PPO算法实践(基于cleanrl)
引言:之前写过一篇《PPO算法逐行代码详解》的博客,在这篇博客中在介绍PPO算法理论的同时,基于《动手学强化学习》书中PPO算法的代码实现进行了逐行详解。但是这个实现我认为过于demo,实用性并不是很强,所以又学习魔改了cleanrl中的PPO算法的实现,在这篇文章中总结一下修改后的代码。
文章目录
- 1. 修改的主要内容
- 2. 训练流程
- 3. 网络结构
- 4. 训练整体流程
- 4.1 相关参数定义、env环境初始化、存储数据结构定义
- 4.2 agent与环境交互产生训练用数据并存储
- 4.3 利用产生的数据进行多次网络参数更新
cleanrl代码仓库: https://github.com/vwxyzjn/cleanrl
修改后的实现:https://github.com/acezsq/rlCode/blob/main/ppo_new.py
1. 修改的主要内容
修改的主要内容:
(1)更改cleanrl中多个环境并行采集数据的实现为单环境采集(为了适配我自己的gym任务环境)
(2)将gymnasium改为的gym(我自己的环境之前是基于gym实现的)
(3)去除部分我认为暂时没必要的配置项
(4)增加少量控制台打印训练进度信息展示
修改后实现的优点:
(1)最大的优点就是更加适配自定义的gym环境
为了验证修改后代码的正确性,这里先展示一下修改后的代码跑CartPole-v1和cleanrl原版代码跑CartPole-v1的效果对比:
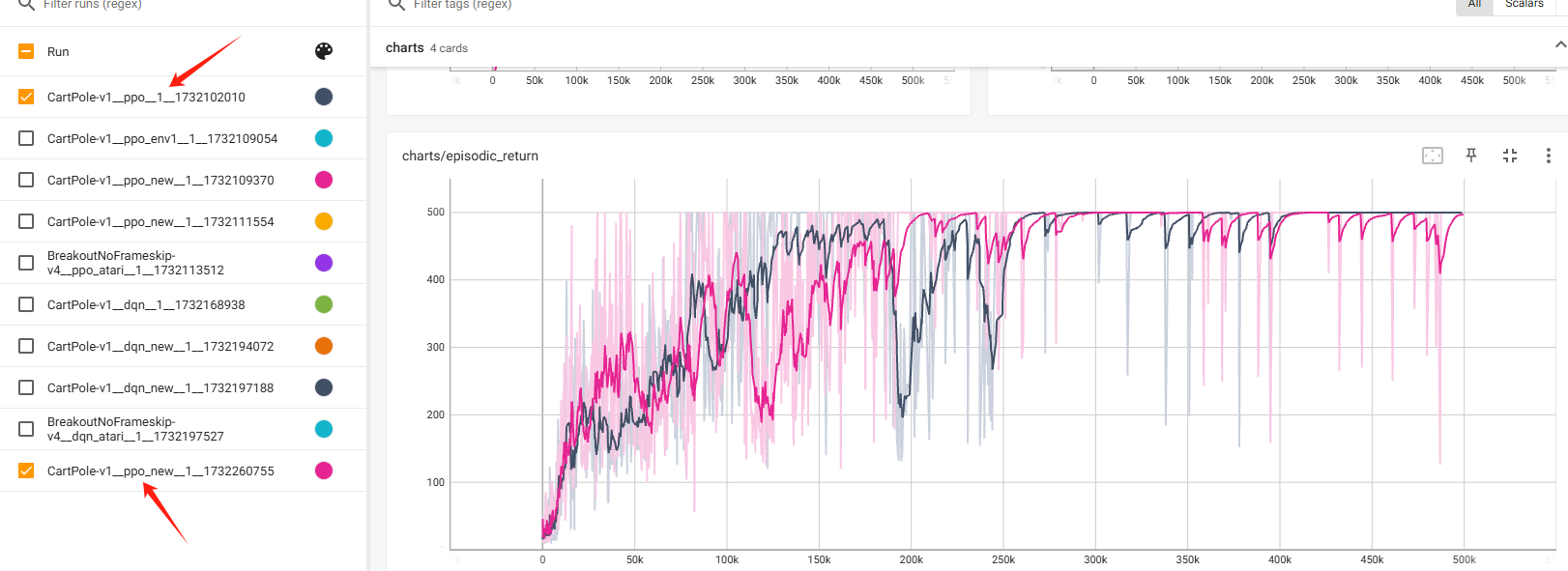
整体上是跟原来的实现大差不多,后期偶有不稳定的现象,这是可接受的。
2. 训练流程
在正式围绕代码实现分析之前,我觉得有必要先就PPO算法的训练流程有个大体的理解。
首先所有的drl算法的训练大逻辑都是agent和环境交互采集数据并存储到某个数据结构中,之后利用数据进行网络参数的更新。对于PPO算法,它是一个on-policy算法,需要采集一定量数据之后结合重要性采样,重复利用多次这批数据进行参数更新,之后清空重新采集。
在本次分析的代码实现中,训练的配置如下:
total_timesteps = 500000
batch_size = 512
minibatch_size = 128
num_iterations = 500000 // 512 = 976
update_epochs = 4
上面的配置就是一共训练500000个step,最外层的大循环一共执行976次,每次与agent与环境交互采集一个batch 512个step的数据,然后循环利用这一个batch的数据4次,每次将512个step的数据随机打乱,分为4个minibatch,每次通过一个minibatch计算损失函数进行参数更新。
3. 网络结构
网络结构:
def layer_init(layer, std=np.sqrt(2), bias_const=0.0):
torch.nn.init.orthogonal_(layer.weight, std)
torch.nn.init.constant_(layer.bias, bias_const)
return layer
class Agent(nn.Module):
def __init__(self, envs):
super().__init__()
self.critic = nn.Sequential(
layer_init(nn.Linear(np.array(envs.observation_space.shape[0]).prod(), 64)),
nn.Tanh(),
layer_init(nn.Linear(64, 64)),
nn.Tanh(),
layer_init(nn.Linear(64, 1), std=1.0),
)
self.actor = nn.Sequential(
layer_init(nn.Linear(np.array(envs.observation_space.shape[0]).prod(), 64)),
nn.Tanh(),
layer_init(nn.Linear(64, 64)),
nn.Tanh(),
layer_init(nn.Linear(64, envs.action_space.n), std=0.01),
)
def get_value(self, x):
return self.critic(x)
def get_action_and_value(self, x, action=None):
logits = self.actor(x)
probs = Categorical(logits=logits)
if action is None:
action = probs.sample()
return action, probs.log_prob(action), probs.entropy(), self.critic(x)
get_value函数返回状态价值;
get_action_and_value函数使用actor获取动作的分布,采样一个动作,返回动作、logΠ(a|s)、动作分布的熵、状态价值。
4. 训练整体流程
我觉得整体流程可以分为以下几部分:
(1)相关参数定义、env环境初始化、存储数据结构定义。
(2)agent与环境交互产生训练用数据并存储。
(3)利用产生的数据进行多次网络参数更新。
4.1 相关参数定义、env环境初始化、存储数据结构定义
下面是主函数,首先是一些关于训练的参数定义和存储数据的数据结构的定义等内容。
if __name__ == "__main__":
args = tyro.cli(Args)
args.batch_size = int(args.num_envs * args.num_steps) # 1 * 512
args.minibatch_size = int(args.batch_size // args.num_minibatches) # 512 // 4 = 128
args.num_iterations = args.total_timesteps // args.batch_size # 500000 // 512 = 976
run_name = f"{args.env_id}__{args.exp_name}__{args.seed}__{int(time.time())}"
writer = SummaryWriter(f"runs/{run_name}")
writer.add_text(
"hyperparameters",
"|param|value|\n|-|-|\n%s" % ("\n".join([f"|{key}|{value}|" for key, value in vars(args).items()])),
)
random.seed(args.seed)
np.random.seed(args.seed)
torch.manual_seed(args.seed)
torch.backends.cudnn.deterministic = args.torch_deterministic
device = torch.device("cuda" if torch.cuda.is_available() and args.cuda else "cpu")
envs = gym.make(args.env_id)
assert isinstance(envs.action_space, gym.spaces.Discrete), "only discrete action space is supported"
agent = Agent(envs).to(device)
optimizer = optim.Adam(agent.parameters(), lr=args.learning_rate, eps=1e-5)
# ALGO Logic: Storage setup
obs = torch.zeros((args.num_steps, envs.observation_space.shape[0])).to(device)
actions = torch.zeros((args.num_steps, )).to(device)
logprobs = torch.zeros((args.num_steps, )).to(device)
rewards = torch.zeros((args.num_steps, )).to(device)
dones = torch.zeros((args.num_steps, )).to(device)
values = torch.zeros((args.num_steps, )).to(device)
global_step = 0
start_time = time.time()
next_obs = envs.reset(seed=args.seed)
next_obs = torch.Tensor(next_obs).to(device)
next_done = torch.zeros(args.num_envs).to(device)
episodic_return = 0
episodic_length = 0
下面是训练的逻辑流程,由于在一个函数里面不好拆开,我就在下面针对不容易理解的部分拆开做分析(见4.2和4.3小节)。
for iteration in range(1, args.num_iterations + 1): # iteration 从1 到 976
print('**************************************************')
print('第 {} of 976 轮'.format(iteration))
print('**************************************************')
# Annealing the rate if instructed to do so.
if args.anneal_lr:
# anneal_lr 是 Learning Rate Annealing 学习率退火
frac = 1.0 - (iteration - 1.0) / args.num_iterations
lrnow = frac * args.learning_rate
optimizer.param_groups[0]["lr"] = lrnow
# 执行512个step
for step in range(0, args.num_steps):
global_step += 1
obs[step] = next_obs
dones[step] = next_done
with torch.no_grad():
action, logprob, _, value = agent.get_action_and_value(next_obs)
values[step] = value.flatten()
actions[step] = action
logprobs[step] = logprob
next_obs, reward, done, info = envs.step(action.cpu().numpy())
rewards[step] = torch.tensor(reward).to(device).view(-1)
next_obs, next_done = torch.Tensor(next_obs).to(device), torch.Tensor(np.array(done)).to(device)
episodic_return += reward
episodic_length += 1
if done == True:
# 计算回合的奖励和长度
envs.reset()
print(f"global_step={global_step}, episodic_return={episodic_return}")
writer.add_scalar("charts/episodic_return", episodic_return, global_step)
writer.add_scalar("charts/episodic_length", episodic_length, global_step)
episodic_return = 0
episodic_length = 0
print('--------------------------------------------------')
print('第 {} of 976 轮 采样完毕数据'.format(iteration))
print('--------------------------------------------------')
with torch.no_grad():
next_value = agent.get_value(next_obs).reshape(1, -1)
advantages = torch.zeros_like(rewards).to(device)
lastgaelam = 0
for t in reversed(range(args.num_steps)):
if t == args.num_steps - 1:
nextnonterminal = 1.0 - next_done
nextvalues = next_value
else:
nextnonterminal = 1.0 - dones[t + 1]
nextvalues = values[t + 1]
delta = rewards[t] + args.gamma * nextvalues * nextnonterminal - values[t]
advantages[t] = lastgaelam = delta + args.gamma * args.gae_lambda * nextnonterminal * lastgaelam
returns = advantages + values
# flatten the batch
b_obs = obs.reshape((-1,) + envs.observation_space.shape)
b_logprobs = logprobs.reshape(-1)
b_actions = actions.reshape((-1,) + envs.action_space.shape)
b_advantages = advantages.reshape(-1)
b_returns = returns.reshape(-1)
b_values = values.reshape(-1)
# Optimizing the policy and value network
b_inds = np.arange(args.batch_size) # batch_size = 512 b_inds = [0,1,2....,511]
# 用于存储每个批次的clip fraction值
clipfracs = []
for epoch in range(args.update_epochs): # update_epochs = 4
# 随机打乱b_inds数组中的元素顺序,以便每个epoch中随机选择训练样本。
np.random.shuffle(b_inds)
# 将训练样本划分为多个大小为args.minibatch_size = 128的小批次
# 其中start和end是小批次的起始索引和结束索引
# mb_inds是当前小批次中样本的索引。
for start in range(0, args.batch_size, args.minibatch_size): # minibatch_size = 128
# start = 0, 128, 256, 384
end = start + args.minibatch_size
mb_inds = b_inds[start:end]
# 根据输入的观察和动作,获取新的对数概率(newlogprob),策略熵(entropy)和值函数估计值(newvalue)
_, newlogprob, entropy, newvalue = agent.get_action_and_value(b_obs[mb_inds], b_actions.long()[mb_inds])
logratio = newlogprob - b_logprobs[mb_inds]
ratio = logratio.exp()
with torch.no_grad():
# calculate approx_kl http://joschu.net/blog/kl-approx.html
old_approx_kl = (-logratio).mean()
approx_kl = ((ratio - 1) - logratio).mean()
clipfracs += [((ratio - 1.0).abs() > args.clip_coef).float().mean().item()]
mb_advantages = b_advantages[mb_inds]
if args.norm_adv:
mb_advantages = (mb_advantages - mb_advantages.mean()) / (mb_advantages.std() + 1e-8)
# Policy loss
pg_loss1 = -mb_advantages * ratio
pg_loss2 = -mb_advantages * torch.clamp(ratio, 1 - args.clip_coef, 1 + args.clip_coef)
pg_loss = torch.max(pg_loss1, pg_loss2).mean()
# Value loss
newvalue = newvalue.view(-1)
if args.clip_vloss:
v_loss_unclipped = (newvalue - b_returns[mb_inds]) ** 2
v_clipped = b_values[mb_inds] + torch.clamp(
newvalue - b_values[mb_inds],
-args.clip_coef,
args.clip_coef,
)
v_loss_clipped = (v_clipped - b_returns[mb_inds]) ** 2
v_loss_max = torch.max(v_loss_unclipped, v_loss_clipped)
v_loss = 0.5 * v_loss_max.mean()
else:
v_loss = 0.5 * ((newvalue - b_returns[mb_inds]) ** 2).mean()
entropy_loss = entropy.mean()
loss = pg_loss - args.ent_coef * entropy_loss + v_loss * args.vf_coef
optimizer.zero_grad()
loss.backward()
nn.utils.clip_grad_norm_(agent.parameters(), args.max_grad_norm)
optimizer.step()
if args.target_kl is not None and approx_kl > args.target_kl:
break
if args.anneal_lr:
# anneal_lr 是 Learning Rate Annealing 学习率退火
frac = 1.0 - (iteration - 1.0) / args.num_iterations
lrnow = frac * args.learning_rate
optimizer.param_groups[0]["lr"] = lrnow
学习率退火是一种训练过程中动态调整学习率的技术。它通常会在训练的早期使用较大的学习率以加快收敛速度。然后逐渐降低学习率,让模型在训练后期更加稳定地收敛或探索更细致的参数空间。
这里就是根据训练的进度,逐步减小学习率。
4.2 agent与环境交互产生训练用数据并存储
# 执行512个step
for step in range(0, args.num_steps):
global_step += 1
obs[step] = next_obs
dones[step] = next_done
with torch.no_grad():
action, logprob, _, value = agent.get_action_and_value(next_obs)
values[step] = value.flatten()
actions[step] = action
logprobs[step] = logprob
next_obs, reward, done, info = envs.step(action.cpu().numpy())
rewards[step] = torch.tensor(reward).to(device).view(-1)
next_obs, next_done = torch.Tensor(next_obs).to(device), torch.Tensor(np.array(done)).to(device)
episodic_return += reward
episodic_length += 1
if done == True:
# 计算回合的奖励和长度
envs.reset()
print(f"global_step={global_step}, episodic_return={episodic_return}")
writer.add_scalar("charts/episodic_return", episodic_return, global_step)
writer.add_scalar("charts/episodic_length", episodic_length, global_step)
episodic_return = 0
episodic_length = 0
这部分是采样数据的过程,采样512个step的数据,将数据存储到之前定义的存储数据的数据结构中。
具体存储的有[obs, action, logprob, done, reward, alue]。
并且采集每个episode的return和length。
with torch.no_grad():
next_value = agent.get_value(next_obs).reshape(1, -1)
advantages = torch.zeros_like(rewards).to(device)
lastgaelam = 0
for t in reversed(range(args.num_steps)):
if t == args.num_steps - 1:
nextnonterminal = 1.0 - next_done
nextvalues = next_value
else:
nextnonterminal = 1.0 - dones[t + 1]
nextvalues = values[t + 1]
delta = rewards[t] + args.gamma * nextvalues * nextnonterminal - values[t]
advantages[t] = lastgaelam = delta + args.gamma * args.gae_lambda * nextnonterminal * lastgaelam
returns = advantages + values
这段代码主要通过GAE计算得到advantages和returns用于后续目标函数。

关于上面的计算详细可见上一篇博客:https://www.zhihu.com/people/30-34-63-88/posts
# flatten the batch
b_obs = obs.reshape((-1,) + envs.observation_space.shape)
b_logprobs = logprobs.reshape(-1)
b_actions = actions.reshape((-1,) + envs.action_space.shape)
b_advantages = advantages.reshape(-1)
b_returns = returns.reshape(-1)
b_values = values.reshape(-1)
这里是将这个batch的数据进行shape的统一规整。
4.3 利用产生的数据进行多次网络参数更新
# Optimizing the policy and value network
b_inds = np.arange(args.batch_size) # batch_size = 512 b_inds = [0,1,2....,511]
# 用于存储每个批次的clip fraction值
clipfracs = []
for epoch in range(args.update_epochs): # update_epochs = 4
# 随机打乱b_inds数组中的元素顺序,以便每个epoch中随机选择训练样本。
np.random.shuffle(b_inds)
# 将训练样本划分为多个大小为args.minibatch_size = 128的小批次
# 其中start和end是小批次的起始索引和结束索引
# mb_inds是当前小批次中样本的索引。
for start in range(0, args.batch_size, args.minibatch_size): # minibatch_size = 128
# start = 0, 128, 256, 384
end = start + args.minibatch_size
mb_inds = b_inds[start:end]
# 根据输入的观察和动作,获取新的对数概率(newlogprob),策略熵(entropy)和值函数估计值(newvalue)
_, newlogprob, entropy, newvalue = agent.get_action_and_value(b_obs[mb_inds], b_actions.long()[mb_inds])
logratio = newlogprob - b_logprobs[mb_inds]
ratio = logratio.exp()
这部分代码是网络参数更新的主体逻辑,就是用一个batch 512个step中的数据进行网络参数更新,利用这一个batch的数据更新四次。具体来说的话就是每次需要先把数据shuffle打乱,之后将这个batch分为四个小的minibatch,每次利用minibatch大小的数据进行loss值的计算,进而进行网络参数的更新。
_, newlogprob, entropy, newvalue = agent.get_action_and_value(b_obs[mb_inds], b_actions.long()[mb_inds])
这里又用了一次agent.get_action_and_value函数,前面在与环境进行数据采样数据也用了一次。前面使用的时候,只传入一个obs,而这里既传入obs也传入action,通过这个函数获取到新的logprob和新的状态价值。其中newlogprob起始就是下面图中的分母进而用于后续actor的更新,newvalue可以用于后续critic的更新。
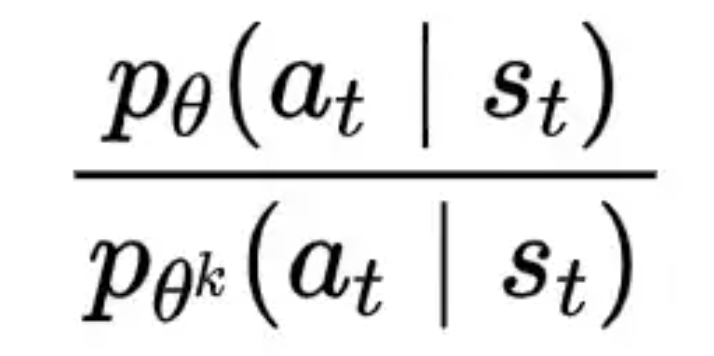
with torch.no_grad():
# calculate approx_kl http://joschu.net/blog/kl-approx.html
old_approx_kl = (-logratio).mean()
approx_kl = ((ratio - 1) - logratio).mean()
clipfracs += [((ratio - 1.0).abs() > args.clip_coef).float().mean().item()]
- 计算近似 KL 散度: 用于评估新策略和旧策略的分布差异。
old_approx_kl和approx_kl是两种不同的计算方式。 - 统计裁剪比率: 记录策略比值超出裁剪阈值的比例(
clipfracs),用于监控 PPO 算法的稳定性和训练质量。
这个主要是用于监控,不是算法主流程内容。
mb_advantages = b_advantages[mb_inds]
if args.norm_adv:
mb_advantages = (mb_advantages - mb_advantages.mean()) / (mb_advantages.std() + 1e-8)
这里对该批次的优势函数值进行归一化,以提高训练的稳定性和收敛速度。
# Policy loss
pg_loss1 = -mb_advantages * ratio
pg_loss2 = -mb_advantages * torch.clamp(ratio, 1 - args.clip_coef, 1 + args.clip_coef)
pg_loss = torch.max(pg_loss1, pg_loss2).mean()
# Value loss
newvalue = newvalue.view(-1)
if args.clip_vloss:
v_loss_unclipped = (newvalue - b_returns[mb_inds]) ** 2
v_clipped = b_values[mb_inds] + torch.clamp(
newvalue - b_values[mb_inds],
-args.clip_coef,
args.clip_coef,
)
v_loss_clipped = (v_clipped - b_returns[mb_inds]) ** 2
v_loss_max = torch.max(v_loss_unclipped, v_loss_clipped)
v_loss = 0.5 * v_loss_max.mean()
else:
v_loss = 0.5 * ((newvalue - b_returns[mb_inds]) ** 2).mean()
entropy_loss = entropy.mean()
loss = pg_loss - args.ent_coef * entropy_loss + v_loss * args.vf_coef
optimizer.zero_grad()
loss.backward()
nn.utils.clip_grad_norm_(agent.parameters(), args.max_grad_norm)
optimizer.step()
if args.target_kl is not None and approx_kl > args.target_kl:
break
上面的代码分别是计算policy network和value network的loss,然后进行梯度清零,反向传播,梯度下降。
计算policy network的目标函数如下:
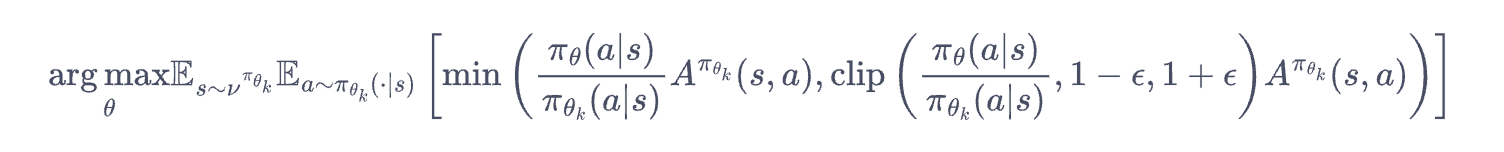
计算value network的loss可以配置是否裁剪。如果使用裁剪的话使用裁剪后的预测值和目标值计算损失,选择未裁剪损失和裁剪损失的较大值,确保更新幅度受控。否则的话使用当前预测值与目标值之间的均方误差(MSE)。
nn.utils.clip_grad_norm_(agent.parameters(), args.max_grad_norm)
这个是对模型参数的梯度进行裁剪,防止梯度爆炸。