[Redis#2] 定义 | 使用场景 | 安装教程 | 快!
目录
1. 定义
In-memory data structures 在内存中存储数据
2. 优点!快
Programmability 可编程性
Extensibility 扩展性
Persistence 持久化
Clustering 分布式集群
High availability 高可用性
⭕快速访问的实现
3. 使用场景
1.Real-time data store
2.Caching & session storage
Session Storage
如何解决上述问题?
3.Streaming & messaging
4. 安装 redis
配置Redis支持远程连接
重启Redis服务
测试连接
注意事项
5.关于
客户端
快!
1. 定义
In-memory data structures 在内存中存储数据
- support for strings, hashes, lists, sets, sorted sets, streams, and more.
-
- key 都是 string
- value 则可以是上述的数据结构
2. 优点!快

Programmability 可编程性
- Server-side scripting with Lua and server-side stored procedures with Redis Functions.
Extensibility 扩展性
- A module API for building custom extensions to Redis in C, C++, and Rust.
- 通过这几个语言编写 Redis 扩展(本质上就是一个动态链接库)
-
- 自己去扩展 Redis 的功能。
- 比如:Redis 自身已经提供了很多的数据结构和命令。通过扩展,让 Redis 支持更多的数据结构以及支持更多的命令。
- 类似于 linux 的动态库.so 实现扩展
Persistence 持久化
- Keeps the dataset in memory for fast access but can also persist all writes to permanent storage to survive reboots and system failures.
-
- 内存中的数据是“易失”的。
- 进程退出/系统重启后,Redis 会把数据存储在硬盘上。
- 内存为主,硬盘为辅。(硬盘相当于对内存的数据备份了一下)
Clustering 分布式集群
- Horizontal scalability with hash-based sharding, scaling to millions of nodes with automatic re-partitioning when growing the cluster.
-
- Redis 作为一个分布式系统中的中间件,能够支持集群是很关键的~~
- 这个水平扩展,类似于 "分库表"
- 一个 Redis 能存储的数据是有限的(内存空间有限)
- 引入多个主机,部署多个 Redis 节点。每个 Redis 存储数据的一部分
High availability 高可用性
- Replication with automatic failover for both standalone and clustered deployments.
- 高可用 ==冗余 / 备份
Redis 自身也是支持 "主从" 结构的。 从节点相当于主节点的备份。
⭕快速访问的实现
- Redis 数据在内存中,就比访问硬盘的数据库要快很多。
- Redis 核心功能都是比较简单的逻辑,比较简单地操作内存的数据结构。
- 从网络角度上,Redis 使用了 IO 多路复用的方式 (epoll)。
使用一个线程管理很多个 socket ~
- Redis 使用的是单线程模型(虽然更高版本的 Redis 引入了多线程)。
-
- 这样的单线程模型,减少了不必要的线程之间的竞争开销。
- 线程提高了效率的前提是 CPU 密集型的任务。使用多线程可以充分的利用 CPU 多核资源。
- [个人不太认可,但是网上这么说的很多]
- Redis 是使用 C 语言开发的,所以就快。
-
- MySQL 也是 C 语言开发的。
注意:在对 redis 的优点进行理解,很多都是相较于 mysql 的
3. 使用场景
1.Real-time data store
- 做数据库
Redis' versatile in-memory data structures enable building data infrastructure for real-time applications that require low latency and high throughput.
- 大多数情况下,考虑到数据存储,优先考虑的是“大”数据存储。
- 但是仍然有一些场景,考虑的是“快”。
例如:
- 搜索引擎 -> 广告搜索(商业搜索)
对于性能要求是非常高的~
搜索所有没有用到MySQL这样的数据库~~ - 当然,使用这样的内存数据库,存储大量的数据,需要不少的硬件资源的~~ 充值了。
- Redis 存的是全量数据,这里的数据是不能随便丢的~~
2.Caching & session storage
- 缓存热点数据
Redis speed makes it ideal for caching database queries, complex computations, API calls, and session state.
- 使用 MySQL 存数据,大慢。
二八原则,把热点数据拎出来,存储在 redis 中的。 - Redis 存的是部分数据
- 全量数据都是以 mysql 为主的。
哪怕 Redis 的数据没了,还可以从 mysql 这边再加载回来~~
Session Storage
Cookie
- 实现用户身份信息的保存,浏览器这边存储了一个用户的 sessionId
需要 session 配合,才可调用到真正的用户数据
- 之前 senssion 是存储在应用服务器上的
- 现在可以运用 Redis存储 session 信息,实现高效调用
用户访问网页的思考:
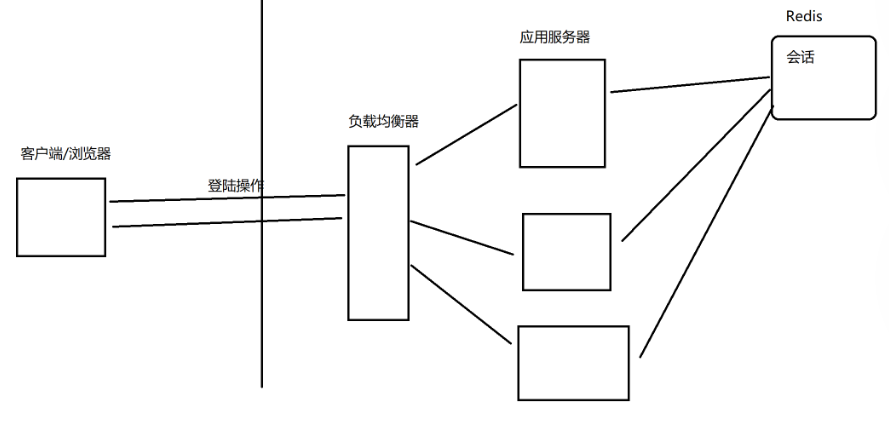
如何解决上述问题?
- 让负载均衡器将同一个用户的请求始终打到同一台服务器上(不能轮询,而是通过 userId 类似的方式来分配服务器)
- 把会话数据单独拿出来放到一组独立的机器上存储(Redis)
3.Streaming & messaging
The stream data type enables high-rate data ingestion, messaging, event sourcing, and notifications.
- 消息队列(服务器),不是 Linux 进程间通信的那个消息队列(这个可以忘记了~~
- 基于这个可以实现一个网络版本的生产者消费者模型~~
- 业界也有很多知名的消息队列,比如 RabbitMQ、Kafka、RocketMQ……
Redis 也提供了消息队列的功能。 - 如果当前场景中,对于消息队列的功能依赖的不多,并且又不想引入额外的依赖,Redis 可以作为一个选择。
Redis 不能做的事情?
存储大规模数据~
💡阅读官方文档是最有效的学习方式,上文就是对官方文档的一些批注
4. 安装 redis
首先,确保你的系统是最新的。可以通过运行以下命令来更新你的软件包列表:
sudo apt update然后,使用apt安装Redis:
sudo apt install redis-server -y配置Redis支持远程连接
默认情况下,Redis仅监听本地回环接口(127.0.0.1),这意味着只有在同一台机器上的客户端才能连接到Redis服务器。为了允许从其他机器进行连接,你需要编辑Redis的配置文件。
- 打开Redis配置文件:使用文本编辑器(如nano或vim)打开Redis配置文件
/etc/redis/redis.conf:
sudo nano /etc/redis/redis.conf- 修改绑定地址:找到
bind指令,默认可能设置为127.0.0.1。将其更改为0.0.0.0,以便Redis监听所有网络接口。如果bind行前面有注释符号(#),请删除该符号以取消注释此行:
# bind 127.0.0.1
bind 0.0.0.0- 关闭保护模式:找到
protected-mode指令,并将其值从yes更改为no。保护模式是一种安全特性,当Redis没有密码保护并且监听非本地网络接口时,会阻止某些命令的执行。由于我们正在开放Redis以接受远程连接,因此需要关闭保护模式:
protected-mode no
- 保存并退出:完成编辑后,保存文件并退出编辑器。如果你使用的是nano,可以通过按
Ctrl+O保存,然后按Ctrl+X退出。
重启Redis服务
为了让更改生效,你需要重启Redis服务:
sudo service redis-server restart测试连接
此时可以通过redis-cli命令进入Redis客户端
问题

解决:

如果进入客户端后,输入ping返回一个PONG,那么就算安装成功了。ctrl+d 可以退出~
注意事项
- 开启Redis的远程访问前,请确保已经配置了合适的防火墙规则,只允许受信任的IP地址访问Redis端口。
- 考虑设置一个密码来增强安全性。可以在
/etc/redis/redis.conf中找到requirepass指令并设置一个强密码。 - 如果你的Redis服务器暴露在互联网上,建议使用SSL/TLS加密通信,以防止数据泄露。
完成上述步骤后,Redis服务器应该已经配置好可以接受远程连接啦
5.关于
客户端
- Redis 客户端也是一个客户端-服务器结构的程序!!
- MySQL 也是
- Redis 客户端和服务端可以在同一个主机上,也可以在不同主机上。(当前阶段,我们一般只有一台机器,此时客户端和服务端就是在同一个机器上)
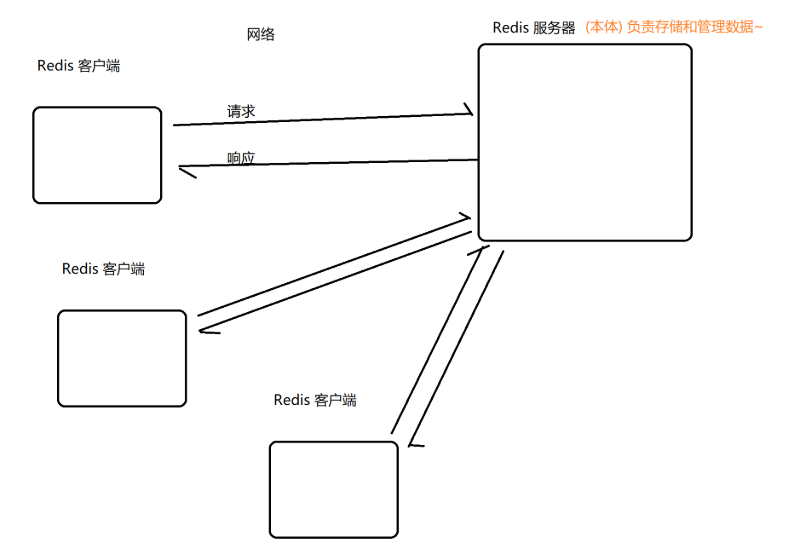
Redis 的客户端也有多种形式:
1. 自带了命令行客户端
[ 之后的文章主要使用这个客户端]
root@bit:~# redis-cli
127.0.0.1:6379>
root@bit:~# redis-cli -h 127.0.0.1 -p 6379
127.0.0.1:6379>2. 图形化界面的客户端
(桌面程序, web 程序)
3. 基于 redis 的 api 自行开发客户端[工作中最主要的形态]
- 非常类似于 mysql 的 C 语言 API 和 JDBC
快!
- 我们谈到的 redis 的快,是相对于 mysql 这样的关系型数据库的。
- 但是如果直接和内存中的操作变量相比,就没有优势了,甚至更慢了!!
- redis 是先通过网络!!再操作内存
是否引入一个技术,一定要想清楚来龙去脉,想清楚能够解决啥问题,引入了啥问题。
千万不能 “无脑” 使用。不能有“锤子思维”
是否要使用 redis?
对症下药,具体问题具体分析,要结合实际的需求来确定!!!
例如:

引入 redis 的缺点,会更慢。
- 但是有了 redis 之后,可以通过网络,把数据单独存储。
- 后续应用服务器重启,不会影响到数据内容。
- 未来要扩展成分布式系统,使用 redis 是更佳的选择。