NLP 中文拼写检测纠正论文-02-2019-SOTA FASPell Chinese Spell Checke github 源码介绍
拼写纠正系列
NLP 中文拼写检测实现思路
NLP 中文拼写检测纠正算法整理
NLP 英文拼写算法,如果提升 100W 倍的性能?
NLP 中文拼写检测纠正 Paper
java 实现中英文拼写检查和错误纠正?可我只会写 CRUD 啊!
一个提升英文单词拼写检测性能 1000 倍的算法?
单词拼写纠正-03-leetcode edit-distance 72.力扣编辑距离
NLP 开源项目
nlp-hanzi-similar 汉字相似度
word-checker 中英文拼写检测
pinyin 汉字转拼音
opencc4j 繁简体转换
sensitive-word 敏感词
前言
大家好,我是老马。
下面学习整理一些其他优秀小伙伴的设计和开源实现。
SpellChecker
手动实现三个方法的拼写检查demo
手动实现三个方法的拼写检查demo
Peter Norvig版本
Trie 版本
BK-Tree版本
FASPell
https://github.com/iqiyi/FASPell
FASPell
该仓库(根据GNU通用公共许可证v3.0许可) 包含构建当前最佳(到2019年初)中文拼写检查器所需的所有数据和代码,可以以此复现我们的同名论文中的全部实验:
FASPell: A Fast, Adaptable, Simple, Powerful Chinese Spell Checker Based On DAE-Decoder Paradigm LINK
概述
中文拼写检查(CSC)的任务通常仅考虑对中文文本中的替换错误进行检测和纠正。
其他类型的错误(例如删除/插入错误)相对较少。
FASPell是中文拼写检查器,可让您轻松完成对任何一种中文文本(简体中文文本;
繁体中文文本; 人类论文; OCR结果等)的拼写检查,且拥有最先进的性能。
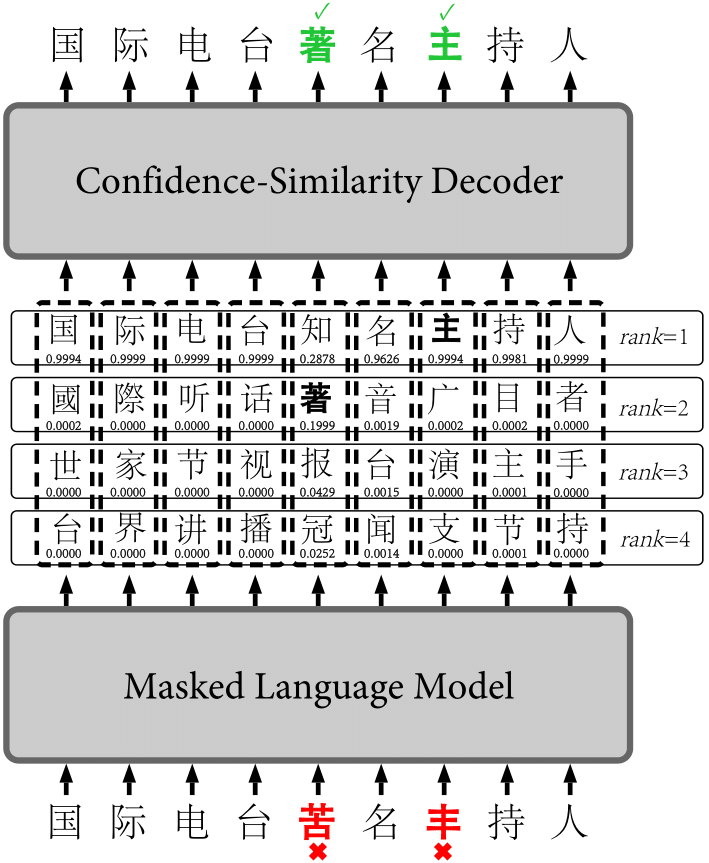
性能
下述表格描述了FASPell在SIGHAN15测试集上的性能。
句子级性能为:
| 精确率 | 召回率 | |
|---|---|---|
| 检错 | 67.6% | 60.0% |
| 纠错 | 66.6% | 59.1% |
字符级性能为:
| 精确率 | 召回率 | |
|---|---|---|
| 检错 | 76.2% | 67.1% |
| 纠错 | 73.5% | 64.8% |
这意味着10个错误检测/纠正中大约7个是正确的,并且可以成功检测/纠正10个错误中的6个。
使用方法
以下是能够指导您构建中文拼写检查器的步骤指南。
依赖
python == 3.6
tensorflow >= 1.7
matplotlib
tqdm
java (仅在使用树编辑距离时需要)
apted.jar (同上,仅在使用树编辑距离时需要)数据准备
在此步骤中,您将在此处下载所有数据。
数据包括拼写检查数据(用于训练和测试)以及用于计算字符相似度的字符特征。
由于FASPell中使用的大多数数据来自其他提供商,所以请注意下载的数据应转换为我们所需的格式。
在仓库中,我们提供了一些示例数据来占位。下载好全部数据后请用相同的文件名覆盖它们。
完成此步骤后,如果您有兴趣,则可以使用以下脚本来计算字符相似度:
$ python char_sim.py 午 牛 年 千请注意,FASPell仅采用字符串编辑距离进行计算 相似。 如果您对使用树编辑距离计算相似度感兴趣 ,您需要下载(从 这里)并编译一个 树编辑距离可执行文件“ apted.jar”到主目录,然后运行:
$ python char_sim.py 午 牛 年 千 -t训练
我们强烈建议您在实施此步骤之前阅读我们的论文。
共有三个训练步骤(按顺序)。 点击链接
获得他们的详细信息:
预训练掩码语言模型:请参阅此处
微调训练掩码语言模型:请参阅此处
训练CSD过滤器:请参见此处
运行拼写检查器
检查您的目录结构是否如下:
FASPell/
- bert_modified/
- create_data.py
- create_tf_record.py
- modeling.py
- tokenization.py
- data/
- char_meta.txt
- model/
- fine-tuned/
- model.ckpt-10000.data-00000-of-00001
- model.ckpt-10000.index
- model.ckpt-10000.meta
- pre-trained/
- bert_config.json
- bert_model.ckpt.data-00000-of-00001
- bert_model.ckpt.index
- bert_model.ckpt.meta
- vocab.txt
- plots/
...
- char_sim.py
- faspell.py
- faspell_configs.json
- masked_lm.py
- plot.py现在,您应该可以使用以下命令对中文句子进行拼写检查:
$ python faspell.py 扫吗关注么众号 受奇艺全网首播您还可以检查文件中的句子(每行一个句子):
$ python faspell.py -m f -f /path/to/your/file如要在测试集上测试拼写检查器,请将faspell_configs.json中的"testing_set"设置为测试集的路径并运行:
$ python faspell.py -m e您可以将faspell_configs.json中的"round"设置为不同的值,并运行上述命令以找到最佳的回合数。
数据
中文拼写检查数据
人类生成的数据:
- SIGHAN-2013 shared task on CSC: LINK
- SIGHAN-2014 shared task on CSC: LINK
- SIGHAN-2015 shared task on CSC: LINK
机器生成的数据:
我们论文中使用的OCR结果:
- Tst_ocr: LINK
- Trn_ocr: LINK
要使用我们的代码,拼写检查数据的格式应按照以下例子:
错误字数 错误句子 正确句子
0 你好!我是張愛文。 你好!我是張愛文。
1 下個星期,我跟我朋唷打算去法國玩兒。 下個星期,我跟我朋友打算去法國玩兒。
0 我聽說,你找到新工作,我很高興。 我聽說,你找到新工作,我很高興。
1 對不氣,最近我很忙,所以我不會去妳的。 對不起,最近我很忙,所以我不會去妳的。
1 真麻煩你了。希望你們好好的跳無。 真麻煩你了。希望你們好好的跳舞。
3 我以前想要高訴你,可是我忘了。我真戶禿。 我以前想要告訴你,可是我忘了。我真糊塗。中文字符特征
我们使用来自两个开放数据库提供的特征。 使用前请检查其许可证。
| 数据库名 | 数据链接 | 使用的文件 | |
|---|---|---|---|
| 字形特征※ | 漢字データベースプロジェクト(汉字数据库项目) | LINK | ids.txt |
| 字音特征 | Unihan Database | LINK | Unihan_Readings.txt |
※ 请注意,原始 ids.txt 本身不提供笔划级别的IDS(出于压缩目的)。 但是,您可以使用树递归(从具有笔画级IDS的简单字符的IDS开始)来为所有字符自己生成笔画级IDS。
可以与我们的代码一起使用的特征文件(char_meta.txt)应该具有格式如下:
unicode编码 字符 CJKV各语言发音 笔划级别的IDS
U+4EBA 人 ren2;jan4;IN;JIN,NIN;nhân ⿰丿㇏
U+571F 土 du4,tu3,cha3,tu2;tou2;TWU,THO;DO,TO;thổ ⿱⿻一丨一
U+7531 由 you2,yao1;jau4;YU;YUU,YUI,YU;do ⿻⿰丨𠃌⿱⿻一丨一
U+9A6C 马 ma3;maa5;null;null;null ⿹⿱𠃍㇉一
U+99AC 馬 ma3;maa5;MA;MA,BA,ME;mã ⿹⿱⿻⿱一⿱一一丨㇉灬其中:
- CJKV各语言发音的字符串遵循格式:
MC;CC;K;JO;V; - 当一个语言中的字符是多音字时,可能的发音用
,分隔; - 当一个字符不存在某个语言的发音时,用
null来做占位符。
小结
希望本文对你有所帮助,如果喜欢,欢迎点赞收藏转发一波。
我是老马,期待与你的下次相遇。