针对AI增强图像大规模鲁棒性测试的数据集
Semi-Truths 是一个大规模的AI增强图像数据集,旨在评估和提升AI生成图像检测器的鲁棒性。该数据集包含了27,600张真实图像和1,472,700张通过多种增强技术生成的AI增强图像,这些图像覆盖了不同的扰动级别和数据分布。

Semi-Truths 的特点在于其详细的元数据,这些元数据描述了图像的来源、增强技术、变化幅度等,为研究者提供了标准化和针对性的评估工具。此外,数据集还包含了一个灵活的图像增强管道,支持无需人工指导的图像编辑,以及对新数据分布和图像合成技术的适应性。
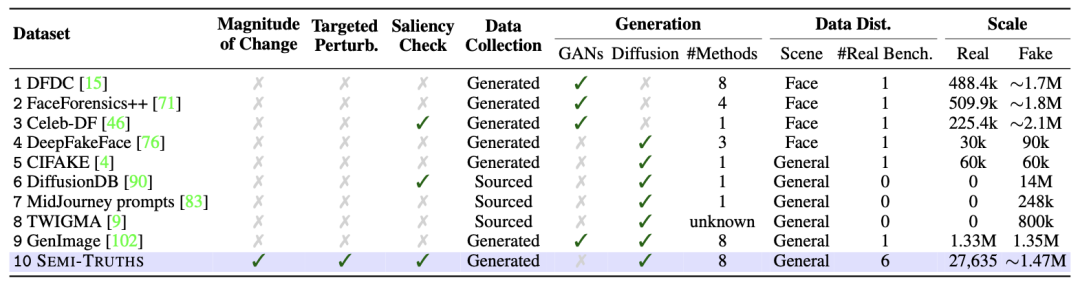
现有的先进检测器对于不同类型的扰动、数据分布和增强方法表现出不同的敏感性,这为理解检测器的性能和局限性提供了新的视角。通过压力测试和定向语义编辑,Semi-Truths揭示了检测器在特定扰动下的表现,为改进检测器提供了有价值的见解。
技术解读
Semi-Truths 数据集是为评估AI生成图像检测器的鲁棒性而设计的大规模资源,它通过结合真实图像和AI增强图像,提供了一个标准化和可定制的测试环境。该数据集利用多种增强技术和扩散模型,生成了具有不同扰动级别和数据分布的图像,每张增强图像都附带详细的元数据,包括源数据分布、增强技术、变化幅度等信息,从而为检测器的性能评估提供了丰富的上下文信息。
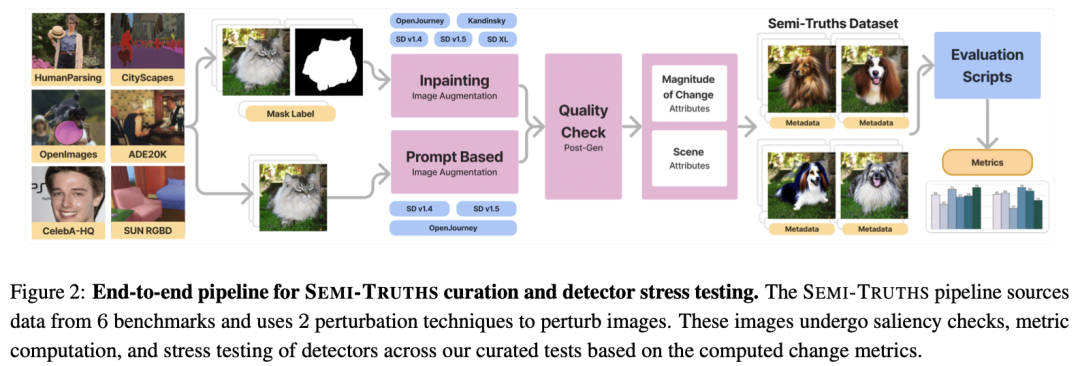
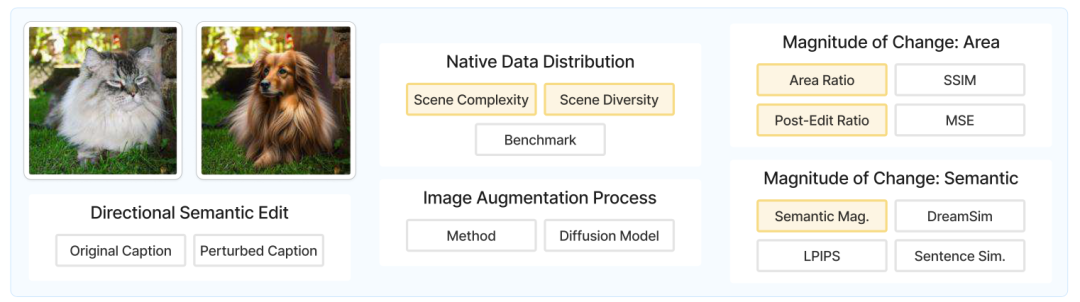
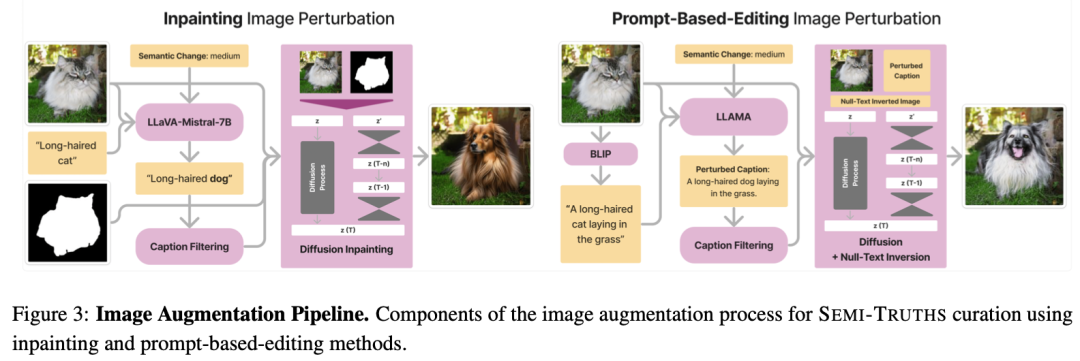
具体来说,Semi-Truths 的处理过程包括从多个语义分割数据集中获取图像和遮罩,然后使用条件绘画和基于提示的编辑技术,结合五种不同的扩散算法,生成具有精确控制变化幅度的AI增强图像。这些图像的变化幅度通过表面区域比例和语义变化程度来量化,使用了结构相似性指数(SSIM)、均方误差(MSE)和自定义度量等指标。此外,数据集还通过场景多样性和复杂性等指标,提供了对图像场景的丰富描述。
技术特点上,Semi-Truths的灵活性和可扩展性使其能够适应新数据分布和图像合成技术,其模块化的评估框架也便于研究者进行定制化的压力测试。Semi-Truths 数据集为AI生成图像检测器提供了一个全面评估的平台,不仅能够测试检测器对不同扰动的敏感性,还能够揭示检测器在特定数据分布和场景下的潜在偏见。随着AI生成技术的不断进步,Semi-Truths将为研究者提供宝贵的资源,以提高检测器的鲁棒性,对抗日益复杂的虚假信息威胁。
论文解读
这篇论文介绍了一个名为SEMI-TRUTHS的数据集,旨在评估AI生成图像检测器的鲁棒性。论文讨论了文本到图像扩散模型的应用和风险,以及现有AI生成图像检测器的有效性问题,介绍了SEMI-TRUTHS数据集,包含27600张真实图像、223400个遮罩和1472700张AI增强图像,用于评估检测器的鲁棒性。
首先,讲述文本到图像生成模型的发展,以及这些模型在艺术、设计等领域的应用和潜在的虚假信息传播风险,强调现有数据集的局限性,如缺乏多样性和对模型偏见的揭示。进而回顾AI图像生成和增强领域的进展,包括自动编码器、基于图形的技术、GANs和扩散模型,讨论了现有数据集的局限性,如单一模型来源、缺乏详细的生成和图像元数据等。
其中,详细介绍了SEMI-TRUTHS数据集的构建,包括真实图像和AI增强图像的收集、增强技术的多样性以及数据分布的广泛性,描述了如何通过改变图像区域的大小和语义变化的程度来量化图像增强的幅度。并且对图像增强管道进行介绍,包括条件绘画和基于提示的编辑技术,提供了数据集的详细属性,包括元数据和图像增强过程的描述。
通过实验,展示使用SEMI-TRUTHS数据集对AI生成图像检测器进行评估的实验结果,分析检测器对不同数据分布、扩散模型和扰动程度的敏感性。最后,总结SEMI-TRUTHS数据集的重要性,它提供了一个全面的资源,用于测试检测器在各种情况下的鲁棒性,并支持模型公平性的研究。