Matlab使用深度网络设计器为迁移学习准备网络
迁移学习通过对预训练网络进行微调,使深度学习模型能在少量数据下快速适应新任务,类似于“举一反三”,而不需要从头训练。本文使用matlab自带的深度网络设计器,可以便捷地修改预训练网络进行迁移学习,通过对预训练网络的最后一层进行解锁,调高学习率,使新层中的学习速度快于迁移层的学习速度,即可输入新数据,完成迁移学习的训练。
在实际工程应用中,构建并训练一个大规模的卷积神经网络是比较复杂的,需要大量的数据以及高性能的硬件。迁移学习则是“另辟蹊径”,将训练好的典型的网络稍加改进,用少量的数据进行训练并加以应用,将一个预先训练好的网络作为学习新任务的起点。利用迁移学习对网络进行微调,通常比从头开始训练一个随机初始化权重的网络要快得多、容易得多。使用较少数量的训练图像,就能将学习到的特征快速迁移到新任务中。
1.使用的数据
本文使用的数据集为 MathWorks Merch 数据集,这是包含 75 幅 MathWorks 商品图像的小型数据集,这些商品分属五个不同类(瓶盖、魔方、扑克牌、螺丝刀和手电筒)。数据的排列使得图像位于对应于这五个类的子文件夹中。
folderName = "MerchData";
unzip("MerchData.zip",folderName);
创建一个图像数据存储(Datastore),通过图像数据存储可以存储大图像数据集合,包括无法放入内存的数据,并在神经网络的训练过程中高效分批读取图像。对图像文件夹建立子文件夹,使用imageDatastore,可以将子文件夹名称转换为图像标签。
imds = imageDatastore(folderName, ...
IncludeSubfolders=true, ...
LabelSource="foldernames");
显示一些示例图像:
numImages = numel(imds.Labels);
idx = randperm(numImages,16);
I = imtile(imds,Frames=idx);
figure
imshow(I)
2.提取数据
提取类名称和类数目:
classNames = categories(imds.Labels);
numClasses = numel(classNames)
numClasses = 5
将数据划分为训练、验证和测试数据集。将 70% 的图像用于训练,15% 的图像用于验证,15% 的图像用于测试。splitEachLabel 函数将图像数据存储拆分为两个新数据存储。
[imdsTrain,imdsValidation,imdsTest] = splitEachLabel(imds,0.7,0.15,0.15,"randomized");
3.选择预训练网络
3.1 深度网络设计器
从命令行打开深度网络设计器App:
deepNetworkDesigner
深度网络设计器提供一些精选的预训练图像分类网络,这些网络已学习适用于各种图像的丰富特征表示。如果您的图像与最初用于训练网络的图像相似,迁移学习效果最好。如果您的训练图像是像 ImageNet 数据库中那样的自然图像,则任一预训练网络都合适。了解有哪些预训练深度神经网络,请参阅预训练的深度神经网络。
如果数据与 ImageNet 数据相差很大(例如,如果您有很小的图像、频谱图或非图像数据),训练新网络可能效果更好。选择SqueezeNet网络:

3.2 浏览网络
深度网络设计器在设计器窗格中显示整个网络的缩小视图。

选择图像输入层 'input',可以看到该网络的输入大小为 227×227×3 像素。

将输入大小保存在变量 inputSize 中:
inputSize = [227 227 3];4.准备要训练的网络
要使用预训练网络进行迁移学习,更改类的数量以匹配新数据集。首先,找到网络中的最后一个可学习层。对于 SqueezeNet,最后一个可学习层是最后一个卷积层,'conv10'。选择 'conv10' 层。在属性窗格的底部,点击解锁层。在出现的警告对话框中,点击仍要解锁,这将解锁层属性,以便使其适应新任务。
在 R2023b 之前:要使网络适应新数据,替换层而不是解锁层。在新的卷积二维层中,将 FilterSize 设置为 [1 1]。
NumFilters 属性定义用于分类问题的类的数量,将 NumFilters 更改为新数据中的类数量,此示例中为 5。
通过将 WeightLearnRateFactor 和 BiasLearnRateFactor 设置为 10 来更改学习率,使新层中的学习速度快于迁移层的学习速度。

要检查网络是否准备好进行训练,点击分析按钮,深度学习网络分析器报告零错误或警告,说明网络已准备就绪,可以开始进行训练。
要导出网络,请点击导出,该 App 将网络保存在变量 net_1 中。

数据存储中图像的大小可以不同,要自动调整训练图像的大小,请使用增强的图像数据存储。数据增强还有助于防止网络过拟合和记忆训练图像的具体细节。指定要对训练图像额外执行的这些增强操作:沿垂直轴随机翻转训练图像,以及在水平和垂直方向上随机平移训练图像最多 30 个像素。
pixelRange = [-30 30];
imageAugmenter = imageDataAugmenter( ...
RandXReflection=true, ...
RandXTranslation=pixelRange, ...
RandYTranslation=pixelRange);
augimdsTrain = augmentedImageDatastore(inputSize(1:2),imdsTrain, ...
DataAugmentation=imageAugmenter);
对于验证集和测试集,只调整图像大小,而不进行其他预处理操作。
augimdsValidation = augmentedImageDatastore(inputSize(1:2),imdsValidation);
augimdsTest = augmentedImageDatastore(inputSize(1:2),imdsTest);
5.指定训练选项
指定训练选项,在选项中进行选择需要经验分析。
-
使用 Adam 优化器进行训练。
-
将初始学习率设置为较小的值以减慢迁移的层中的学习速度。
-
指定少量轮数。一轮训练是对整个训练数据集的一个完整训练周期。对于迁移学习,所需的训练轮数相对较少。
-
指定验证数据和验证频率,以便每经过一轮训练就计算一次基于验证数据的准确度。
-
指定mini batch size,即每次迭代中使用多少个图像。为了确保在每轮训练中都使用整个数据集,请设置mini batch size以均分训练样本的数量。
-
在图中显示训练进度并监控准确度度量。
-
禁用详尽输出。
options = trainingOptions("adam", ...
InitialLearnRate=0.0001, ...
MaxEpochs=8, ...
ValidationData=imdsValidation, ...
ValidationFrequency=5, ...
MiniBatchSize=11, ...
Plots="training-progress", ...
Metrics="accuracy", ...
Verbose=false);
6.训练和测试网络
使用 trainnet 函数训练神经网络,对于分类任务,损失函数使用交叉熵损失。
net = trainnet(imdsTrain,net_1,"crossentropy",options);
对测试图像进行分类,要使用多个观测值进行预测,使用 minibatchpredict 函数;要将预测分数转换为标签,使用 scores2label 函数。
YTest = minibatchpredict(net,augimdsTest);
YTest = scores2label(YTest,classNames);
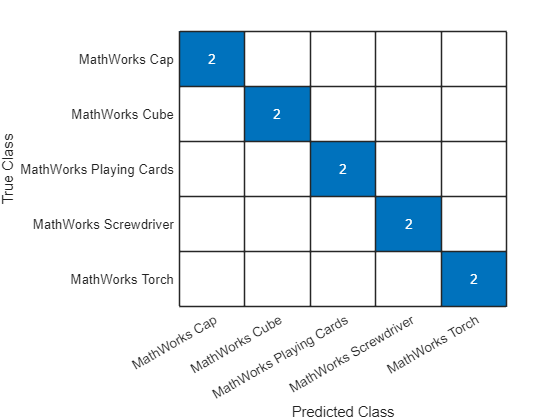
在混淆图中可视化分类准确度:
TTest = imdsTest.Labels;
figure
confusionchart(TTest,YTest);
7.使用新数据进行预测
对一个图像进行分类,从 JPEG 文件中读取一个图像,调整其大小,并将其转换为单精度数据类型。
im = imread("MerchDataTest.jpg");
im = imresize(im,inputSize(1:2));
X = single(im);
对图像进行分类,要使用单个观测值进行预测,使用 predict 函数;要使用 GPU,先将数据转换为 gpuArray。
if canUseGPU
X = gpuArray(X);
end
scores = predict(net,X);
[label,score] = scores2label(scores,classNames);
显示具有预测标签和对应分数的图像:
figure
imshow(im)
title(string(label) + " (Score: " + gather(score) + ")")