Elasticsearch:更好的二进制量化(BBQ)对比乘积量化(PQ)
作者:来自 Elastic Benjamin Trent

为什么我们选择花时间研究更好的二进制量化而不是在 Lucene 和 Elasticsearch 中进行生产量化。
我们一直在逐步使 Elasticsearch 和 Lucene 的向量搜索变得更快、更实惠。我们的主要重点不仅是通过 SIMD 提高搜索速度,而且还通过标量量化降低成本。首先是 4 倍,然后是 8 倍。然而,这还不够。通过乘积量化(Product Quantization 简称 PQ)等技术,可以在不显著降低召回率的情况下实现 32 倍的减少。我们需要实现更高级别的量化,以在速度和成本之间提供足够的权衡。
一种实现这一目标的方法是专注于 PQ(乘积量化)。另一种则是直接改进二值量化。剧透如下:
- BBQ 的向量量化速度比 PQ 快 10-50 倍
- BBQ 的查询速度比 PQ 快 2-4 倍
- BBQ 的召回率与 PQ 相当或更好
那么,我们到底测试了什么?结果如何?
我们到底要测试什么?
从理论上讲,PQ 和 Better Binary Quantization(BBQ) 都有各种优缺点。但我们需要一套静态的标准来测试两者。拥有一个独立的 “优点和缺点(pros & cons)” 列表是一种过于定性的衡量标准。当然,事物有不同的好处,但我们希望有一套定量的标准来帮助我们做出决策。这遵循了类似于 Rich Hickey 解释的决策矩阵的模式。
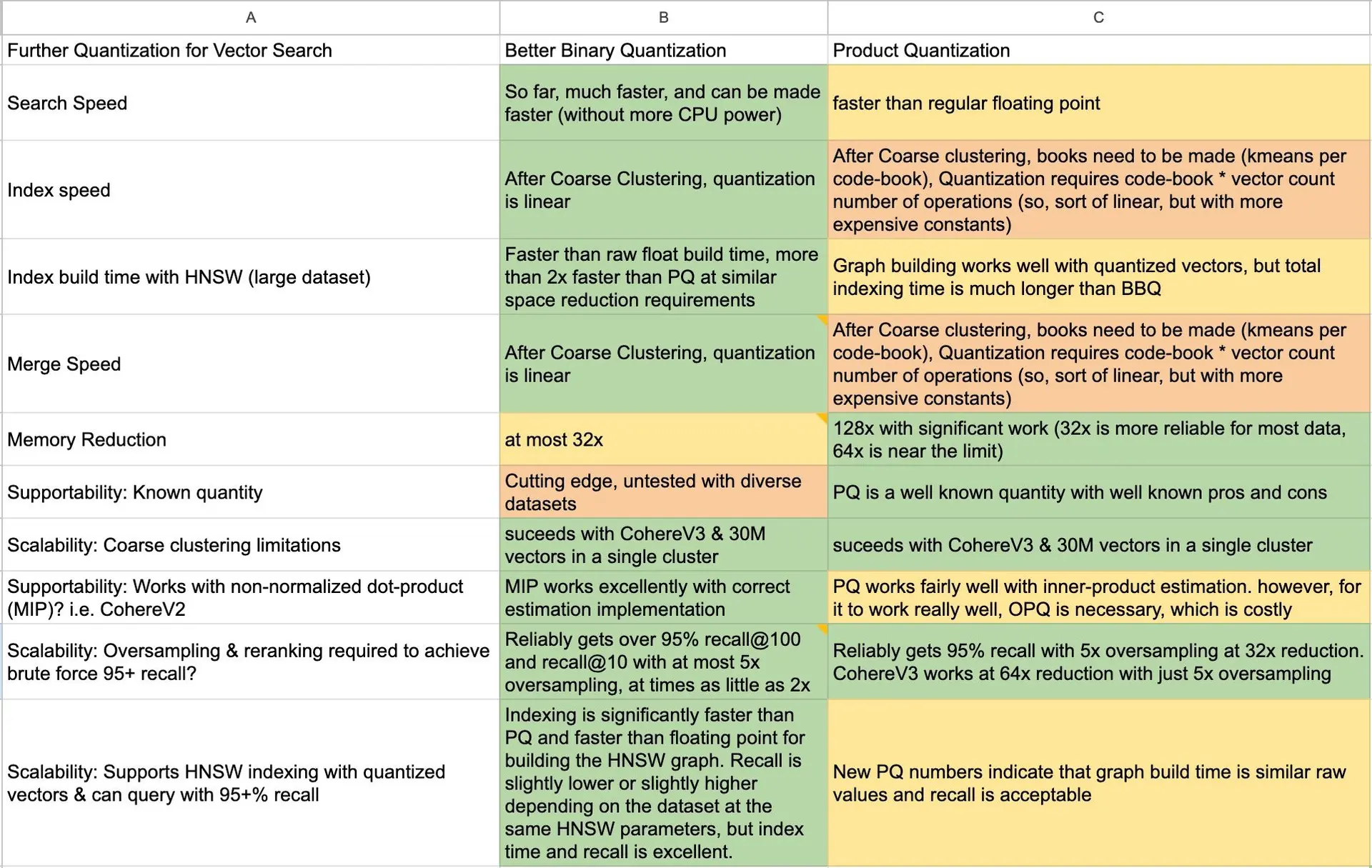
我们的标准是:
- 搜索速度
- 索引速度平稳
- 使用 HNSW 的索引速度
- 合并速度
- 内存减少可能
- 该算法是否众所周知并在生产环境中经过实战测试?
- 粗粒度聚类是否绝对必要?或者,该算法如何公平地只使用一个质心
- 需要强力(brute force)过采样才能实现 95% 的召回率
- HNSW 索引仍然有效,并且可以在与强力类似的重新排序下实现 +90% 的召回率
显然,几乎所有标准都是可衡量的,我们确实有一个我们认为重要的定性标准。对于未来的可支持性,成为一种众所周知的算法很重要,如果所有其他措施都与之相关,这可能是决策的转折点。
我们如何测试它?
Lucene 和 Elasticsearch 都是用 Java 编写的,因此我们直接用 Java 编写了两个概念证明。这样,我们就可以在性能上进行同类比较。另外,在进行乘积量化(Product Quantization, PQ)时,我们仅测试了最高 32 倍的空间压缩。虽然 PQ 可以通过减少码本数量(code books)进一步压缩空间,但我们发现对于许多模型来说,召回率会迅速下降到不可接受的水平,从而需要更高比例的过采样。
此外,由于优化 PQ(Optimized PQ)对计算资源要求较高,我们没有采用这种技术。
我们测试了不同的数据集和相似性指标。特别是:
- e5Small,它只有 384 个维度,与其他模型相比,它的向量空间相当窄。你可以在我们的位向量博客中看到 e5small 的简单二进制量化表现有多差。因此,我们希望确保二进制量化的演变能够处理这样的模型。
- Cohere 的 v3 模型,它有 1024 个维度,并且喜欢被量化。如果量化方法不适用于此方法,那么它可能不适用于任何模型。
- Cohere 的 v2 模型有 768 个维度,其出色的性能依赖于最大内积的非欧几里得向量空间。我们希望确保它能够像乘积量化一样处理非欧几里得空间。
我们在基于 ARM 的 MacBook 上进行了本地测试,并在更大的 x86 机器上进行了远程测试,以确保无论 CPU 架构如何,我们发现的任何性能差异都是可重复的。
那么,结果如何呢?
e5small quora
这是一个较小的数据集,使用 e5small 构建了 522k 个向量。它的维度很少,嵌入空间很窄,因此无法与简单的二进制量化一起使用。由于 BBQ 是二进制量化的演变,因此验证它与 PQ 相比在如此不利的模型下是否有效非常重要。
在 M1 Max ARM 笔记本电脑上测试:
| Algorithm | quantization build time (ms) | brute-force latency (ms) | brute-force recall @ 10:50 | hnsw build time (ms) | hnsw recall @ 10:100 | hnsw latency (ms) |
|---|---|---|---|---|---|---|
| BBQ | 1041 | 11 | 99% | 104817 | 96% | 0.25 |
| Product Quantization | 59397 | 20 | 99% | 239660 | 96% | 0.45 |
CohereV3
此模型在量化方面表现出色。我们希望在单个粗粒度质心中处理更多向量(30M),以确保我们的小规模结果实际上可以转化为更多向量。
此测试是在 Google Cloud 中一台更大的 x86 机器上进行的:
| Algorithm | quantization build time (ms) | brute-force latency (ms) | brute-force recall @ 10:50 | hnsw build time (ms) | hnsw recall @ 10:100 | hnsw latency (ms) |
|---|---|---|---|---|---|---|
| BBQ | 998363 | 1776 | 98% | 40043229 | 90% | 0.6 |
| Product Quantization | 13116553 | 5790 | 98% | N/A | N/A | N/A |
当谈到类似召回率的索引和搜索速度时,BBQ 显然是赢家。
内积搜索和 BBQ
我们在其他实验中注意到,在量化时,非欧几里得搜索可能很难准确实现。此外,简单的二值量化对向量的大小不敏感,而向量大小对于内积计算至关重要。
带着这个需要注意的点(脚注),我们花了几天时间研究代数,调整查询估算最后阶段的校正措施。结果是:成功了!
| Algorithm | recall 10:10 | recall 10:20 | recall 10:30 | recall 10:40 | recall 10:50 | recall 10:100 |
|---|---|---|---|---|---|---|
| BBQ | 71% | 87% | 93% | 95% | 96% | 99% |
| Product Quantization | 65% | 84% | 90% | 93% | 95% | 98% |
就这样,圆满结束!
我们对更优二值量化(Better Binary Quantization, BBQ)感到非常兴奋!经过大量的尝试和验证,我们不断被其结果质量所惊艳 —— 每个向量维度仅保留 1 位信息就能达到如此效果。
敬请期待,它将在未来的 Elasticsearch 版本中与你见面!
Elasticsearch 包含许多新功能,助您构建适合各种场景的最佳搜索解决方案。欢迎查看我们的示例笔记本以了解更多,开启免费的云端试用,或在本地机器上体验 Elastic 的强大功能。
原文:Better Binary Quantization vs. Product Quantization - Search Labs