lru.Get("key2"); ok {
t.Fatalf("cache miss key2 failed")
}
}
// TestRemoveoldest 测试 LRU 缓存自动移除最旧元素的功能
func TestRemoveoldest(t *testing.T) {
// 定义三个键和对应的值
k1, k2, k3 := "key1", "key2", "k3"
v1, v2, v3 := "value1", "value2", "v3"
// 计算总容量,简单地将所有键和值的长度相加
cap := len(k1 + k2 + v1 + v2)
// 创建一个新的 LRU 缓存,容量为 cap,且没有淘汰回调函数
lru := New(int64(cap), nil)
// 添加三个键值对到缓存中
lru.Add(k1, String(v1))
lru.Add(k2, String(v2))
lru.Add(k3, String(v3))
// 检查 "key1" 是否被移除,以及缓存长度是否为 2
if _, ok := lru.Get("key1"); ok || lru.Len() != 2 {
t.Fatalf("Removeoldest key1 failed")
}
}
// TestOnEvicted 测试淘汰回调函数是否被正确调用
func TestOnEvicted(t *testing.T) {
// 创建一个切片用于记录被淘汰的键
keys := make([]string, 0)
// 定义淘汰回调函数,将被淘汰的键添加到 keys 切片中
callback := func(key string, value Value) {
keys = append(keys, key)
}
// 创建一个新的 LRU 缓存,容量为 10,并设置淘汰回调函数
lru := New(int64(10), callback)
// 添加多个键值对,导致部分键被淘汰
lru.Add("key1", String("123456")) // 长度 7
lru.Add("k2", String("k2")) // 长度 2,总长度 9
lru.Add("k3", String("k3")) // 长度 2,总长度 11,"key1" 被淘汰
lru.Add("k4", String("k4")) // 长度 2,总长度 13,"k2" 被淘汰
// 预期被淘汰的键为 "key1" 和 "k2"
expect := []string{"key1", "k2"}
// 比较实际淘汰的键与预期是否一致
if !reflect.DeepEqual(expect, keys) {
t.Fatalf("Call OnEvicted failed, expect keys equals to %s", expect)
}
}
// TestAdd 测试向 LRU 缓存添加元素时是否正确更新缓存的字节数
func TestAdd(t *testing.T) {
// 创建一个新的 LRU 缓存,容量为 0,没有淘汰回调函数
lru := New(int64(0), nil)
// 添加键 "key" 对应的值 "1"
lru.Add("key", String("1"))
// 再次添加键 "key" 对应的值 "111",应覆盖之前的值
lru.Add("key", String("111"))
// 检查缓存的字节数是否正确更新为键和值的总长度
if lru.nbytes != int64(len("key")+len("111")) {
t.Fatal("expected 6 but got", lru.nbytes)
}
}
1.6 函数签名:
函数签名
// New 是 Cache 的构造函数,初始化一个新的 Cache 实例。
func New(maxBytes int64, onEvicted func(string, Value)) *Cache
方法签名
// Add 向缓存中添加一个键值对。
func (c *Cache) Add(key string, value Value)
// Get 查找键对应的值。
func (c *Cache) Get(key string) (value Value, ok bool)
// RemoveOldest 移除缓存中最久未使用的条目。
func (c *Cache) RemoveOldest()
// Len 返回缓存中条目的数量。
func (c *Cache) Len() int
说明
-
New:创建并返回一个新的 Cache实例,设置最大缓存字节数和可选的驱逐回调函数。 -
Add:添加或更新缓存中的键值对,若缓存超出限制,则移除最久未使用的条目。 -
Get:根据键获取对应的值,并将该条目移动到链表前端表示最近使用。 -
RemoveOldest:移除缓存中最久未使用的条目,并执行驱逐回调(如果有)。 -
Len:返回当前缓存中条目的数量。
1.7 文件内容概述:
- Cache 结构体: 实现了一个基于最近最少使用(LRU)策略的缓存,不支持并发访问。
- entry 结构体: 存储缓存条目的键和值。
- Value 接口: 定义缓存值必须实现的
Len方法,用于计算其占用的字节数。 - New 函数: 构造一个新的
Cache实例。 - Add 方法: 向缓存中添加或更新键值对,并根据需要移除最久未使用的条目。
- Get 方法: 获取指定键的值,并将其移动到前端表示最近使用。
- RemoveOldest 方法: 移除缓存中最久未使用的条目。
- Len 方法: 返回缓存中条目的数量。
2. 一致性哈希包 (consistenthash)
2.1 简要描述和设计思路
一致性哈希(Consistent Hashing) 是一种分布式系统中常用的算法,用于将请求分配到不同的节点上,减少因节点增加或减少导致的数据重分布。通过一致性哈希,可以确保数据在节点之间分布均匀,并在节点变化时最小化数据迁移。
在本实现中,引入了 虚拟节点 的概念。每个真实节点对应多个虚拟节点,这样可以更均匀地将请求分布到各个节点上,避免由于节点数量较少导致的负载不均衡。
2.2 代码及注释
package consistenthash
import (
"hash/crc32"
"sort"
"strconv"
)
// Hash 定义了哈希函数类型,接收一个字节数组,返回 uint32 类型的哈希值
type Hash func(data []byte) uint32
// Map 结构体表示一致性哈希的主数据结构
type Map struct {
hash Hash // 哈希函数
replicas int // 每个真实节点对应的虚拟节点数量
keys []int // 哈希环,存储所有虚拟节点的哈希值(已排序)
hashMap map[int]string // 虚拟节点与真实节点的映射表
}
// New 创建一个一致性哈希的 Map 实例
func New(replicas int, fn Hash) *Map {
m := &Map{
replicas: replicas, // 设置虚拟节点的数量
hash: fn, // 设置哈希函数
hashMap: make(map[int]string), // 初始化映射表
}
// 如果未提供哈希函数,使用默认的 crc32.ChecksumIEEE
if m.hash == nil {
m.hash = crc32.ChecksumIEEE
}
return m
}
// Add 向哈希环中添加真实节点
func (m *Map) Add(keys ...string) {
for _, key := range keys {
// 对每个真实节点,创建指定数量的虚拟节点
for i := 0; i < m.replicas; i++ {
// 将虚拟节点编号与真实节点名组合,生成唯一的虚拟节点键
virtualNodeKey := strconv.Itoa(i) + key
// 计算虚拟节点的哈希值
hash := int(m.hash([]byte(virtualNodeKey)))
// 将哈希值添加到哈希环中
m.keys = append(m.keys, hash)
// 建立虚拟节点与真实节点的映射关系
m.hashMap[hash] = key
}
}
// 对哈希环进行排序
sort.Ints(m.keys)
}
// Get 根据给定的键,选择最近的节点
func (m *Map) Get(key string) string {
if len(m.keys) == 0 {
return ""
}
// 计算键的哈希值
hash := int(m.hash([]byte(key)))
// 使用二分查找找到第一个大于等于哈希值的位置
idx := sort.Search(len(m.keys), func(i int) bool {
return m.keys[i] >= hash
})
// 如果超过了最大索引,循环回到哈希环的起点
idx = idx % len(m.keys)
// 返回对应的真实节点名称
return m.hashMap[m.keys[idx]]
}
2.3 测试代码
package consistenthash
import (
"strconv"
"testing"
)
func TestHashing(t *testing.T) {
// 自定义哈希函数,返回整数值
hash := New(3, func(data []byte) uint32 {
i, _ := strconv.Atoi(string(data))
return uint32(i)
})
// 添加节点
hash.Add("6", "4", "2")
// 测试键与节点的映射关系
testCases := map[string]string{
"2": "2",
"11": "2",
"23": "4",
"27": "2",
}
for k, v := range testCases {
if hash.Get(k) != v {
t.Errorf("Asking for %s, should have yielded %s", k, v)
}
}
// 添加新节点
hash.Add("8")
// 更新期望的映射关系
testCases["27"] = "8"
for k, v := range testCases {
if hash.Get(k) != v {
t.Errorf("Asking for %s, should have yielded %s", k, v)
}
}
}
2.4 函数签名说明
New 函数
func New(replicas int, fn Hash) *Map
- 描述:创建并返回一个一致性哈希的 Map 实例。
- 参数:
replicas:每个真实节点对应的虚拟节点数量。fn:哈希函数,可选参数,若为nil则使用默认的crc32.ChecksumIEEE。
- 返回值:
*Map,一致性哈希 Map 的指针。
Add 方法
func (m *Map) Add(keys ...string)
- 描述:向哈希环中添加一个或多个真实节点。
- 参数:
keys:真实节点的名称,可变参数。
Get 方法
func (m *Map) Get(key string) string
- 描述:根据给定的键,选择最近的真实节点。
- 参数:
key:需要查找的键。
- 返回值:对应的真实节点名称。
2.5 整体设计思路
- 一致性哈希算法:通过将节点和键映射到同一个哈希空间,实现节点的动态增删时,数据重分布的最小化。
- 虚拟节点:通过为每个真实节点创建多个虚拟节点,解决哈希值分布不均的问题,提高负载均衡性。
- 高效查找:使用排序的哈希环和二分查找,实现对节点的高效定位。
- 灵活性:允许用户自定义哈希函数,增强算法的适用性。
3. 单航班(SingleFlight)包
3.1 简要描述和设计思路
在高并发场景下,可能会有多个请求同时请求同一个数据,这可能导致对底层数据源的重复访问或计算,增加了系统的负担。SingleFlight 通过抑制对同一资源的重复请求,确保对于相同的键,在同一时间只有一个请求在进行,其他请求等待结果即可。
3.2 代码及注释
package singleflight
import "sync"
// call 表示正在进行中或已完成的请求
type call struct {
wg sync.WaitGroup // 用于同步等待
val interface{} // 请求的结果
err error // 请求的错误信息
}
// Group 管理不同键的请求
type Group struct {
mu sync.Mutex // 保护 m 的并发访问
m map[string]*call // 存储进行中的请求
}
// Do 执行并返回给定函数的结果,确保相同的键只会被请求一次
func (g *Group) Do(key string, fn func() (interface{}, error)) (interface{}, error) {
g.mu.Lock()
if g.m == nil {
g.m = make(map[string]*call)
}
// 如果请求已在进行中,等待其完成
if c, ok := g.m[key]; ok {
g.mu.Unlock()
c.wg.Wait()
return c.val, c.err
}
// 否则,创建一个新的请求
c := new(call)
c.wg.Add(1)
g.m[key] = c
g.mu.Unlock()
// 执行请求函数
c.val, c.err = fn()
c.wg.Done()
// 请求完成,删除请求记录
g.mu.Lock()
delete(g.m, key)
g.mu.Unlock()
return c.val, c.err
}
3.3 测试代码
package singleflight
import (
"sync"
"testing"
)
func TestDo(t *testing.T) {
var g Group
var count int
var wg sync.WaitGroup
key := "key"
// 模拟多个并发请求
for i := 0; i < 100; i++ {
wg.Add(1)
go func() {
defer wg.Done()
val, err := g.Do(key, func() (interface{}, error) {
count++
return count, nil
})
if err != nil {
t.Errorf("Error: %v", err)
}
if val.(int) != 1 {
t.Errorf("Expected 1 but got %d", val.(int))
}
}()
}
wg.Wait()
if count != 1 {
t.Errorf("Function was called %d times, expected 1", count)
}
}
3.4 函数签名说明
Do 方法
func (g *Group) Do(key string, fn func() (interface{}, error)) (interface{}, error)
- 描述:执行并返回给定函数的结果,确保同一时间相同的键只会被请求一次。
- 参数:
key:请求的键。fn:实际执行的函数。
- 返回值:
interface{}:函数执行的结果。error:执行过程中产生的错误。
3.5 整体设计思路
- 抑制重复请求:通过记录正在进行的请求,防止对同一键的重复请求,节省资源。
- 并发控制:使用互斥锁和 WaitGroup,确保并发安全,并让后续请求等待结果。
- 提升效率:避免了因并发请求导致的资源浪费,提高系统的整体性能。
4. Geecache 包
Geecache 是一个分布式缓存系统,实现了多级缓存、分布式节点管理、并发控制等功能。
4.1 简要描述和设计思路
- ByteView:用于存储缓存值的不可变视图,确保数据的线程安全。
- cache:内部使用 LRU 算法管理缓存数据,并通过互斥锁实现并发安全。
- Group:缓存命名空间,负责与用户的交互,加载数据并管理缓存。
- HTTPPool:实现了基于 HTTP 的节点间通信,管理节点间的请求转发和数据获取。
4.2 代码及注释
a. ByteView 结构体
package geecache
// ByteView 保存了一个不可变的字节视图。
type ByteView struct {
b []byte // 存储真实的缓存值
}
// Len 返回缓存值的长度
func (v ByteView) Len() int {
return len(v.b)
}
// ByteSlice 返回缓存值的一个拷贝,防止外部修改
func (v ByteView) ByteSlice() []byte {
return cloneBytes(v.b)
}
// String 返回缓存值的字符串表示
func (v ByteView) String() string {
return string(v.b)
}
// cloneBytes 创建一个字节切片的拷贝
func cloneBytes(b []byte) []byte {
c := make([]byte, len(b))
copy(c, b)
return c
}
b. cache 结构体
package geecache
import (
"geecache/lru"
"sync"
)
// cache 包装了 lru.Cache,并添加了互斥锁
type cache struct {
mu sync.Mutex // 互斥锁,保护内部的 LRU cache
lru *lru.Cache // LRU 缓存
cacheBytes int64 // 最大缓存大小
}
// add 添加一个键值对到缓存中
func (c *cache) add(key string, value ByteView) {
c.mu.Lock()
defer c.mu.Unlock()
if c.lru == nil {
c.lru = lru.New(c.cacheBytes, nil)
}
c.lru.Add(key, value)
}
// get 从缓存中获取指定的键值
func (c *cache) get(key string) (ByteView, bool) {
c.mu.Lock()
defer c.mu.Unlock()
if c.lru == nil {
return ByteView{}, false
}
if val, ok := c.lru.Get(key); ok {
return val.(ByteView), true
}
return ByteView{}, false
}
c. Group 结构体
package geecache
import (
"fmt"
"geecache/singleflight"
"log"
"sync"
)
// Group 代表一个缓存的命名空间
type Group struct {
name string // 名称
getter Getter // 获取源数据的回调
mainCache cache // 内部缓存
peers PeerPicker // 节点选择器
loader *singleflight.Group // 确保每个键只被请求一次
}
// Getter 是回调接口,用于加载数据源
type Getter interface {
Get(key string) ([]byte, error)
}
// GetterFunc 是函数类型,实现了 Getter 接口
type GetterFunc func(key string) ([]byte, error)
// Get 调用函数自身,获取数据
func (f GetterFunc) Get(key string) ([]byte, error) {
return f(key)
}
var (
mu sync.RWMutex
groups = make(map[string]*Group)
)
// NewGroup 创建一个新的 Group 实例
func NewGroup(name string, cacheBytes int64, getter Getter) *Group {
if getter == nil {
panic("nil Getter")
}
mu.Lock()
defer mu.Unlock()
g := &Group{
name: name,
getter: getter,
mainCache: cache{cacheBytes: cacheBytes},
loader: &singleflight.Group{},
}
groups[name] = g
return g
}
// GetGroup 根据名称获取 Group 实例
func GetGroup(name string) *Group {
mu.RLock()
defer mu.RUnlock()
return groups[name]
}
// Get 从缓存中获取值,未命中则加载
func (g *Group) Get(key string) (ByteView, error) {
if key == "" {
return ByteView{}, fmt.Errorf("key is required")
}
if v, ok := g.mainCache.get(key); ok {
log.Println("[GeeCache] hit")
return v, nil
}
return g.load(key)
}
// RegisterPeers 注册节点选择器
func (g *Group) RegisterPeers(peers PeerPicker) {
if g.peers != nil {
panic("RegisterPeers called more than once")
}
g.peers = peers
}
// load 使用 singleflight 防止缓存击穿
func (g *Group) load(key string) (value ByteView, err error) {
viewi, err := g.loader.Do(key, func() (interface{}, error) {
if g.peers != nil {
if peer, ok := g.peers.PickPeer(key); ok {
if value, err = g.getFromPeer(peer, key); err == nil {
return value, nil
}
log.Println("[GeeCache] Failed to get from peer", err)
}
}
return g.getLocally(key)
})
if err == nil {
return viewi.(ByteView), nil
}
return ByteView{}, err
}
// getLocally 调用用户回调获取数据
func (g *Group) getLocally(key string) (ByteView, error) {
bytes, err := g.getter.Get(key)
if err != nil {
return ByteView{}, err
}
value := ByteView{b: cloneBytes(bytes)}
g.populateCache(key, value)
return value, nil
}
// populateCache 将数据添加到缓存
func (g *Group) populateCache(key string, value ByteView) {
g.mainCache.add(key, value)
}
// getFromPeer 从其他节点获取数据
func (g *Group) getFromPeer(peer PeerGetter, key string) (ByteView, error) {
bytes, err := peer.Get(g.name, key)
if err != nil {
return ByteView{}, err
}
return ByteView{b: bytes}, nil
}
d. HTTPPool 结构体
package geecache
import (
"fmt"
"geecache/consistenthash"
"io/ioutil"
"log"
"net/http"
"net/url"
"strings"
"sync"
)
const (
defaultBasePath = "/_geecache/" // 默认路径前缀
defaultReplicas = 50 // 虚拟节点默认数量
)
// HTTPPool 实现了 PeerPicker 接口,管理节点间的 HTTP 通信
type HTTPPool struct {
self string // 自身地址
basePath string // 通信地址前缀
mu sync.Mutex // 保护 peers 和 httpGetters
peers *consistenthash.Map // 一致性哈希环
httpGetters map[string]*httpGetter // 映射远程节点与对应的 httpGetter
}
// NewHTTPPool 初始化一个 HTTPPool 实例
func NewHTTPPool(self string) *HTTPPool {
return &HTTPPool{
self: self,
basePath: defaultBasePath,
}
}
// Log 打印日志信息
func (p *HTTPPool) Log(format string, v ...interface{}) {
log.Printf("[Server %s] %s", p.self, fmt.Sprintf(format, v...))
}
// ServeHTTP 处理所有的 HTTP 请求
func (p *HTTPPool) ServeHTTP(w http.ResponseWriter, r *http.Request) {
if !strings.HasPrefix(r.URL.Path, p.basePath) {
panic("HTTPPool serving unexpected path: " + r.URL.Path)
}
p.Log("%s %s", r.Method, r.URL.Path)
parts := strings.SplitN(r.URL.Path[len(p.basePath):], "/", 2)
if len(parts) != 2 {
http.Error(w, "bad request", http.StatusBadRequest)
return
}
groupName := parts[0]
key := parts[1]
group := GetGroup(groupName)
if group == nil {
http.Error(w, "no such group: "+groupName, http.StatusNotFound)
return
}
view, err := group.Get(key)
if err != nil {
http.Error(w, err.Error(), http.StatusInternalServerError)
return
}
w.Header().Set("Content-Type", "application/octet-stream")
w.Write(view.ByteSlice())
}
// Set 更新节点列表
func (p *HTTPPool) Set(peers ...string) {
p.mu.Lock()
defer p.mu.Unlock()
p.peers = consistenthash.New(defaultReplicas, nil)
p.peers.Add(peers...)
p.httpGetters = make(map[string]*httpGetter, len(peers))
for _, peer := range peers {
p.httpGetters[peer] = &httpGetter{baseURL: peer + p.basePath}
}
}
// PickPeer 根据键选择相应的节点
func (p *HTTPPool) PickPeer(key string) (PeerGetter, bool) {
p.mu.Lock()
defer p.mu.Unlock()
if peer := p.peers.Get(key); peer != "" && peer != p.self {
p.Log("Pick peer %s", peer)
return p.httpGetters[peer], true
}
return nil, false
}
// httpGetter 实现了 PeerGetter 接口,通过 HTTP 从远程节点获取数据
type httpGetter struct {
baseURL string // 远程节点的地址
}
// Get 从远程节点获取数据
func (h *httpGetter) Get(group string, key string) ([]byte, error) {
u := fmt.Sprintf(
"%v%v/%v",
h.baseURL,
url.QueryEscape(group),
url.QueryEscape(key),
)
res, err := http.Get(u)
if err != nil {
return nil, err
}
defer res.Body.Close()
if res.StatusCode != http.StatusOK {
return nil, fmt.Errorf("server returned: %v", res.Status)
}
bytes, err := ioutil.ReadAll(res.Body)
if err != nil {
return nil, fmt.Errorf("reading response body: %v", err)
}
return bytes, nil
}
4.3 函数签名说明
Group 相关
-
NewGroup 函数
func NewGroup(name string, cacheBytes int64, getter Getter) *Group- 描述:创建一个新的缓存组。
- 参数:
name:缓存组的名称。cacheBytes:缓存的最大容量。getter:用于加载源数据的回调函数。
- 返回值:
*Group,缓存组的实例。
-
Get 方法
func (g *Group) Get(key string) (ByteView, error)- 描述:根据键获取缓存值,未命中则加载。
- 参数:
key:要获取的键。
- 返回值:
ByteView:缓存值。error:错误信息。
-
RegisterPeers 方法
func (g *Group) RegisterPeers(peers PeerPicker)- 描述:注册节点选择器,用于在分布式环境中查找节点。
HTTPPool 相关
-
NewHTTPPool 函数
func NewHTTPPool(self string) *HTTPPool- 描述:初始化一个 HTTPPool 实例。
- 参数:
self:当前节点的地址。
- 返回值:
*HTTPPool,HTTPPool 实例。
-
ServeHTTP 方法
func (p *HTTPPool) ServeHTTP(w http.ResponseWriter, r *http.Request)- 描述:实现了 http.Handler 接口,处理 HTTP 请求。
-
Set 方法
func (p *HTTPPool) Set(peers ...string)- 描述:更新节点列表,并建立一致性哈希环。
-
PickPeer 方法
func (p *HTTPPool) PickPeer(key string) (PeerGetter, bool)- 描述:根据键选择合适的节点。
4. geecache 包
a. ByteView 结构体
文件内容概述:
- ByteView 结构体: 保存一个不可变的字节视图。
- Len 方法: 返回视图的长度。
- ByteSlice 方法: 返回数据的拷贝。
- String 方法: 返回数据的字符串形式。
- cloneBytes 函数: 创建字节切片的拷贝。
设计思路:
- 数据不可变性: 通过
ByteView保证缓存中存储的数据不可变,避免并发读写问题。 - 数据安全: 提供数据拷贝方法,防止外部修改缓存数据。
b. cache 结构体
文件内容概述:
- cache 结构体: 内部使用
lru.Cache来存储键值对,并通过互斥锁确保并发安全。 - add 方法: 向缓存中添加键值对。
- get 方法: 从缓存中获取指定键的值。
设计思路:
- 线程安全: 通过
sync.Mutex确保对内部 LRU 缓存的并发访问安全。 - 高效缓存: 结合
lru包提供的高效 LRU 缓存策略,管理缓存数据。
c. Group 结构体
文件内容概述:
- Group 结构体: 表示一个缓存组,包含名称、数据加载接口、主缓存、远程节点选择器和
singleflight组。 - Getter 接口和 GetterFunc 类型: 定义从外部加载数据的接口,允许通过函数实现接口。
- NewGroup 函数: 创建并注册一个新的缓存组。
- GetGroup 函数: 根据名称获取已注册的缓存组。
- Get 方法: 从缓存中获取数据,若未命中则加载数据。
- RegisterPeers 方法: 注册远程节点选择器。
- load 方法: 通过
singleflight加载数据,处理远程节点获取逻辑。 - populateCache 方法: 将加载的数据添加到主缓存中。
- getLocally 方法: 从本地数据源加载数据。
- getFromPeer 方法: 从远程节点获取数据。
设计思路:
- 命名空间管理: 通过
Group实现缓存的命名空间,支持多个独立的缓存组。 - 数据加载机制: 使用
Getter接口和GetterFunc类型灵活地定义数据加载逻辑。 - 分布式支持: 通过
PeerPicker和远程节点获取,实现跨节点的数据分布和获取。 - 请求合并: 利用
singleflight确保同一键的并发请求只执行一次加载操作,提升效率。 - 缓存层次: 结合本地缓存和远程节点缓存,提供多级缓存机制,提高数据获取效率。
d. HTTPPool 结构体
文件内容概述:
- HTTPPool 结构体: 实现了
PeerPicker接口,通过 HTTP 管理一组节点。 - NewHTTPPool 函数: 初始化一个
HTTPPool实例。 - Log 方法: 记录日志信息。
- ServeHTTP 方法: 处理 HTTP 请求,按照路径获取相应的缓存数据。
- Set 方法: 更新节点列表,构建一致性哈希环和对应的
httpGetter实例。 - PickPeer 方法: 根据键选择一个合适的远程节点。
设计思路:
- HTTP 通信: 通过实现
http.Handler接口,支持通过 HTTP 协议进行节点间通信和数据获取。 - 一致性哈希集成: 利用
consistenthash.Map实现节点选择,确保数据均匀分布和高可用性。 - 动态节点管理: 通过
Set方法动态更新节点列表,支持节点的添加和移除。 - 远程数据获取: 通过
httpGetter实现跨节点的数据获取,支持分布式缓存。
e. 接口定义
文件内容概述:
- PeerPicker 接口: 定位拥有特定键的节点。
- PeerGetter 接口: 从节点获取数据。
设计思路:
- 抽象化接口: 定义清晰的接口(
PeerPicker和PeerGetter),实现模块之间的解耦和灵活扩展。 - 可插拔组件: 通过接口设计,可以灵活替换或扩展节点选择和数据获取的实现方式。
整体设计思路总结
1. 高效的本地缓存:
- LRU 缓存策略: 通过
lru包实现高效的本地缓存,管理内存使用,提升缓存命中率。 - 线程安全: 使用互斥锁确保并发访问的安全性,避免数据竞争。
2. 分布式架构支持:
- 一致性哈希: 通过
consistenthash包实现数据在多个节点间的均匀分布,减少节点变动带来的影响。 - HTTP 通信: 通过
HTTPPool实现节点间的通信,支持跨节点的数据获取和分发。
3. 并发请求管理:
- SingleFlight 机制: 使用
singleflight包确保同一键的并发请求只执行一次数据加载操作,避免重复计算和资源浪费。
4. 灵活的数据加载机制:
- Getter 接口: 通过定义
Getter接口,允许用户自定义数据加载逻辑,适应不同的数据源。 - 扩展性: 通过接口和模块化设计,系统具备良好的扩展性,易于集成新的功能或替换现有实现。
5. 数据一致性和安全性:
- 不可变数据视图: 使用
ByteView确保缓存数据的不可变性,避免并发读写带来的数据不一致问题。 - 缓存层次: 结合本地缓存和远程节点缓存,提供多级缓存机制,提升数据获取效率和系统可靠性。
6. 日志和监控:
- 日志记录: 通过
HTTPPool的Log方法记录关键操作和请求,便于监控和调试系统行为。
使用流程概述
-
初始化缓存组:
- 使用
NewGroup创建一个新的缓存组,指定名称、最大缓存字节数和数据加载函数(实现Getter接口)。
- 使用
-
配置节点池:
- 创建
HTTPPool实例,指定当前节点的地址。 - 使用
Set方法注册所有节点地址,构建一致性哈希环。
- 创建
-
处理缓存请求:
- 当调用
Group.Get(key)时,首先尝试从本地缓存中获取数据。 - 若缓存未命中,通过
singleflight机制确保同一键的并发请求只加载一次数据。 - 根据一致性哈希选择对应的节点,尝试从远程节点获取数据。
- 若远程获取失败,则调用本地的
Getter函数加载数据,并将结果缓存。
- 当调用
-
分发和同步:
- 通过
HTTPPool实现节点间的数据同步和分发,确保数据在各个节点间的一致性和高可用性。
- 通过
缓存击穿与缓存穿透详解
在构建高性能的分布式缓存系统(如 Geecache)时,理解并解决缓存相关的问题是至关重要的。两种常见的问题是 缓存击穿(Cache Breakdown) 和 缓存穿透(Cache Penetration)。本文将详细介绍这两种问题的定义、区别,并通过具体的例子帮助您更好地理解它们。
一、基本定义
1. 缓存穿透(Cache Penetration)
定义:缓存穿透指的是查询一个既不在缓存中,也不在数据库中的数据。这类请求会绕过缓存,直接访问数据库,可能导致数据库压力骤增,甚至宕机。
典型场景:
- 攻击者通过构造大量不存在的请求,试图绕过缓存,直接攻击数据库。
- 用户错误地请求不存在的数据,导致频繁的数据库访问。
2. 缓存击穿(Cache Breakdown)
定义:缓存击穿发生在一个热点数据(高并发访问的键)在缓存中失效(如过期或被淘汰)时,大量的并发请求同时访问这个失效的数据,导致这些请求同时打到数据库,可能造成数据库压力过大。
典型场景:
- 某个热门商品的库存信息在缓存中过期,导致大量用户同时请求这个商品的库存,瞬间压垮数据库。
二、区别
| 特性 | 缓存穿透(Cache Penetration) | 缓存击穿(Cache Breakdown) |
|---|---|---|
| 原因 | 查询的数据既不在缓存中,也不在数据库中。 | 热点数据在缓存中失效,导致大量并发请求同时访问数据库。 |
| 影响 | 可能导致数据库压力骤增,甚至宕机。 | 可能导致数据库瞬间承受大量请求,影响性能和稳定性。 |
| 解决策略 | 使用布隆过滤器(Bloom Filter)、缓存空对象(Null Cache)等。 | 使用互斥锁(Mutex)、单次请求机制(如 singleflight)等。 |
三、具体例子
1. 缓存穿透的例子
场景:假设有一个用户查询系统,用户通过 userID 查询用户信息。如果某些 userID 不存在于数据库中,且这些请求会绕过缓存,直接访问数据库。
问题:大量不存在的 userID 请求会直接打到数据库,导致数据库压力增大。
代码示例:
// Getter 接口定义
type Getter interface {
Get(key string) ([]byte, error)
}
// 示例 Getter 实现,从数据库获取用户信息
type GetterFunc func(key string) ([]byte, error)
func (f GetterFunc) Get(key string) ([]byte, error) {
return f(key)
}
// Group.Get 方法
func (g *Group) Get(key string) (ByteView, error) {
if key == "" {
return ByteView{}, fmt.Errorf("key is required")
}
// 1. 尝试从本地缓存获取
if v, ok := g.mainCache.get(key); ok {
return v, nil
}
// 2. 缓存未命中,使用 singleflight 防止缓存击穿
value, err := g.loader.Do(key, func() (interface{}, error) {
// 尝试从远程节点获取
if g.peers != nil {
if peer, ok := g.peers.PickPeer(key); ok {
if value, err := g.getFromPeer(peer, key); err == nil {
return value, nil
}
}
}
// 从本地数据源获取
return g.getLocally(key)
})
if err != nil {
return ByteView{}, err
}
return value.(ByteView), nil
}
// 改进后的 Get 方法,加入缓存穿透的防护
func (g *Group) Get(key string) (ByteView, error) {
if key == "" {
return ByteView{}, fmt.Errorf("key is required")
}
// 1. 尝试从本地缓存获取
if v, ok := g.mainCache.get(key); ok {
return v, nil
}
// 2. 缓存未命中,使用 singleflight 防止缓存击穿
value, err := g.loader.Do(key, func() (interface{}, error) {
// 尝试从远程节点获取
if g.peers != nil {
if peer, ok := g.peers.PickPeer(key); ok {
if value, err := g.getFromPeer(peer, key); err == nil {
return value, nil
}
}
}
// 从本地数据源获取
data, err := g.getLocally(key)
if err != nil {
return nil, err
}
// 如果数据为空,将空对象添加到缓存,防止缓存穿透
if len(data.b) == 0 {
// 使用一个特殊的空对象标识
g.mainCache.add(key, ByteView{b: []byte{}})
} else {
// 正常添加到缓存
g.populateCache(key, data)
}
return data, nil
})
if err != nil {
return ByteView{}, err
}
// 检查是否是空对象
if len(value.(ByteView).b) == 0 {
return ByteView{}, fmt.Errorf("no such key: %s", key)
}
return value.(ByteView), nil
}
解决策略:
-
缓存空对象(Null Cache):
- 当查询的数据不存在时,将一个特殊的空对象(如空字节切片)缓存起来。
- 这样后续的相同请求会命中缓存中的空对象,避免再次访问数据库。
-
布隆过滤器(Bloom Filter):
- 使用布隆过滤器预先存储所有可能存在的
userID。 - 查询时,先在布隆过滤器中检查
userID是否存在,如果不存在,直接返回错误,避免访问数据库。
- 使用布隆过滤器预先存储所有可能存在的
示例代码:缓存空对象
如上代码所示,当 getLocally 返回的数据为空时,将一个空的 ByteView 添加到缓存中。
2. 缓存击穿的例子
场景:某个热门商品的库存信息在缓存中失效(如过期),此时有大量用户同时请求这个商品的库存,导致所有请求同时打到数据库,可能造成数据库压力过大。
问题:高并发下,失效的热点键导致大量并发请求打到数据库,影响系统性能。
代码示例:
// Group.Get 方法
func (g *Group) Get(key string) (ByteView, error) {
if key == "" {
return ByteView{}, fmt.Errorf("key is required")
}
// 1. 尝试从本地缓存获取
if v, ok := g.mainCache.get(key); ok {
return v, nil
}
// 2. 缓存未命中,使用 singleflight 防止缓存击穿
value, err := g.loader.Do(key, func() (interface{}, error) {
// 尝试从远程节点获取
if g.peers != nil {
if peer, ok := g.peers.PickPeer(key); ok {
if value, err := g.getFromPeer(peer, key); err == nil {
return value, nil
}
}
}
// 从本地数据源获取
return g.getLocally(key)
})
if err != nil {
return ByteView{}, err
}
return value.(ByteView), nil
}
解释:
- 当缓存中的
key失效时,多个并发请求会同时进入Group.Get方法。 singleflight.Group.Do会确保对于相同的key,只有一个请求会执行getLocally,其他请求会等待该请求完成并共享结果。- 这样,只有一个请求会打到数据库,其余请求会等待并从缓存中获取结果,避免了缓存击穿。
完整实现示例:
结合之前的防护措施,以下是完整的 Group.Get 方法,既防护了缓存穿透,又防护了缓存击穿。
func (g *Group) Get(key string) (ByteView, error) {
if key == "" {
return ByteView{}, fmt.Errorf("key is required")
}
// 1. 尝试从本地缓存获取
if v, ok := g.mainCache.get(key); ok {
// 检查是否为空对象,避免缓存穿透
if len(v.b) == 0 {
return ByteView{}, fmt.Errorf("no such key: %s", key)
}
return v, nil
}
// 2. 缓存未命中,使用 singleflight 防止缓存击穿
value, err := g.loader.Do(key, func() (interface{}, error) {
// 尝试从远程节点获取
if g.peers != nil {
if peer, ok := g.peers.PickPeer(key); ok {
if value, err := g.getFromPeer(peer, key); err == nil {
return value, nil
}
}
}
// 从本地数据源获取
data, err := g.getLocally(key)
if err != nil {
return nil, err
}
// 如果数据为空,将空对象添加到缓存,防止缓存穿透
if len(data.b) == 0 {
// 使用一个特殊的空对象标识
g.mainCache.add(key, ByteView{b: []byte{}})
} else {
// 正常添加到缓存
g.populateCache(key, data)
}
return data, nil
})
if err != nil {
return ByteView{}, err
}
// 检查是否是空对象
if len(value.(ByteView).b) == 0 {
return ByteView{}, fmt.Errorf("no such key: %s", key)
}
return value.(ByteView), nil
}
解释:
- 缓存击穿防护:通过
singleflight.Group.Do,确保对于相同的key,只有一个请求会执行getLocally,其他请求等待该请求完成并共享结果。 - 缓存穿透防护:如果
getLocally返回的数据为空,将一个空对象添加到缓存中,避免后续的相同请求再次打到数据库。
四、总结
1. 缓存穿透
- 问题:大量不存在的数据请求绕过缓存,直接打到数据库,导致数据库压力增大。
- 解决策略:
- 缓存空对象:将不存在的数据以空对象形式缓存,防止后续请求重复访问数据库。
- 布隆过滤器:使用布隆过滤器预先过滤不存在的
key,避免无效请求打到数据库。
2. 缓存击穿
- 问题:热点数据在缓存中失效时,大量并发请求同时访问数据库,可能导致数据库压力过大。
- 解决策略:
- 单次请求机制:使用
singleflight等机制,确保对于相同的key,只有一个请求会访问数据库,其他请求等待结果。 - 互斥锁:在加载数据时加锁,确保只有一个 goroutine 执行数据加载操作。
- 单次请求机制:使用
3. 综合防护
在实际应用中,结合使用多种策略可以更有效地防护缓存穿透和击穿。例如:
- 缓存空对象 结合 单次请求机制:既防止不存在的
key频繁访问数据库,又防止热点数据失效时的大量并发请求。 - 布隆过滤器 与 缓存穿透防护:提前过滤不存在的
key,进一步降低数据库压力。
热点键详解
在分布式缓存系统(如 Geecache)中,热点键(Hot Keys) 是指那些被频繁访问的键。这些键由于其高访问频率,可能会成为系统的瓶颈,导致性能下降甚至系统故障。理解热点键的概念、识别其问题及采取相应的解决策略,对于构建高性能和高可用性的缓存系统至关重要。
一、热点键的定义
热点键(Hot Keys) 是指在缓存系统中被大量请求访问的特定键。这些键可能由于以下原因成为热点:
- 高频访问:某些数据因业务需求或用户行为被频繁访问。
- 资源消耗大:对应的数据体积较大,访问时消耗较多资源。
- 有限缓存资源:缓存空间有限,热点键可能占用大量缓存资源,影响其他键的缓存命中率。
示例
假设在一个电商平台中,某个热门商品的库存信息(键为 product:12345:stock)因为促销活动而被大量用户同时查询和更新,这个键就成为了热点键。
二、热点键带来的问题
1. 缓存压力过大
热点键由于被频繁访问,会导致缓存系统承受巨大的读写压力。如果缓存无法及时处理这些请求,可能导致请求延迟增加,甚至缓存系统崩溃。
2. 数据库压力骤增
如果热点键的数据在缓存中失效(例如过期或被淘汰),大量并发请求会同时打到数据库,可能导致数据库性能下降或宕机。
3. 资源不均衡
热点键占用了大量缓存资源,可能导致其他键的缓存命中率下降,影响系统的整体性能和响应速度。
三、热点键的识别与监控
1. 访问统计
通过监控工具(如 Prometheus、Grafana)统计每个键的访问频率,识别出访问量异常高的键。
2. 性能指标
监控缓存系统的响应时间、吞吐量、错误率等指标,发现因热点键导致的性能异常。
3. 日志分析
分析应用和缓存系统的日志,识别出频繁访问的键和可能的异常访问模式。
四、解决热点键问题的策略
1. 合理设置缓存过期时间
为热点键设置较长的过期时间,减少频繁的缓存失效和重新加载请求。然而,这需要权衡数据的新鲜度和缓存命中率。
2. 使用互斥锁(Mutex)或单次请求机制(SingleFlight)
在加载热点键数据时,使用互斥锁或类似 singleflight 的机制,确保同一时间只有一个请求加载数据,其他请求等待结果,避免大量并发请求打到数据库。
示例代码:使用 singleflight 处理热点键
// 假设这是 Geecache 中的 Group 结构体
type Group struct {
name string
getter Getter
mainCache cache
peers PeerPicker
loader *singleflight.Group
}
// Get 方法
func (g *Group) Get(key string) (ByteView, error) {
if key == "" {
return ByteView{}, fmt.Errorf("key is required")
}
// 1. 尝试从本地缓存获取
if v, ok := g.mainCache.get(key); ok {
// 检查是否为空对象,避免缓存穿透
if len(v.b) == 0 {
return ByteView{}, fmt.Errorf("no such key: %s", key)
}
return v, nil
}
// 2. 缓存未命中,使用 singleflight 防止缓存击穿
value, err := g.loader.Do(key, func() (interface{}, error) {
// 尝试从远程节点获取
if g.peers != nil {
if peer, ok := g.peers.PickPeer(key); ok {
if value, err := g.getFromPeer(peer, key); err == nil {
return value, nil
}
}
}
// 从本地数据源获取
data, err := g.getLocally(key)
if err != nil {
return nil, err
}
// 如果数据为空,将空对象添加到缓存,防止缓存穿透
if len(data.b) == 0 {
g.mainCache.add(key, ByteView{b: []byte{}})
} else {
// 正常添加到缓存
g.populateCache(key, data)
}
return data, nil
})
if err != nil {
return ByteView{}, err
}
// 检查是否是空对象
if len(value.(ByteView).b) == 0 {
return ByteView{}, fmt.Errorf("no such key: %s", key)
}
return value.(ByteView), nil
}
3. 分片(Sharding)
将热点键的数据分布到不同的缓存实例或服务器上,减少单个缓存实例的压力。
策略:
- 按键哈希分片:根据键的哈希值,将键分配到不同的缓存节点。
- 按数据类型分片:将不同类型的数据分配到不同的缓存池中。
4. 缓存预热
在系统启动或预期的高峰期之前,提前将热点键的数据加载到缓存中,避免高峰期大量请求直接打到数据库。
实现方法:
- 启动脚本:编写启动脚本,在系统启动时加载热点键的数据。
- 定时任务:设置定时任务,定期刷新热点键的数据。
5. 缓存淘汰策略优化
针对热点键,使用特殊的缓存淘汰策略,确保热点键不会被频繁淘汰,保持其高命中率。
示例:
- 永不过期:对于特别重要的热点键,设置为永不过期,手动管理其缓存生命周期。
- 自定义淘汰策略:根据访问频率动态调整缓存淘汰策略,优先保留热点键。
6. 数据复制与多级缓存
将热点键的数据复制到多个缓存实例,甚至部署多级缓存(如本地缓存与分布式缓存结合),提高数据的可用性和访问速度。
示例:
- 本地缓存 + 分布式缓存:在应用服务器本地缓存热点键的数据,同时在分布式缓存中保持副本,减少访问延迟和压力。
- 多级分布式缓存:部署多个分布式缓存层,热点键的数据分布在不同层级,优化访问性能。
7. 限流与降级
对热点键的请求进行限流,防止过载,同时在系统压力过大时,进行降级处理(如返回默认值或错误提示)。
实现方法:
- 令牌桶算法:使用令牌桶算法限制单位时间内的请求数。
- 熔断机制:在检测到系统压力过大时,暂时停止对热点键的请求,保护系统稳定性。
8. 使用布隆过滤器(Bloom Filter)
结合缓存穿透防护,通过布隆过滤器预先判断键是否存在,避免对热点键的无效请求打到缓存和数据库。
示例:
- 在请求处理流程中,先查询布隆过滤器,如果键不存在,直接返回错误,避免进一步的处理。
五、实际案例分析
案例 1:电商平台的热门商品库存
场景:在电商平台的促销活动期间,某个热门商品的库存信息被大量用户同时查询和更新。
问题:
- 缓存中的库存键(如
product:12345:stock)因为高频访问,导致缓存系统负载过大。 - 如果库存信息在缓存中失效,大量请求同时打到数据库,可能导致库存系统崩溃。
解决方案:
-
使用
singleflight机制:- 确保对于
product:12345:stock的数据加载操作只有一个请求打到数据库,其他请求等待结果。
- 确保对于
-
设置较长的缓存过期时间:
- 对于库存信息这种变化频率较低的数据,设置较长的过期时间,减少频繁的缓存失效和数据加载。
-
数据复制:
- 将库存信息复制到多个缓存节点,分散缓存压力。
-
限流与降级:
- 对库存查询请求进行限流,当系统压力过大时,返回库存信息的简化版本或提示稍后再试。
代码实现示例:
// 在 Group.Get 方法中,使用 singleflight 防止缓存击穿
func (g *Group) Get(key string) (ByteView, error) {
if key == "" {
return ByteView{}, fmt.Errorf("key is required")
}
// 尝试从本地缓存获取
if v, ok := g.mainCache.get(key); ok {
// 检查是否为空对象,避免缓存穿透
if len(v.b) == 0 {
return ByteView{}, fmt.Errorf("no such key: %s", key)
}
return v, nil
}
// 使用 singleflight 防止缓存击穿
value, err := g.loader.Do(key, func() (interface{}, error) {
// 尝试从远程节点获取
if g.peers != nil {
if peer, ok := g.peers.PickPeer(key); ok {
if value, err := g.getFromPeer(peer, key); err == nil {
return value, nil
}
}
}
// 从本地数据源获取
data, err := g.getLocally(key)
if err != nil {
return nil, err
}
// 如果数据为空,将空对象添加到缓存,防止缓存穿透
if len(data.b) == 0 {
g.mainCache.add(key, ByteView{b: []byte{}})
} else {
// 正常添加到缓存
g.populateCache(key, data)
}
return data, nil
})
if err != nil {
return ByteView{}, err
}
// 检查是否是空对象
if len(value.(ByteView).b) == 0 {
return ByteView{}, fmt.Errorf("no such key: %s", key)
}
return value.(ByteView), nil
}
案例 2:社交平台的热门帖子点赞
场景:在社交平台中,一个热门帖子的点赞数被大量用户同时更新和查询。
问题:
- 点赞键(如
post:67890:likes)频繁被更新,导致缓存系统承受高并发写入压力。 - 如果缓存中的点赞键失效,导致大量并发请求打到数据库,影响数据库性能。
解决方案:
-
使用乐观锁或原子操作:
- 在更新点赞数时,使用原子操作(如 Redis 的
INCR命令)避免竞争条件。
- 在更新点赞数时,使用原子操作(如 Redis 的
-
分布式锁:
- 使用分布式锁(如基于 Redis 的 Redlock)控制对点赞键的并发访问,确保数据一致性。
-
数据分片:
- 将点赞数分片到不同的缓存节点,分散写入压力。
-
缓存预热:
- 在活动开始前,预先加载热门帖子的点赞数到缓存中,避免高峰期的加载压力。
代码实现示例:
// 使用原子操作更新点赞数
func (g *Group) IncrementLikes(key string) error {
// 尝试从缓存中获取当前点赞数
if v, ok := g.mainCache.get(key); ok {
// 使用原子操作更新缓存中的点赞数
newLikes := atomic.AddInt32((*int32)(unsafe.Pointer(&v.b[0])), 1)
g.mainCache.add(key, ByteView{b: []byte{byte(newLikes)}})
return nil
}
// 如果缓存未命中,使用 singleflight 加载数据
_, err := g.loader.Do(key, func() (interface{}, error) {
// 从数据库加载当前点赞数
likes, err := g.getLocally(key)
if err != nil {
return nil, err
}
// 将点赞数添加到缓存
g.populateCache(key, likes)
return likes, nil
})
if err != nil {
return err
}
// 递增点赞数
return g.IncrementLikes(key)
}