o1的风又吹到多模态,直接吹翻了GPT-4o-mini
开源LLaVA-o1:一个设计用于进行自主多阶段推理的新型VLM。与思维链提示不同,LLaVA-o1独立地参与到总结、视觉解释、逻辑推理和结论生成的顺序阶段。
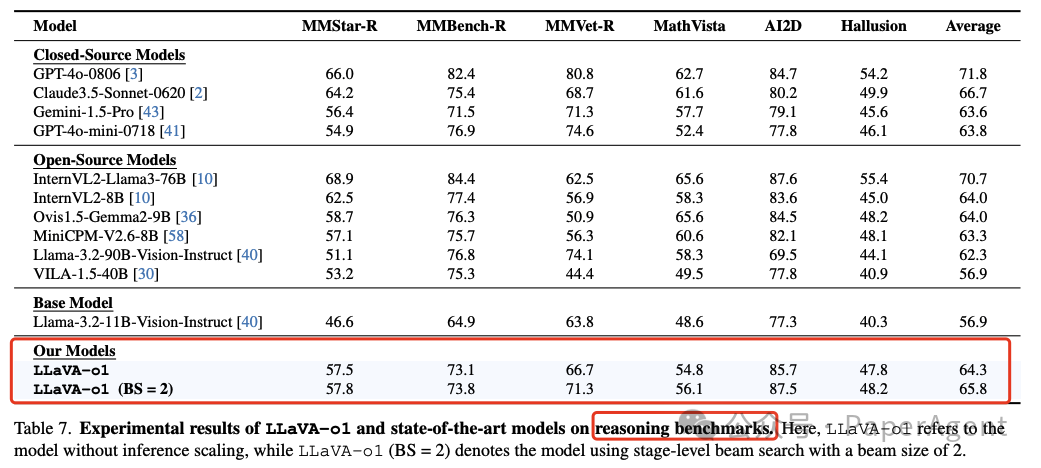
LLaVA-o1超过了一些更大甚至是闭源模型的性能,例如Gemini-1.5-pro、GPT-4o-mini和Llama-3.2-90B-Vision-Instruct。

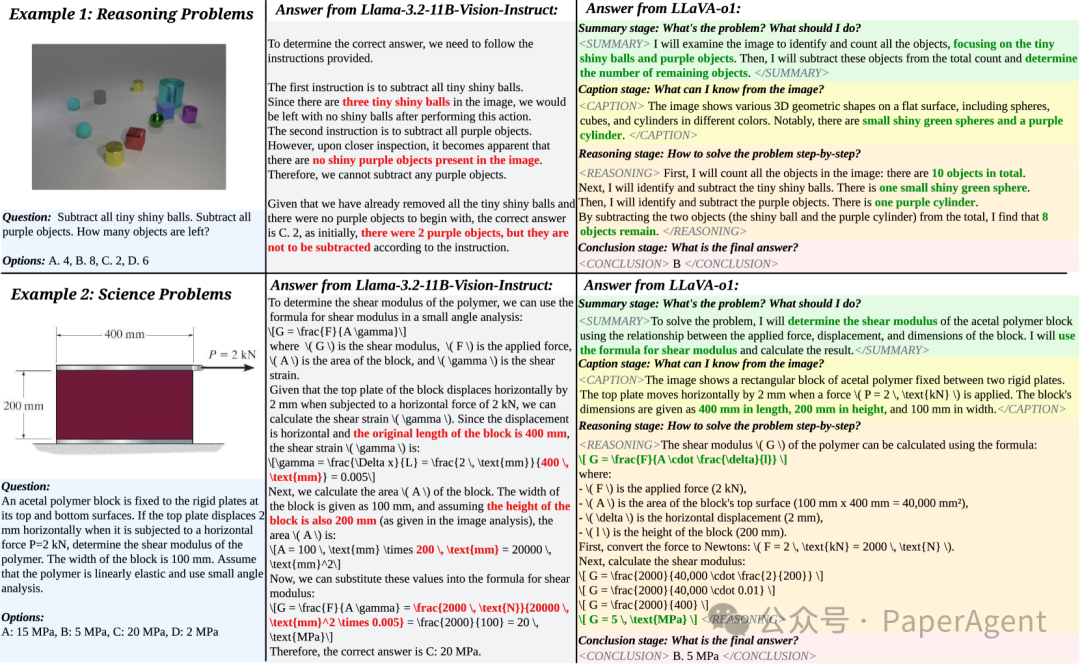
基础模型与LLaVA-o1的比较。基础模型Llama-3.2-11B-Vision-Instruct在推理过程中有明显的缺陷,整个推理过程中出现了几个错误。相比之下,LLaVA-o1首先概述问题,从图像中解释相关信息,然后进行逐步推理过程,并最终得出一个有充分支持的结论。
LLaVA-o1如何炼成
LLaVA-o1模型的结构化推理框架,专门的数据集和训练方法,以及推理时的阶段性束搜索策略,来提高模型在复杂任务中的推理能力和扩展性。
-
结构化推理阶段:
-
总结阶段(Summary Stage):LLaVA-o1在这一阶段提供对问题的高层次总结,概述它打算解决的问题的主要方面。
-
图像描述阶段(Caption Stage):如果存在图像,LLaVA-o1提供与问题相关的图像元素的简洁概述,帮助理解多模态输入。
-
推理阶段(Reasoning Stage):在初始总结的基础上,LLaVA-o1进行结构化、逻辑推理,得出初步答案。
-
结论阶段(Conclusion Stage):在最后阶段,LLaVA-o1根据前面的推理综合答案。结论阶段的输出是直接提供给用户的响应,而前三个阶段是内部的“隐藏阶段”,代表LLaVA-o1的推理过程。
-
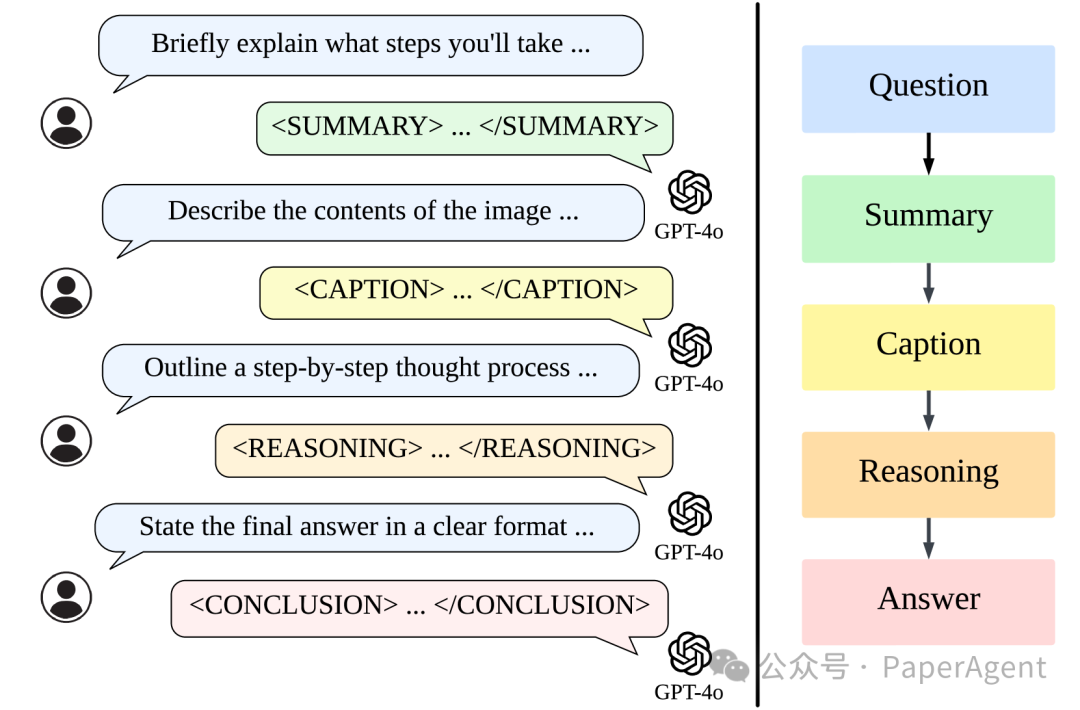
四对特殊标签:<SUMMARY></SUMMARY>、<CAPTION></CAPTION>、<REASONING></REASONING>和<CONCLUSION></CONCLUSION>
-
-
数据准备和模型训练:
-
由于现有的视觉问题回答(VQA)数据集缺乏训练LLaVA-o1所需的详细推理过程,研究者们编译了一个新的数据集LLaVA-o1-100k,整合了多个广泛使用的VQA数据集的样本。
-
使用GPT-4o生成包括总结、图像描述、推理和结论的详细推理过程,并将这些编译成LLaVA-o1-100k数据集。
-
选择了Llama-3.2-11B-Vision-Instruct模型作为基础模型,并使用LLaVA-o1-100k数据集进行全参数微调。
-
-
有效的推理时扩展使用阶段性束搜索:
-
训练完成后的目标是在推理期间进一步增强模型的推理能力。LLaVA-o1的输出设计为结构化,提供了理想的粒度,用于推理时扩展。
-
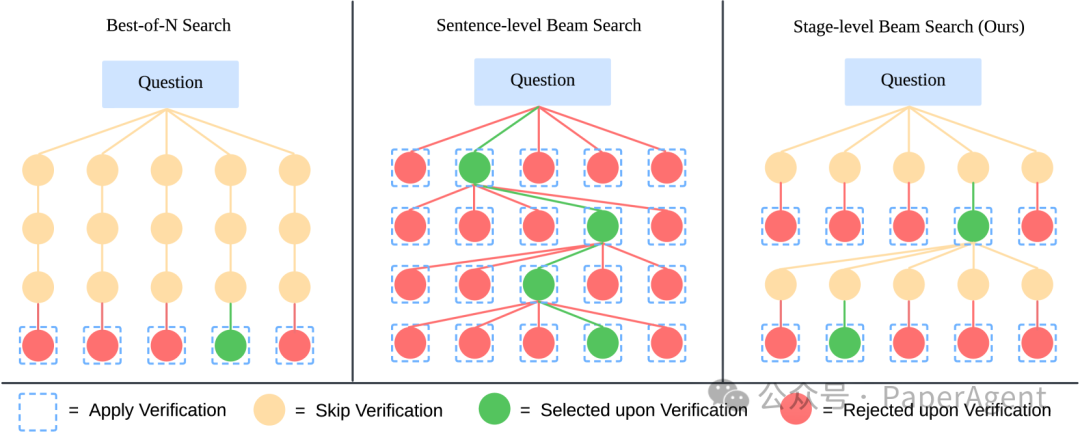
采用阶段性束搜索方法,该方法在每个推理阶段生成多个候选结果,并选择最佳结果以继续生成过程。
-
通过在每个阶段进行有效的验证,这种方法验证了结构化输出在提高推理时扩展中的有效性。
-
推理方法的示意图。最佳选择法(Best-of-N search)生成N个完整的响应,并从中选择最好的一个;句子级束搜索(Sentence-level Beam Search)为每个句子生成多个候选项并选择最好的一个。相比之下,LLaVA-o1的阶段性束搜索(Stage-level Beam Search)为每个推理阶段(例如,总结、标题、推理和结论)生成候选项,并在每个阶段选择最佳选项。最佳选择法在粗略层面上操作,而句子级束搜索过于细致,而LLaVA-o1的方法实现了最佳平衡并取得了最佳性能。
有无阶段性束搜索的LLaVA-o1性能比较。LLaVA-o1的阶段性束搜索在模型推理过程中有效地选择了更好的推理。

实验数据
-
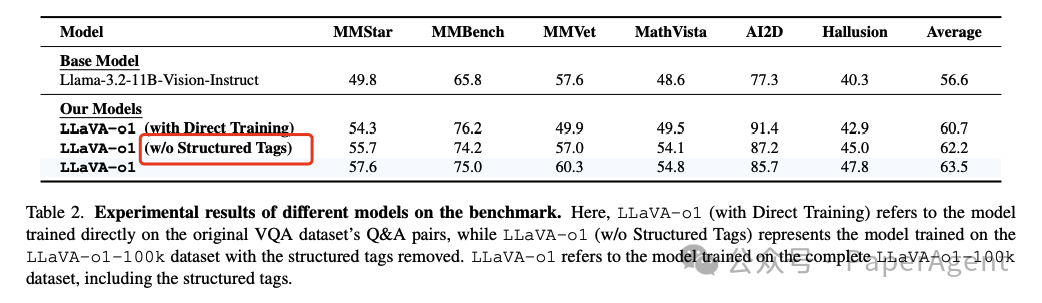
LLaVA-o1在多模态推理基准测试中相较于其基础模型Llama-3.2-11B-Vision-Instruct实现了8.9%的性能提升。
-
LLaVA-o1在各种基准测试中不仅超越了基础模型,还超过了一些更大甚至是闭源模型,例如Gemini-1.5-pro、GPT-4o-mini和Llama-3.2-90B-Vision-Instruct。
-
结构化标签(structured tags)对于模型性能至关重要。去除这些标签后,模型性能显著下降,说明这些标签有助于推理过程并提高了模型性能。
https://arxiv.org/pdf/2411.10440LLaVA-o1: Let Vision Language Models Reason Step-by-Stephttps://github.com/PKU-YuanGroup/LLaVA-o1
来源 | PaperAgent