Kafka--关于broker的夺命连环问
目录
1、zk在kafka集群中有何作用
2、简述kafka集群中的Leader选举机制
3、kafka是如何处理数据乱序问题的。
4、kafka中节点如何服役和退役
4.1 服役新节点
1)新节点准备
2)执行负载均衡操作
4.2 退役旧节点
5、Kafka中Leader挂了,Follower挂了,然后再启动,数据如何同步?
6、kafka中初始化的时候Leader选举有一定的规律,如何打破这个规律呢?
7、kafka是如何做到高效读写
8、Kafka集群中数据的存储是按照什么方式存储的?
9、简述kafka中的数据清理策略。
10、kafka中是如何快速定位到一个offset的。
1、zk在kafka集群中有何作用
在zookeeper中存储着kafka集群中的相关信息:
(1)kafka/brokers/ids:{0,1,2} 记录集群中有哪些服务器
(2)kafka/brokers/topics/first/partition/0/state:{Leader:0,isr:{0,1,2}} 记录集群中不同分区谁是Leader以及可用的服务器
(3)kafka/controller {"borkerid:0"}辅助Leader的选举
图解:

2、简述kafka集群中的Leader选举机制
总结:
集群启动后,集群中的broker会在zk中进行注册,谁先进行注册,那么先注册的broker中的Controller就会被选举为Controller Leader,负责监听broker节点的变化以及Leader的选举,随后controller将节点信息上传到zk中,其他的controller从zk中同步相关信息。当broker中的Leader挂掉时,controller会监听到节点的变化,从而获取isr,从isr存活的副本中,按照AR中的排序优先选择靠前的副本成为新的Leader,并及时更新ISR。
图解:

3、kafka是如何处理数据乱序问题的。
开启幂等性
4、kafka中节点如何服役和退役
服役:执行负载均衡操作(1.创建均衡主题 2.生成副本均衡计划(设置--broker-list "0,1,2,3") 3.创建副本存储计划(将未来分区策略放在一个json文件中) 4.执行副本存储计划(运行json文件))
退役:同上 在第二步2.生成副本均衡计划中设置--broker-list "0,1,2"
4.1 服役新节点
1)新节点准备
(1)关闭 bigdata03,进行一个快照,并右键执行克隆操作。
(2)开启 bigdata04,并修改 IP 地址。
vi /etc/sysconfig/network-scripts/ifcfg-ens33
修改完记得重启网卡:
systemctl restart network(3)在 bigdata04 上,修改主机名称为 bigdata04。
hostname bigdata04 # 临时修改[root@bigdata04 ~]# vim /etc/hostname
bigdata04
还要记得修改 /etc/hosts文件,并进行同步
修改bigdata01的hosts 文件,修改完之后,记得同步一下
192.168.52.11 bigdata01
192.168.52.12 bigdata03
192.168.52.13 bigdata02
192.168.52.14 bigdata04
xsync.sh /etc/hosts
scp -r /etc/hosts root@bigdata04:/etc/(4)重新启动 bigdata03、bigdata04。
(5)修改 bigdata04 中 kafka 的 broker.id 为 3。
进入bigdata04的kafka中,修改里面的配置文件 config/server.properties(6)删除 bigdata04 中 kafka 下的 datas 和 logs。
rm -rf datas/* logs/*
(7)启动 bigdata01、bigdata02、bigdata03 上的 kafka 集群。
先启动zk集群
xcall.sh zkServer.sh stop
xcall.sh zkServer.sh start启动kafka集群(只能启动三台)
kf.sh start (8)单独启动 bigdata04 中的 kafka。
bin/kafka-server-start.sh -daemon ./config/server.properties
查看kafka集群first主题的详情:
bin/kafka-topics.sh --bootstrap-server bigdata01:9092 --topic first --describe
发现副本数并没有增加。
由于我之前创建first这个主题的时候只有一个副本,不是三个副本,所以呢,演示效果不佳。
kafka-topics.sh --bootstrap-server bigdata01:9092 --topic third --create --partitions 3 --replication-factor 3

2)执行负载均衡操作
(1)创建一个要均衡的主题
创建一个文件:vi topics-to-move.json
写上如下代码,如果多个topic 可以使用,分隔
{
"topics": [
{"topic": "third"}
],
"version": 1
}(2)生成一个负载均衡的计划
在创建的时候,记得启动bigdata04节点,否则计划中还是没有bigdata04
bin/kafka-reassign-partitions.sh --bootstrap-server bigdata01:9092 --topics-to-move-json-file topics-to-move.json --broker-list "0,1,2,3" --generate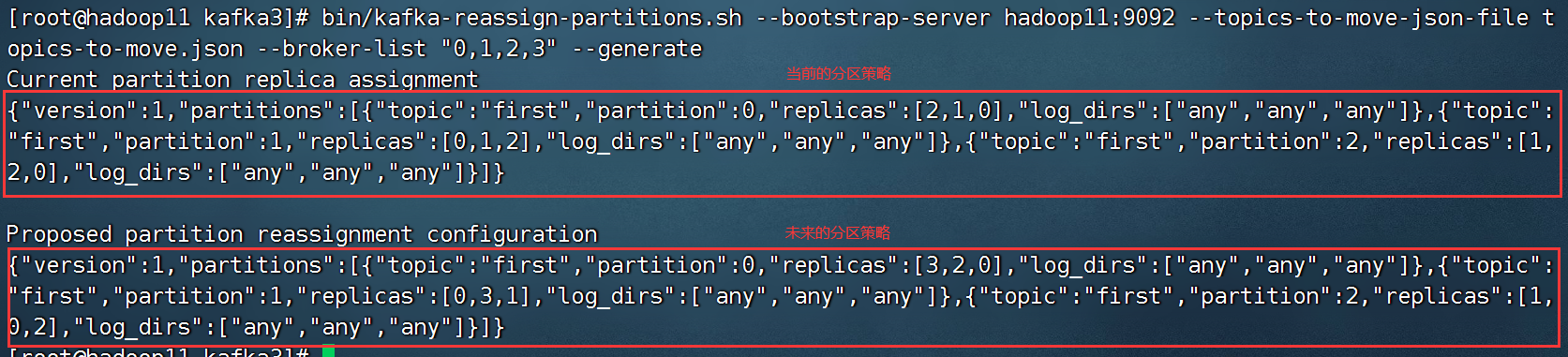
未来的分区策略拷贝一份:
{"version":1,"partitions":[{"topic":"abc","partition":0,"replicas":[2,0,1],"log_dirs":["any","any","any"]},{"topic":"abc","partition":1,"replicas":[3,1,2],"log_dirs":["any","any","any"]},{"topic":"abc","partition":2,"replicas":[0,2,3],"log_dirs":["any","any","any"]}]}(3)创建副本存储计划(所有副本存储在 broker0、broker1、broker2、broker3 中)。
vi increase-replication-factor.json{"version":1,"partitions":[{"topic":"first","partition":0,"replicas":[3,2,0],"log_dirs":["any","any","any"]},{"topic":"first","partition":1,"replicas":[0,3,1],"log_dirs":["any","any","any"]},{"topic":"first","partition":2,"replicas":[1,0,2],"log_dirs":["any","any","any"]}]}
以上这个内容来自于第二步的执行计划。(4)执行副本存储计划。
bin/kafka-reassign-partitions.sh --bootstrap-server bigdata01:9092 --reassignment-json-file increase-replication-factor.json --execute
(5)验证副本存储计划。
bin/kafka-reassign-partitions.sh --bootstrap-server bigdata01:9092 --reassignment-json-file increase-replication-factor.json --verify
如果不相信添加成功,可以查看first节点的详情:

4.2 退役旧节点
1)执行负载均衡操作
先按照退役一台节点,生成执行计划,然后按照服役时操作流程执行负载均衡。
(1)创建一个要均衡的主题
kafka下添加文件:vim topics-to-move.json
添加如下内容:
{
"topics": [
{"topic": "abc"}
],
"version": 1
}(2)创建执行计划。
bin/kafka-reassign-partitions.sh --bootstrap-server bigdata01:9092 --topics-to-move-json-file topics-to-move.json --broker-list "0,1,2" --generate
(3)创建副本存储计划(所有副本存储在 broker0、broker1、broker2 中)。
添加文件: vi increase-replication-factor.json
添加如下代码:
{"version":1,"partitions":[{"topic":"first","partition":0,"replicas":[0,2,1],"log_dirs":["any","any","any"]},{"topic":"first","partition":1,"replicas":[1,0,2],"log_dirs":["any","any","any"]},{"topic":"first","partition":2,"replicas":[2,1,0],"log_dirs":["any","any","any"]}]}(4)执行副本存储计划
bin/kafka-reassign-partitions.sh --bootstrap-server bigdata01:9092 --reassignment-json-file increase-replication-factor.json --execute(5)验证副本存储计划。
bin/kafka-reassign-partitions.sh --bootstrap-server hadoop11:9092 --reassignment-json-file increase-replication-factor.json --verify

2)执行停止命令
在 bigdata04上执行停止命令即可。
bin/kafka-server-stop.sh
5、Kafka中Leader挂了,Follower挂了,然后再启动,数据如何同步?
总结:
follower故障:
当follower发生故障时,会被临时踢出ISR队列,此时的Leader和其他的follower会继续接收信息。当follower恢复后,会读取磁盘中记录的上次的HW,并将logs文件中高于HW的部分全部截掉,从HW开始从Leader中同步信息。当该follower中的LEO大于等于partition中的HW时,又重新加入ISR队列。
Leader故障:
Leader故障后,会从ISR中重新选举出新的Leader。为了保证数据的一致性,follower会从logs文件中把高于Leader的部分全部截掉,然后重新从Leader中同步信息。
详解:

LEO演示-- 每一个副本最后的偏移量offset + 1

HW(高水位线 High Water) 演示:所有副本中,最小的LEO


由于数据同步的时候先进入Leader,随后同步给Follower,假如Follower挂掉了,Leader和其他的Follower 继续往前存储数据,挂掉的节点从ISR集合中剔除,此时挂掉的Follower又重启了,它会先从上一次挂掉的节点的HW开始同步数据,直到追上最后一个Follower为止,此时会重新回归ISR。

6、kafka中初始化的时候Leader选举有一定的规律,如何打破这个规律呢?
简述:可以通过创建副本计划(编写json文件),指定副本在broker中的存储位置,然后执行副本计划(运行json文件),打破Leader的选举规律。
手动调整分区副本存储的步骤如下:
(1)创建一个新的 topic,名称为 three。
bin/kafka-topics.sh --bootstrap-server bigdata01:9092 --create --partitions 4 --replication-factor 2 --topic three
(2)查看分区副本存储情况。
bin/kafka-topics.sh --bootstrap-server bigdata01:9092 --describe --topic three
(3)创建副本存储计划(所有副本都指定存储在 broker0、broker1 中)。
vi increase-replication-factor.json
输入如下内容:
{
"version":1,
"partitions":[{"topic":"three","partition":0,"replicas":[0,1]},
{"topic":"three","partition":1,"replicas":[0,1]},
{"topic":"three","partition":2,"replicas":[1,0]},
{"topic":"three","partition":3,"replicas":[1,0]}]
}(4)执行副本存储计划。
屁股决定脑袋
bin/kafka-reassign-partitions.sh --bootstrap-server bigdata01:9092 --reassignment-json-file increase-replication-factor.json --execute
(5)验证副本存储计划。
bin/kafka-reassign-partitions.sh -- bootstrap-server bigdata01:9092 --reassignment-json-file increase-replication-factor.json --verify
(6)查看分区副本存储情况
bin/kafka-topics.sh --bootstrap-server bigdata01:9092 --describe --topic three

7、kafka是如何做到高效读写
1)Kafka 本身是分布式集群,可以采用分区技术,并行度高
2)读数据采用稀疏索引,可以快速定位要消费的数据。(mysql中索引多了之后,写入速度就慢了)
3)顺序写磁盘
Kafka 的 producer 生产数据,要写入到 log 文件中,写的过程是一直追加到文件末端, 为顺序写。官网有数据表明,同样的磁盘,顺序写能到 600M/s,而随机写只有 100K/s。这与磁盘的机械机构有关,顺序写之所以快,是因为其省去了大量磁头寻址的时间。
4)页缓存 + 零拷贝技术
零拷贝:Kafka的数据加工处理操作交由Kafka生产者和Kafka消费者处理。Kafka Broker应用层不关心存储的数据,所以就不用 走应用层,传输效率高
PageCache页缓存:Kafka重度依赖底层操作系统提供的PageCache功 能。当上层有写操作时,操作系统只是将数据写入 PageCache。当读操作发生时,先从PageCache中查找,如果找不到,再去磁盘中读取。实际上PageCache是把尽可能多的空闲内存都当做了磁盘缓存来使用

8、Kafka集群中数据的存储是按照什么方式存储的?
总结:
Topic是逻辑概念,partition是物理概念,每一partition对应一个log(日志文件),该log文件中存储的就是producer生产的数据。Prodecer生产的数据会被不断地追加写入到log文件的末尾,为了防止log文件过大而导致数据定位效率低下,kafka采取了分片和索引的机制,将每个partition分为多个segment。每个segment包括:".index"文件、".log"文件、".timeindex"文件,这些文件位于一个文件夹下面,该文件夹的明明规则为:topic名称+分区序号。
图解:
9、简述kafka中的数据清理策略。
1)delete 日志删除:将过期数据删除
log.cleanup.policy = delete 所有数据启用删除策略
(1)基于时间:默认打开。以 segment 中所有记录中的最大时间戳作为该文件时间戳。
(2)基于大小:默认关闭。超过设置的所有日志总大小,删除最早的 segment。
log.retention.bytes,默认等于-1,表示无穷大。
思考:如果一个 segment 中有一部分数据过期,一部分没有过期,怎么处理?

2)compact 日志压缩(合并的意思,不是真的压缩)
compact日志压缩:对于相同key的不同value值,只保留最后一个版本。
log.cleanup.policy = compact 所有数据启用压缩策略

压缩后的offset可能是不连续的,比如上图中没有6,当从这些offset消费消息时,将会拿到比这个offset大的offset对应的消息,实际上会拿到offset为7的消息,并从这个位置开始消费。
这种策略只适合特殊场景,比如消息的key是用户ID,value是用户的资料,通过这种压缩策略,整个消息集里就保存了所有用户最新的资料。
比如:张三 去年18岁,今年19岁,这种场景下可以进行压缩。
10、kafka中是如何快速定位到一个offset的。
总结:
首先根据目标offset定位segment文件,找到小于等于目标offset的最大offset对应的索引,定位到log文件,向下遍历找到目标record。
图解:
