NLP论文速读(微软出品)|使用GPT-4进行指令微调(Instruction Tuning with GPT-4)
论文速读|Instruction Tuning with GPT-4
论文信息:

简介:
这篇论文试图解决的问题是如何通过指令调优(instruction-tuning)提升大型语言模型(LLMs)在执行新任务时的零样本(zero-shot)能力。具体来说,它探讨了使用机器生成的指令跟随数据来微调大型语言模型,以提高其在没有人类编写指令的情况下完成新任务的能力。本文的动机源于先前研究表明,通过指令调优可以显著提升LLMs在新任务上的零样本性能。然而,现有的方法依赖于人类标注的提示和反馈,或者使用公开基准和数据集进行监督微调,这些方法成本较高且可能不够高效。因此,研究者们探索了一种称为自我指令调优(Self-Instruct tuning)的方法,该方法通过学习由最先进的指令调优教师模型生成的指令跟随数据来对齐LLMs与人类意图。本文的动机是利用最新的GPT-4模型生成的指令跟随数据来进一步提高开源LLMs的性能。
论文方法:

本文提出了首次使用GPT-4作为教师模型进行自我指令调优的尝试。研究者们生成了52K的英文和中文指令跟随数据,并基于这些数据开发了指令调优的LLaMA模型和奖励模型。为了全面评估指令调优LLMs的质量,研究者们使用了三种评估指标:人类对三个对齐标准的评估、使用GPT-4反馈的自动评估,以及对不自然指令的ROUGE-L评估。此外,研究者们还收集了GPT-4的反馈和比较数据,用于训练奖励模型。论文中还提供了算法伪代码,详细说明了提示工程、GPT-4调用和数据生成中的超参数。研究者们还对比了使用GPT-4和GPT-3.5生成的指令跟随数据的输出响应集,以及这些数据在不同评估标准下的性能表现。
论文实验:
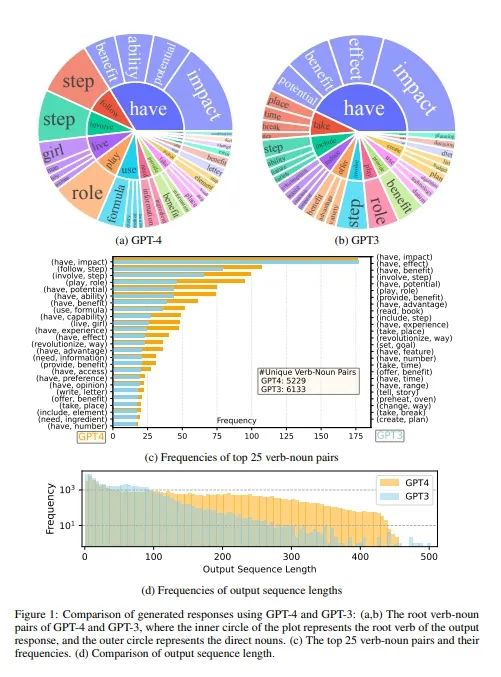
Figure 1 展示了使用 GPT-4 和 GPT-3 生成的指令跟随数据的比较。这个比较涵盖了几个关键的统计数据和可视化图表,以展示两种模型在生成响应时的差异。Figure 1(a) 和 (b) 展示了 GPT-4 和 GPT-3 在输出响应中的根动词和直接宾语名词的组合。这些组合反映了模型生成响应的基本内容和结构。内部圆圈代表输出响应的根动词,外部圆圈代表直接宾语名词。这些图表显示了每个模型生成的响应中最常见的动词-名词对,以及它们的频率。Figure 1(c) 展示了两组数据中频率最高的 25 个动词-名词对,并比较了它们的频率。这有助于理解模型在生成响应时的常用短语和结构。Figure 1(d) 比较了 GPT-4 和 GPT-3 生成的输出序列长度的频率分布。这显示了模型生成响应的长度差异,以及它们在不同长度上的分布情况。GPT-4 倾向于生成更长的序列,而 GPT-3.5 生成的输出分布有一个更长的尾部,这可能是因为 Alpaca 数据集在每次迭代中都移除了相似的指令实例,而当前的数据生成过程是一次性的。
论文链接:
https://arxiv.org/abs/2304.03277
原文来自:
NLP论文速读(微软出品)|使用GPT-4进行指令微调