【机器人】SceneGrasp 同时支持3D物体重建、6D位姿估计、抓取点估计
本文分享SceneGrasp,它来自IROS2023,同时支持物体分类、3D物体重建、6D位姿估计、抓取点估计。
它是一种快速、高效且同时处理多个任务的方法,能够使机器人更好地理解和操作其环境。
同时处理多个任务,实现任务之间共享信息,而且速度达到30 FPS。
论文地址:Real-time Simultaneous Multi-Object 3D Shape Reconstruction, 6DoF Pose Estimation and Dense Grasp Prediction
开源地址:https://github.com/SamsungLabs/SceneGrasp
一、整体框架
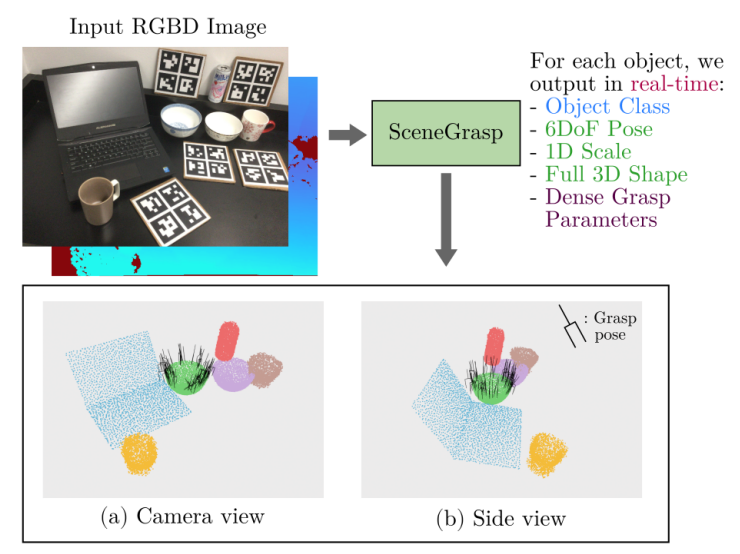
从单个RGB-D图像中,同时感知多个物体,包括物体类别、6D位姿、3D形状和抓取点信息,速度能达到30帧。
SceneGrasp的整体框架,如下图所示:
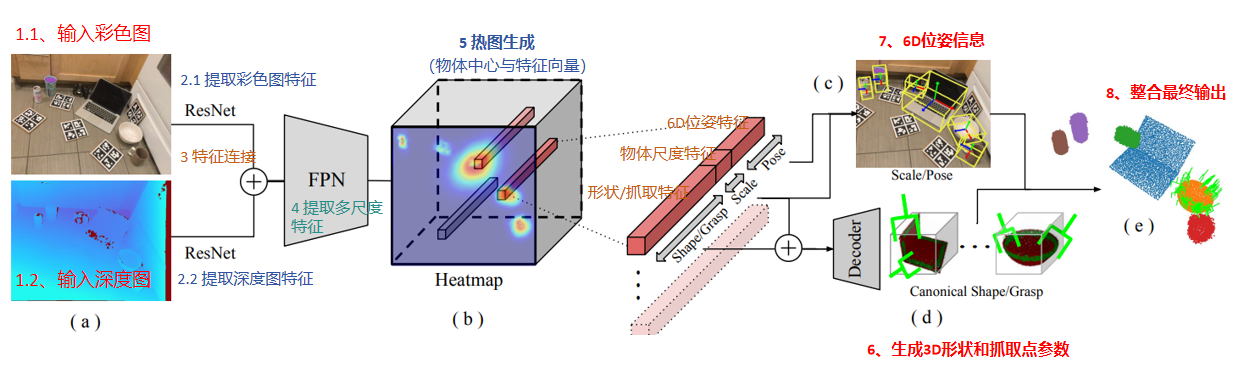
分析一下思路流程:
- 输入包括:彩色图、深度图像
- 分别用ResNet对彩色图像进行特征提取,以及对深度图提取特征
- 将彩色特征和深度特征进行整合连接
- 整合后的特征,送入FPN进行多尺度特征提取,以适应不同大小的物体检测
- 获取多尺度的特征,生成热图,热力图中每一点,表示物体中心位置与特正向量(6D位姿特征、物体尺度特征、形状/抓取特征)
- 获取物体尺度特征、和形状/抓取特征,送入ScaleShapeGrasp-AE,生成物体的3D形状、和抓取参数
- 获取物体尺度特征、和6D位姿特征,进一步生成6D位姿信息
- 整合最终输出,得到6D位姿估计信息、3D物体形状、抓取点估计信息
二、 SceneGrasp训练方法
从单个RGB-D图像中,同时感知多个物体的:类别、6D位姿、完整3D形状和抓取参数,所有这些都在实时进行,能达到30帧。
为了实现这一目标,采用了一种两步训练方法,涉及两个主要网络:ScaleShapeGrasp-AE和SceneGrasp-Net。
第一步:ScaleShapeGrasp-AE
这个自编码器的目标是学习物体形状和尺度依赖的抓取参数的联合潜在空间。
它处理单位尺度和规范方向的点云,学习重建输入形状以及每个点的密集抓取参数。
-
输入: 单位尺度、规范方向的点云,以及物体的尺度。
-
输出: 重建的点云和每个点的抓取参数,包括抓取成功概率、接近方向、基线方向和抓取宽度。
第二步:SceneGrasp-Net(主要的模型结构)
这个网络的目标是从RGB-D图像中预测物体的类别、位姿、尺度和形状-抓取嵌入。它基于CenterSnap模型,该模型通过热图预测来检测物体。
-
输入: RGB-D图像。
-
输出: 物体的类别、6DoF位姿、1D尺度和形状-抓取嵌入特征。
三、基于尺度的形状-抓取自编码器(ScaleShapeGrasp-AE)
这是SceneGrasp方法的关键组件之一,负责学习物体的形状和抓取参数的联合表示。
首先,目标是学习一个低维潜在空间,该空间能够捕捉物体在单位标准空间中的形状,以及基于物体尺度的抓取分布。
简而言之,它需要处理不同尺度的物体,并预测每个物体点的抓取可行性。
3.1)输入与输出
-
输入:
- 点云(N×3): 表示物体表面的3D点,这些点在单位尺度和标准方向下。
- 尺度(s∈R): Scale表示物体相对于标准尺度的缩放因子。
-
输出:
- 重建的点云(P^): 自编码器重建的输入点云。
-
每个点的抓取参数:
- 抓取成功(gs): 每个点被成功抓取的概率。
- 接近方向(a): 抓取器接近物体的方向。
- 基线方向(b): 与接近方向垂直的方向,定义抓取器的对齐方式。
- 抓取宽度(gw): 抓取器需要张开的宽度以抓住该点。
3.2)自编码器结构
下面的图展示了ScaleShapeGrasp-AE的工作原理,及其对尺度变化的处理
三个主要部分:(a) 编码器-解码器架构,(b) 每点抓取表示,以及 (c) Scale尺度对抓取成功预测的影响。
每个部分都揭示了自编码器如何处理形状和抓取参数,以及尺度如何影响抓取可行性。
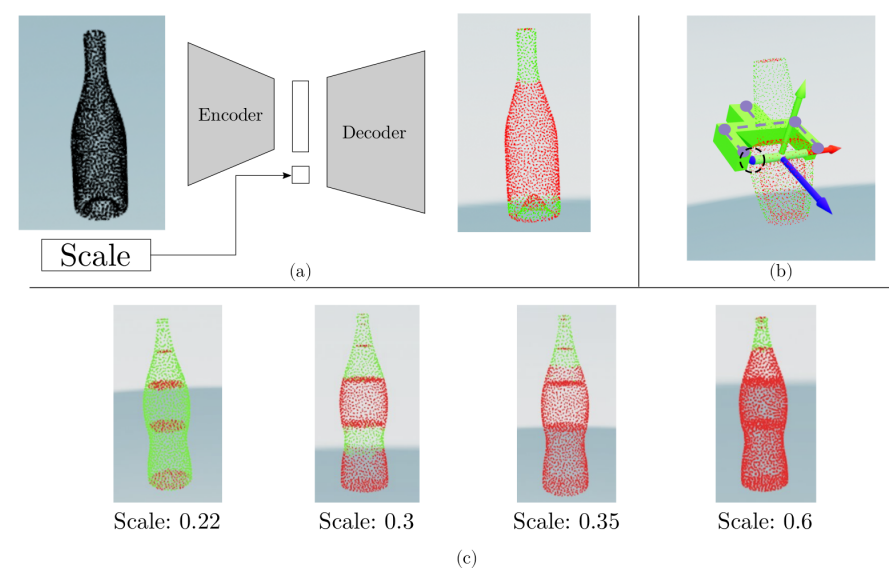
在(b) 每点抓取表示,瓶子的3D重建模型上覆盖了颜色编码的点,表示每个点的抓取可行性。
绿色点: 表示抓取成功的高概率区域。红色点: 表示抓取成功的低概率或不可行区域。
方向箭头: 蓝色和绿色的箭头表示接近方向(a)和基线方向(b),提供关于如何最优抓取每个可行点的信息。
在(c) 尺度对抓取成功预测的影响,图像展示了瓶子在不同尺度(0.22, 0.3, 0.35, 0.6)下的抓取可行性预测,同时保持形状不变。
随着尺度的增加,较宽的区域逐渐变为不可抓取(红色),因为它们超过了抓取器的最大宽度。
自编码器能够根据物体的尺度Scale,调整抓取策略。
下面分析一下自编码器结构
编码器(E):
-
基于PointNet的架构,能够处理无序的点云数据。
-
将点云映射到一个128维的嵌入向量,捕捉形状的潜在表示。
嵌入向量增强:
- 将物体的尺度s附加到嵌入向量上,形成一个129维的向量,使自编码器能够学习尺度依赖的抓取参数。
解码器(D):
- 一系列全连接层,将增强的嵌入向量上采样到N×(3+17)的维度。每个点的向量被拆分为:
-
3D坐标: 重建的点云位置。
-
抓取参数:
-
gs: 通过sigmoid函数预测。
-
a和b: 通过Gram-Schmidt过程从两个向量z1和z2派生。
-
gw: 通过softmax层预测,表示为一个独热向量,表示离散的抓取宽度类别。
-
-
3.3)损失函数
训练自编码器是一个细致的过程,涉及形状和抓取参数的联合学习。

-
抓取损失的详细信息:
-
Lgs: 二元交叉熵损失,用于预测的抓取成功概率。
-
Lgw: 二元交叉熵损失,用于预测的抓取宽度。
-
L6DoF: 预测的抓取关键点位置与真实关键点位置之间的距离损失。
-
3.4)ScaleShapeGrasp-AE关键创新点
-
联合形状和抓取学习: 通过在单个自编码器中联合建模形状和抓取参数,该方法能够学习形状几何和抓取可行性的相互依赖关系。
-
尺度依赖的抓取参数: 通过将尺度附加到嵌入向量上,自编码器能够学习如何根据物体的大小调整抓取策略,这对于不同尺度物体的现实场景至关重要。
-
基于PointNet的编码器: 利用PointNet的无序点云处理能力,确保自编码器对输入点云的顺序不敏感,提高鲁棒性。
四、实验与测试
数据集
-
NOCS数据集: 这是一个标准的RGB-D数据集,包含来自六个类别的物体:瓶子、碗、罐子、杯子、笔记本电脑和相机。该数据集提供了每个物体实例的6DoF位姿,并且作者使用[27]中的工具为每个物体实例标注了密集的抓取标签。
-
训练和测试集: 他们遵循标准的训练-测试拆分,使用CAMERA-train集进行训练,在REAL-train集上微调,并在REAL-test集上进行评估。
备注:抓取标签标注是参考这篇论文的 [27] Simultaneous object reconstruction and grasp prediction using a camera-centric object shell representation
评估指标
-
1、3D物体检测和6D位姿估计:
-
平均精度(AP): 在不同的IoU(交并比)阈值下计算。
-
平均精度(AP): 对于位姿估计,使用旋转误差小于n度和位移误差小于m厘米的阈值。
-
-
2、3D形状重建:
-
双向Chamfer距离: 衡量重建点云与真实点云之间的距离。
-
-
3、抓取估计:
-
抓取成功率: 成功抓取尝试的比例。
-
覆盖率: 预测的抓取覆盖真实抓取标签的比例。
-
基线方法
-
NOCS: 使用Mask R-CNN架构预测NOCS图,并结合深度信息预测位姿和尺寸。
-
DeformNet: 预测每个物体的2D边界框,并变形平均形状以获得最终的形状重建。
-
CenterSnap: 在热图的峰值处检测物体,并使用形状解码器预测形状。
下图展示SceneGrasp方法在NOCS-Real测试集上性能, 图表分为三个部分:3D IoU、旋转误差和位移误差
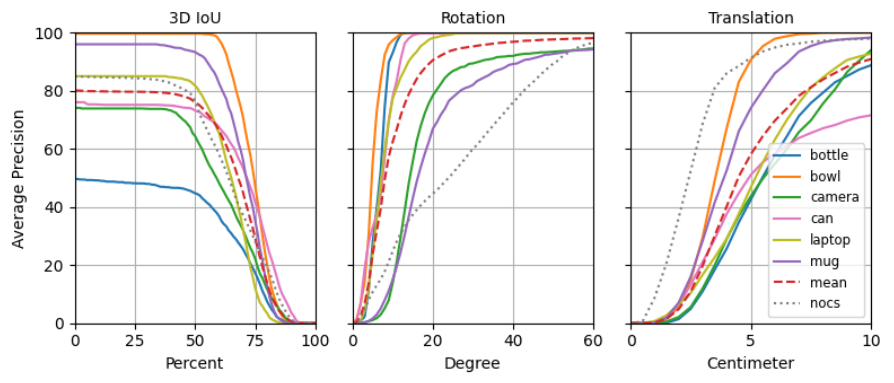
每个图表都显示了不同百分比阈值下的平均精度(AP),并按物体类别进行了细分。
-
3D IoU: SceneGrasp在所有IoU阈值下都优于NOCS,特别是在较高的IoU要求下,这表明其位姿估计更准确。
-
旋转误差: SceneGrasp在旋转位姿估计上显著优于NOCS,特别是在较小的旋转误差范围内。
-
位移误差: 虽然SceneGrasp在位移估计上总体更准确,但与NOCS的差距不如旋转位姿估计那么显著,且在较大的位移误差范围内表现相似。
此外,图表显示SceneGrasp在80%的测试案例中位移误差约为3厘米,这对于大多数机器人操作任务来说是可以接受的。
下面的表格,展示了不同方法在NOCS数据集上的3D形状重建性能
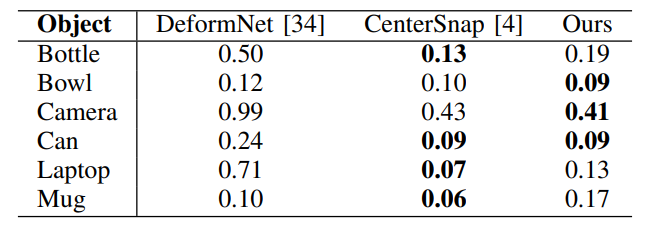
- 按物体类别显示了它们的Chamfer距离。Chamfer距离越低,表示重建的形状越准确。
- Chamfer距离的定义:它是两个点云之间的平均最近邻距离,用于衡量重建形状与真实形状之间的相似度。
下面的表格,展示了不同覆盖率下的抓取成功率

- 覆盖率指的是预测的抓取点,覆盖真实抓取标签的比例
- 成功率则表示在这些覆盖率下成功抓取的比率
- 从10%到50%覆盖率下,成功率分别为92.3%、89.7%、87.3%、84.2%和78.3%。
- 随着覆盖率的增加,成功率逐渐下降。为更高的覆盖率,意味着更多的抓取点被采样,这些抓取点可能置信度较低,从而导致整体成功率下降
- 置信度阈值: 模型根据置信度对抓取点进行排序,选择最自信的抓取点以达到所需的覆盖率。高置信度抓取点更可能是成功的,而低置信度抓取点则可能失败。
五、看看效果
下面是在仿真环境中,3D物体重建、抓取点估计的效果

下面机械臂抓取的效果:

论文复现,参考我这篇博客:
【机器人】复现SceneGrasp 同时支持多目标 3D物体重建、6DoF位姿估计、抓取预测-CSDN博客
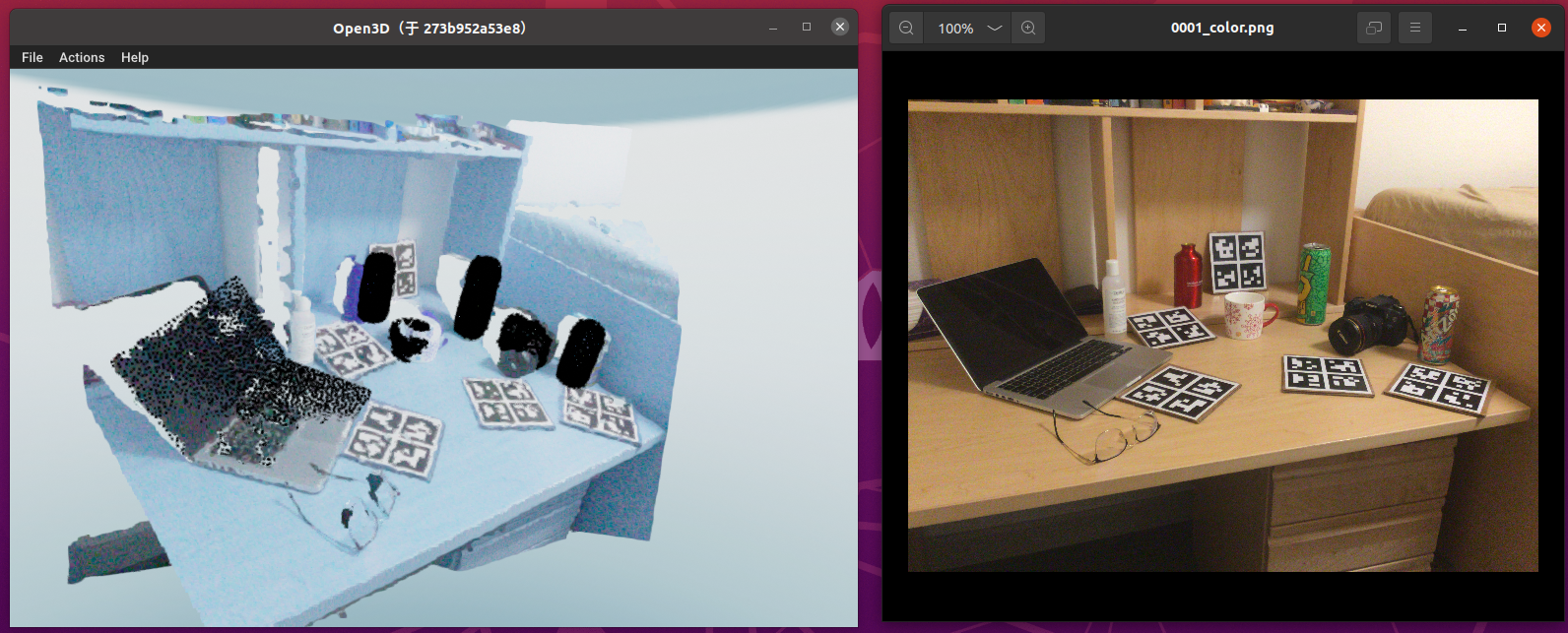
看看3D点云的效果(左侧),右侧是彩色图
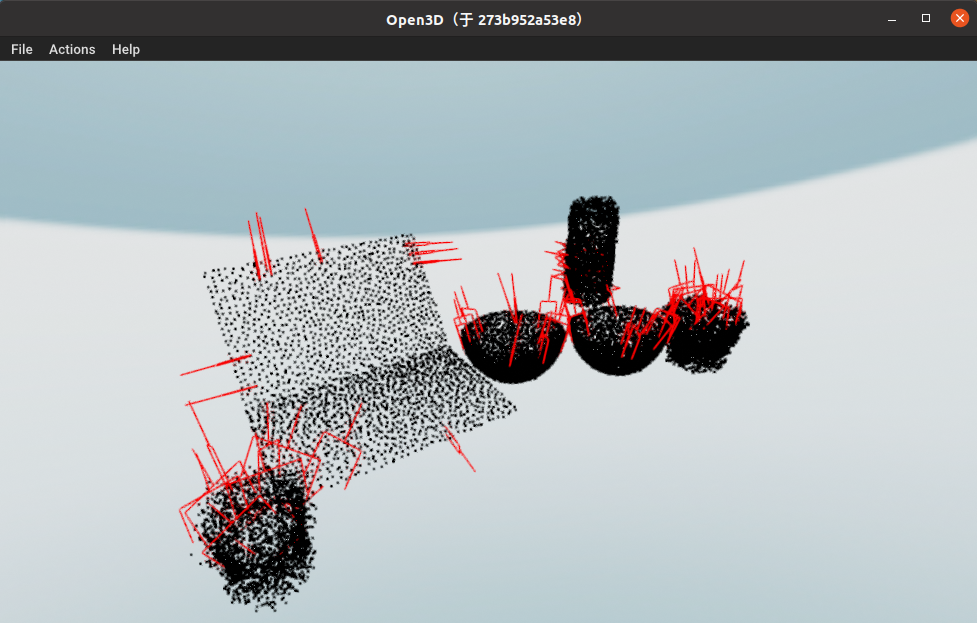
再看看物体重建的效果、抓取估计(红色框)
相关文章推荐:
【机器人】Graspness 端到端抓取点估计 | 环境搭建 | 模型推理测试_graspness使用-CSDN博客
【机器人】Graspness 端到端 抓取点估计 | 论文解读_graspness discovery in clutters for fast and accur-CSDN博客
分享完成~