MATLAB图注意力网络GAT多标签图分类预测可视化
全文链接:https://tecdat.cn/?p=38321
本示例展示了如何使用图注意力网络(GATs)对具有多个独立标签的图进行分类。当数据中的观测值具有带有多个独立标签的图结构时,可以使用GAT来预测未知标签观测值的标签(点击文末“阅读原文”获取完整代码数据)。
GAT利用图结构和图节点上的可用信息,通过一种掩码多头自注意力机制聚合相邻节点的特征,并为图中的每个节点计算输出特征或嵌入。在通常情况下,使用读出(readout)或图池化操作对节点的输出特征进行聚合或汇总后,这些输出特征将用于对图进行分类。
数据集介绍
本示例使用QM7 - X数据集训练GAT,该数据集包含6950个表示分子的图。每个分子由最多23个原子(以节点表示)组成。数据集中包含5种独特的原子:碳(C)、氢(H)、氮(N)、氧(O)和硫(S)。原子的三种物理化学性质(标量Hirshfeld偶极矩、原子极化率和范德华半径)被用作节点信息。图标签是在分子形成中起重要作用的官能团或特定原子组。每个官能团代表一个子图,因此,如果代表图的分子没有官能团,则图可以有多个标签或没有标签。本示例考虑的官能团有CH、CH2、CH3、N、NH、NH2、NOH和OH。
数据准备
(一)加载数据
数据是一个包含5个字段的结构体。atNUM字段包含原子序数,atXYZ字段包含节点坐标,hDIP、atPOL和vdwR字段包含节点特征。数据总共由6950个图组成,每个图最多有23个节点。对于节点数少于23个的图,数据用零填充。
(二)准备训练数据
提取和连接节点特征
features = cat(3,dataQM7X.hDIP,dataQM7X.atPOL,dataQM7X.vdwR)
features = permute(features,\[1 3 2\])构建邻接矩阵数据
atomicNumber = dataQM7X.atNUM
coordinates = dataQM7X.atXYZ
adjacency = coordinates2Adjacency(coordinates,atomicNumber)提取标签
labels = uniqueFunctionalGroups(adjacency,atomicNumber)划分数据集
对训练特征(不包括填充数据的零元素)进行归一化:
numGraphsTrain = size(featuresTrain,3)
for j = 1:numGraphsTrain
validIdx = 1:nnz(featuresTrain(:,1,j))
featuresTrain(validIdx,:,j) = (featuresTrain(validIdx,:,j) - muX)./sqrt(sigsqX)
end对验证特征使用相同的统计数据进行归一化,并排除填充数据的零元素
获取类别名称和编码训练标签
可视化每个类别的图数量:
classCounts = sum(TTrain,1)
figure
bar(classCounts)
ylabel("Count")
xticklabels(classNames)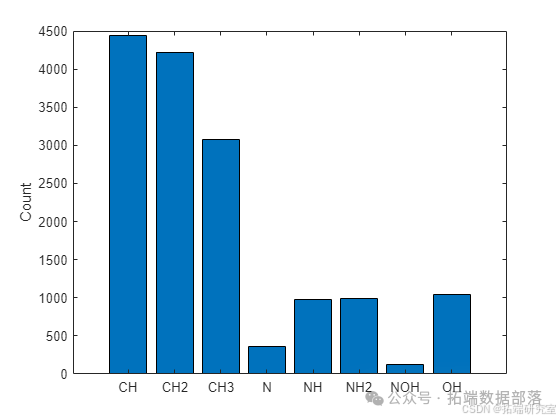
可视化每个图的标签数量
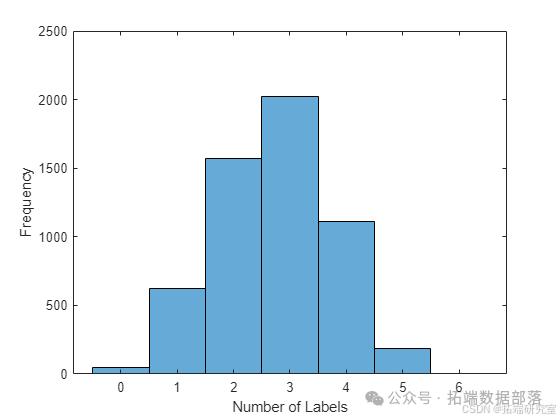
对验证标签进行编码
创建数据存储和组合数据
为验证特征和邻接数据创建数据存储并组合:
featuresValidation = arrayDatastore(featuresValidation,IterationDimension=3)
adjacencyValidation = arrayDatastore(adjacencyValidation,IterationDimension=3)
dsValidation = combine(featuresValidation,adjacencyValidation)模型定义
(一)模型概述
模型输入特征矩阵X和邻接矩阵A,输出分类预测。模型利用掩码多头自注意力机制聚合节点邻域的特征(节点邻域是指与该节点直接相连的节点集合),邻接矩阵生成的掩码用于防止不同邻域节点之间的注意力计算。模型在前两个注意力算子后使用ELU非线性激活函数,并在最后两个注意力算子之间使用跳跃连接以帮助收敛。利用平均法对输出节点特征进行图级预测,最后使用sigmoid操作计算独立的类别概率。
(二)初始化模型参数
创建注意力头数量结构体
numHeads = struct
numHeads.attn1 = 3
numHeads.attn2 = 3
numHeads.attn3 = 5创建模型可学习参数结构体并初始化权重
初始化第二个注意力操作的权重
初始化第三个注意力操作的权重
(三)定义模型函数和损失函数
创建model函数,其输入模型参数、输入特征和邻接矩阵以及每个图的节点数,返回标签预测。创建modelLoss函数,其输入模型参数、一批输入特征和相应的邻接矩阵、每个图的节点数以及相应的编码标签目标,返回损失、损失相对于可学习参数的梯度以及模型预测。
训练选项指定
训练70个轮次,小批量大小为300。GATs的大训练小批量数据可能导致内存不足错误,如果硬件内存不足,则减小小批量大小。训练学习率为0.01,将预测概率转换为二进制编码标签的阈值设为0.5,每210次迭代验证一次模型。
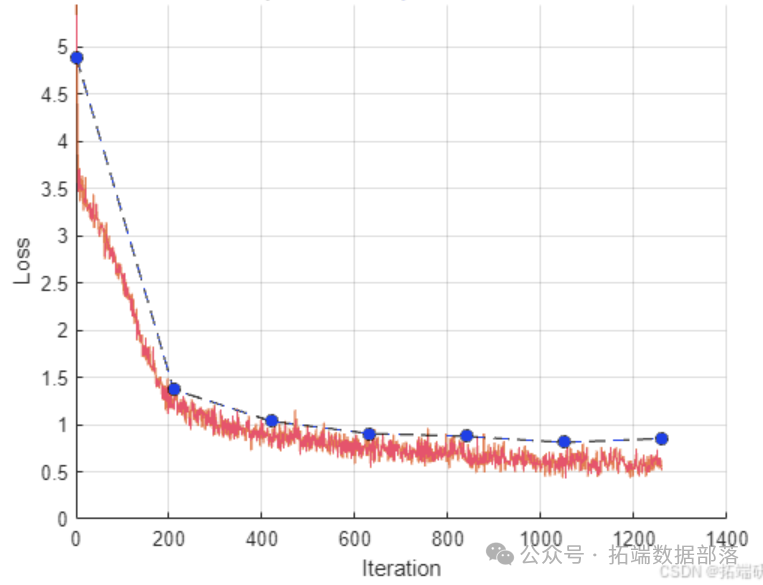
模型训练
使用自定义训练循环训练模型。利用minibatchqueue处理和管理训练数据小批量。对于每次迭代和小批量:丢弃部分小批量;使用自定义小批量预处理函数preprocessMiniBatch去除数据中的零填充,计算每个图的节点数,并将多个图实例合并为单个图实例;将输出数据类型转换为double;仅将特征数据转换为dlarray对象;如果有GPU可用,则在GPU上训练。
设置验证数据的数据存储读取大小:
dsValidation.UnderlyingDatastores{1}.ReadSize = miniBatchSize
dsValidation.UnderlyingDatastores{2}.ReadSize = miniBatchSize初始化Adam优化器参数:
trailingAvg = \[\]
trailingAvgSq = \[\]训练模型:
点击标题查阅往期内容

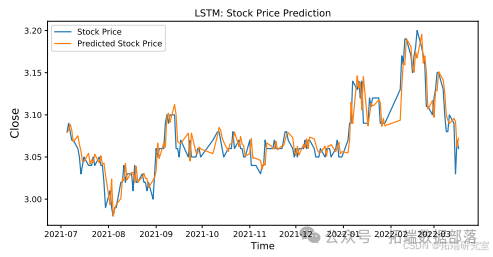
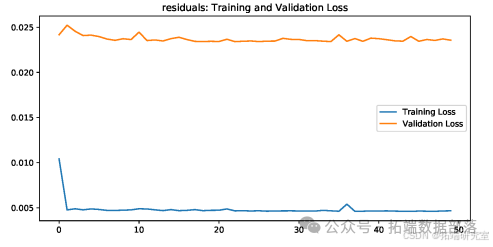
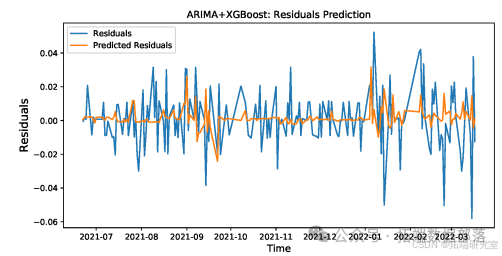
Python注意力机制Attention下CNN-LSTM-ARIMA混合模型预测中国银行股票价格|附数据代码

左右滑动查看更多
01
02
03
04
模型测试
如果有GPU可用,将测试数据转换为gpuArray对象,并使用训练特征的统计数据对测试特征进行归一化。创建测试特征和邻接数据的数据存储并组合,对测试标签进行编码。
使用modelPredictions函数对测试数据进行预测,并将预测概率转换为二进制编码标签,通过计算F - score评估性能。
可视化每个类别的混淆矩阵和接收者操作特征(ROC)曲线。
使用新数据预测
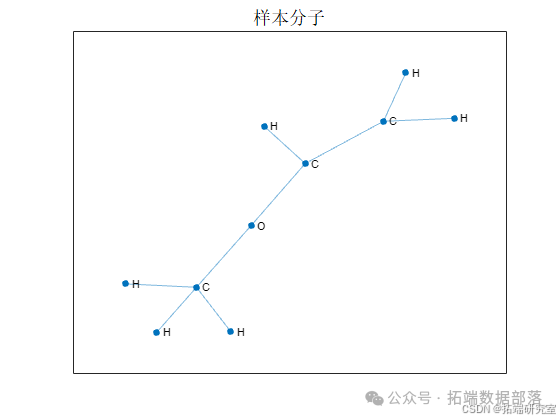
加载预处理的QM7X样本数据,获取邻接矩阵和节点特征,显示图的节点数,提取图数据,将原子序数映射为符号并显示图。
将特征转换为dlarray对象,如果有GPU可用则转换为gpuArray,使用model函数进行预测并将预测概率转换为二进制编码标签,可视化注意力分数。
模型相关函数介绍
model函数:输入模型参数、特征矩阵、邻接矩阵、每个图的节点数和头数,返回预测和注意力分数。在每层使用graphAttention函数计算图注意力,前两层使用ELU非线性激活函数,在隐藏层使用残差连接,在最后一层后使用globalAveragePool函数执行读出操作,使用sigmoid函数计算标签预测作为独立的类别概率。modelLoss函数:输入模型参数、特征矩阵、邻接矩阵、每个图的节点数、二进制编码标签返回损失相对于模型参数的梯度、相应的损失和模型预测。
总结
本文详细介绍了基于图注意力网络的多标签图分类方法,包括数据准备、模型定义、训练过程、测试过程以及使用新数据进行预测等环节,并对模型相关的各个函数进行了阐述。这种方法在处理具有图结构和多个独立标签的数据时具有一定的优势,可以为相关领域的研究和应用提供有效的分类模型,在化学分子等具有图结构的数据分类问题中有着潜在的应用价值,通过对模型参数的合理设置和训练,可以提高分类的准确性和可靠性,为进一步的分析和决策提供有力支持。同时,不同的函数在模型的构建和运行中发挥着各自独特的作用,共同构成了完整的图分类系统。但需要注意的是,训练GAT是一个计算密集型任务,在实际应用中需要考虑硬件资源的限制。此外,对于模型的改进和优化可以进一步探索,以适应更复杂的数据集和应用场景。

本文中分析的数据、代码分享到会员群,扫描下面二维码即可加群!

资料获取
在公众号后台回复“领资料”,可免费获取数据分析、机器学习、深度学习等学习资料。

点击文末“阅读原文”
获取全文完整代码数据资料。
本文选自《MATLAB图注意力网络GAT多标签图分类预测可视化》。
点击标题查阅往期内容
【视频讲解】Python深度神经网络DNNs-K-Means(K-均值)聚类方法在MNIST等数据可视化对比分析
MATLAB用CNN-LSTM神经网络的语音情感分类深度学习研究
Python用CEEMDAN-LSTM-VMD金融股价数据预测及SVR、AR、HAR对比可视化
Python注意力机制Attention下CNN-LSTM-ARIMA混合模型预测中国银行股票价格|附数据代码
R语言KERAS用RNN、双向RNNS递归神经网络、LSTM分析预测温度时间序列、 IMDB电影评分情感
Python用CNN-LSTM、ARIMA、Prophet股票价格预测的研究与分析|附数据代码
【视频讲解】线性时间序列原理及混合ARIMA-LSTM神经网络模型预测股票收盘价研究实例
RNN循环神经网络 、LSTM长短期记忆网络实现时间序列长期利率预测
结合新冠疫情COVID-19股票价格预测:ARIMA,KNN和神经网络时间序列分析
深度学习:Keras使用神经网络进行简单文本分类分析新闻组数据
用PyTorch机器学习神经网络分类预测银行客户流失模型
PYTHON用LSTM长短期记忆神经网络的参数优化方法预测时间序列洗发水销售数据
Python用Keras神经网络序列模型回归拟合预测、准确度检查和结果可视化
R语言深度学习卷积神经网络 (CNN)对 CIFAR 图像进行分类:训练与结果评估可视化
深度学习:Keras使用神经网络进行简单文本分类分析新闻组数据
Python用LSTM长短期记忆神经网络对不稳定降雨量时间序列进行预测分析
R语言深度学习Keras循环神经网络(RNN)模型预测多输出变量时间序列
R语言KERAS用RNN、双向RNNS递归神经网络、LSTM分析预测温度时间序列、 IMDB电影评分情感
Python用Keras神经网络序列模型回归拟合预测、准确度检查和结果可视化
Python用LSTM长短期记忆神经网络对不稳定降雨量时间序列进行预测分析
R语言中的神经网络预测时间序列:多层感知器(MLP)和极限学习机(ELM)数据分析报告
R语言深度学习:用keras神经网络回归模型预测时间序列数据
Matlab用深度学习长短期记忆(LSTM)神经网络对文本数据进行分类
R语言KERAS深度学习CNN卷积神经网络分类识别手写数字图像数据(MNIST)
MATLAB中用BP神经网络预测人体脂肪百分比数据
Python中用PyTorch机器学习神经网络分类预测银行客户流失模型
R语言实现CNN(卷积神经网络)模型进行回归数据分析
SAS使用鸢尾花(iris)数据集训练人工神经网络(ANN)模型
【视频】R语言实现CNN(卷积神经网络)模型进行回归数据分析
Python使用神经网络进行简单文本分类
R语言用神经网络改进Nelson-Siegel模型拟合收益率曲线分析
R语言基于递归神经网络RNN的温度时间序列预测
R语言神经网络模型预测车辆数量时间序列
R语言中的BP神经网络模型分析学生成绩
matlab使用长短期记忆(LSTM)神经网络对序列数据进行分类
R语言实现拟合神经网络预测和结果可视化
用R语言实现神经网络预测股票实例
使用PYTHON中KERAS的LSTM递归神经网络进行时间序列预测
python用于NLP的seq2seq模型实例:用Keras实现神经网络机器翻译
用于NLP的Python:使用Keras的多标签文本LSTM神经网络分类



![]()
