Spring AI 框架使用的核心概念
一、模型(Model)
AI 模型是旨在处理和生成信息的算法,通常模仿人类的认知功能。通过从大型数据集中学习模式和见解,这些模型可以做出预测、文本、图像或其他输出,从而增强各个行业的各种应用。
AI 模型有很多种,每种都适用于特定的用例。虽然 ChatGPT 及其生成 AI 功能通过文本输入和输出吸引了用户,但许多模型和公司都提供不同的输入和输出。在 ChatGPT 之前,许多人都对文本到图像的生成模型着迷,例如 Midjourney 和 Stable Diffusion。
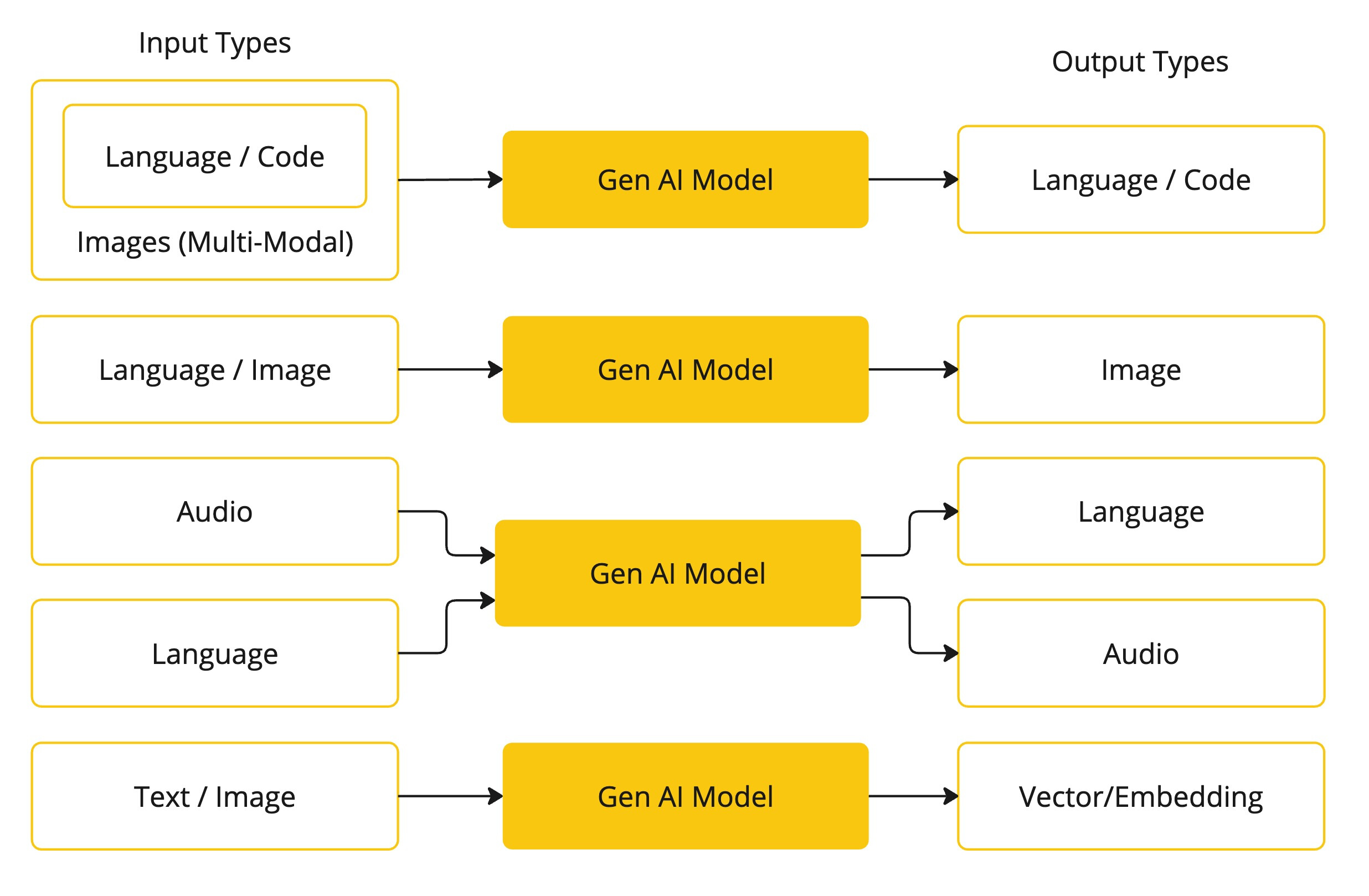
Spring AI 目前支持以语言、图像和音频形式处理输入和输出的模型。上表中的最后一行接受文本作为输入并输出数字,通常称为嵌入文本(Embedding Text),用来表示 AI 模型中使用的内部数据结构。Sprig AI 提供了对 Embedding 的支持以支持开发更高级的应用场景。
GPT 等模型的独特之处在于其预训练特性,正如 GPT 中的“P”所示——Chat Generative Pre-trained Transformer。这种预训练功能将 AI 转变为通用的开发工具,开发者使用这种工具不再需要广泛的机器学习或模型训练背景。
二、提示(Prompt)
Prompt作为语言基础输入的基础,指导AI模型生成特定的输出。对于熟悉ChatGPT的人来说,Prompt似乎只是输入到对话框中的文本,然后发送到API。然而,它的内涵远不止于此。在许多AI模型中,Prompt的文本不仅仅是一个简单的字符串。
ChatGPT的API包含多个文本输入,每个文本输入都有其角色。例如,系统角色用于告知模型如何行为并设定交互的背景。还有用户角色,通常是来自用户的输入。
撰写有效的Prompt既是一门艺术,也是一门科学。ChatGPT旨在模拟人类对话,这与使用SQL“提问”有很大的区别。与AI模型的交流就像与另外一个人对话一样。
这种互动风格的重要性使得“Prompt工程”这一学科应运而生。现在有越来越多的技术被提出,以提高Prompt的有效性。投入时间去精心设计Prompt可以显著改善生成的输出。
分享Prompt已成为一种共同的实践,且正在进行积极的学术研究。例如,最近的一篇研究论文发现,最有效的Prompt之一可以以“深呼吸一下,分步进行此任务”开头。这表明语言的重要性之高。我们尚未完全了解如何充分利用这一技术的前几代版本,例如ChatGPT 3.5,更不用说正在开发的新版本了。
提示词模板(Prompt Template)
创建有效的Prompt涉及建立请求的上下文,并用用户输入的特定值替换请求的部分内容。这个过程使用传统的基于文本的模板引擎来进行Prompt的创建和管理。Spring AI采用开源库StringTemplate来实现这一目的。
例如,考虑以下简单的Prompt模板:
Tell me a {adjective} joke about {content}.
在Spring AI中,Prompt模板可以类比于Spring MVC架构中的“视图”。一个模型对象,通常是java.util.Map,提供给Template,以填充模板中的占位符。渲染后的字符串成为传递给AI模型的Prompt的内容。
传递给模型的Prompt在具体数据格式上有相当大的变化。从最初的简单字符串开始,Prompt逐渐演变为包含多条消息的格式,其中每条消息中的每个字符串代表模型的不同角色。
三、嵌入(Embedding)
嵌入(Embedding)是文本、图像或视频的数值表示,能够捕捉输入之间的关系,Embedding通过将文本、图像和视频转换为称为向量(Vector)的浮点数数组来工作。这些向量旨在捕捉文本、图像和视频的含义,Embedding数组的长度称为向量的维度。
通过计算两个文本片段的向量表示之间的数值距离,应用程序可以确定用于生成嵌入向量的对象之间的相似性。
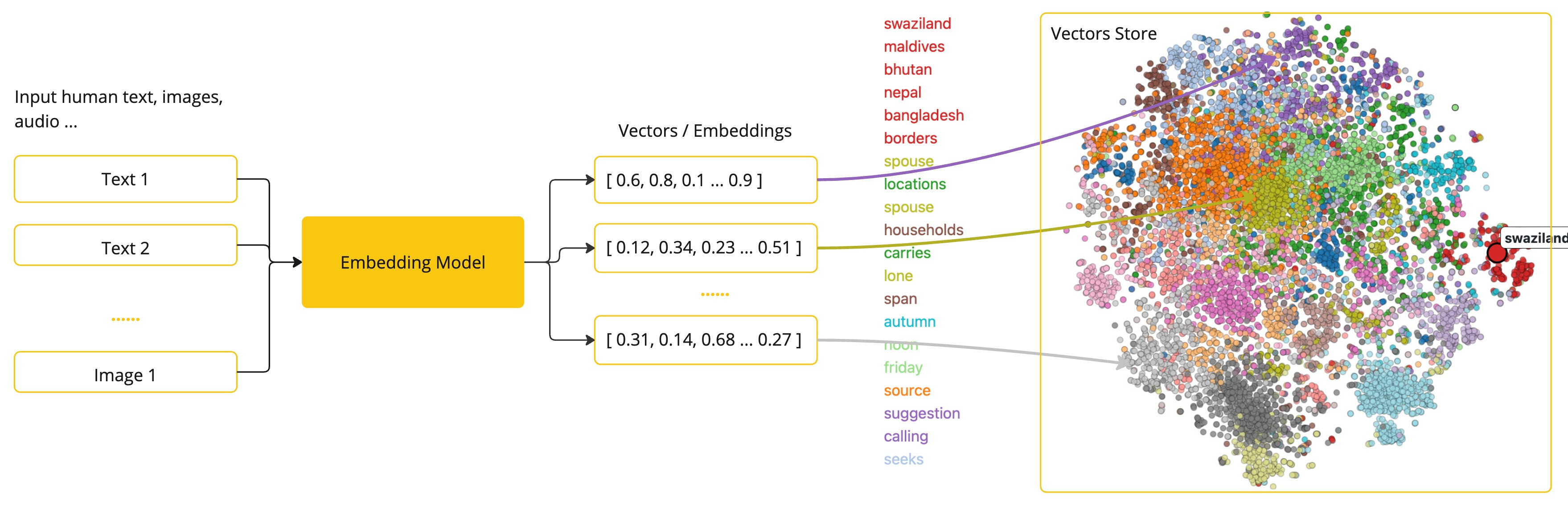
作为一名探索人工智能的Java开发者,理解这些向量表示背后的复杂数学理论或具体实现并不是必需的。对它们在人工智能系统中的作用和功能有基本的了解就足够了,尤其是在将人工智能功能集成到您的应用程序中时。
Embedding在实际应用中,特别是在检索增强生成(RAG)模式中,具有重要意义。它们使数据能够在语义空间中表示为点,这类似于欧几里得几何的二维空间,但在更高的维度中。这意味着,就像欧几里得几何中平面上的点可以根据其坐标的远近关系而接近或远离一样,在语义空间中,点的接近程度反映了意义的相似性。关于相似主题的句子在这个多维空间中的位置较近,就像图表上彼此靠近的点。这种接近性有助于文本分类、语义搜索,甚至产品推荐等任务,因为它允许人工智能根据这些点在扩展的语义空间中的“位置”来辨别和分组相关概念。
您可以将这个语义空间视为一个向量。
四、Token
token是 AI 模型工作原理的基石。输入时,模型将单词转换为token。输出时,它们将token转换回单词。
在英语中,一个token大约对应一个单词的 75%。作为参考,莎士比亚的全集总共约 90 万个单词,翻译过来大约有 120 万个token。

也许更重要的是 “token = 金钱”。在托管 AI 模型的背景下,您的费用由使用的token数量决定。输入和输出都会影响总token数量。
此外,模型还受到 token 限制,这会限制单个 API 调用中处理的文本量。此阈值通常称为“上下文窗口”。模型不会处理超出此限制的任何文本。
例如,ChatGPT3 的token限制为 4K,而 GPT4 则提供不同的选项,例如 8K、16K 和 32K。Anthropic 的 Claude AI 模型的token限制为 100K,而 Meta 的最新研究则产生了 1M token限制模型。
要使用 GPT4 总结莎士比亚全集,您需要制定软件工程策略来切分数据并在模型的上下文窗口限制内呈现数据。Spring AI 项目可以帮助您完成此任务。
五、结构化输出(Structured Output)
即使您要求回复为 JSON ,AI 模型的输出通常也会以 java.lang.String 的形式出现。它可能是正确的 JSON,但它可能并不是你想要的 JSON 数据结构,它只是一个字符串。此外,在提示词 Prompt 中要求 “返回JSON” 并非 100% 准确。
这种复杂性导致了一个专门领域的出现,涉及创建 Prompt 以产生预期的输出,然后将生成的简单字符串转换为可用于应用程序集成的数据结构。
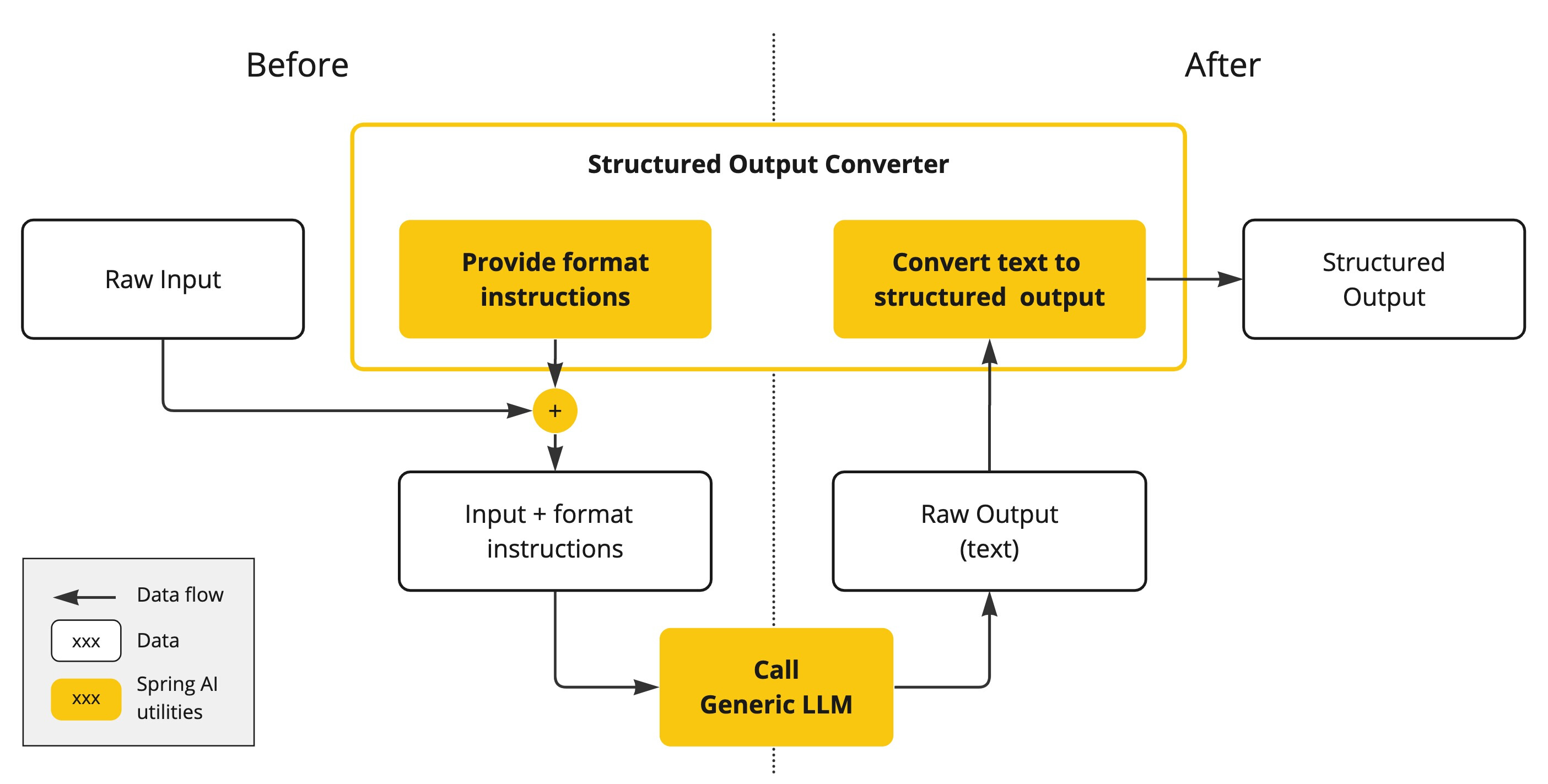
结构化输出转换采用精心设计的提示,通常需要与模型进行多次交互才能实现所需的格式。
六、将您的数据和 API 引入 AI 模型
如何让人工智能模型与不在训练集中的数据一同工作?
请注意,GPT 3.5/4.0 数据集仅支持截止到 2021 年 9 月之前的数据。因此,该模型表示它不知道该日期之后的知识,因此它无法很好的应对需要用最新知识才能回答的问题。一个有趣的小知识是,这个数据集大约有 650GB。
有三种技术可以定制 AI 模型以整合您的数据:
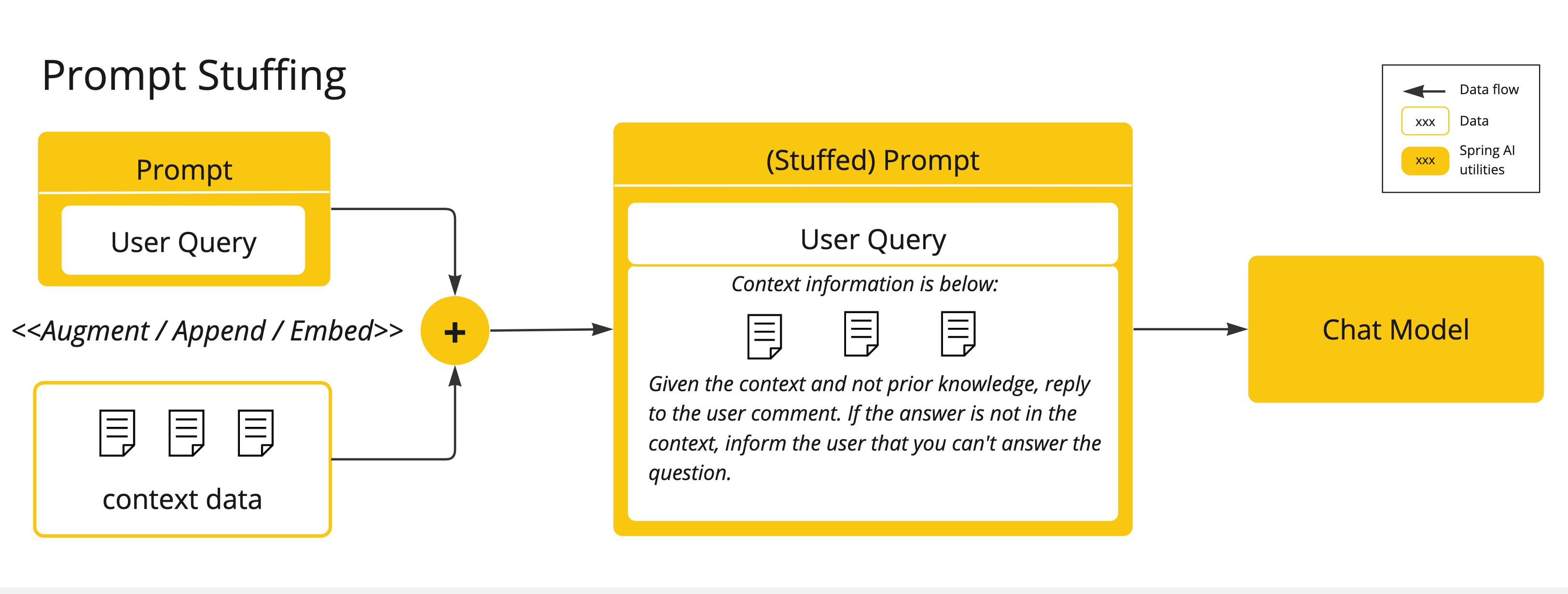
Fine Tuning微调:这种传统的机器学习技术涉及定制模型并更改其内部权重。然而,即使对于机器学习专家来说,这是一个具有挑战性的过程,而且由于 GPT 等模型的大小,它极其耗费资源。此外,有些模型可能不提供此选项。Prompt Stuffing提示词填充:一种更实用的替代方案是将您的数据嵌入到提供给模型的提示中。考虑到模型的令牌限制,我们需要具备过滤相关数据的能力,并将过滤出的数据填充到在模型交互的上下文窗口中,这种方法俗称“提示词填充”。Spring AI 库可帮助您基于“提示词填充” 技术, 也称为检索增强生成 (RAG)实现解决方案。
- Function Calling:此技术允许注册自定义的用户函数,将大型语言模型连接到外部系统的 API。Spring AI 大大简化了支持函数调用所需编写的代码 。
检索增强生成(RAG)
一种称为检索增强生成 (RAG) 的技术已经出现,旨在解决为 AI 模型提供额外的知识输入,以辅助模型更好的回答问题。
该方法涉及批处理式的编程模型,其中涉及到:从文档中读取非结构化数据、对其进行转换、然后将其写入矢量数据库。从高层次上讲,这是一个 ETL(提取、转换和加载)管道。矢量数据库则用于 RAG 技术的检索部分。
在将非结构化数据加载到矢量数据库的过程中,最重要的转换之一是将原始文档拆分成较小的部分。将原始文档拆分成较小部分的过程有两个重要步骤:
- 将文档拆分成几部分,同时保留内容的语义边界。例如,对于包含段落和表格的文档,应避免在段落或表格中间拆分文档;对于代码,应避免在方法实现的中间拆分代码。
- 将文档的各部分进一步拆分成大小仅为 AI 模型令牌 token 限制的一小部分的部分。
RAG 的下一个阶段是处理用户输入。当用户的问题需要由 AI 模型回答时,问题和所有“类似”的文档片段都会被放入发送给 AI 模型的提示中。这就是使用矢量数据库的原因,它非常擅长查找具有一定相似度的“类似”内容。
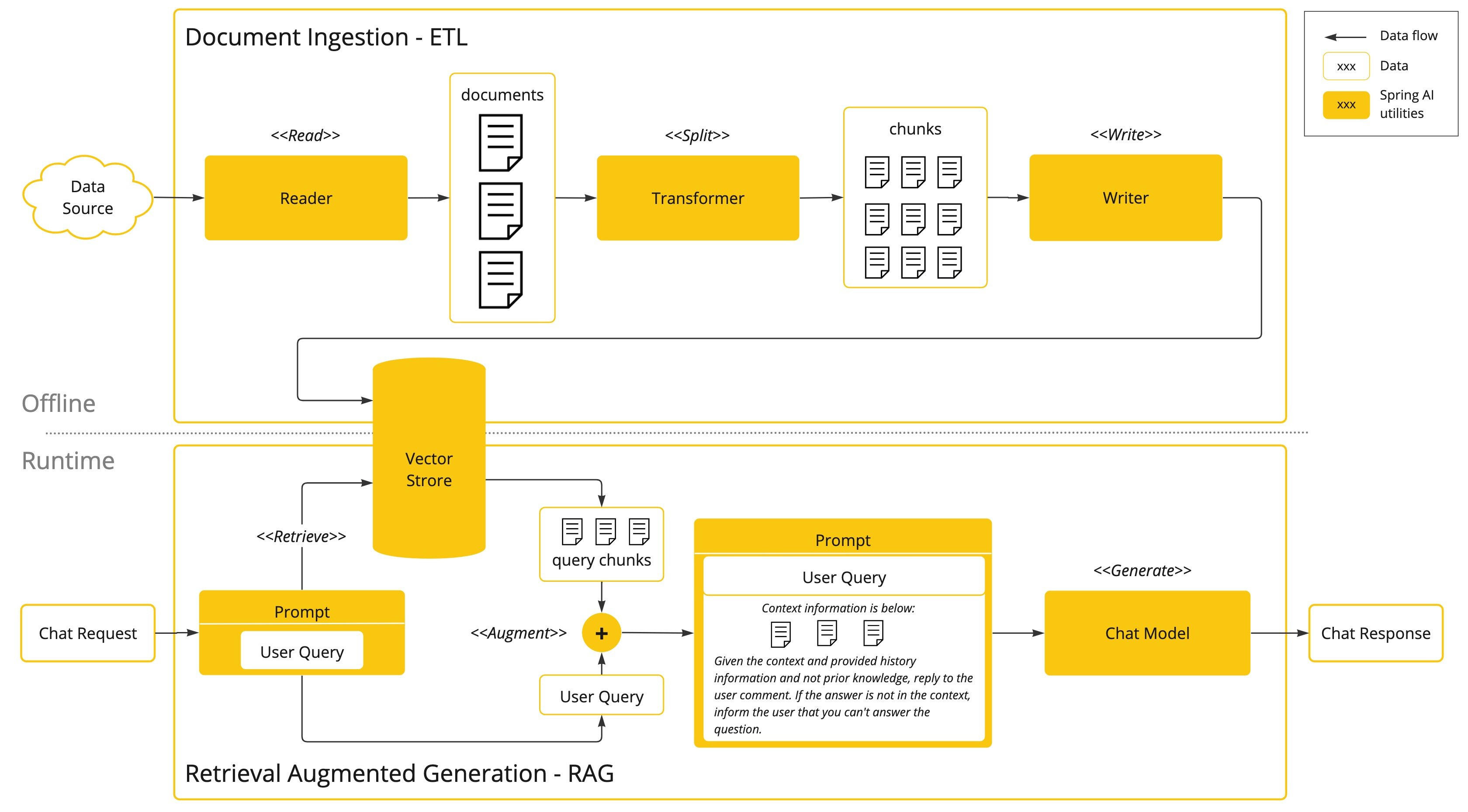
ETL 管道提供了有关协调从数据源提取数据并将其存储在结构化向量存储中的流程的更多信息,确保在将数据传递给 AI 模型时数据具有最佳的检索格式。
ChatClient - RAG解释了如何使用QuestionAnswerAdvisorAdvisor 在您的应用程序中启用 RAG 功能。
函数调用(Function Calling)
大型语言模型 (LLM) 在训练后即被冻结,导致知识陈旧,并且无法访问或修改外部数据。
Function Calling机制解决了这些缺点,它允许您注册自己的函数,以将大型语言模型连接到外部系统的 API。这些系统可以为 LLM 提供实时数据并代表它们执行数据处理操作。
Spring AI 大大简化了您需要编写的代码以支持函数调用。它为您处理函数调用对话。您可以将函数作为提供,@Bean然后在提示选项中提供该函数的 bean 名称以激活该函数。此外,您可以在单个提示中定义和引用多个函数。
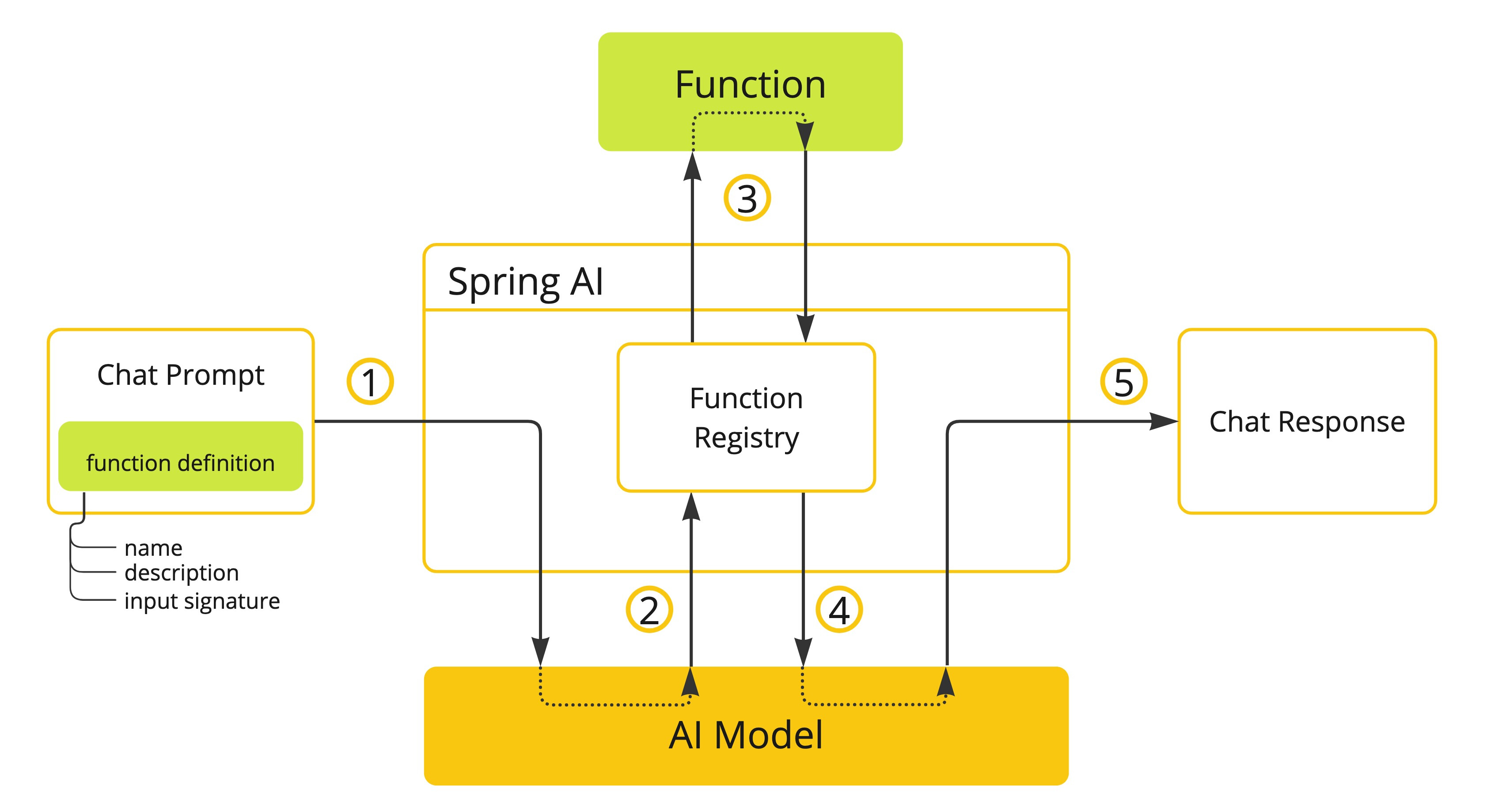
- (1)执行聊天请求并发送函数定义信息。后者提供
name(description例如,解释模型何时应调用该函数)和input parameters(例如,函数的输入参数模式)。 - (2)当模型决定调用该函数时,它将使用输入参数调用该函数,并将输出返回给模型。
- (3)Spring AI 为您处理此对话。它将函数调用分派给适当的函数,并将结果返回给模型。
- (4)模型可以执行多个函数调用来检索所需的所有信息。
- (5)一旦获取了所有需要的信息,模型就会生成响应。
请关注函数调用文档以获取有关如何在不同 AI 模型中使用此功能的更多信息。
七、评估人工智能的回答(Evaluation)
有效评估人工智能系统回答的正确性,对于确保最终应用程序的准确性和实用性非常重要,一些新兴技术使得预训练模型本身能够用于此目的。
Evaluation 评估过程涉及分析响应是否符合用户的意图、与查询的上下文强相关,一些指标如相关性、连贯性和事实正确性等都被用于衡量 AI 生成的响应的质量。
一种方法是把用户的请求、模型的响应一同作为输入给到模型服务,对比模型给的响应或回答是否与提供的响应数据一致。
此外,利用矢量数据库(Vector Database)中存储的信息作为补充数据可以增强评估过程,有助于确定响应的相关性。