Java开发经验——JDK工具类的安全问题
摘要
本文探讨了Java开发中JDK工具类的安全问题,重点分析了不同工具类(包括Java自带的Objects工具类、Apache Commons Lang、Guava和Spring Framework的ObjectUtils)在比较对象相等性时的使用方法和优势。同时,文章还涉及了Integer类型拆箱与封箱、Lombok代码生成异常、计算精度问题、List集合类问题和异常处理问题等多个Java开发中的常见问题。

1. Object对象是否相等
在Java中,判断两个对象是否相等通常依赖于equals方法(不推荐),但对于更复杂的场景或特定需求,可以使用一些工具类。以下是常用的工具类和方法:
1.1. Objects工具类(Java 7+)
java.util.Objects提供了许多便捷的方法用于对象操作,其中Objects.equals非常适合比较两个对象是否相等,避免了空指针异常。简化了空值判断,自动处理null。
import java.util.Objects;
public class Main {
public static void main(String[] args) {
String str1 = "hello";
String str2 = "hello";
System.out.println(Objects.equals(str1, str2)); // 输出 true
System.out.println(Objects.equals(str1, null)); // 输出 false
System.out.println(Objects.equals(null, null)); // 输出 true
}
}
1.2. Apache Commons Lang
org.apache.commons.lang3.ObjectUtils提供了多种对象操作工具,其中ObjectUtils.equals是比较对象是否相等的便捷方法。功能丰富,支持其他对象操作,比如默认值设置等。
import org.apache.commons.lang3.ObjectUtils;
public class Main {
public static void main(String[] args) {
String str1 = "world";
String str2 = "world";
System.out.println(ObjectUtils.equals(str1, str2)); // 输出 true
System.out.println(ObjectUtils.equals(str1, null)); // 输出 false
System.out.println(ObjectUtils.equals(null, null)); // 输出 true
}
}
1.3. Guava(com.google.common.base.Objects)
Guava的Objects.equal也是一个强大的比较工具(注意,它在新版Guava中已被Objects.equals替代)。简单易用,适合使用Guava库的项目。
import com.google.common.base.Objects;
public class Main {
public static void main(String[] args) {
String str1 = "java";
String str2 = "java";
System.out.println(Objects.equal(str1, str2)); // 输出 true
System.out.println(Objects.equal(str1, null)); // 输出 false
System.out.println(Objects.equal(null, null)); // 输出 true
}
}
1.4. Spring Framework - ObjectUtils
Spring的org.springframework.util.ObjectUtils也提供了一个null-safe equals方法。对Spring项目非常友好。
import org.springframework.util.ObjectUtils;
public class Main {
public static void main(String[] args) {
String str1 = "spring";
String str2 = "spring";
System.out.println(ObjectUtils.nullSafeEquals(str1, str2)); // 输出 true
System.out.println(ObjectUtils.nullSafeEquals(str1, null)); // 输出 false
System.out.println(ObjectUtils.nullSafeEquals(null, null)); // 输出 true
}
}
2. Integer类型拆箱与封箱
String a = "1";
String b = "1";
log.info("\nString a = \"1\";\n" +
"String b = \"1\";\n" +
"a == b ? {}", a == b); //true
String c = new String("2");
String d = new String("2");
log.info("\nString c = new String(\"2\");\n" +
"String d = new String(\"2\");" +
"c == d ? {}", c == d); //false
String e = new String("3").intern();
String f = new String("3").intern();
log.info("\nString e = new String(\"3\").intern();\n" +
"String f = new String(\"3\").intern();\n" +
"e == f ? {}", e == f); //true
String g = new String("4");
String h = new String("4");
log.info("\nString g = new String(\"4\");\n" +
"String h = new String(\"4\");\n" +
"g == h ? {}", g.equals(h)); //true首先要明确的是其设计初衷是节省内存。当代码中出现双引号形式创建字符串对象时,JVM 会先对这个字符串进行检查,如果字符串常量池中存在相同内容的字符串对象的引用,则将这个引用返回;否则,创建新的字符串对象,然后将这个引用放入字符串常量池,并返回该引用。这种机制,就是字符串驻留或池化。
再回到刚才的例子,再来分析一下运行结果:
- 第一个案例返回 true,因为 Java 的字符串驻留机制,直接使用双引号声明出来的两个 String 对象指向常量池中的相同字符串。
- 第二个案例,new 出来的两个 String 是不同对象,引用当然不同,所以得到 false 的结果。
- 第三个案例,使用 String 提供的 intern 方法也会走常量池机制,所以同样能得到 true。
- 第四个案例,通过 equals 对值内容判等,是正确的处理方式,当然会得到 true。
- 虽然使用 new 声明的字符串调用 intern 方法,也可以让字符串进行驻留,但在业务代码中滥用 intern,可能会产生性能问题。
是时候给出第二原则了:没事别轻易用 intern,如果要用一定要注意控制驻留的字符串的数量,并留意常量表的各项指标。
3. Lombok生成代码异常
Lombok 的 @Data 注解会帮我们实现 equals 和 hashcode 方法,但是有继承关系时,Lombok 自动生成的方法可能就不是我们期望的了。我们先来研究一下其实现:定义一个 Person 类型,包含姓名和身份证两个字段:
@Data
class Person {
private String name;
private String identity;
public Person(String name, String identity) {
this.name = name;
this.identity = identity;
}
}对于身份证相同、姓名不同的两个 Person 对象:
Person person1 = new Person("zhuye","001");
Person person2 = new Person("Joseph","001");
log.info("person1.equals(person2) ? {}", person1.equals(person2));使用 equals 判等会得到 false。如果你希望只要身份证一致就认为是同一个人的话,可以使用 @EqualsAndHashCode.Exclude 注解来修饰 name 字段,从 equals 和 hashCode 的实现中排除 name 字段:
@EqualsAndHashCode.Exclude
private String name;修改后得到 true。打开编译后的代码可以看到,Lombok 为 Person 生成的 equals 方法的实现,确实只包含了 identity 属性:
public boolean equals(final Object o) {
if (o == this) {
return true;
} else if (!(o instanceof LombokEquealsController.Person)) {
return false;
} else {
LombokEquealsController.Person other = (LombokEquealsController.Person)o;
if (!other.canEqual(this)) {
return false;
} else {
Object this$identity = this.getIdentity();
Object other$identity = other.getIdentity();
if (this$identity == null) {
if (other$identity != null) {
return false;
}
} else if (!this$identity.equals(other$identity)) {
return false;
}
return true;
}
}
}但到这里还没完,如果类型之间有继承,Lombok 会怎么处理子类的 equals 和 hashCode 呢?我们来测试一下,写一个 Employee 类继承 Person,并新定义一个公司属性:
@Data
class Employee extends Person {
private String company;
public Employee(String name, String identity, String company) {
super(name, identity);
this.company = company;
}
}在如下的测试代码中,声明两个 Employee 实例,它们具有相同的公司名称,但姓名和身份证均不同:
Employee employee1 = new Employee("zhuye","001", "bkjk.com");
Employee employee2 = new Employee("Joseph","002", "bkjk.com");
log.info("employee1.equals(employee2) ? {}", employee1.equals(employee2)); 很遗憾,结果是 true,显然是没有考虑父类的属性,而认为这两个员工是同一人,说明 @EqualsAndHashCode 默认实现没有使用父类属性。
为解决这个问题,我们可以手动设置 callSuper 开关为 true,来覆盖这种默认行为:
@Data
@EqualsAndHashCode(callSuper = true)
class Employee extends Person {修改后的代码,实现了同时以子类的属性 company 加上父类中的属性 identity,作为 equals 和 hashCode 方法的实现条件(实现上其实是调用了父类的 equals 和 hashCode)。
4. 计算精度、舍入和溢出问题
4.1. Double运算
我们先从简单的反直觉的四则运算看起。对几个简单的浮点数进行加减乘除运算:
System.out.println(0.1+0.2);
System.out.println(1.0-0.8);
System.out.println(4.015*100);
System.out.println(123.3/100);
double amount1 = 2.15;
double amount2 = 1.10;
if (amount1 - amount2 == 1.05)
System.out.println("OK");输出结果如下:
0.30000000000000004
0.19999999999999996
401.49999999999994
1.2329999999999999可以看到,输出结果和我们预期的很不一样。比如,0.1+0.2 输出的不是 0.3 而是 0.30000000000000004;再比如,对 2.15-1.10 和 1.05 判等,结果判等不成立。
出现这种问题的主要原因是,计算机是以二进制存储数值的,浮点数也不例外。Java 采用了IEEE 754 标准实现浮点数的表达和运算,你可以通过这里查看数值转化为二进制的结果。
比如,0.1 的二进制表示为 0.0 0011 0011 0011… (0011 无限循环),再转换为十进制就是 0.1000000000000000055511151231257827021181583404541015625。对于计算机而言,0.1 无法精确表达,这是浮点数计算造成精度损失的根源。
你可能会说,以 0.1 为例,其十进制和二进制间转换后相差非常小,不会对计算产生什么影响。但,所谓积土成山,如果大量使用 double 来作大量的金钱计算,最终损失的精度就是大量的资金出入。比如,每天有一百万次交易,每次交易都差一分钱,一个月下来就差 30 万。这就不是小事儿了。那,如何解决这个问题呢?
我们大都听说过 BigDecimal 类型,浮点数精确表达和运算的场景,一定要使用这个类型。不过,在使用 BigDecimal 时有几个坑需要避开。我们用 BigDecimal 把之前的四则运算改一下:
System.out.println(new BigDecimal(0.1).add(new BigDecimal(0.2)));
System.out.println(new BigDecimal(1.0).subtract(new BigDecimal(0.8)));
System.out.println(new BigDecimal(4.015).multiply(new BigDecimal(100)));
System.out.println(new BigDecimal(123.3).divide(new BigDecimal(100)));输出如下:
0.3000000000000000166533453693773481063544750213623046875
0.1999999999999999555910790149937383830547332763671875
401.49999999999996802557689079549163579940795898437500
1.232999999999999971578290569595992565155029296875可以看到,运算结果还是不精确,只不过是精度高了而已。这里给出浮点数运算避坑第一原则:使用 BigDecimal 表示和计算浮点数,且务必使用字符串的构造方法来初始化 BigDecimal:
System.out.println(new BigDecimal("0.1").add(new BigDecimal("0.2")));
System.out.println(new BigDecimal("1.0").subtract(new BigDecimal("0.8")));
System.out.println(new BigDecimal("4.015").multiply(new BigDecimal("100")));
System.out.println(new BigDecimal("123.3").divide(new BigDecimal("100")));改进后,就能得到我们想要的输出了:
0.3
0.2
401.500
1.233到这里,你可能会继续问,不能调用 BigDecimal 传入 Double 的构造方法,但手头只有一个 Double,如何转换为精确表达的 BigDecimal 呢?
我们试试用 Double.toString 把 double 转换为字符串,看看行不行?
System.out.println(new BigDecimal("4.015").multiply(new BigDecimal(Double.toString(100))));输出为 401.5000。与上面字符串初始化 100 和 4.015 相乘得到的结果 401.500 相比,这里为什么多了 1 个 0 呢?原因就是,BigDecimal 有 scale 和 precision 的概念,scale 表示小数点右边的位数,而 precision 表示精度,也就是有效数字的长度。
调试一下可以发现,new BigDecimal(Double.toString(100)) 得到的 BigDecimal 的 scale=1、precision=4;而 new BigDecimal(“100”) 得到的 BigDecimal 的 scale=0、precision=3。对于 BigDecimal 乘法操作,返回值的 scale 是两个数的 scale 相加。所以,初始化 100 的两种不同方式,导致最后结果的 scale 分别是 4 和 3:
private static void testScale() {
BigDecimal bigDecimal1 = new BigDecimal("100");
BigDecimal bigDecimal2 = new BigDecimal(String.valueOf(100d));
BigDecimal bigDecimal3 = new BigDecimal(String.valueOf(100));
BigDecimal bigDecimal4 = BigDecimal.valueOf(100d);
BigDecimal bigDecimal5 = new BigDecimal(Double.toString(100));
print(bigDecimal1); //scale 0 precision 3 result 401.500
print(bigDecimal2); //scale 1 precision 4 result 401.5000
print(bigDecimal3); //scale 0 precision 3 result 401.500
print(bigDecimal4); //scale 1 precision 4 result 401.5000
print(bigDecimal5); //scale 1 precision 4 result 401.5000
}
private static void print(BigDecimal bigDecimal) {
log.info("scale {} precision {} result {}", bigDecimal.scale(), bigDecimal.precision(), bigDecimal.multiply(new BigDecimal("4.015")));
}BigDecimal 的 toString 方法得到的字符串和 scale 相关,又会引出了另一个问题:对于浮点数的字符串形式输出和格式化,我们应该考虑显式进行,通过格式化表达式或格式化工具来明确小数位数和舍入方式。接下来,我们就聊聊浮点数舍入和格式化。
4.2. 浮点数舍入和格式化的方式
除了使用 Double 保存浮点数可能带来精度问题外,更匪夷所思的是这种精度问题,加上 String.format 的格式化舍入方式,可能得到让人摸不着头脑的结果。
我们看一个例子吧。首先用 double 和 float 初始化两个 3.35 的浮点数,然后通过 String.format 使用 %.1f 来格式化这 2 个数字:
double num1 = 3.35;
float num2 = 3.35f;
System.out.println(String.format("%.1f", num1));//四舍五入
System.out.println(String.format("%.1f", num2));得到的结果居然是 3.4 和 3.3。
这就是由精度问题和舍入方式共同导致的,double 和 float 的 3.35 其实相当于 3.350xxx 和 3.349xxx:
3.350000000000000088817841970012523233890533447265625
3.349999904632568359375String.format 采用四舍五入的方式进行舍入,取 1 位小数,double 的 3.350 四舍五入为 3.4,而 float 的 3.349 四舍五入为 3.3。
我们看一下 Formatter 类的相关源码,可以发现使用的舍入模式是 HALF_UP(代码第 11 行):
else if (c == Conversion.DECIMAL_FLOAT) {
// Create a new BigDecimal with the desired precision.
int prec = (precision == -1 ? 6 : precision);
int scale = value.scale();
if (scale > prec) {
// more "scale" digits than the requested "precision"
int compPrec = value.precision();
if (compPrec <= scale) {
// case of 0.xxxxxx
value = value.setScale(prec, RoundingMode.HALF_UP);
} else {
compPrec -= (scale - prec);
value = new BigDecimal(value.unscaledValue(),
scale,
new MathContext(compPrec));
}
}
}如果我们希望使用其他舍入方式来格式化字符串的话,可以设置 DecimalFormat,如下代码所示:
double num1 = 3.35;
float num2 = 3.35f;
DecimalFormat format = new DecimalFormat("#.##");
format.setRoundingMode(RoundingMode.DOWN);
System.out.println(format.format(num1));
format.setRoundingMode(RoundingMode.DOWN);
System.out.println(format.format(num2));当我们把这 2 个浮点数向下舍入取 2 位小数时,输出分别是 3.35 和 3.34,还是我们之前说的浮点数无法精确存储的问题。
因此,即使通过 DecimalFormat 来精确控制舍入方式,double 和 float 的问题也可能产生意想不到的结果,所以浮点数避坑第二原则:浮点数的字符串格式化也要通过 BigDecimal 进行。
比如下面这段代码,使用 BigDecimal 来格式化数字 3.35,分别使用向下舍入和四舍五入方式取 1 位小数进行格式化:
BigDecimal num1 = new BigDecimal("3.35");
BigDecimal num2 = num1.setScale(1, BigDecimal.ROUND_DOWN);
System.out.println(num2);
BigDecimal num3 = num1.setScale(1, BigDecimal.ROUND_HALF_UP);
System.out.println(num3);这次得到的结果是 3.3 和 3.4,符合预期。
4.3. 小心数值溢出问题
数值计算还有一个要小心的点是溢出,不管是 int 还是 long,所有的基本数值类型都有超出表达范围的可能性。比如,对 Long 的最大值进行 +1 操作:
long l = Long.MAX_VALUE;
System.out.println(l + 1);
System.out.println(l + 1 == Long.MIN_VALUE);输出结果是一个负数,因为 Long 的最大值 +1 变为了 Long 的最小值:
-9223372036854775808
true显然这是发生了溢出,而且是默默地溢出,并没有任何异常。这类问题非常容易被忽略,改进方式有下面 2 种。
方法一是,考虑使用 Math 类的 addExact、subtractExact 等 xxExact 方法进行数值运算,这些方法可以在数值溢出时主动抛出异常。我们来测试一下,使用 Math.addExact 对 Long 最大值做 +1 操作:
try {
long l = Long.MAX_VALUE;
System.out.println(Math.addExact(l, 1));
} catch (Exception ex) {
ex.printStackTrace();
}执行后,可以得到 ArithmeticException,这是一个 RuntimeException:
java.lang.ArithmeticException: long overflow
at java.lang.Math.addExact(Math.java:809)
at org.geekbang.time.commonmistakes.numeralcalculations.demo3.CommonMistakesApplication.right2(CommonMistakesApplication.java:25)
at org.geekbang.time.commonmistakes.numeralcalculations.demo3.CommonMistakesApplication.main(CommonMistakesApplication.java:13)方法二是,使用大数类 BigInteger。BigDecimal 是处理浮点数的专家,而 BigInteger 则是对大数进行科学计算的专家。
如下代码,使用 BigInteger 对 Long 最大值进行 +1 操作;如果希望把计算结果转换一个 Long 变量的话,可以使用 BigInteger 的 longValueExact 方法,在转换出现溢出时,同样会抛出 ArithmeticException:
BigInteger i = new BigInteger(String.valueOf(Long.MAX_VALUE));
System.out.println(i.add(BigInteger.ONE).toString());
try {
long l = i.add(BigInteger.ONE).longValueExact();
} catch (Exception ex) {
ex.printStackTrace();
}输出结果如下:
9223372036854775808
java.lang.ArithmeticException: BigInteger out of long range
at java.math.BigInteger.longValueExact(BigInteger.java:4632)
at org.geekbang.time.commonmistakes.numeralcalculations.demo3.CommonMistakesApplication.right1(CommonMistakesApplication.java:37)
at org.geekbang.time.commonmistakes.numeralcalculations.demo3.CommonMistakesApplication.main(CommonMistakesApplication.java:11)可以看到,通过 BigInteger 对 Long 的最大值加 1 一点问题都没有,当尝试把结果转换为 Long 类型时,则会提示 BigInteger out of long range。
5. List 集合类
5.1. Arrays.asList 把数据转换为 List
Java 8 中 Stream 流式处理的各种功能,大大减少了集合类各种操作(投影、过滤、转换)的代码量。所以,在业务开发中,我们常常会把原始的数组转换为 List 类数据结构,来继续展开各种 Stream 操作。
你可能也想到了,使用 Arrays.asList 方法可以把数组一键转换为 List,但其实没这么简单。接下来,就让我们看看其中的缘由,以及使用 Arrays.asList 把数组转换为 List 的几个坑。
在如下代码中,我们初始化三个数字的 int[]数组,然后使用 Arrays.asList 把数组转换为 List:
int[] arr = {1, 2, 3};
List list = Arrays.asList(arr);
log.info("list:{} size:{} class:{}", list, list.size(), list.get(0).getClass());但,这样初始化的 List 并不是我们期望的包含 3 个数字的 List。通过日志可以发现,这个 List 包含的其实是一个 int 数组,整个 List 的元素个数是 1,元素类型是整数数组。
12:50:39.445 [main] INFO org.geekbang.time.commonmistakes.collection.aslist.AsListApplication - list:[[I@1c53fd30] size:1 class:class [I其原因是,只能是把 int 装箱为 Integer,不可能把 int 数组装箱为 Integer 数组。我们知道,Arrays.asList 方法传入的是一个泛型 T 类型可变参数,最终 int 数组整体作为了一个对象成为了泛型类型 T:
public static <T> List<T> asList(T... a) {
return new ArrayList<>(a);
}直接遍历这样的 List 必然会出现 Bug,修复方式有两种,如果使用 Java8 以上版本可以使用 Arrays.stream 方法来转换,否则可以把 int 数组声明为包装类型 Integer 数组:
int[] arr1 = {1, 2, 3};
List list1 = Arrays.stream(arr1).boxed().collect(Collectors.toList());
log.info("list:{} size:{} class:{}", list1, list1.size(), list1.get(0).getClass());
Integer[] arr2 = {1, 2, 3};
List list2 = Arrays.asList(arr2);
log.info("list:{} size:{} class:{}", list2, list2.size(), list2.get(0).getClass());修复后的代码得到如下日志,可以看到 List 具有三个元素,元素类型是 Integer:
13:10:57.373 [main] INFO org.geekbang.time.commonmistakes.collection.aslist.AsListApplication - list:[1, 2, 3] size:3 class:class java.lang.Integer可以看到第一个坑是,不能直接使用 Arrays.asList 来转换基本类型数组。
把三个字符串 1、2、3 构成的字符串数组,使用 Arrays.asList 转换为 List 后,将原始字符串数组的第二个字符修改为 4,然后为 List 增加一个字符串 5,最后数组和 List 会是怎样呢?
String[] arr = {"1", "2", "3"};
List list = Arrays.asList(arr);
arr[1] = "4";
try {
list.add("5");
} catch (Exception ex) {
ex.printStackTrace();
}
log.info("arr:{} list:{}", Arrays.toString(arr), list);可以看到,日志里有一个 UnsupportedOperationException,为 List 新增字符串 5 的操作失败了,而且把原始数组的第二个元素从 2 修改为 4 后,asList 获得的 List 中的第二个元素也被修改为 4 了:
java.lang.UnsupportedOperationException
at java.util.AbstractList.add(AbstractList.java:148)
at java.util.AbstractList.add(AbstractList.java:108)
at org.geekbang.time.commonmistakes.collection.aslist.AsListApplication.wrong2(AsListApplication.java:41)
at org.geekbang.time.commonmistakes.collection.aslist.AsListApplication.main(AsListApplication.java:15)
13:15:34.699 [main] INFO org.geekbang.time.commonmistakes.collection.aslist.AsListApplication - arr:[1, 4, 3] list:[1, 4, 3]Arrays.asList 返回的 List 不支持增删操作。Arrays.asList 返回的 List 并不是我们期望的 java.util.ArrayList,而是 Arrays 的内部类 ArrayList。ArrayList 内部类继承自 AbstractList 类,并没有覆写父类的 add 方法,而父类中 add 方法的实现,就是抛出 UnsupportedOperationException。相关源码如下所示:
public static <T> List<T> asList(T... a) {
return new ArrayList<>(a);
}
private static class ArrayList<E> extends AbstractList<E> implements RandomAccess, java.io.Serializable {
private final E[] a;
ArrayList(E[] array) {
a = Objects.requireNonNull(array);
}
...
@Override
public E set(int index, E element) {
E oldValue = a[index];
a[index] = element;
return oldValue;
}
...
}
public abstract class AbstractList<E> extends AbstractCollection<E> implements List<E> {
...
public void add(int index, E element) {
throw new UnsupportedOperationException();
}
}对原始数组的修改会影响到我们获得的那个 List。看一下 ArrayList 的实现,可以发现 ArrayList 其实是直接使用了原始的数组。所以,我们要特别小心,把通过 Arrays.asList 获得的 List 交给其他方法处理,很容易因为共享了数组,相互修改产生 Bug。
修复方式比较简单,重新 new 一个 ArrayList 初始化 Arrays.asList 返回的 List 即可:
String[] arr = {"1", "2", "3"};
List list = new ArrayList(Arrays.asList(arr));
arr[1] = "4";
try {
list.add("5");
} catch (Exception ex) {
ex.printStackTrace();
}
log.info("arr:{} list:{}", Arrays.toString(arr), list);修改后的代码实现了原始数组和 List 的“解耦”,不再相互影响。同时,因为操作的是真正的 ArrayList,add 也不再出错:
13:34:50.829 [main] INFO org.geekbang.time.commonmistakes.collection.aslist.AsListApplication - arr:[1, 4, 3] list:[1, 2, 3, 5]5.2. List.subList进行切片操作居然会导致OOM问题
业务开发时常常要对 List 做切片处理,即取出其中部分元素构成一个新的 List,我们通常会想到使用 List.subList 方法。但,和 Arrays.asList 的问题类似,List.subList 返回的子 List 不是一个普通的 ArrayList。这个子 List 可以认为是原始 List 的视图,会和原始 List 相互影响。如果不注意,很可能会因此产生 OOM 问题。接下来,我们就一起分析下其中的坑。
如下代码所示,定义一个名为 data 的静态 List 来存放 Integer 的 List,也就是说 data 的成员本身是包含了多个数字的 List。循环 1000 次,每次都从一个具有 10 万个 Integer 的 List 中,使用 subList 方法获得一个只包含一个数字的子 List,并把这个子 List 加入 data 变量:
private static List<List<Integer>> data = new ArrayList<>();
private static void oom() {
for (int i = 0; i < 1000; i++) {
List<Integer> rawList = IntStream.rangeClosed(1, 100000).boxed().collect(Collectors.toList());
data.add(rawList.subList(0, 1));
}
}你可能会觉得,这个 data 变量里面最终保存的只是 1000 个具有 1 个元素的 List,不会占用很大空间,但程序运行不久就出现了 OOM:
Exception in thread "main" java.lang.OutOfMemoryError: Java heap space
at java.util.Arrays.copyOf(Arrays.java:3181)
at java.util.ArrayList.grow(ArrayList.java:265)出现 OOM 的原因是,循环中的 1000 个具有 10 万个元素的 List 始终得不到回收,因为它始终被 subList 方法返回的 List 强引用。那么,返回的子 List 为什么会强引用原始的 List,它们又有什么关系呢?我们再继续做实验观察一下这个子 List 的特性。
首先初始化一个包含数字 1 到 10 的 ArrayList,然后通过调用 subList 方法取出 2、3、4;随后删除这个 SubList 中的元素数字 3,并打印原始的 ArrayList;最后为原始的 ArrayList 增加一个元素数字 0,遍历 SubList 输出所有元素:
List<Integer> list = IntStream.rangeClosed(1, 10).boxed().collect(Collectors.toList());
List<Integer> subList = list.subList(1, 4);
System.out.println(subList);
subList.remove(1);
System.out.println(list);
list.add(0);
try {
subList.forEach(System.out::println);
} catch (Exception ex) {
ex.printStackTrace();
}代码运行后得到如下输出:
[2, 3, 4]
[1, 2, 4, 5, 6, 7, 8, 9, 10]
java.util.ConcurrentModificationException
at java.util.ArrayList$SubList.checkForComodification(ArrayList.java:1239)
at java.util.ArrayList$SubList.listIterator(ArrayList.java:1099)
at java.util.AbstractList.listIterator(AbstractList.java:299)
at java.util.ArrayList$SubList.iterator(ArrayList.java:1095)
at java.lang.Iterable.forEach(Iterable.java:74)可以看到两个现象:
- 原始 List 中数字 3 被删除了,说明删除子 List 中的元素影响到了原始 List;
- 尝试为原始 List 增加数字 0 之后再遍历子 List,会出现 ConcurrentModificationException。
public class ArrayList<E> extends AbstractList<E>
implements List<E>, RandomAccess, Cloneable, java.io.Serializable {
protected transient int modCount = 0;
private void ensureExplicitCapacity(int minCapacity) {
modCount++;
// overflow-conscious code
if (minCapacity - elementData.length > 0)
grow(minCapacity);
}
public void add(int index, E element) {
rangeCheckForAdd(index);
ensureCapacityInternal(size + 1); // Increments modCount!!
System.arraycopy(elementData, index, elementData, index + 1,
size - index);
elementData[index] = element;
size++;
}
public List<E> subList(int fromIndex, int toIndex) {
subListRangeCheck(fromIndex, toIndex, size);
return new SubList(this, offset, fromIndex, toIndex);
}
private class SubList extends AbstractList<E> implements RandomAccess {
private final AbstractList<E> parent;
private final int parentOffset;
private final int offset;
int size;
SubList(AbstractList<E> parent,
int offset, int fromIndex, int toIndex) {
this.parent = parent;
this.parentOffset = fromIndex;
this.offset = offset + fromIndex;
this.size = toIndex - fromIndex;
this.modCount = ArrayList.this.modCount;
}
public E set(int index, E element) {
rangeCheck(index);
checkForComodification();
return l.set(index+offset, element);
}
public ListIterator<E> listIterator(final int index) {
checkForComodification();
...
}
private void checkForComodification() {
if (ArrayList.this.modCount != this.modCount)
throw new ConcurrentModificationException();
}
...
}
}- 第一,ArrayList 维护了一个叫作 modCount 的字段,表示集合结构性修改的次数。所谓结构性修改,指的是影响 List 大小的修改,所以 add 操作必然会改变 modCount 的值。
- 第二,分析第 21 到 24 行的 subList 方法可以看到,获得的 List 其实是内部类 SubList,并不是普通的 ArrayList,在初始化的时候传入了 this。
- 第三,分析第 26 到 39 行代码可以发现,这个 SubList 中的 parent 字段就是原始的 List。SubList 初始化的时候,并没有把原始 List 中的元素复制到独立的变量中保存。我们可以认为 SubList 是原始 List 的视图,并不是独立的 List。双方对元素的修改会相互影响,而且 SubList 强引用了原始的 List,所以大量保存这样的 SubList 会导致 OOM。
第四,分析第 47 到 55 行代码可以发现,遍历 SubList 的时候会先获得迭代器,比较原始 ArrayList modCount 的值和 SubList 当前 modCount 的值。获得了 SubList 后,我们为原始 List 新增了一个元素修改了其 modCount,所以判等失败抛出 ConcurrentModificationException 异常。
既然 SubList 相当于原始 List 的视图,那么避免相互影响的修复方式有两种:
- 一种是,不直接使用 subList 方法返回的 SubList,而是重新使用 new ArrayList,在构造方法传入 SubList,来构建一个独立的 ArrayList;
- 另一种是,对于 Java 8 使用 Stream 的 skip 和 limit API 来跳过流中的元素,以及限制流中元素的个数,同样可以达到 SubList 切片的目的。
//方式一:
List<Integer> subList = new ArrayList<>(list.subList(1, 4));
//方式二:
List<Integer> subList = list.stream().skip(1).limit(3).collect(Collectors.toList());修复后代码输出如下:
[2, 3, 4]
[1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
2
4可以看到,删除 SubList 的元素不再影响原始 List,而对原始 List 的修改也不会再出现 List 迭代异常。
6. 异常处理问题
6.1. 捕获和处理异常容易犯的错
“统一异常处理”方式正是我要说的第一个错:不在业务代码层面考虑异常处理,仅在框架层面粗犷捕获和处理异常。
为了理解错在何处,我们先来看看大多数业务应用都采用的三层架构:
- Controller 层负责信息收集、参数校验、转换服务层处理的数据适配前端,轻业务逻辑;
- Service 层负责核心业务逻辑,包括各种外部服务调用、访问数据库、缓存处理、消息处理等;
- Repository 层负责数据访问实现,一般没有业务逻辑。
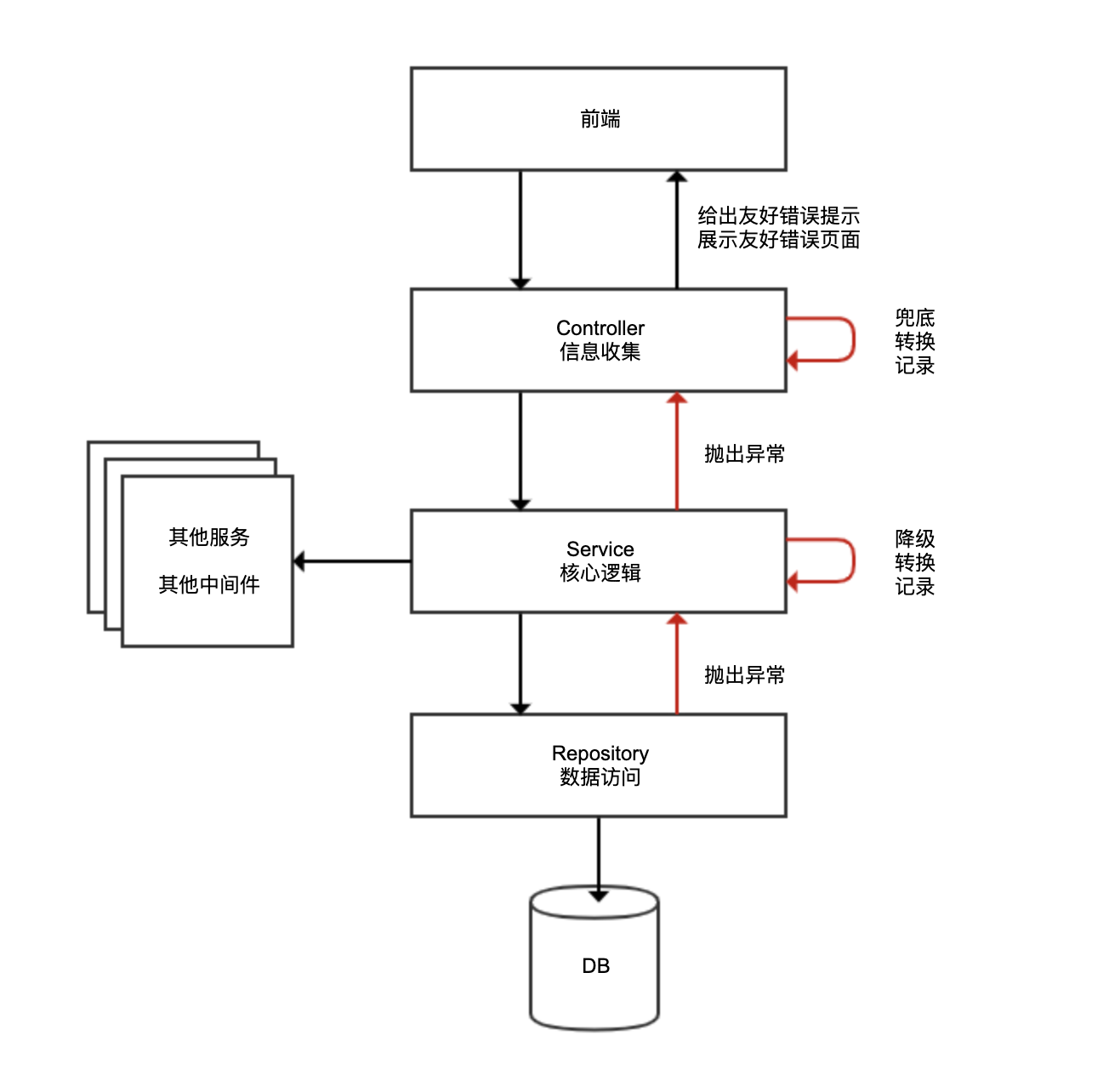
每层架构的工作性质不同,且从业务性质上异常可能分为业务异常和系统异常两大类,这就决定了很难进行统一的异常处理。我们从底向上看一下三层架构:
Repository 层出现异常或许可以忽略,或许可以降级,或许需要转化为一个友好的异常。如果一律捕获异常仅记录日志,很可能业务逻辑已经出错,而用户和程序本身完全感知不到。
Service 层往往涉及数据库事务,出现异常同样不适合捕获,否则事务无法自动回滚。此外 Service 层涉及业务逻辑,有些业务逻辑执行中遇到业务异常,可能需要在异常后转入分支业务流程。如果业务异常都被框架捕获了,业务功能就会不正常。
如果下层异常上升到 Controller 层还是无法处理的话,Controller 层往往会给予用户友好提示,或是根据每一个 API 的异常表返回指定的异常类型,同样无法对所有异常一视同仁。
因此,我不建议在框架层面进行异常的自动、统一处理,尤其不要随意捕获异常。但,框架可以做兜底工作。如果异常上升到最上层逻辑还是无法处理的话,可以以统一的方式进行异常转换,比如通过 @RestControllerAdvice + @ExceptionHandler,来捕获这些“未处理”异常:
对于自定义的业务异常,以 Warn 级别的日志记录异常以及当前 URL、执行方法等信息后,提取异常中的错误码和消息等信息,转换为合适的 API 包装体返回给 API 调用方;
对于无法处理的系统异常,以 Error 级别的日志记录异常和上下文信息(比如 URL、参数、用户 ID)后,转换为普适的“服务器忙,请稍后再试”异常信息,同样以 API 包装体返回给调用方。
第二个错,捕获了异常后直接生吞。在任何时候,我们捕获了异常都不应该生吞,也就是直接丢弃异常不记录、不抛出。这样的处理方式还不如不捕获异常,因为被生吞掉的异常一旦导致 Bug,就很难在程序中找到蛛丝马迹,使得 Bug 排查工作难上加难。
通常情况下,生吞异常的原因,可能是不希望自己的方法抛出受检异常,只是为了把异常“处理掉”而捕获并生吞异常,也可能是想当然地认为异常并不重要或不可能产生。但不管是什么原因,不管是你认为多么不重要的异常,都不应该生吞,哪怕是一个日志也好。
第三个错,丢弃异常的原始信息。我们来看两个不太合适的异常处理方式,虽然没有完全生吞异常,但也丢失了宝贵的异常信息。
6.2. 注意finally中的异常
有些时候,我们希望不管是否遇到异常,逻辑完成后都要释放资源,这时可以使用 finally 代码块而跳过使用 catch 代码块。
但要千万小心 finally 代码块中的异常,因为资源释放处理等收尾操作同样也可能出现异常。比如下面这段代码,我们在 finally 中抛出一个异常:
@GetMapping("wrong")
public void wrong() {
try {
log.info("try");
//异常丢失
throw new RuntimeException("try");
} finally {
log.info("finally");
throw new RuntimeException("finally");
}
}最后在日志中只能看到 finally 中的异常,虽然 try 中的逻辑出现了异常,但却被 finally 中的异常覆盖了。这是非常危险的,特别是 finally 中出现的异常是偶发的,就会在部分时候覆盖 try 中的异常,让问题更不明显:
[13:34:42.247] [http-nio-45678-exec-1] [ERROR] [.a.c.c.C.[.[.[/].[dispatcherServlet]:175 ] - Servlet.service() for servlet [dispatcherServlet] in context with path [] threw exception [Request processing failed; nested exception is java.lang.RuntimeException: finally] with root cause
java.lang.RuntimeException: finally至于异常为什么被覆盖,原因也很简单,因为一个方法无法出现两个异常。修复方式是,finally 代码块自己负责异常捕获和处理:
@GetMapping("right")
public void right() {
try {
log.info("try");
throw new RuntimeException("try");
} finally {
log.info("finally");
try {
throw new RuntimeException("finally");
} catch (Exception ex) {
log.error("finally", ex);
}
}
}或者可以把 try 中的异常作为主异常抛出,使用 addSuppressed 方法把 finally 中的异常附加到主异常上:
@GetMapping("right2")
public void right2() throws Exception {
Exception e = null;
try {
log.info("try");
throw new RuntimeException("try");
} catch (Exception ex) {
e = ex;
} finally {
log.info("finally");
try {
throw new RuntimeException("finally");
} catch (Exception ex) {
if (e!= null) {
e.addSuppressed(ex);
} else {
e = ex;
}
}
}
throw e;
}运行方法可以得到如下异常信息,其中同时包含了主异常和被屏蔽的异常:
java.lang.RuntimeException: try
at org.geekbang.time.commonmistakes.exception.finallyissue.FinallyIssueController.right2(FinallyIssueController.java:69)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
...
Suppressed: java.lang.RuntimeException: finally
at org.geekbang.time.commonmistakes.exception.finallyissue.FinallyIssueController.right2(FinallyIssueController.java:75)
... 54 common frames omitted其实这正是 try-with-resources 语句的做法,对于实现了 AutoCloseable 接口的资源,建议使用 try-with-resources 来释放资源,否则也可能会产生刚才提到的,释放资源时出现的异常覆盖主异常的问题。比如如下我们定义一个测试资源,其 read 和 close 方法都会抛出异常:
public class TestResource implements AutoCloseable {
public void read() throws Exception{
throw new Exception("read error");
}
@Override
public void close() throws Exception {
throw new Exception("close error");
}
}使用传统的 try-finally 语句,在 try 中调用 read 方法,在 finally 中调用 close 方法:
@GetMapping("useresourcewrong")
public void useresourcewrong() throws Exception {
TestResource testResource = new TestResource();
try {
testResource.read();
} finally {
testResource.close();
}
}可以看到,同样出现了 finally 中的异常覆盖了 try 中异常的问题:
java.lang.Exception: close error
at org.geekbang.time.commonmistakes.exception.finallyissue.TestResource.close(TestResource.java:10)
at org.geekbang.time.commonmistakes.exception.finallyissue.FinallyIssueController.useresourcewrong(FinallyIssueController.java:27)而改为 try-with-resources 模式之后:
@GetMapping("useresourceright")
public void useresourceright() throws Exception {
try (TestResource testResource = new TestResource()){
testResource.read();
}
}try 和 finally 中的异常信息都可以得到保留:
java.lang.Exception: read error
at org.geekbang.time.commonmistakes.exception.finallyissue.TestResource.read(TestResource.java:6)
...
Suppressed: java.lang.Exception: close error
at org.geekbang.time.commonmistakes.exception.finallyissue.TestResource.close(TestResource.java:10)
at org.geekbang.time.commonmistakes.exception.finallyissue.FinallyIssueController.useresourceright(FinallyIssueController.java:35)
... 54 common frames omitted6.3. 千万别把异常定义为静态变量
既然我们通常会自定义一个业务异常类型,来包含更多的异常信息,比如异常错误码、友好的错误提示等,那就需要在业务逻辑各处,手动抛出各种业务异常来返回指定的错误码描述(比如对于下单操作,用户不存在返回 2001,商品缺货返回 2002 等)。
对于这些异常的错误代码和消息,我们期望能够统一管理,而不是散落在程序各处定义。这个想法很好,但稍有不慎就可能会出现把异常定义为静态变量的坑。
我在救火排查某项目生产问题时,遇到了一件非常诡异的事情:我发现异常堆信息显示的方法调用路径,在当前入参的情况下根本不可能产生,项目的业务逻辑又很复杂,就始终没往异常信息是错的这方面想,总觉得是因为某个分支流程导致业务没有按照期望的流程进行。
经过艰难的排查,最终定位到原因是把异常定义为了静态变量,导致异常栈信息错乱,类似于定义一个 Exceptions 类来汇总所有的异常,把异常存放在静态字段中:
public class Exceptions {
public static BusinessException ORDEREXISTS = new BusinessException("订单已经存在", 3001);
...
}把异常定义为静态变量会导致异常信息固化,这就和异常的栈一定是需要根据当前调用来动态获取相矛盾。
我们写段代码来模拟下这个问题:定义两个方法 createOrderWrong 和 cancelOrderWrong 方法,它们内部都会通过 Exceptions 类来获得一个订单不存在的异常;先后调用两个方法,然后抛出。
@GetMapping("wrong")
public void wrong() {
try {
createOrderWrong();
} catch (Exception ex) {
log.error("createOrder got error", ex);
}
try {
cancelOrderWrong();
} catch (Exception ex) {
log.error("cancelOrder got error", ex);
}
}
private void createOrderWrong() {
//这里有问题
throw Exceptions.ORDEREXISTS;
}
private void cancelOrderWrong() {
//这里有问题
throw Exceptions.ORDEREXISTS;
}运行程序后看到如下日志,cancelOrder got error 的提示对应了 createOrderWrong 方法。显然,cancelOrderWrong 方法在出错后抛出的异常,其实是 createOrderWrong 方法出错的异常:
[14:05:25.782] [http-nio-45678-exec-1] [ERROR] [.c.e.d.PredefinedExceptionController:25 ] - cancelOrder got error
org.geekbang.time.commonmistakes.exception.demo2.BusinessException: 订单已经存在
at org.geekbang.time.commonmistakes.exception.demo2.Exceptions.<clinit>(Exceptions.java:5)
at org.geekbang.time.commonmistakes.exception.demo2.PredefinedExceptionController.createOrderWrong(PredefinedExceptionController.java:50)
at org.geekbang.time.commonmistakes.exception.demo2.PredefinedExceptionController.wrong(PredefinedExceptionController.java:18)修复方式很简单,改一下 Exceptions 类的实现,通过不同的方法把每一种异常都 new 出来抛出即可:
public class Exceptions {
public static BusinessException orderExists(){
return new BusinessException("订单已经存在", 3001);
}
}