Python数据可视化案例——折线图
目录
json介绍:
Pyecharts介绍
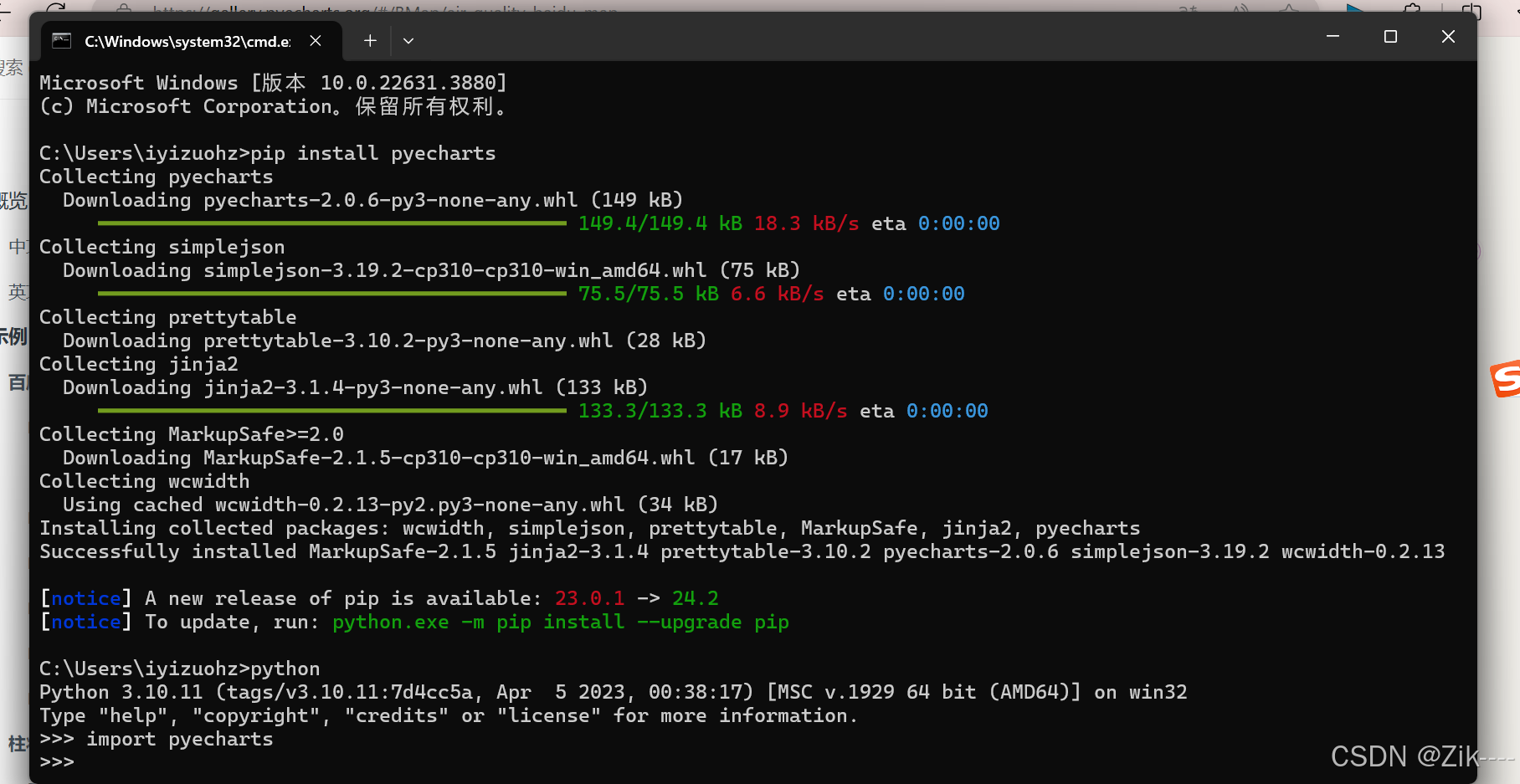
安装pyecharts包?
构建一个基础的折线图
配置全局配置项
综合案例:
使用工具对数据进行查看?:
数据处理
json介绍:
json是一种轻量级的数据交互格式,采用完全独立于编程语言的文本格式来存储和表示数据。不同语言格式之间通过json进行转化,json本质上为字符串。
下面演示使用json进行数据格式的转化。
python转为json使用json的dumps方法。
代码演示:
import json
# python转为json
# 列表转化
data =[{"name":"张三","age":12},{"name":"王五","age":13},{"name":"李四","age":14}]
json_str1=json.dumps(data,ensure_ascii= False) # ensure_ascii= false,让中文内容直接输出不转换为码
print(type(json_str1))
print(json_str1)
# 字典转化
d={'name':'李四','age':12}
json_str2=json.dumps(d,ensure_ascii= False)
print(type(json_str2))
print(json_str2)
运行结果:

反过来,json转为python使用json的loads方法。
代码演示:
data ='[{"name":"张三","age":12},{"name":"王五","age":13},{"name":"李四","age":14}]'
list1=json.loads(data)
print(type(list1))
print(list1)
运行结果:

Pyecharts介绍
Pyecharts是一个基于Python的开源数据可视化库,它用于创建交互式的图表和图形。Pyecharts可以生成各种类型的图表,包括折线图、柱状图、散点图、饼图等。它提供了丰富的图表样式和配置选项,使用户能够自定义图表的外观和行为。
打开pyecharts查看官方示例。
安装pyecharts包
构建一个基础的折线图
代码:
from pyecharts.charts import Line
# 创建一个 Line 类型的图表对象
line = Line()
# 添加 x 轴数据,这里传入一个包含三个国家名称的列表
# x 轴通常表示不同的类别或时间点等
line.add_xaxis(['中国','美国','日本'])
# 添加 y 轴数据,
# 第一个参数是系列名称,这里命名为'GDP'
# 第二个参数是对应的数据列表,表示三个国家的 GDP 值
line.add_yaxis('GDP',[30,20,10])
# 生成 HTML 文件来渲染图表,这样可以在浏览器中查看图像
line.render()
运行代码会发现出现一个html结尾的网页文件。
选择一个浏览器打开。
效果图:
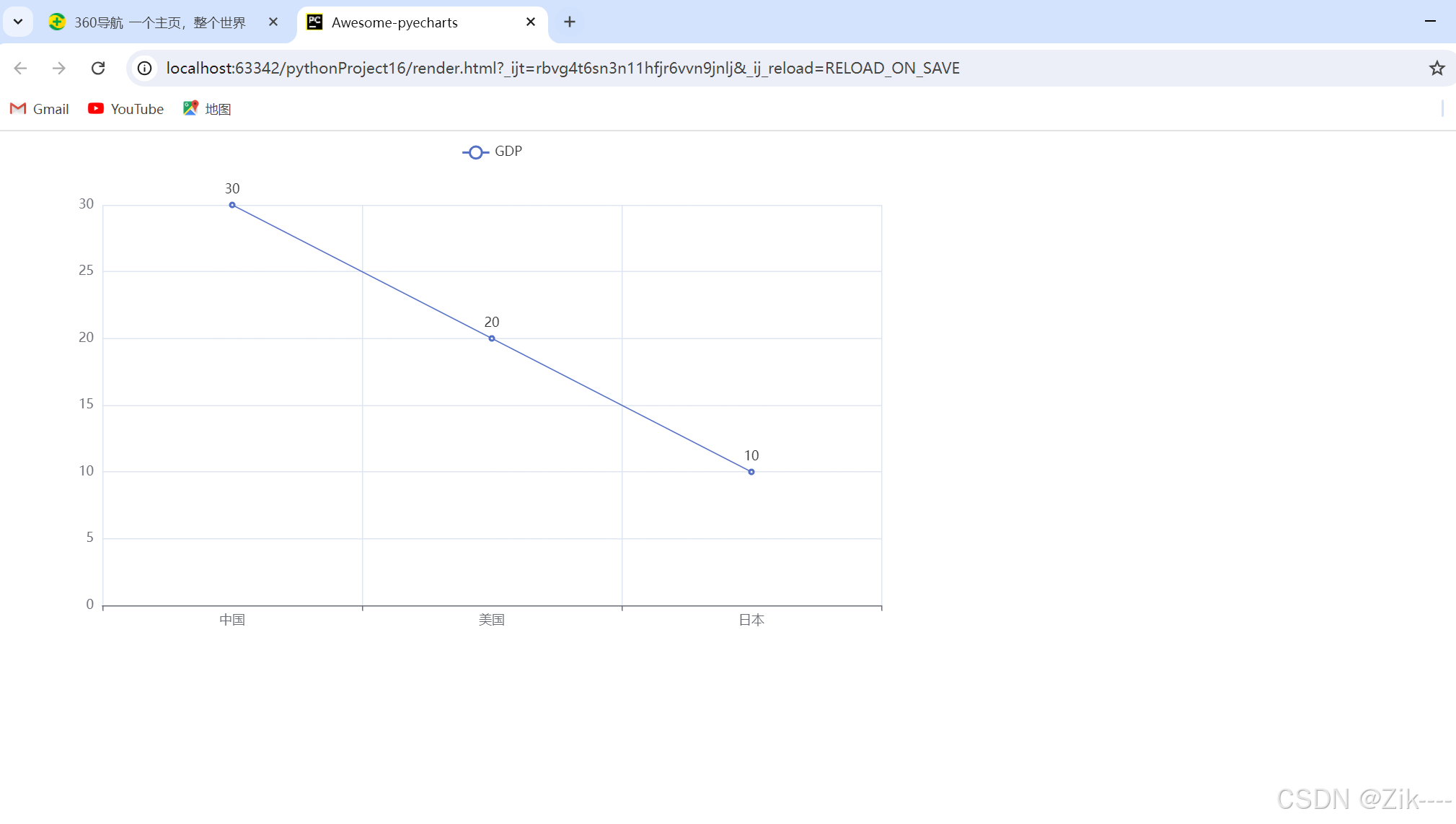
配置全局配置项:
通过导入包的更多功能添加一些更多的属性,使图表更美观。
from pyecharts.charts import Line # 从 pyecharts 库中导入 Line 类,用于创建折线图
from pyecharts.options import TitleOpts, LegendOpts, ToolboxOpts # 导入用于设置标题、图例和工具箱选项的类
# 创建一个折线图对象
line = Line()
# 添加 x 轴数据,这里是三个国家的名称
line.add_xaxis(['中国', '美国', '日本'])
# 添加 y 轴数据,第一个参数是系列名称,这里是'GDP',第二个参数是对应国家的 GDP 值列表(这里只是示例数据)
line.add_yaxis('GDP', [30, 20, 10])
# 设置全局配置项
line.set_global_opts(
# 设置标题选项
title_opts=TitleOpts(
title='GDP展示', # 设置标题为'GDP展示'
pos_left='center', # 设置标题水平位置为居中
pos_bottom='1%' # 设置标题距离底部为 1%的位置
),
# 设置图例选项,is_show=True 表示显示图例
legend_opts=LegendOpts(is_show=True),
# 设置工具箱选项,is_show=True 表示显示工具箱
toolbox_opts=ToolboxOpts(is_show=True)
)
# 生成并渲染图表,默认会在当前目录下生成一个 HTML 文件,可以在浏览器中打开查看图表
line.render()
效果图:
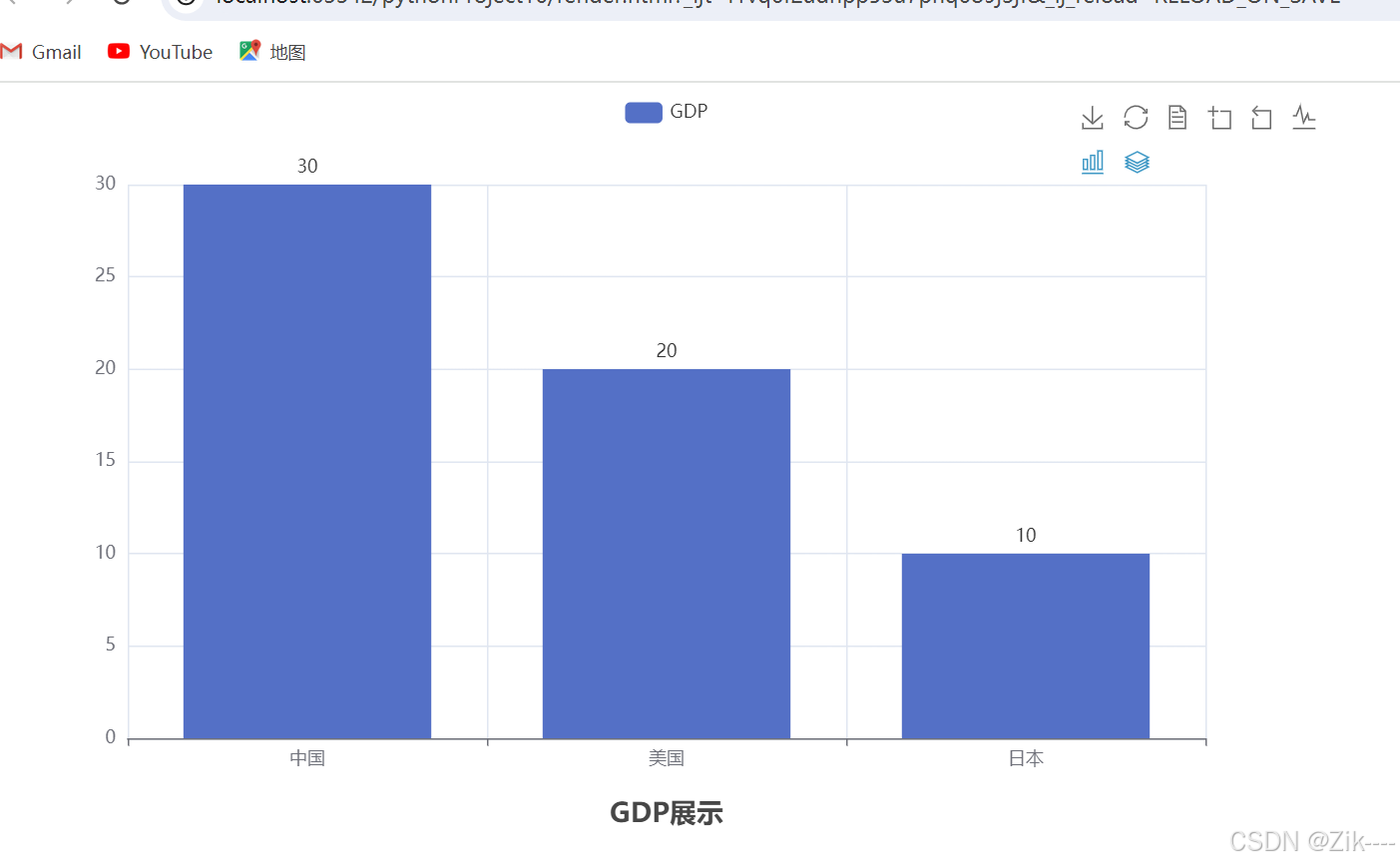
综合案例:
生成2022年美日印新冠疫情确诊人数折线对比图。
使用工具对数据进行查看:
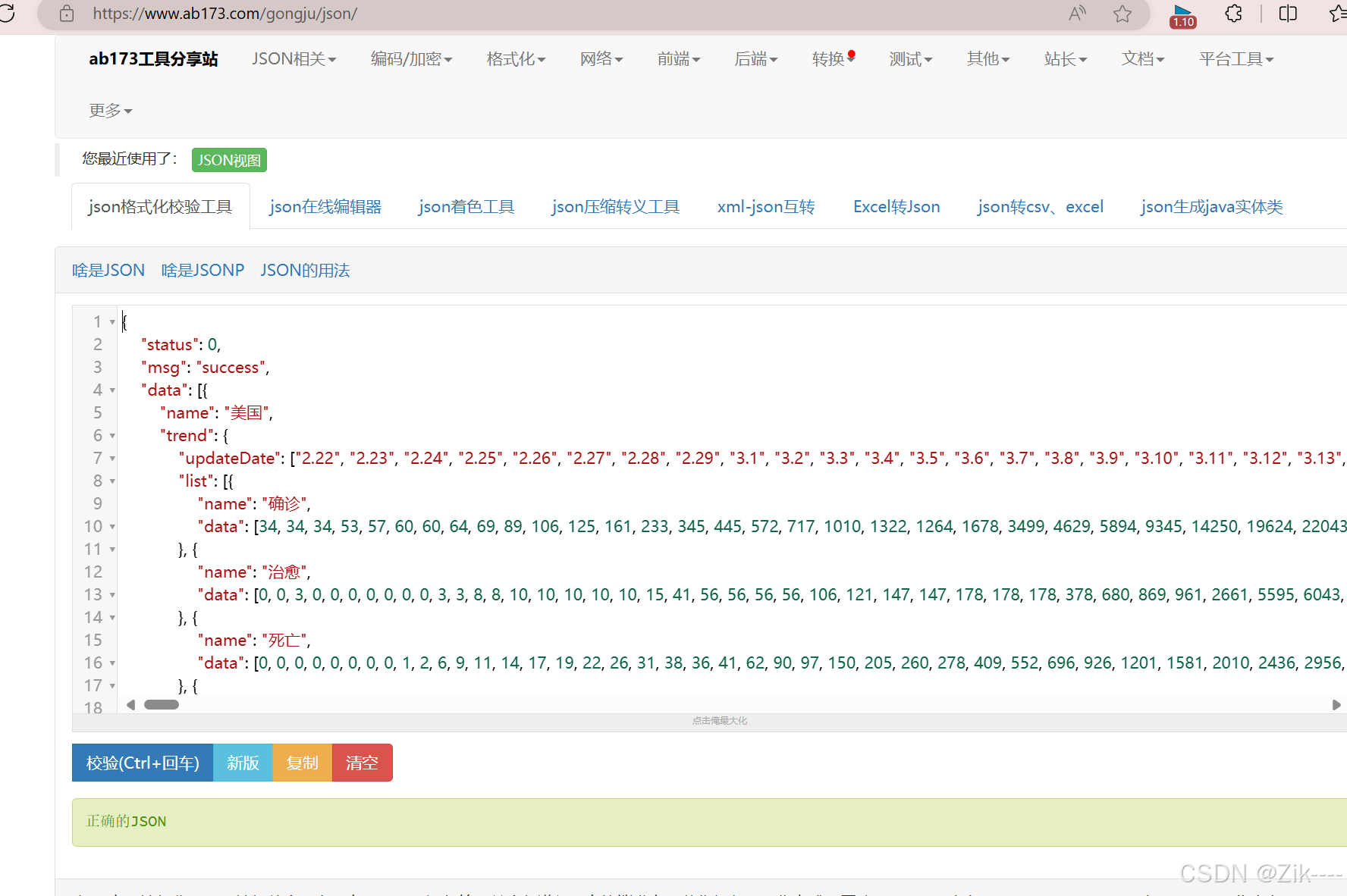
准备好的文件中的json数据如下:
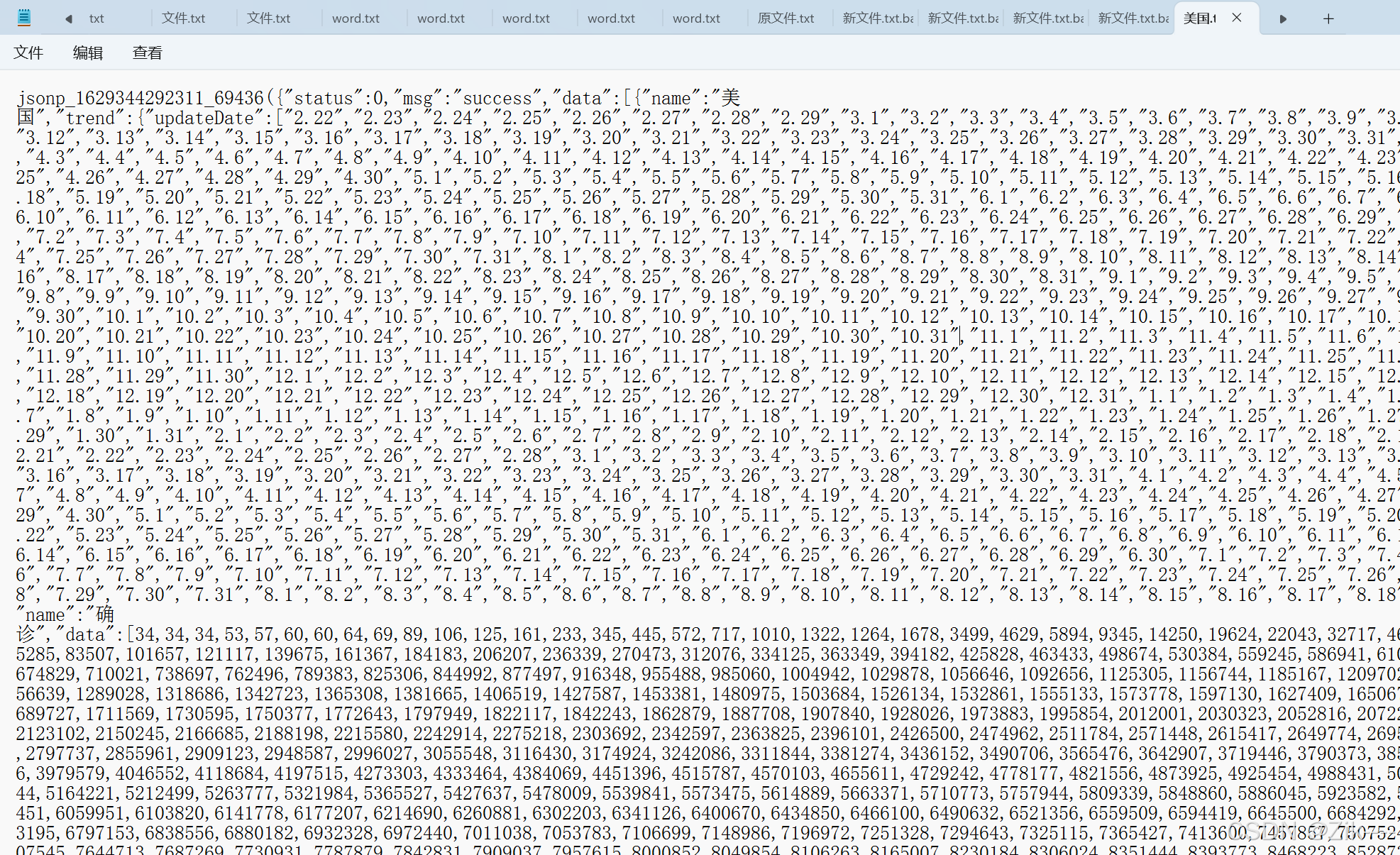
在abc173网站中对该json数据格式化,直观看出层次结构(点击json视图工具)。
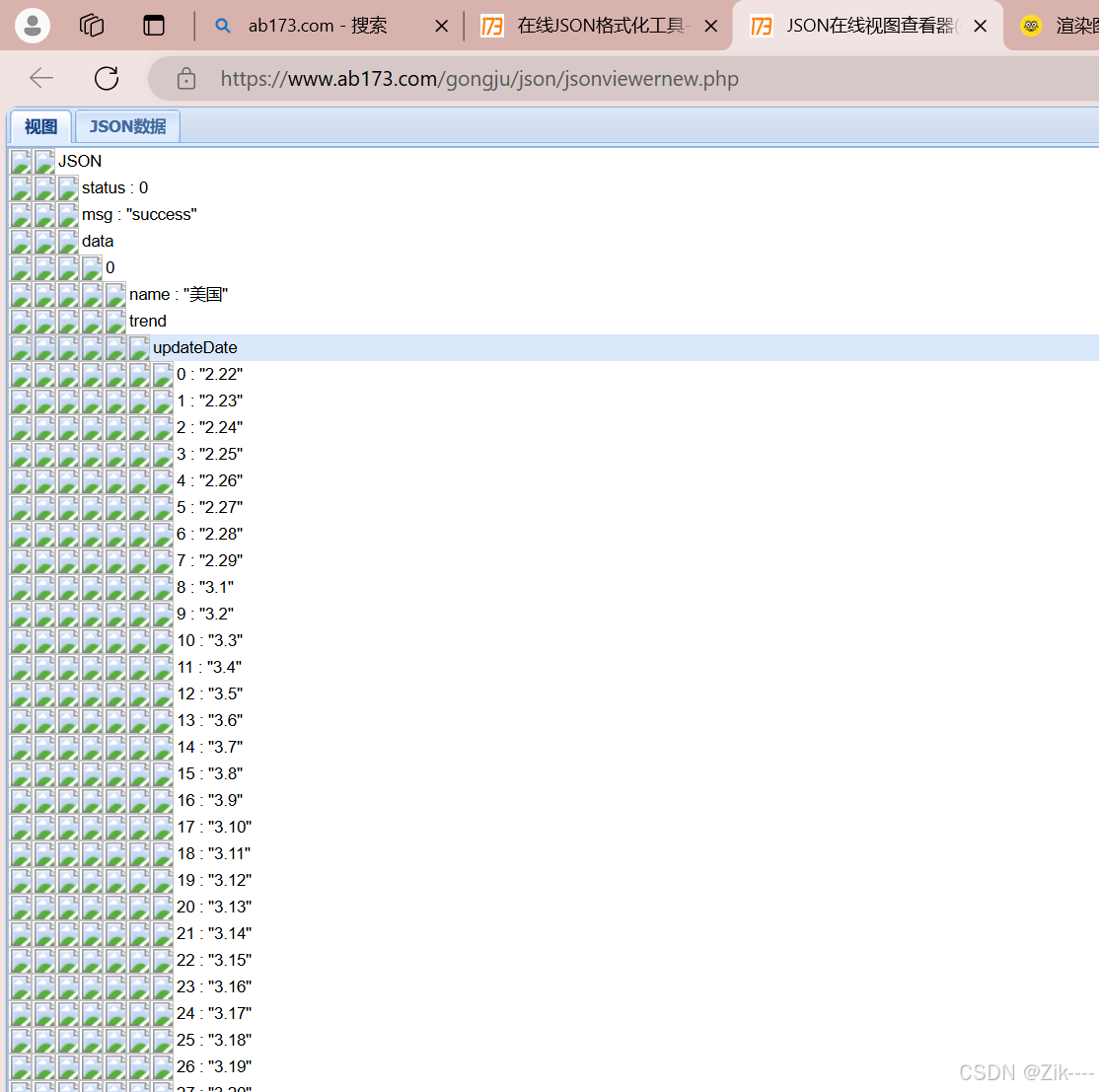
数据处理:
我们需要获取json数据中的2020年的日期作为x轴,该年的确诊人数作为y轴。
美国数据处理的代码演示:
import json
# 读取json文件
# 打开位于 'D:/美国.txt' 的文件,以只读模式('r')打开,并指定编码为 'UTF-8'
f_us = open('D:/美国.txt', 'r', encoding='UTF-8')
# 读取文件内容
us_data = f_us.read()
# 去掉开头和结尾不规范字符
# 将文件内容中的字符串 'jsonp_1629344292311_69436(' 替换为空字符串,去除开头不规范部分
us_data = us_data.replace('jsonp_1629344292311_69436(', '')
# 只取字符串的前部分直到倒数第二个字符,去除结尾不规范部分
us_data = us_data[:-2]
# json转python字典
# 使用 json 模块的 loads 函数将处理后的字符串转换为 Python 字典对象
us_dict = json.loads(us_data)
# 获取trend key
# 从字典中获取 'data' 键对应列表的第一个元素中的 'trend' 键对应的值
us_trend = us_dict['data'][0]['trend']
# 获取日期数据,用于x轴,取2020年
# 获取 'trend' 字典中的 'updateDate' 列表的前 314 个元素,作为 x 轴数据(假设这里对应 2020 年的数据长度为 314)
us_x_data = us_trend['updateDate'][:314]
# 验证 print(us_x_data)
# 获取确诊人数数据,用于y轴,取2020年
# 获取 'trend' 字典中的 'list' 列表的第一个元素中的 'data' 列表的前 314 个元素,作为 y 轴数据(假设这里对应 2020 年的数据长度为 314)
us_y_data = us_trend['list'][0]['data'][:314]
# 验证 print(us_y_data)
同样的对日本和印度的json数据进行相应的处理。
import json
from pyecharts.charts import Line
from pyecharts.options import TitleOpts,LegendOpts,ToolboxOpts# 引入标题
# 读取json文件
f_us =open('D:/美国.txt','r',encoding='UTF-8')
us_data=f_us.read()
f_jp =open('D:/日本.txt','r',encoding='UTF-8')
jp_data=f_jp.read()
f_in =open('D:/印度.txt','r',encoding='UTF-8')
in_data=f_in.read()
# 去掉开头和结尾不规范字符
us_data=us_data.replace('jsonp_1629344292311_69436(','')
us_data=us_data[:-2]
jp_data=jp_data.replace('jsonp_1629350871167_29498(','')
jp_data=jp_data[:-2]
in_data=in_data.replace('jsonp_1629350745930_63180(','')
in_data=in_data[:-2]
# json转python字典
us_dict=json.loads(us_data)
jp_dict=json.loads(jp_data)
in_dict=json.loads(in_data)
# 获取trend key
us_trend=us_dict['data'][0]['trend']
jp_trend=jp_dict['data'][0]['trend']
in_trend=in_dict['data'][0]['trend']
# 获取日期数据,用于x轴,取2020年
us_x_data=us_trend['updateDate'][:314]
jp_x_data=jp_trend['updateDate'][:314]
in_x_data=in_trend['updateDate'][:314]
# 获取确诊人数数据,用于y轴,取2020年
us_y_data=us_trend['list'][0]['data'][:314]
jp_y_data=jp_trend['list'][0]['data'][:314]
in_y_data=in_trend['list'][0]['data'][:314]
# 生成图表
line=Line()
line.add_xaxis(us_x_data) # x轴数据共用
line.add_yaxis("美国确诊人数",us_y_data)
line.add_yaxis("日本确诊人数",jp_y_data)
line.add_yaxis("印度确诊人数",in_y_data)
# 设置标题,注意标题一定在全局属性中设置
line.set_global_opts(
title_opts=TitleOpts(title='2022年美日印新冠疫情确诊人数对比图',pos_left='center',pos_bottom='1%'
))
# 查看图像
line.render()
# 关闭文件
f_us.close()
f_jp.close()
f_in.close()
运行代码得到下图 。
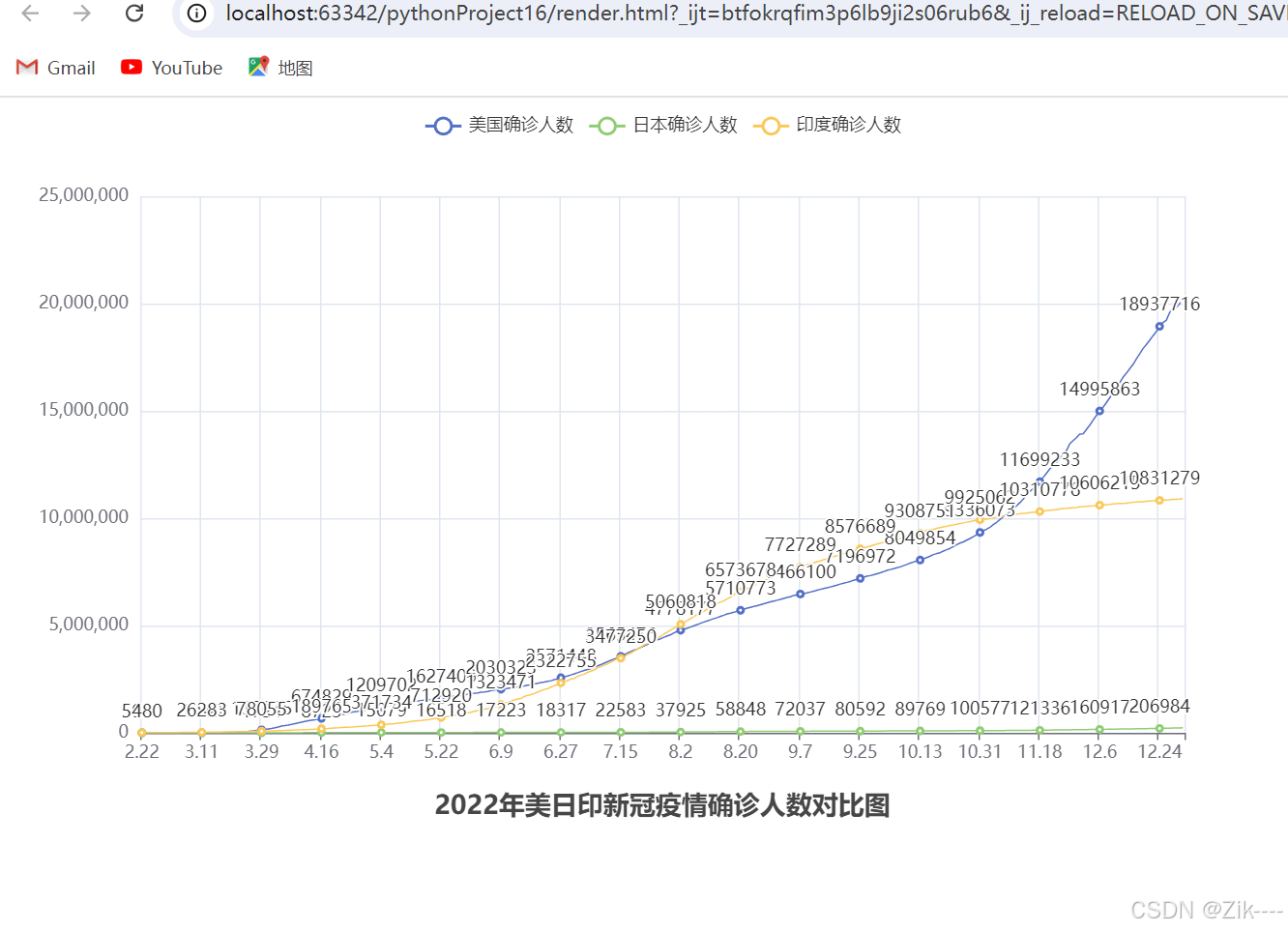
我们可以看到当前图线的数字太多不太美观,通过设置系列属性来去掉混合数字,ctrl+p查看所有功能找到label_opts。
# 修改y轴数据代码
line.add_yaxis("美国确诊人数",us_y_data,label_opts=LabelOpts(is_show=False))
line.add_yaxis("日本确诊人数",jp_y_data,label_opts=LabelOpts(is_show=False))
line.add_yaxis("印度确诊人数",in_y_data,label_opts=LabelOpts(is_show=False))
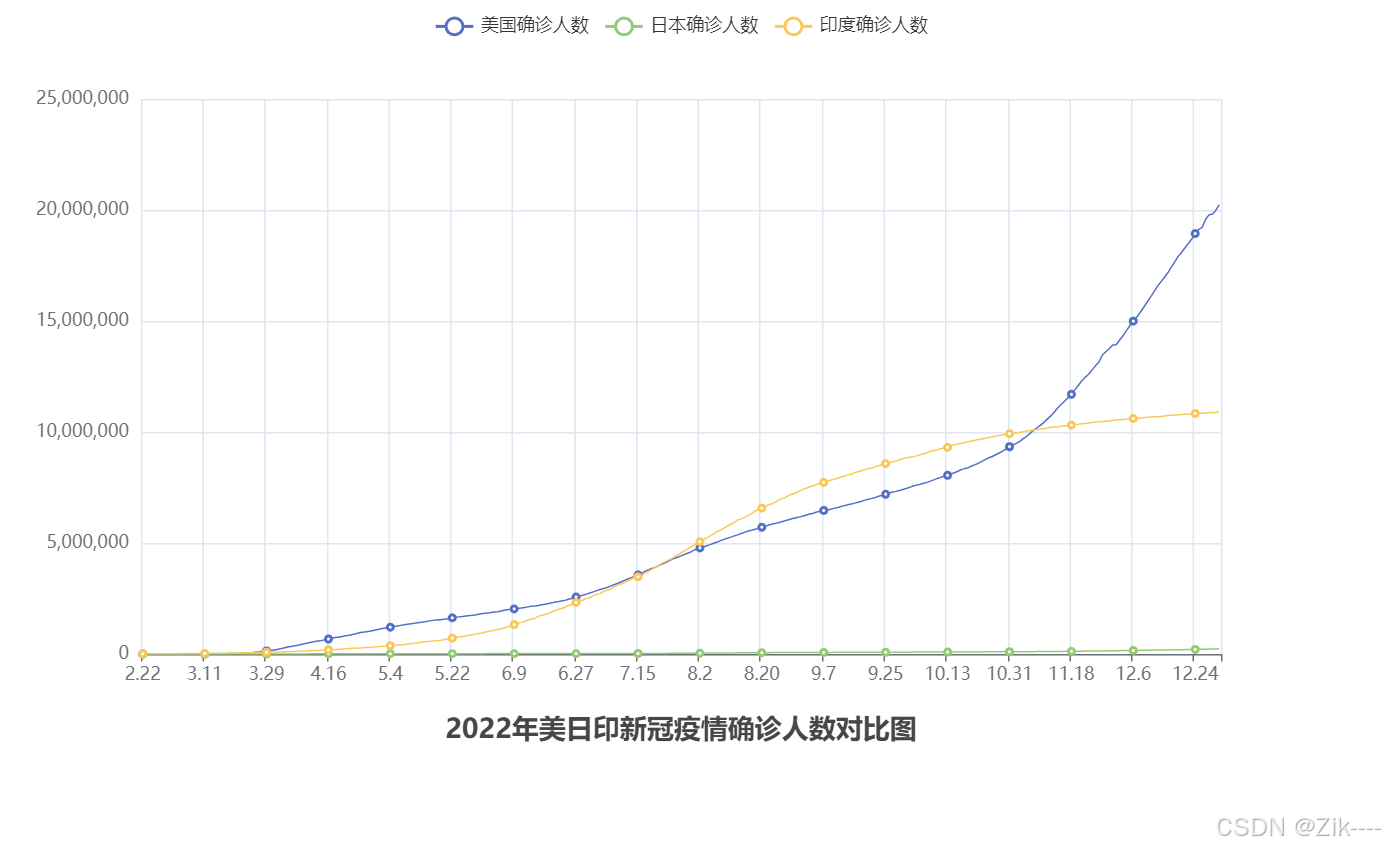
可以看到数字消失了,图表清爽了很多。
以上内容仅是对 JSON 数据格式转化以及 Pyecharts 库使用的简单演示。希望这样的分享能给您带来帮助,也期待能获得您的投币点赞支持,感谢!