NLP论文速读(EMNLP 2024)|动态奖励与提示优化来帮助语言模型的进行自我对齐
论文速读|Dynamic Rewarding with Prompt Optimization Enables Tuning-free Self-Alignment of Language Models
论文信息:

简介:
本文讨论的背景是大型语言模型(LLMs)的自我对齐问题。传统的LLMs对齐方法依赖于昂贵的训练和人类偏好注释,这限制了它们的可扩展性和实用性。随着LLMs变得更复杂和广泛采用,对于成本效益高、注释效率高且能快速适应的对齐策略的需求日益迫切。自我对齐旨在通过利用模型本身来提高LLMs的对齐,例如用模型生成的反馈替换人类反馈,合成偏好数据或自我批评。然而,这些方法仍然需要大量的资源,包括成本高昂且不稳定的RLHF(从人类反馈中学习的强化学习)调整,以及一定程度的人类监督。本文解决的问题是如何在不进行昂贵调整或注释的情况下,实现LLMs的自我对齐。具体来说,它旨在降低与LLMs对齐相关的成本,并提高模型适应不同对齐挑战的效率。本文提出了一种无需调整的自我对齐方法,称为动态奖励与提示优化(DRPO),它利用基于搜索的优化框架,使LLMs能够迭代自我改进并制定最优的对齐指令,无需额外的训练或人类干预。
论文方法:
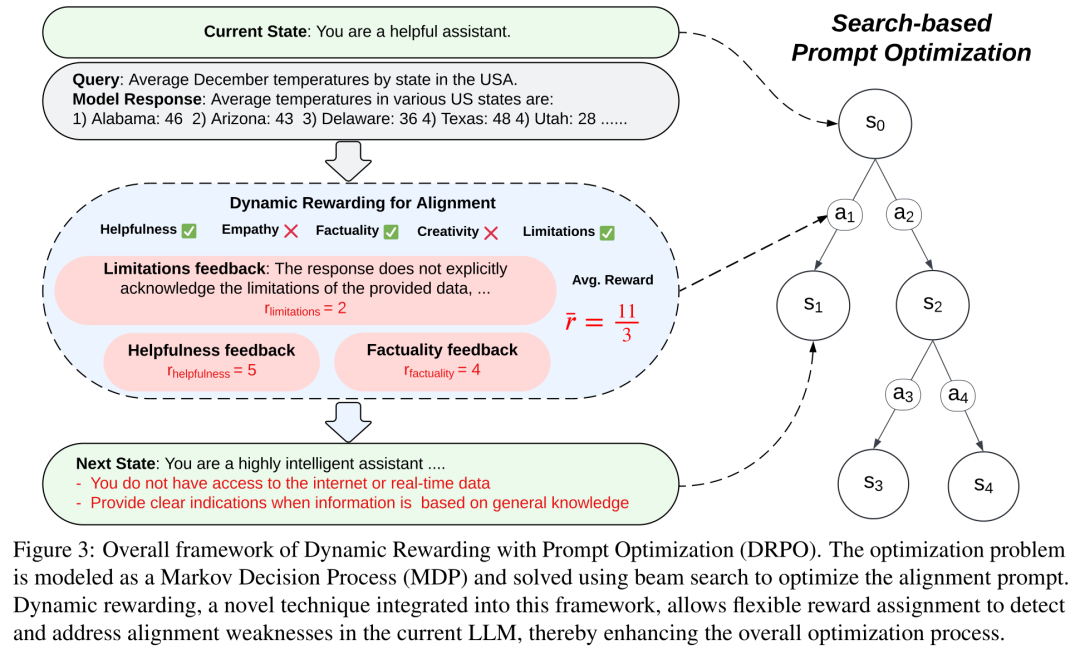
本文提出的方法是动态奖励与提示优化(DRPO),它基于搜索的提示优化(PO)框架构建,使LLMs能够自我纠正并自动制定详细的对齐指令。DRPO的核心创新在于其动态奖励机制,该机制与优化框架集成,允许基于特定查询动态调整LLMs的奖励,以识别和解决模型的对齐盲点。具体来说,DRPO包括以下几个步骤:
问题表述:给定一个LLM B,对齐指令由系统提示P和一组N个上下文学习(ICL)示例I组成。目标是找到最佳的P和IK,以最大化模型响应的对齐。
动态奖励与提示优化(DRPO):DRPO将系统提示和ICL示例分别优化,采用两步优化方法。首先,构建一个通用的ICL示例集并优化它们的响应以获得I*,然后基于优化后的通用集I估计模型特定的系统提示P。
动态奖励机制:将优化问题表述为马尔可夫决策过程(MDP),状态s代表优化目标,动作a基于给定状态的对齐反馈定义。动态奖励函数R可以根据特定查询动态调整,以灵活地评分和评估响应。
ICL示例优化:从一组基础ICL示例开始,目标是找到一个通用集I*,以最大化跨不同模型的对齐。通过搜索树的状态s0 = bi初始化,并使用动态奖励函数R评估和改进对齐。
系统提示优化:使用K个优化的ICL示例IK,通过相似性检索选择。收集一组种子样本X,用于测试基础模型B的对齐。目标是找到最优提示P,以最大化LLM B的对齐。
论文实验:
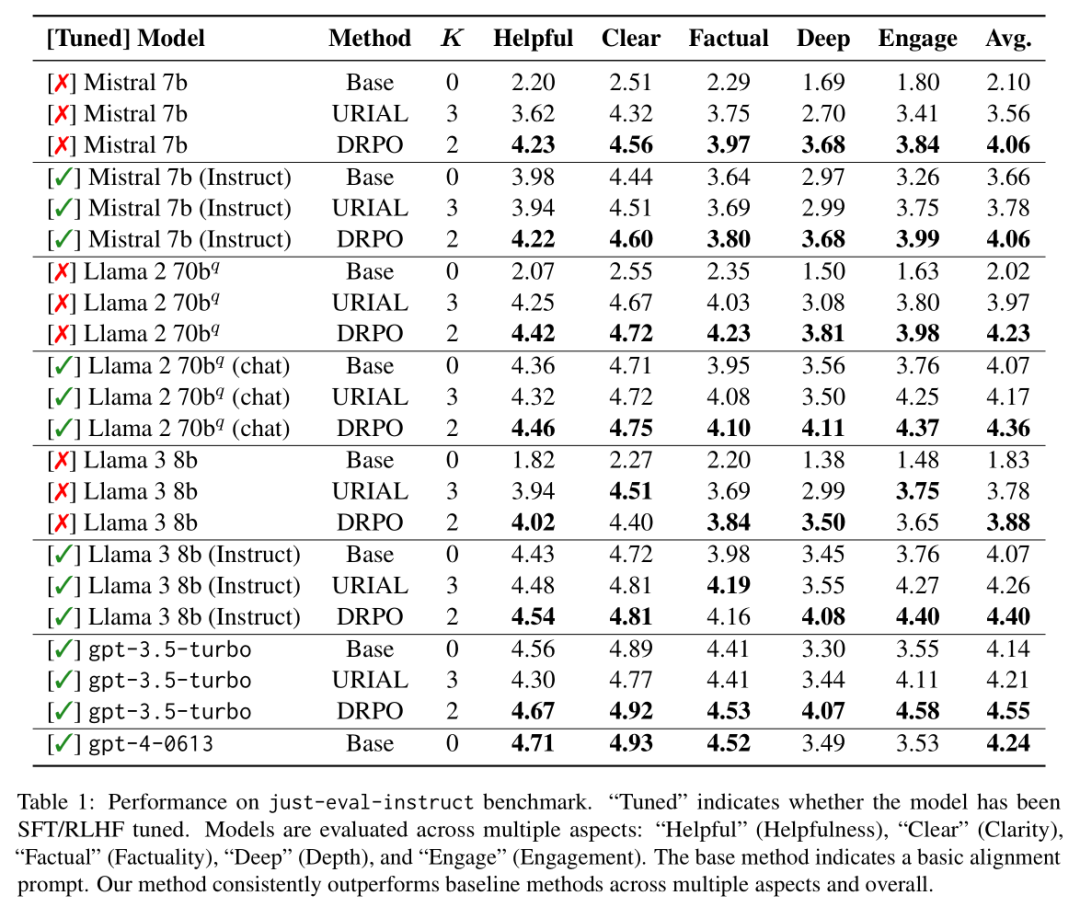
根据Table 1,论文中的实验旨在评估动态奖励与提示优化(DRPO)方法在不同大型语言模型(LLMs)上的性能,并与基线方法进行比较。实验使用了just-eval-instruct基准测试,这是一个合并了五个流行对齐数据集的标准对齐基准,包含1000个示例,用于全面和细致地评估LLM对齐。这些示例中,前800个评估模型的帮助性,剩下的200个评估无害性。评分标准从1到5,分别代表“强烈反对”、“反对”、“中立”、“同意”和“强烈同意”。DRPO在所有模型上的表现均优于基线方法,无论是未经调整的模型还是经过SFT/RLHF调整的模型。在未经调整的模型(如Mistral 7b和Llama 2 70bq)上应用DRPO后,其表现甚至超过了经过RLHF/SFT调整的模型。DRPO在URIAL使用的ICL示例数量更少的情况下,仍然实现了优于URIAL的性能,这突显了DRPO优化对齐指令的质量。表中还提到,尽管just-eval-instruct包括了安全指标,但所有方法(RLHF/SFT、URIAL和DRPO)在安全指标上都取得了一致的高分,表明像DRPO这样的无需调整的方法可以实现非常安全且符合人类价值观的模型。
论文链接:
https://arxiv.org/abs/2411.08733
原文来自:
NLP论文速读(EMNLP 2024)|动态奖励与提示优化来帮助语言模型的进行自我对齐