网易游戏用户流失预测实践
摘要
客户留存是游戏公司面临的一个关键问题,因为收入在很大程度上受到用户基数的影响。以往的研究达成共识,吸引一个新玩家的成本可能是留住现有玩家的六倍,这表明一个准确的流失预测模型对于制定客户留存策略至关重要。现有的工作更多关注于研究登录信息(例如用户的登录活动特征),忽略了丰富的游戏内行为(例如升级、交易物资),这些行为可以隐含地反映用户的偏好及其相互依赖性。在本文中,我们提出了一种新颖的端到端神经网络,名为ChurnPred,用于解决流失预测问题。特别是,我们不仅考虑了登录行为,还考虑了游戏内行为,以更全面地建模用户行为模式。对于登录活动的时间序列,我们利用基于LSTM的结构来学习内在的时间依赖性,从而捕捉活动序列的演变。对于游戏内行为,我们开发了一个时间感知过滤组件,以更好地区分特定时间段内发生的行为模式,并引入多视角机制,从多个角度自动提取这些行为的多种组合。在真实世界数据上进行的综合实验表明,与最先进的方法相比,所提出的模型具有有效性。
1 引言
包括大型多人在线角色扮演游戏(MMORPGs)在内的在线游戏所产生的巨大收入吸引了许多游戏公司,导致游戏市场竞争日益激烈。客户留存正成为一个主要关注点,因为:
1)吸引一个新玩家的成本可能是留住现有玩家的六倍 [23];
2)长期玩家通常比新玩家产生更高的利润。
作为用户留存的重要组成部分,尽早了解玩家是否会在早期阶段选择留存或离开游戏(即流失预测问题)至关重要。
一个准确的流失预测模型对于制定客户留存策略至关重要。一旦通过预测模型识别出流失者,游戏管理者可以采取一些措施防止这些玩家离开游戏,例如提供一些奖励任务以激发用户的兴趣,或推送用户感兴趣的新游戏策略通知。此外,流失预测模型的预测结果可以为游戏平台提供参考,以了解游戏玩家的整体偏好,从而制定适当的策略。流失玩家数量的增加可能成为游戏运营商提前调整游戏策略的强烈信号。
以往针对在线游戏(例如MMORPGs)流失预测问题的研究主要集中在挖掘显著特征,以指示用户是否即将离开游戏。他们倾向于在对多种特征进行全面分析后利用手工特征,并使用传统的基于机器学习的方法完成流失预测任务 [3,4,7,8,10]。以往研究的局限性主要有两方面:1)严重依赖领域特定知识和人工特征,这在不同应用场景中并不普遍。例如,一些特征对于在线游戏来说并不通用或难以收集,如[10]中的“点击次数”和“使用的休息次数”,[3]中的“每周会话间隔总和”,[8]中的“社交活动”和“物品升级”,[2]中的“群体互动率”。2)主要利用从登录信息统计得出的特征,而忽略了用户在游戏中的行为信息。这些信息对于流失预测非常重要,因为它可以进一步指示用户对游戏的偏好。玩家在完善角色方面投入了大量精力,例如不断执行任务以升级或交易物资以增强装备,这展示了他们对游戏角色的一种偏好。Tao等人已经证明了用户游戏内行为信息在机器人检测中的重要性 [16]。
在线游戏中的流失预测存在若干挑战。如上所述,用户在在线游戏中的行为主要分为两类:登录信息(例如会话统计、登录频率)和游戏内行为信息(例如一系列游戏内行为,如升级、交易物资)。首先,这些数据类型不同,因为前者通常表示为实值向量,而后者的每个元素是表示特定动作的离散值。将这些数据一起建模以捕捉用户-游戏交互和内在行为模式是一个挑战。其次,由于每个玩家都有自己的生命周期,需要进行短期和长期建模,以更好地捕捉用户偏好和时间模式的演变。第三,用户的行为与他们的日常生活密切相关(详细内容将在第3节中给出)。例如,用户在工作日与周末的游戏参与时间长度不同,或某些事件如交易特定物品或战斗只能在某些特殊日子(例如节日)发生。因此,在建模时必须额外考虑这些信息的影响。
为了缓解上述挑战,本文提出了一种新颖的端到端神经网络方法,名为ChurnPred,用于在线游戏中的流失预测。我们将登录信息和游戏内信息结合起来,更全面地建模用户行为,从中自动学习潜在的行为模式,而无需手动提取特征。考虑到用户生命周期对登录行为的影响,我们利用LSTM模型来学习用户的短期和长期偏好。由于我们在第3节中发现某些行为与发生的日期密切相关,我们提出了一种时间感知过滤组件,以更好地区分基于事件周期的这些特征行为。此外,我们提出了一种多视角机制,从多个角度自动提取游戏内行为的多种组合,这些组合可能导致用户的离开。
总结起来,本文的主要贡献如下:
- 我们开发了一种新颖的端到端神经网络方法,名为ChurnPred,通过考虑登录行为和游戏内行为来进行在线游戏中的流失预测。此外,我们提出了时间感知过滤机制,以更好地区分在特定时期发生的行为模式,并提出了一种多视角机制,以从多个角度提取游戏内行为的多种组合,这些组合可能暗示用户的离开。
- 我们在一个包含三个不同时间段的真实数据集上进行了综合实验,以验证所提出模型的有效性。实验结果表明,我们的模型在在线游戏中的流失预测方面具有优越性。
2 相关工作
客户流失行为在许多行业中一直被广泛分析,因为大多数公司相信用户数量和粘性在市场竞争力和活力中起着重要作用。大多数这些工作 [10,14,23] 更关注于提取突出的特征,并探索传统分类器(如逻辑回归 [11]、随机森林 [21])之间的分类性能。他们将流失预测建模为二元分类问题,并倾向于使用统计技术总结样本的差异以更好地识别。这些研究严重依赖领域特定知识和人工特征,这在不同应用场景中并不通用。最近,一些研究提出了更先进的流失预测模型。一些工作 [13, 18] 通过建模玩家的游戏时间提出了生存分析模型。由于深度学习在检测 [19] 和推荐 [5, 20] 等各个领域取得了巨大成功,一些研究 [1, 9, 17] 关注于利用深度神经网络解决流失预测问题,这激励我们采用深度神经网络模型。
只有少数论文直接涉及包括MMORPGs在内的在线游戏。Borbora等人设计了一种基于生命周期的方法来建模流失行为,并提出了三个维度来构建派生特征,以便更好地分类基于距离的架构wClusterDist [3]。然而,基于生命周期的方法忽略了用户注册时间和游戏时间的消耗。那些长期玩游戏的忠实客户在观察中往往不太活跃,因此可能很容易被误认为是流失者。Runge等人专注于预测休闲社交游戏中高价值玩家的流失,因为他们发现前7%的付费玩家贡献了大约50%的总收入,并获取了一系列用于分类的特征 [14]。Castro等人提出了一种基于频率分析的方法,用于从登录记录中进行特征表示。该方法将登录记录转换为固定长度的数组作为输入,并使用带有k近邻算法的概率分类器进行分类 [4]。上述研究主要关注登录信息(即登录频率),但没有考虑在线游戏(例如MMORPGs)中用户的游戏内行为信息。游戏内行为对于用户行为建模至关重要,因为它包含了关于用户的丰富信息,包括玩家在游戏中的特定事件及这些事件的时间顺序。这些数据将有助于充分反映或准确捕捉玩家离开游戏的倾向。
3 数据集描述
在本节中,我们提供了来自网易游戏发布的一款MMORPG的真实数据集的一些详细信息。该数据集收集自一个服务器,包括2018年6月22日至2018年9月20日的用户日志,涵盖超过88万用户的数亿行为序列。在该数据集中,基于游戏内容和用户日志定义了485个常规事件,并为每个玩家自动建立了记录事件及触发时间的日志。
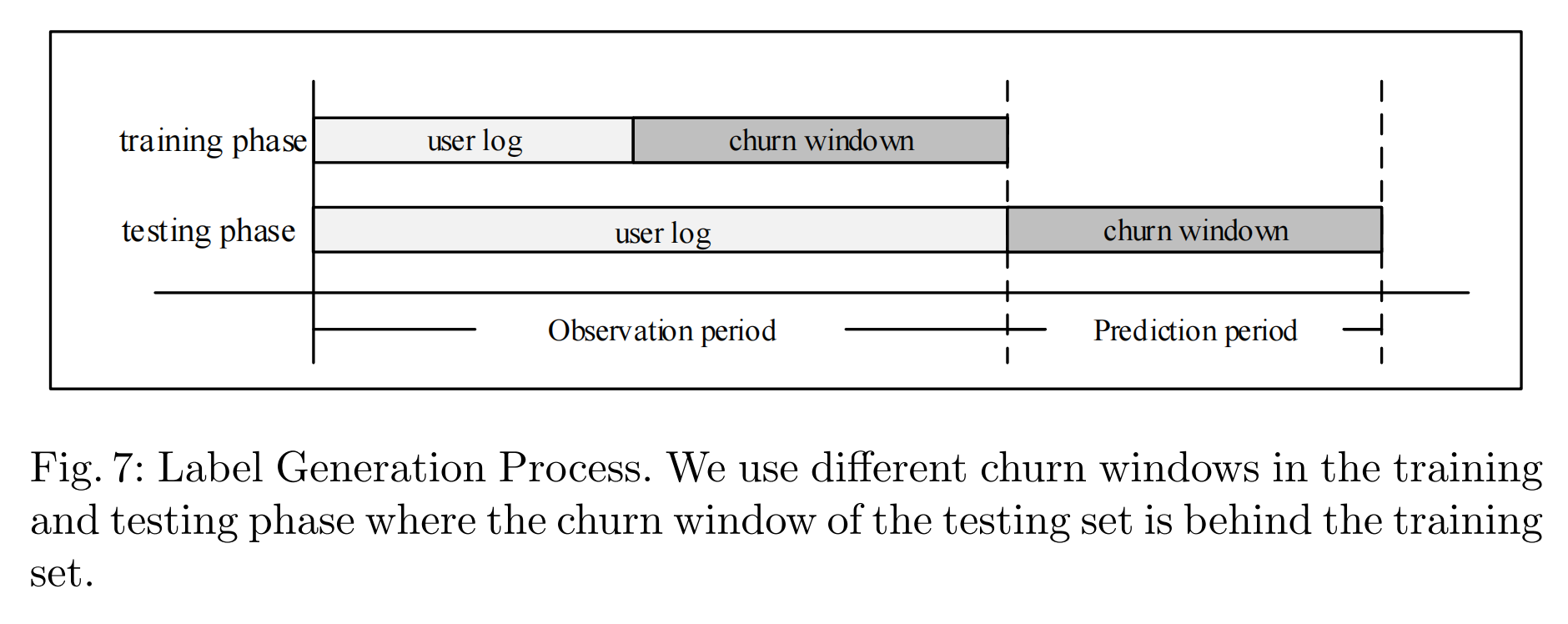
在该数据集中,我们定义了两类用户:流失者和非流失者。通常,流失者代表永久离开游戏的用户。为了减少歧义,我们将那些持续不活跃超过7天的用户定义为流失者 [12, 23]。假设离开日表示用户离开游戏的那一天。为了在同一阶段比较两类用户,我们主要关注在特定时期内离开游戏的用户和那些没有离开的用户。我们将该时期定义为流失窗口,表示为[观察日1, 观察日2]。离开日落在此窗口内的用户将被视为“流失者”,而离开日在观察日2之后的用户被定义为“非流失者”。在接下来的部分中,我们采用这种设置来定义“流失者”和“非流失者”。
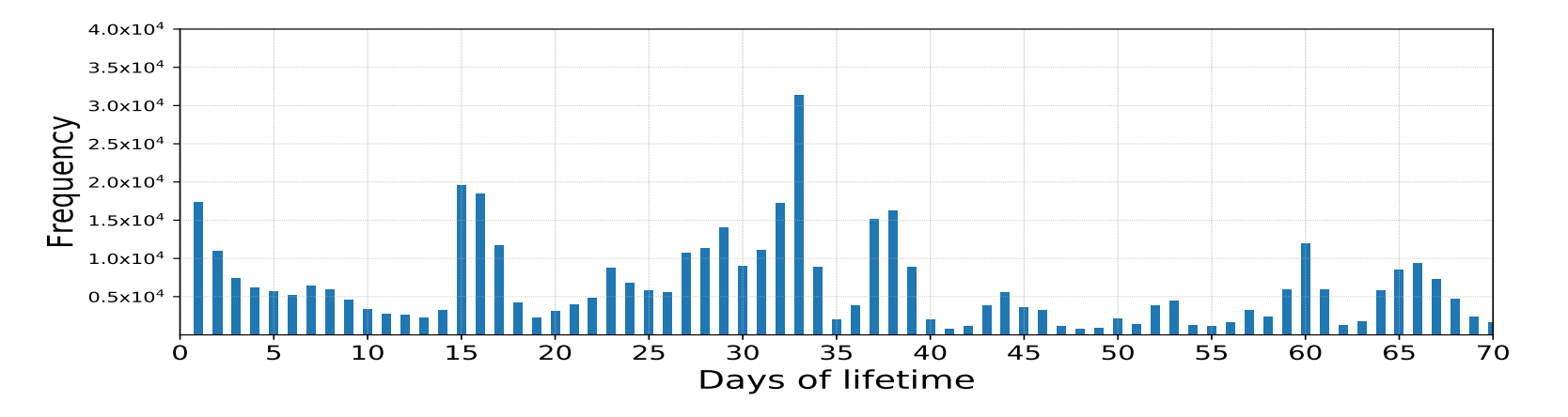
为了找出用户在离开前玩了多长时间游戏,我们检查了该数据集中所有用户生命周期的分布,如图1所示。我们观察到流失者的数量周期性波动。这表明用户在玩了一定天数(15/16/32/33天)后有较高的概率离开游戏。预测模型需要通过考虑用户生命周期来捕捉这一特征,以预测用户离开的概率。
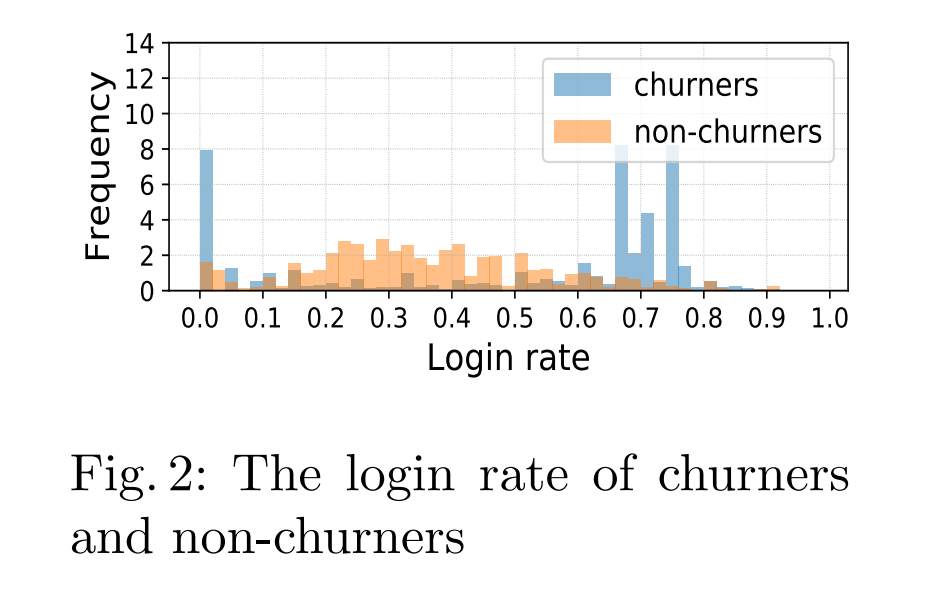
为了更好地理解是什么激励用户继续玩游戏,我们比较了流失者和非流失者的登录信息和游戏内行为信息之间的差异。我们观察到几个显著特征。
图2显示了流失者和非流失者在整个生命周期内的登录天数百分比。我们可以看到,非流失者集中在0.2到0.5的范围内,而流失者在两端都有高分布。一些流失者由于各种原因(如对游戏缺乏兴趣)登录率较低。但有趣的是,图中还揭示了高登录率的用户有更高的离开概率。这种用户在离开前频繁登录游戏的现象对游戏运营商采取一些流失预防措施(如推送通知)有帮助。
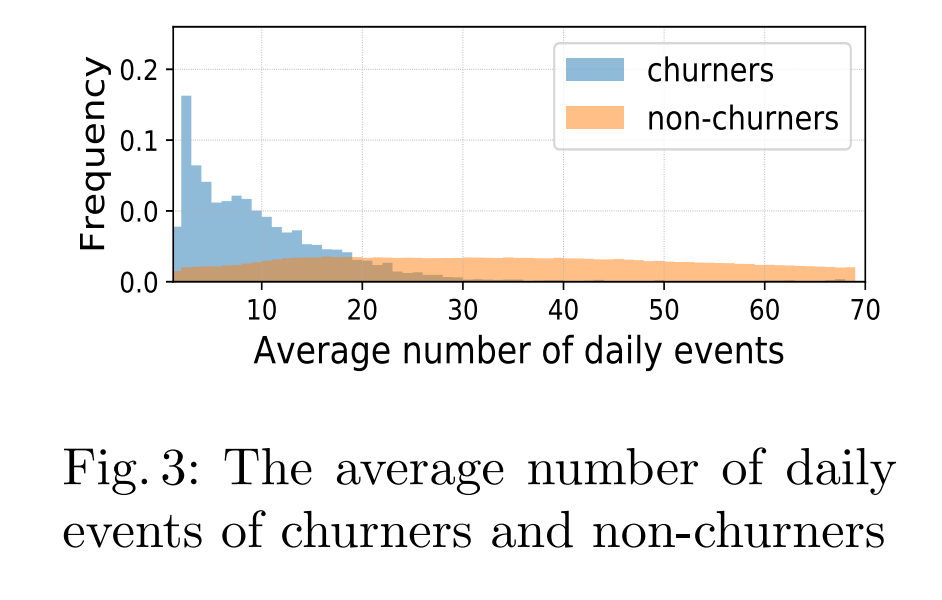
在图3中,流失者的平均每日事件相对较少,非流失者的分布表现稳定。直观上,事件数量反映了游戏时间的长短。流失者每天的事件较少,因为他们由于缺乏动机而较少参与游戏,而非流失者更愿意花时间玩游戏,因此有更多的事件。
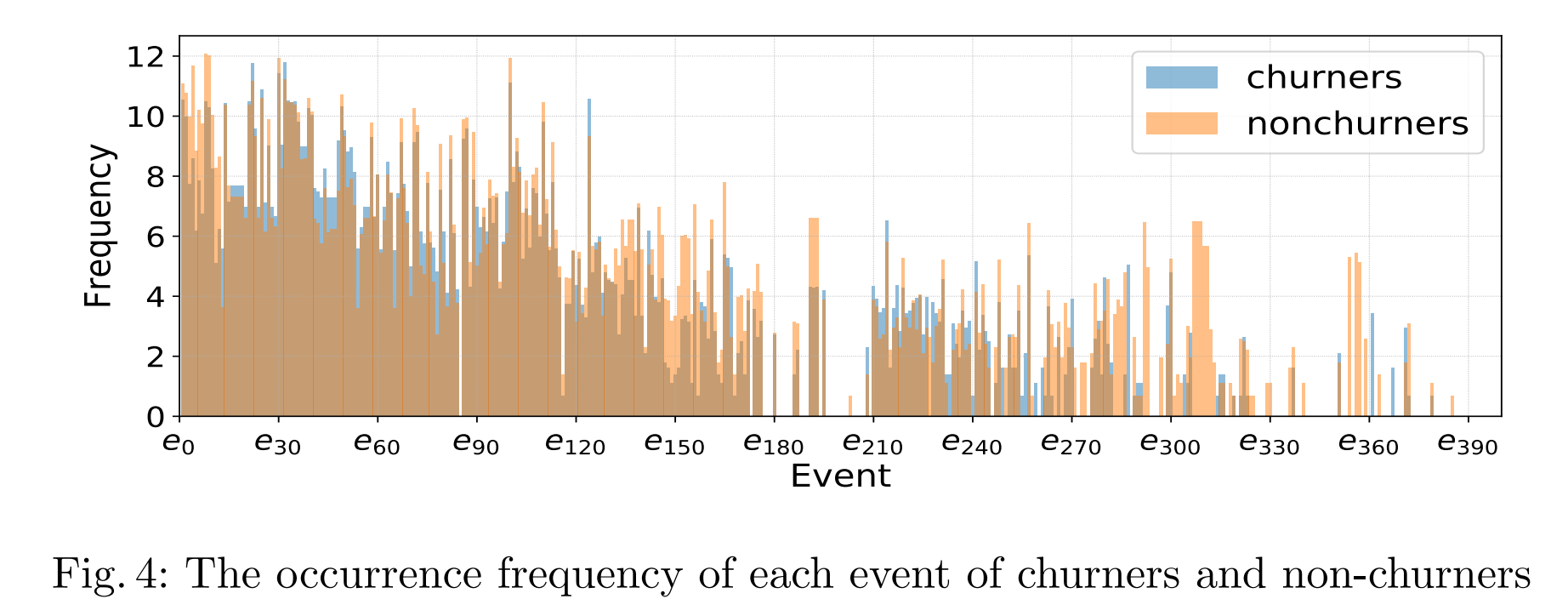
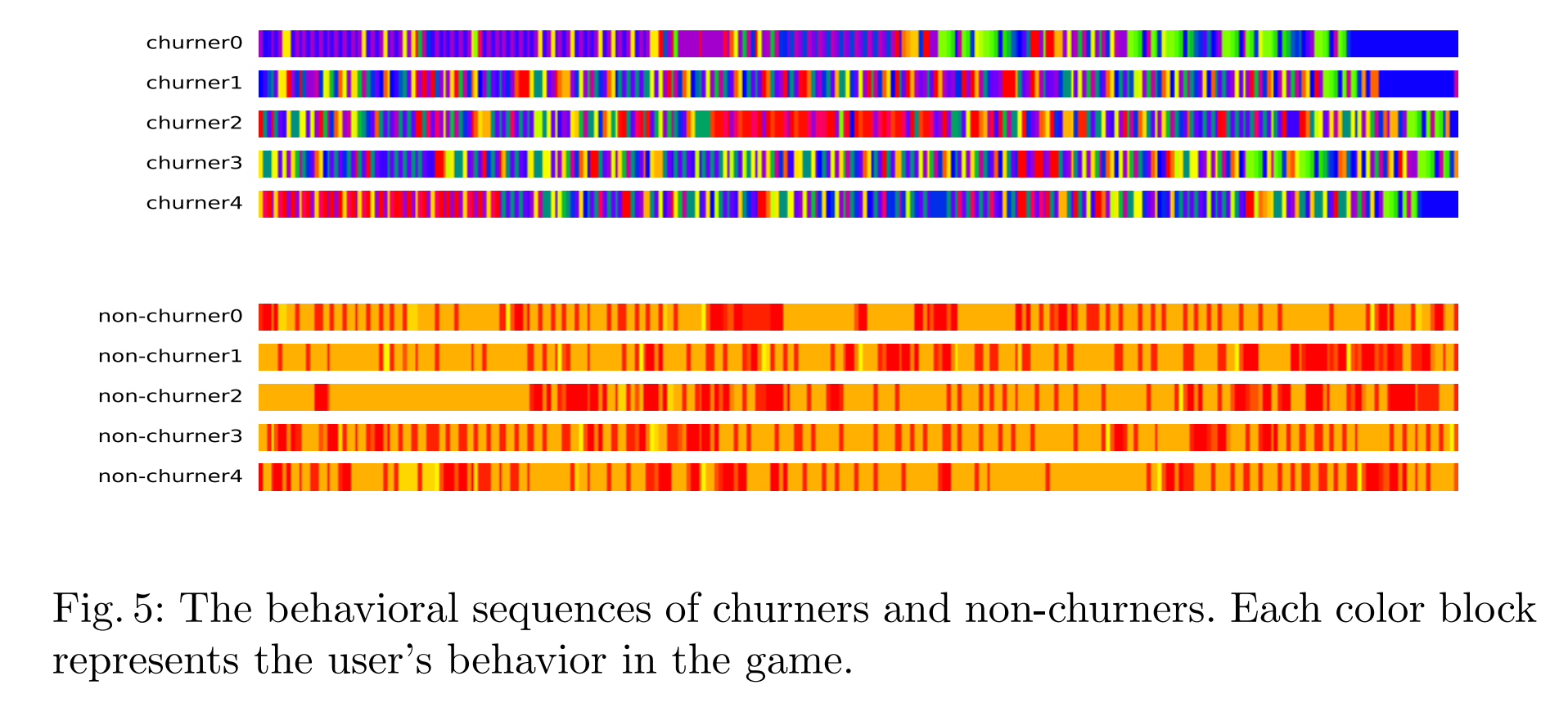
然后我们调查了用户的游戏内行为。图4绘制了流失者和非流失者的每个事件的频率。我们可以看到,这两类用户在事件频率上存在一些差异。一些事件在某些类型的用户中更频繁地发生或具有相对较高的频率。例如,e150在非流失者中频率较高,而e310在非流失者中常见,但在流失者中很少发生。对于事件序列,我们随机抽取了5个流失者和5个非流失者在流失窗口内,并提取了他们离开日和观察日1之前的最后200个事件序列。结果如图5所示。在此期间,非流失者的行为通常多样且每个行为持续时间较短,而流失者的行为单调且每个行为持续时间较长。可以清楚地看到,流失者和非流失者的行为存在显著差异,这进一步表明短期行为反映了用户是否留在游戏中。一些研究关注长期行为建模,这不仅面临冗长的行为信息,还增加了模型的复杂性和训练时间。
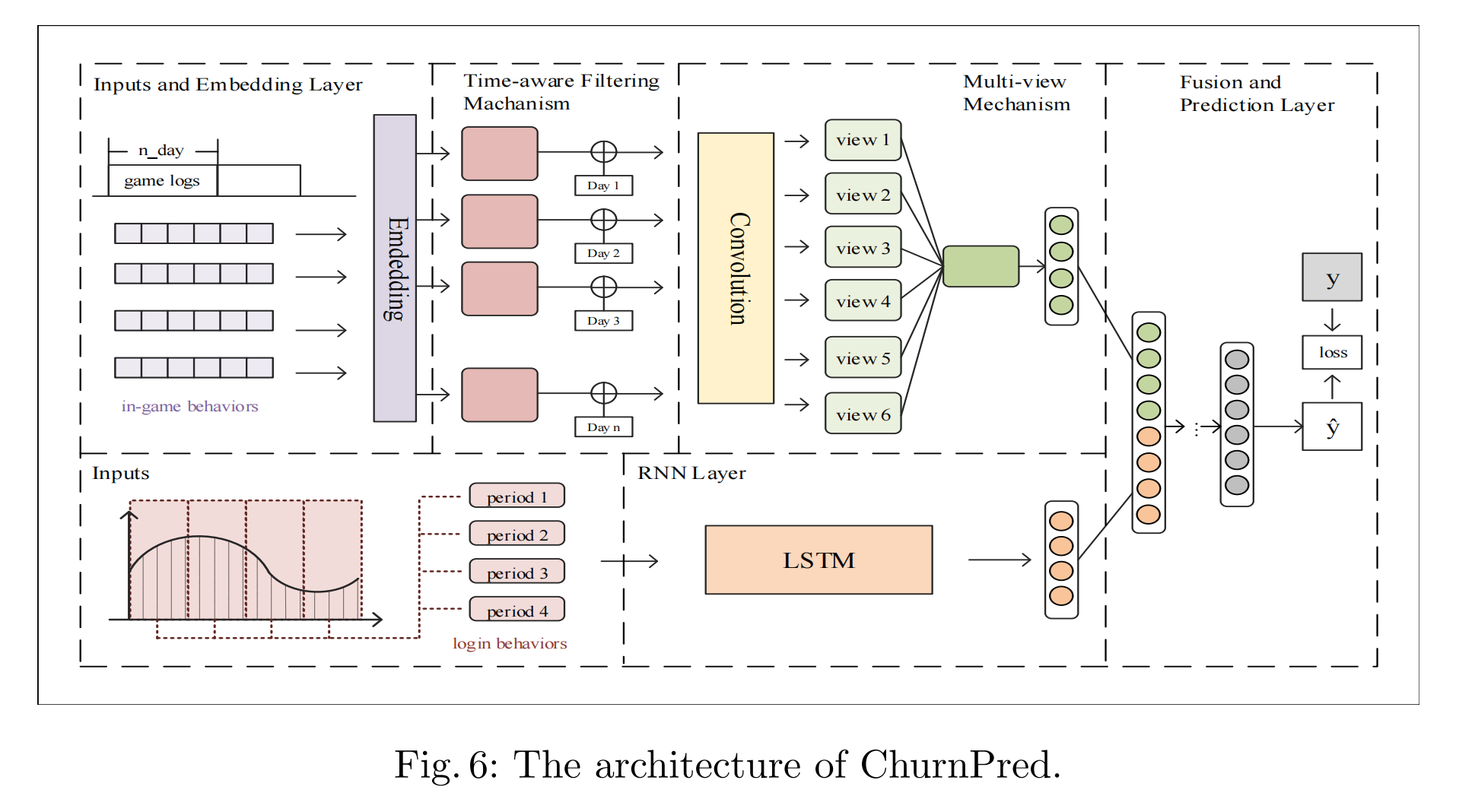
4 模型架构
在本节中,我们介绍所提出模型的详细信息。架构如图6所示。该模型可以分为三个主要组件:
1)一个游戏内行为编码器,将每个用户的游戏内行为信息建模为上下文嵌入向量。
2)一个登录行为编码器,将每个用户在在线游戏中的登录信息建模为上下文嵌入向量。
3)融合和预测层,聚合上述两种嵌入向量并输出用户是否离开游戏的最终可能性。
4.1 游戏内行为编码器
输入
在游戏内信息方面,我们收集用户u的每日事件e(ut_d) in E,并按时间顺序排列,表示为游戏内行为序列 S u ( d ) = { e ( u d 1 ) , . . . , e ( u t d ) , . . . , e ( u B d ) } Su(d) = \{e(ud_1), ..., e(ut_d), ..., e(uB_d)\} Su(d)={e(ud1),...,e(utd),...,e(uBd)},其中E是事件集,d表示事件的日期,B表示 S u ( d ) Su(d) Su(d)的长度。正如我们上面讨论的,用户的总历史行为是冗长且大量的,这可能大大增加模型的复杂性和训练时间。在本文中,我们使用观察日1之前T1天的数据作为输入,表示为 S u = { S u ( 1 ) , S u ( 2 ) , . . , S u ( T 1 ) } Su = \{Su(1), Su(2), .., Su(T1)\} Su={Su(1),Su(2),..,Su(T1)}。
嵌入层
给定 S u ( d ) = { e ( u d 1 ) , . . . , e ( u t d ) , . . . , e ( u B d ) } Su(d) = \{e(ud_1), ..., e(ut_d), ..., e(uB_d)\} Su(d)={e(ud1),...,e(utd),...,e(uBd)},通过嵌入层将事件嵌入到潜在空间中的内容向量。在离散化过程中,每个事件标识e(ut_d) in E被编码为一个具有|E|维度的one-hot向量o(ut_d)。由于输入是高维二进制向量,我们使用嵌入层将其转换为稠密表示。事件嵌入向量x(ut_d)可以通过以下公式获得:
x ( u t d ) = W e T o ( u t d ) , t ∈ { 1 , 2 , . . . , B } x(ut_d) = We^T o(ut_d), t \in \{1, 2, ..., B\} x(utd)=WeTo(utd),t∈{1,2,...,B}
其中 W e ∈ R ∣ E ∣ × L We \in R^{|E| \times L} We∈R∣E∣×L表示潜在因子矩阵(嵌入矩阵),L是用于设置潜在向量维度的预定义值。
时间感知过滤机制
在上述分析中,我们发现用户的行为与其发生的日期密切相关。因此,我们提出了一种时间感知门控机制,以基于时间段捕捉这些特征行为。Dauphin等人在[6]中提出了门控线性单元(GLU),他们在语言建模中使用这种门控机制,使模型选择相关词或特征以生成下一个词。受其工作的启发,我们基于此结构做了一些修改,额外考虑了时间段对输入的影响。我们为每一天引入了一个时间矩阵W(d),以选择哪些特征将传播到下游层。公式如下:
D u ( d ) = X u ( d ) ⊙ σ ( X u ( d ) ∗ W ( d ) + b ( d ) ) , d ∈ { 1 , 2 , . . . , T 1 } Du(d) = Xu(d) \odot \sigma(Xu(d) \ast W(d) + b(d)), d \in \{1, 2, ..., T1\} Du(d)=Xu(d)⊙σ(Xu(d)∗W(d)+b(d)),d∈{1,2,...,T1}
其中 X u ( d ) = { x ( 1 ) u t , x ( 2 ) u t , . . , x ( u t B ) } ∈ R B × L Xu(d) = \{x(1)ut, x(2)ut, .., x(ut_B)\} \in R^{B \times L} Xu(d)={x(1)ut,x(2)ut,..,x(utB)}∈RB×L, σ \sigma σ是一个sigmoid函数, ⊙ \odot ⊙是Hadamard(元素级)乘积,W(d),b(d)是需要学习的参数。
多视角机制
随着卷积神经网络(CNN)在捕捉图像识别局部特征方面的成功,我们采用CNN单元进行多视角生成,将 V u ( d ) Vu(d) Vu(d)视为行为信息的“图像”,并将序列模式视为该“图像”的局部特征。卷积滤波器表示为 k h × k w kh \times kw kh×kw矩阵,它们滑过“图像”,然后总结各种视角下行为的多种组合。我们使用B个滤波器分别对每一天的游戏内行为进行编码。每个滤波器 F ( d ) ∈ R k h × k w F(d) \in R^{kh \times kw} F(d)∈Rkh×kw滑过 D u ( d ) Du(d) Du(d)如下:
v u l k ( d ) = D u , ( d { ) l : l + k h − 1 , k : k + k w − 1 ⊕ F ( d ) } vu_{lk}(d) = Du,(d\{)_{l:l+kh-1,k:k+kw-1} \oplus F(d)\} vulk(d)=Du,(d{)l:l+kh−1,k:k+kw−1⊕F(d)}
V u ( d ) = { v u l k ( d ) ∣ 1 ≤ l ≤ B − k h + 1 , 1 ≤ k ≤ L − k w + 1 } Vu(d) = \{vu_{lk}(d) | 1 \le l \le B - kh + 1, 1 \le k \le L - kw + 1\} Vu(d)={vulk(d)∣1≤l≤B−kh+1,1≤k≤L−kw+1}
其中 ⊕ \oplus ⊕是元素级乘积的和, D u , { l : l + k h − 1 , k : k + k w − 1 } Du,\{l:l+kh-1,k:k+kw-1\} Du,{l:l+kh−1,k:k+kw−1}表示 D u ( d ) Du(d) Du(d)的卷积区域,行从 l l l到 l + k h − 1 l+kh-1 l+kh−1,列从 k k k到 k + k w − 1 k+kw-1 k+kw−1。
注意,从上述公式获得的视图对最终结果的贡献并不相等。我们引入了一种注意力机制[24]来解决这个问题。传统的注意力机制用于学习多个向量的注意力权重。在本文中,我们修改了公式,以便从多个矩阵(即视图)中学习权重。最终视图 V u Vu Vu的表示形式是这些生成视图的加权和,计算如下:
H u ( d ) = t a n h ( V u ( d ) ) Hu(d) = tanh(Vu(d)) Hu(d)=tanh(Vu(d))
α ( d u ) = e x p ( H u ( d ) ⊕ W a ) ∑ i = 1 T 1 e x p ( H u ( i ) ⊕ W a ) \alpha(d_u) = \frac{exp(Hu(d) \oplus Wa)}{\sum_{i=1}^{T1} exp(Hu(i) \oplus Wa)} α(du)=∑i=1T1exp(Hu(i)⊕Wa)exp(Hu(d)⊕Wa)
V u = ∑ i = 1 T 1 α ( d ) V u ( d ) Vu = \sum_{i=1}^{T1} \alpha(d)Vu(d) Vu=i=1∑T1α(d)Vu(d)
其中 V u ( d ) , H u ( d ) , W a , V u ∈ R ( B − k h + 1 ) × ( L − k w + 1 ) Vu(d), Hu(d), Wa, Vu \in R^{(B-kh+1) \times (L-kw+1)} Vu(d),Hu(d),Wa,Vu∈R(B−kh+1)×(L−kw+1), α u ( d ) \alpha_u(d) αu(d)是视图 V u ( d ) Vu(d) Vu(d)的注意力权重, W a , b a Wa, ba Wa,ba是训练参数。为了将最终视图转换为潜在向量,我们使用最大池化来总结最终视图的特征。公式如下:
c i n u = m a x − p o o l i n g ( V u ) c_{in_u} = max - pooling(Vu) cinu=max−pooling(Vu)
其中 c 1 u ∈ R B − k h + 1 c_{1_u} \in R^{B-kh+1} c1u∈RB−kh+1是游戏内行为信息的上下文表示。
4.2 登录行为编码器
输入
在线游戏中的登录行为可以表示为登录频率、游戏时间等。在本文中,我们使用每个用户的每日游戏时间来描述登录信息。我们定义一个大小为 T 1 T1 T1 天的时间窗口,并考虑观察日1之前的 T 2 T2 T2 个连续时间窗口。输入可以表示为一个序列 M u = { m 1 , m 2 , . . , m T 2 } Mu = \{m1, m2, .., mT2\} Mu={m1,m2,..,mT2},其中 m t mt mt 是一个 ∣ T 1 ∣ |T1| ∣T1∣ 维向量,表示第 t t t 个窗口中每一天的时长。
循环神经网络(RNN)层
我们应用多层 LSTM(长短期记忆网络)进行长短期建模,因为它将每日数据的各种时期作为时间序列,并且在学习内在时间依赖性方面具有强大的能力,从而捕捉活动序列的变化。每层 LSTM 的计算如下:
i t = σ ( W i ∗ h t − 1 + W i ∗ m t + b i ) it = \sigma(Wi \ast ht-1 + Wi \ast mt + bi) it=σ(Wi∗ht−1+Wi∗mt+bi)
f t = σ ( W f ∗ h t − 1 + W i ∗ m t + b f ) ft = \sigma(Wf \ast ht-1 + Wi \ast mt + bf) ft=σ(Wf∗ht−1+Wi∗mt+bf)
c ˜ t = t a n h ( W c ∗ h t − 1 + W i ∗ m t + b c ) c˜t = tanh(Wc \ast ht-1 + Wi \ast mt + bc) c˜t=tanh(Wc∗ht−1+Wi∗mt+bc)
c t = f t ⊙ c t − 1 + i t ⊙ c ˜ t ct = ft \odot ct-1 + it \odot c˜t ct=ft⊙ct−1+it⊙c˜t
g t = σ ( W g ∗ h t − 1 + W g ∗ m t + b g ) gt = \sigma(Wg \ast ht-1 + Wg \ast mt + bg) gt=σ(Wg∗ht−1+Wg∗mt+bg)
h t = g t ⊙ t a n h ( c t ) ht = gt \odot tanh(ct) ht=gt⊙tanh(ct)
其中, i t it it、 f t ft ft、 g t gt gt 和 c t ct ct 分别是时间 t t t 的输入门、遗忘门、输出门和记忆状态。 h t ht ht 代表隐藏状态向量,我们默认设置 h 0 = 0 h0 = 0 h0=0。 W i , W f , W c , W g , b i , b f , b c , b g Wi, Wf, Wc, Wg, bi, bf, bc, bg Wi,Wf,Wc,Wg,bi,bf,bc,bg 是训练参数。最后一个 LSTM 的输出将被视为登录信息的上下文表示 c 2 u = h T 2 c2_u = hT2 c2u=hT2。
4.3 融合与预测层
在获得两种上下文嵌入向量后,即 c i n u c_{in}^u cinu 和 c o u t u c_{out}^u coutu,我们将这些向量连接成一个统一的向量 c u c^u cu,它将被视为行为特征的高级表示。我们将其输入到一个全连接的前馈神经网络,并输出最终的流失预测概率。通过融合得到的统一嵌入表示可以表示为:
c u = [ c 1 u , c 2 u ] c^u = [c_{1}^u, c_{2}^u] cu=[c1u,c2u]
y u = σ ( W p ∗ c u + b p ) y^u = \sigma(W^p \ast c^u + b^p) yu=σ(Wp∗cu+bp)
其中 [ . ] [.] [.] 是连接操作, W p , b p W^p, b^p Wp,bp 是这一层的参数。
4.4 损失函数与优化
最后,我们采用交叉熵作为模型优化的损失函数。为了防止过拟合,我们在损失函数中对参数进行 l 2 l2 l2 正则化。目标函数定义如下:
L = − ∑ [ y i log y ^ i + ( 1 − y i ) log ( 1 − y ^ i ) ] + λ ∥ Θ ∥ 2 L = - \sum [y_i \log \hat{y}_i + (1 - y_i) \log(1 - \hat{y}_i)] + \lambda \| \Theta \|^2 L=−∑[yilogy^i+(1−yi)log(1−y^i)]+λ∥Θ∥2
其中, y ^ i \hat{y}_i y^i 是用户 u i u_i ui 成为流失用户的概率, y i y_i yi 是相应的真实得分。如果用户 u u u 是流失用户,则 y i = 1 y_i = 1 yi=1;否则, y i = 0 y_i = 0 yi=0。 Θ \Theta Θ 代表在训练阶段将要学习的所有模型参数, λ \lambda λ 是正则化权重。我们使用 Adam 优化器来学习模型。
5 实验
在本节中,我们旨在回答以下研究问题:
- RQ1: 与广泛使用的方法和最新的流失预测方法相比,ChurnPred 的表现如何?
- RQ2: 我们提出的方法中,游戏内行为编码器和登录行为编码器的效果如何?
- RQ3: 不同超参数设置(例如嵌入向量的维度)如何影响 ChurnPred 的性能?
5.1 数据集和实验设置
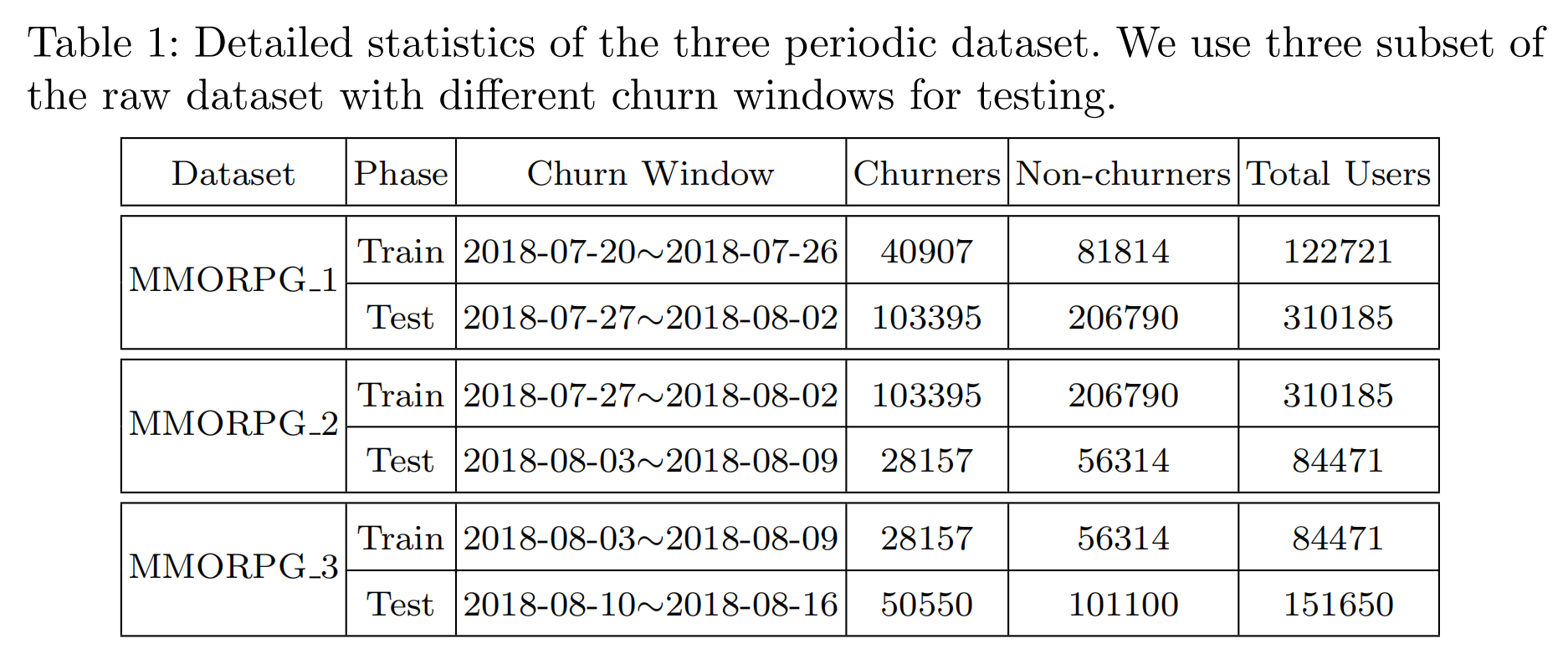
我们在第3节描述的真实世界数据集上进行了实验。具体来说,我们提取了用户在游戏中的每日事件,并按时间顺序排列,作为游戏内行为信息的特征(即行为序列)。每个每日行为序列的长度将被视为登录信息的特征(即每日游戏时间),并通过归一化预处理。在构建训练和测试样本时,受文献 [9] 启发,我们采用了类似的拆分过程来消除数据泄漏问题。此外,为了避免数据分布不均,我们采用了下采样方法,即流失用户与非流失用户的比例为1:2。为了更好地评估我们模型的性能,我们将数据集分为三个子集,其中测试阶段的流失窗口为连续三周。这些数据集的描述如表1所示。
5.2 评估指标和基线
我们采用了三种广泛使用的评估指标,即精确度(Precision)、F1分数(F1-Score)和准确度(Accuracy),并在达到最佳F1分数时记录性能。每个实验运行5次,以最佳F1分数作为最终性能。为了验证所提出的ChurnPred模型的有效性,我们将其与以下基线进行比较:
- 逻辑回归(Logistic Regression, LR)[10, 14]:这是一种流行的线性分类算法,使用登录信息。它分析一个或多个现有自变量之间的关系。
- 随机森林(Random Forest, RF)[10]:这是一种基于集成学习的传统分类器,包含多个决策树,并共同做出分类决策。输入与LR相同。
- 多层感知机(Multi-layer Perceptron, MLP)[14]:多层感知机是一种人工神经网络,将一组输入向量映射到低维空间。我们使用登录信息作为输入,实施了包含2个全连接层的MLP。
- wClusterDist [3]:wClusterDist是一种基于距离的分类方案,基于登录信息以及在参与度、热情和持久性三个语义维度中派生的特征进行分类。
- LSTM+注意力机制(ATT-LSTM)[15]:这是一种基于注意力机制的LSTM模型,用于分类早期流失用户,其输入是以固定间隔分箱的用户行为事件序列。输入是注册后的用户游戏内行为序列。
- PLSTM+ [22]:这是一个涉及可解释聚类和流失预测的两步框架。预测模型基于LSTM,通过利用用户多维活动之间的相关性,并从可解释聚类中得出底层用户类型。与其原始输入类似,我们将10种最频繁的游戏内行为的每日发生次数作为输入进行预测。
5.3 参数设置
基于神经网络的模型(包括ChurnPred、ATT-LSTM、PLSTM+和MLP)均在Pytorch中实现。这些模型使用Adam优化器进行优化,默认批量大小为512。在超参数方面,我们对神经网络的超参数进行了网格搜索:学习率在 { 0.0001 , 0.001 , 0.01 } \{0.0001, 0.001, 0.01\} {0.0001,0.001,0.01}之间调整,隐藏层和嵌入矩阵的大小在 { 8 , 16 , 32 , 64 } \{8, 16, 32, 64\} {8,16,32,64}之间调整,阈值在 { 0.1 , 0.2 , 0.3 , 0.4 , 0.5 , 0.6 , 0.7 , 0.8 , 0.9 } \{0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9\} {0.1,0.2,0.3,0.4,0.5,0.6,0.7,0.8,0.9}之间调整。对于ChurnPred,卷积由宽度为3且高度等于嵌入矩阵大小的卷积核完成。对于PLSTM+,我们将损失函数中的 λ \lambda λ设置为1,并在每个LSTM中使用2个隐藏层。对于wClusterDist,我们将聚类数量设置为5。对于ATT-LSTM,我们使用2层LSTM并将dropout设置为0.5。
5.4 性能比较 (RQ1)
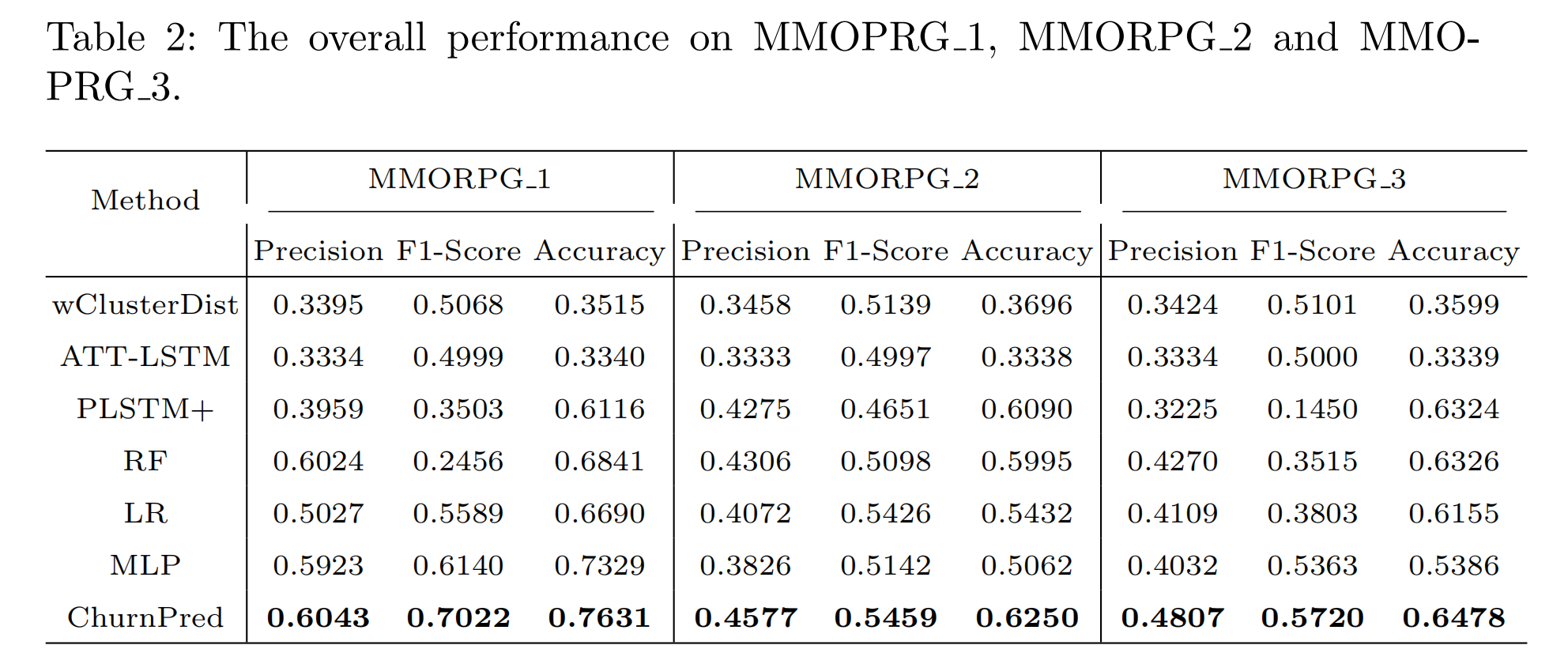
表2显示了所提出模型与最新模型的性能比较。实验结果的关键观察如下:
- 在传统方法LR、RF和MLP中,RF在三个数据集上的平均精确度最好,而MLP在三个数据集上的平均F1分数最好。这表明RF在预测流失用户方面相对准确,但由于RF在大多数情况下将流失用户误认为非流失用户,因此未能找到更多的真实样本。MLP在这些方法中具有较高的F1分数。可能的原因是该模型尽可能将非流失用户预测为流失用户,从而召回越来越多的真实样本,从而在精度下降的情况下提高了F1分数。
- 在比较模型中,PLSTM+和ATT-LSTM都使用用户的游戏内行为信息作为输入,但表现出不同的性能。PLSTM+表现较差,表明用户行为事件的频率无法完全描述用户的近期行为信息。相反,ATT-LSTM使用行为序列作为输入并取得了更好的性能,这表明用户行为序列中的潜在行为模式有能力指示用户是否会离开游戏。
- RF、LR、MLP和wClusterDist都使用登录信息作为输入。在这些模型中,MLP在平均F1分数指标上表现最好,其次是wClusterDist。结果表明,MLP能够捕捉到登录序列中的动态变化,而RF和LR缺乏编码这些信息的能力。wClusterDist受益于参与度、热情和持久性三个语义维度中的派生特征,这些特征描述了用户登录状态的变化,从而表现出更好的性能。
- ChurnPred总体上优于所有基线。这主要是由于考虑了在线游戏中的登录信息和游戏内行为信息。对于游戏内行为,它利用多视角机制来学习潜在的行为模式。对于登录信息,它对每日游戏时间的变化敏感,这表明模型捕捉到了登录信息中的动态特征。通过整合这两种信息,模型得到了极大的改进。
5.5 组件分析 (RQ2)
为了评估我们提出的方法中登录行为编码器和游戏内行为编码器之间的性能,我们设计了三种不同的模型:ChurnPred-α保留登录行为编码器,ChurnPred-β仅使用游戏内行为编码器,ChurnPred采用上述两种组件。这三种模型在MMORPG 1数据集上进行,并在训练时保持相同的模型参数。结果如图8所示。我们可以看到,ChurnPred取得了最佳性能,ChurnPred-β次之,ChurnPred-α排在第三。这表明游戏内行为序列暗示了潜在的行为模式,与在线游戏中的登录信息相比,包含了更多关于用户离开的意图的信息。此外,结果证明了我们提出的ChurnPred在编码内在的序列模式和登录模式方面的有效性,这两者在决策过程中都起到了重要作用。

5.6 参数敏感性 (RQ3)
为了研究ChurnPred模型的鲁棒性,我们研究了不同参数选择如何影响性能。除了被测试的参数外,我们将其他参数设置为默认值。实验在MMORPG 1数据集上进行。
嵌入大小的影响
图9(a)显示了不同嵌入矩阵维度大小下的性能。我们可以观察到,随着维度的增加,模型性能总体上下降,这表明所提出的模型对嵌入矩阵的维度敏感,选择合理的维度长度可以使模型表现优越,反之亦然。
隐藏状态维度的影响
我们保持相同的超参数,并在 { 8 , 16 , 32 , 64 , 128 } \{8, 16, 32, 64, 128\} {8,16,32,64,128}范围内改变LSTM组件中隐藏状态的维度(hidden dim),以研究ChurnPred是否能从维度大小中受益。实验结果如图9(b)所示。我们可以看到,当hidden dim=2时,模型表现最好,而在大多数情况下表现较差,这意味着需要适当地选择隐藏状态的维度大小,否则性能会变差。
层数的影响
图9©显示了LSTM组件中不同隐藏层数量(n layer)下的性能。当n layer=2时,获得了最佳性能。之后,随着层数的增加,性能开始缓慢下降并趋于稳定。这表明两层足以使模型达到显著性能,更多的层数不会带来更好的性能。

6 结论与未来工作
在本文中,我们研究了在线游戏中的流失预测问题。我们首先探索并分析了真实世界MMORPG用户的行为,包括参与度、生命周期天数、游戏内行为等。根据分析见解,我们开发了一种名为ChurnPred的流失预测模型,通过利用在线游戏中的游戏内行为和登录行为。我们提出了一种时间感知过滤机制和多视角机制进行行为建模。在真实世界数据集上进行的综合实验表明,与最新方法相比,所提出模型的有效性。作为未来工作,我们将考虑游戏内行为的社会影响。我们认为,更丰富的信息可以帮助模型在流失预测上做出更好的决策。此外,未来还将考虑所提出模型的可扩展性问题。
References
-
Bertens, P., Guitart, A., Peri´a˜nez, A.: Games and big data: A scalable multi- ´
dimensional churn prediction model. In: 2017 IEEE Conference on Computational
Intelligence and Games (CIG). pp. 33–36. IEEE (2017) -
Borbora, Z., Srivastava, J., Hsu, K.W., Williams, D.: Churn prediction in mmorpgs
using player motivation theories and an ensemble approach. In: 2011 IEEE Third
International Conference on Privacy, Security, Risk and Trust and 2011 IEEE Third
International Conference on Social Computing. pp. 157–164. IEEE (2011) -
Borbora, Z.H., Srivastava, J.: User behavior modelling approach for churn prediction in online games. In: 2012 International Conference on Privacy, Security, Risk
and Trust and 2012 International Confernece on Social Computing. pp. 51–60.
IEEE (2012) -
Castro, E.G., Tsuzuki, M.S.: Churn prediction in online games using players’ login records: A frequency analysis approach. IEEE Transactions on Computational
Intelligence and AI in Games 7(3), 255–265 (2015) -
Chen, L., Liu, Y., He, X., Gao, L., Zheng, Z.: Matching user with item set: collaborative bundle recommendation with deep attention network. In: Proceedings of
the 28th International Joint Conference on Artificial Intelligence. pp. 2095–2101.
AAAI Press (2019) -
Dauphin, Y.N., Fan, A., Auli, M., Grangier, D.: Language modeling with gated
convolutional networks. In: Proceedings of the 34th International Conference on
Machine Learning-Volume 70. pp. 933–941. JMLR. org (2017) -
Kawale, J., Pal, A., Srivastava, J.: Churn prediction in mmorpgs: A social influence
based approach. In: 2009 International Conference on Computational Science and
Engineering. vol. 4, pp. 423–428. IEEE (2009) -
Kwon, H., Jeong, W., Kim, D.W., Yang, S.I.: Clustering player behavioral data
and improving performance of churn prediction from mobile game. In: 2018 International Conference on Information and Communication Technology Convergence
(ICTC). pp. 1252–1254. IEEE (2018) -
Liu, X., Xie, M., Wen, X., Chen, R., Ge, Y., Duffield, N., Wang, N.: A semisupervised and inductive embedding model for churn prediction of large-scale mobile games. In: 2018 IEEE International Conference on Data Mining (ICDM). pp.
277–286. IEEE (2018) -
Miloˇsevi´c, M., Zivi´c, N., Andjelkovi´c, I.: Early churn prediction with personalized ˇ
targeting in mobile social games. Expert Systems with Applications 83, 326–332
(2017) -
Nie, G., Wang, G., Zhang, P., Tian, Y., Shi, Y.: Finding the hidden pattern of credit
card holder’s churn: A case of china. In: International Conference on Computational
Science. pp. 561–569. Springer (2009) -
Pudipeddi, J.S., Akoglu, L., Tong, H.: User churn in focused question answering
sites: characterizations and prediction. In: Proceedings of the 23rd International
Conference on World Wide Web. pp. 469–474. ACM (2014) -
Ren, K., Qin, J., Zheng, L., Yang, Z., Zhang, W., Qiu, L., Yu, Y.: Deep Recurrent
Survival Analysis. arXiv e-prints arXiv:1809.02403 (Sep 2018) -
Runge, J., Gao, P., Garcin, F., Faltings, B.: Churn prediction for high-value players in casual social games. In: 2014 IEEE conference on Computational Intelligence
and Games. pp. 1–8. IEEE (2014) -
Sato, K., Oka, M., Kato, K.: Early churn user classification in social networking
service using attention-based long short-term memory. In: Pacific-Asia Conference
on Knowledge Discovery and Data Mining. pp. 45–56. Springer (2019) -
Tao, J., Xu, J., Gong, L., Li, Y., Fan, C., Zhao, Z.: Nguard: A game bot detection
framework for netease mmorpgs. In: Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. pp. 811–820. ACM
(2018) -
Umayaparvathi, V., Iyakutti, K.: Automated feature selection and churn prediction
using deep learning models. International Research Journal of Engineering and
Technology (IRJET) 4(3), 1846–1854 (2017) -
Viljanen, M., Airola, A., Heikkonen, J., Pahikkala, T.: Playtime measurement with
survival analysis. IEEE Transactions on Games 10(2), 128–138 (2017) -
Wu, J., Yuan, Q., Lin, D., You, W., Chen, W., Chen, C., Zheng, Z.: Who are
the phishers? phishing scam detection on ethereum via network embedding. arXiv
preprint arXiv:1911.09259 (2019) -
Xie, F., Chen, L., Ye, Y., Zheng, Z., Lin, X.: Factorization machine based service
recommendation on heterogeneous information networks. In: 2018 IEEE International Conference on Web Services (ICWS). pp. 115–122. IEEE (2018) -
Xie, Y., Li, X., Ngai, E., Ying, W.: Customer churn prediction using improved balanced random forests. Expert Systems with Applications 36(3), 5445–5449 (2009)
-
Yang, C., Shi, X., Jie, L., Han, J.: I know you’ll be back: Interpretable new user
clustering and churn prediction on a mobile social application. In: Proceedings of
the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data
Mining. pp. 914–922. ACM (2018) -
Yuan, S., Bai, S., Song, M., Zhou, Z.: Customer churn prediction in the online
new media platform: A case study on juzi entertainment. In: 2017 International
Conference on Platform Technology and Service (PlatCon). pp. 1–5. IEEE (2017) -
Zhou, P., Shi, W., Tian, J., Qi, Z., Li, B., Hao, H., Xu, B.: Attention-based bidirectional long short-term memory networks for relation classification. In: Proceedings
of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers). pp. 207–212 (2016)