Linux内核链表学习录
前沿
链表是一种比较经典的数据结构,特点是存储结构链式的,内存中结构式非连续存储,通过指针进行连接,并且可进行扩展,动态分配内存,能充分的利用存储空间(存储不连续特性)。该特性有点通常适用于频繁插入与删除的场景。但是在随机访问效率较低,需要遍历,另外内存开销也大点,因其每个元素节点都需要额外的指针空间。
一.通常链表有单向&双向链表
单向链表:
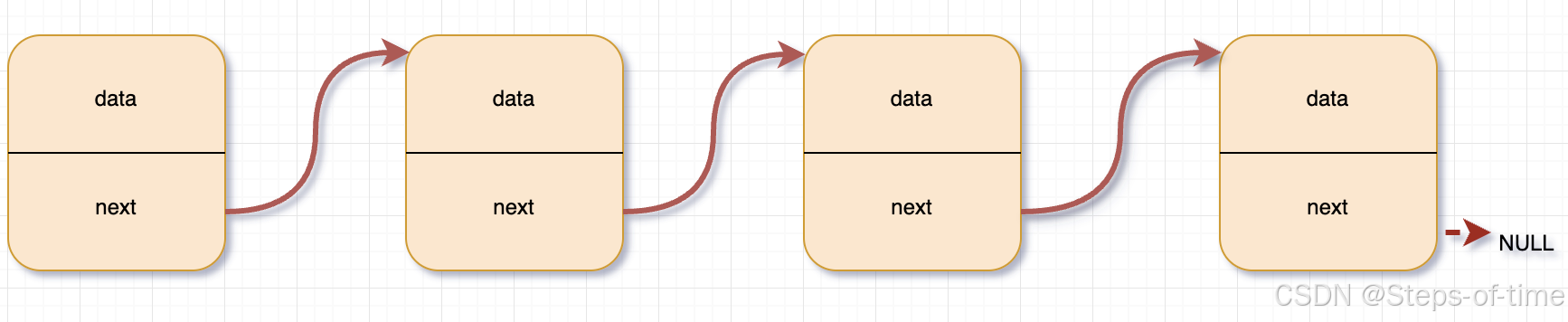
双向链表:
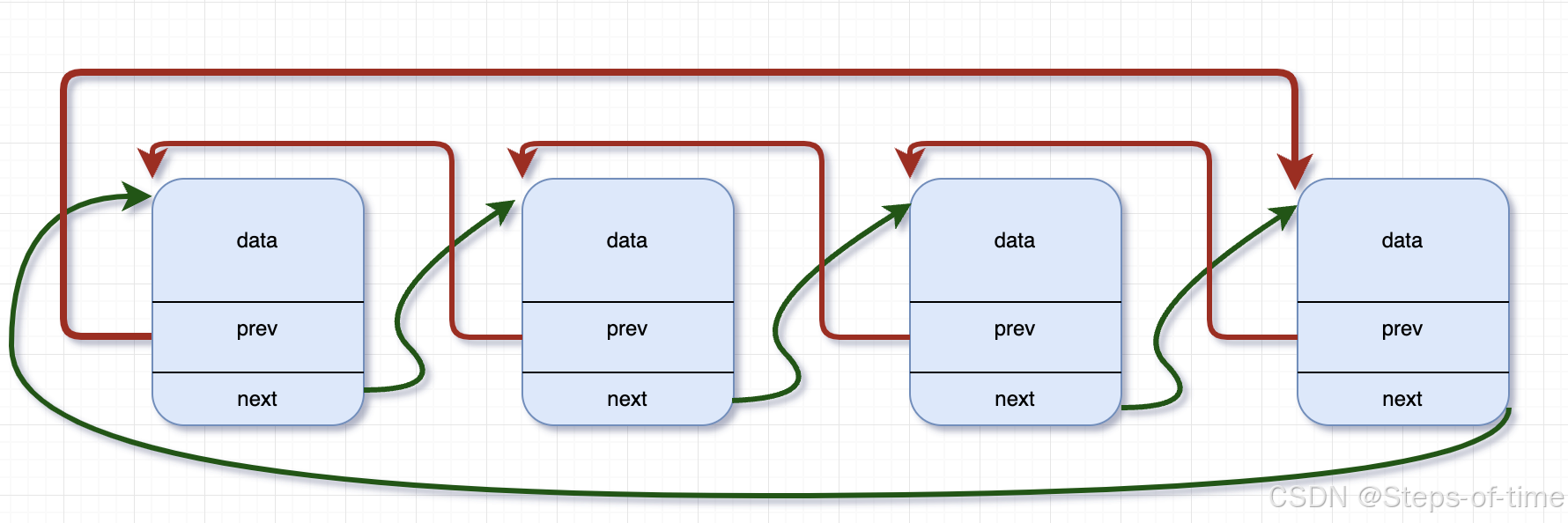
上述的两种形式的链表,都有一个共同特点,数据域跟指针域都在同一个结构体中。也是通常学习使用的方式,但是该种方式有种局限性,那就是所有的节点结构类型都是一样的。通常的结构定义写法如下:
// 单链表
struct My_Data {
int a;
struct My_Data *next;
};
// 双向链表
struct My_Data_Double {
int a;
struct My_Data_Double *prev,*next;
};上述代码中的指针类型都是结构体本身结构类型的指针类型,所有使用过程prev跟next存储的节点指针地址都是整个结构体的所在内存的首地址。使用举例:
单向链表:
// add My_Data Node
void addNode(struct My_Data **head,struct My_Data *node,struct My_Data **tail)
{
#if 0
// 头插法
if(!(*head)){
*head = node;
}else{
node->next = *head;
*head = node;
}
#else
// 尾插法
if(!(*head))
{
*tail = *head = node;
}else{
if(tail)
*tail = (*tail)->next = node;
}
#endif
}上述代码采用了单向链表的创建头插法&尾插法&删除某个节点方式举例使用。双向链表这里不做举例了,请见后面内核双向链表实现方法,详细请见第二部分内容。
二.Linux内核双向循环链表。
a.内核双向链表与普通链表差异性,
用户数据跟链表结构指针不是同一种类型,链表节点是一个独立的结构,内部仅有两个成员prev跟next,无任何其他数据成员,结构如下:
链表结构:
struct list_head {
struct list_head *next, *prev;
};定义一个头部管理结构:
struct list_head head;链表图示:
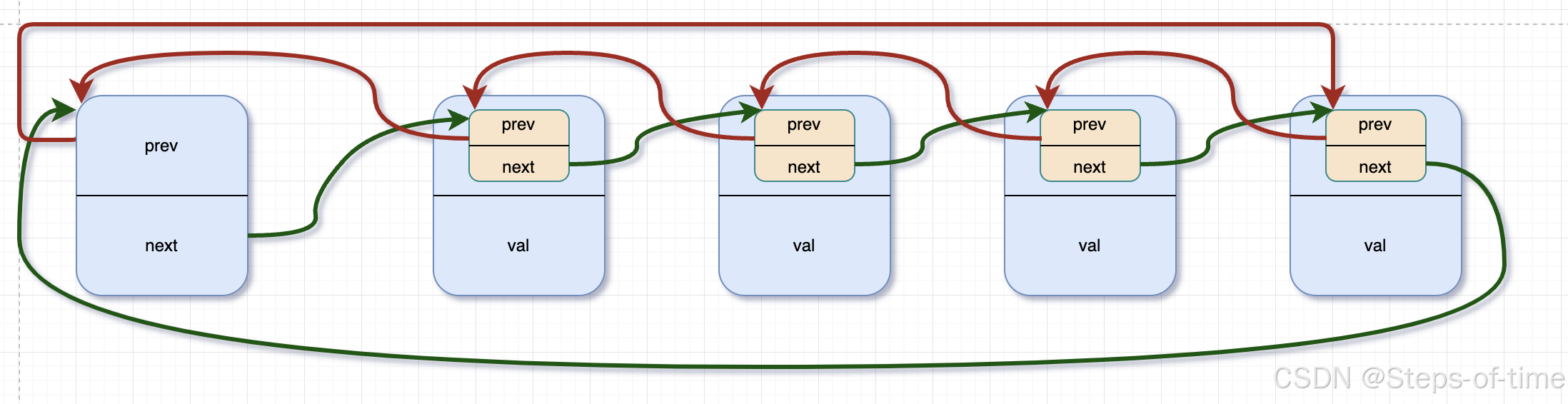
通过list_head将所有的结构点链接串起来,就形成一个完整的双向链表。那么新问题又来了,既然链表结构之间只有指针成员,那如果要访问自定义的数据成员信息,该如何访问呢?继续往下看。在Linux内核中实现了经典的双向循环链表,且有两个经典的宏,offsetof & container_of的实现,详情见下。
b.两个经典的宏定义实现
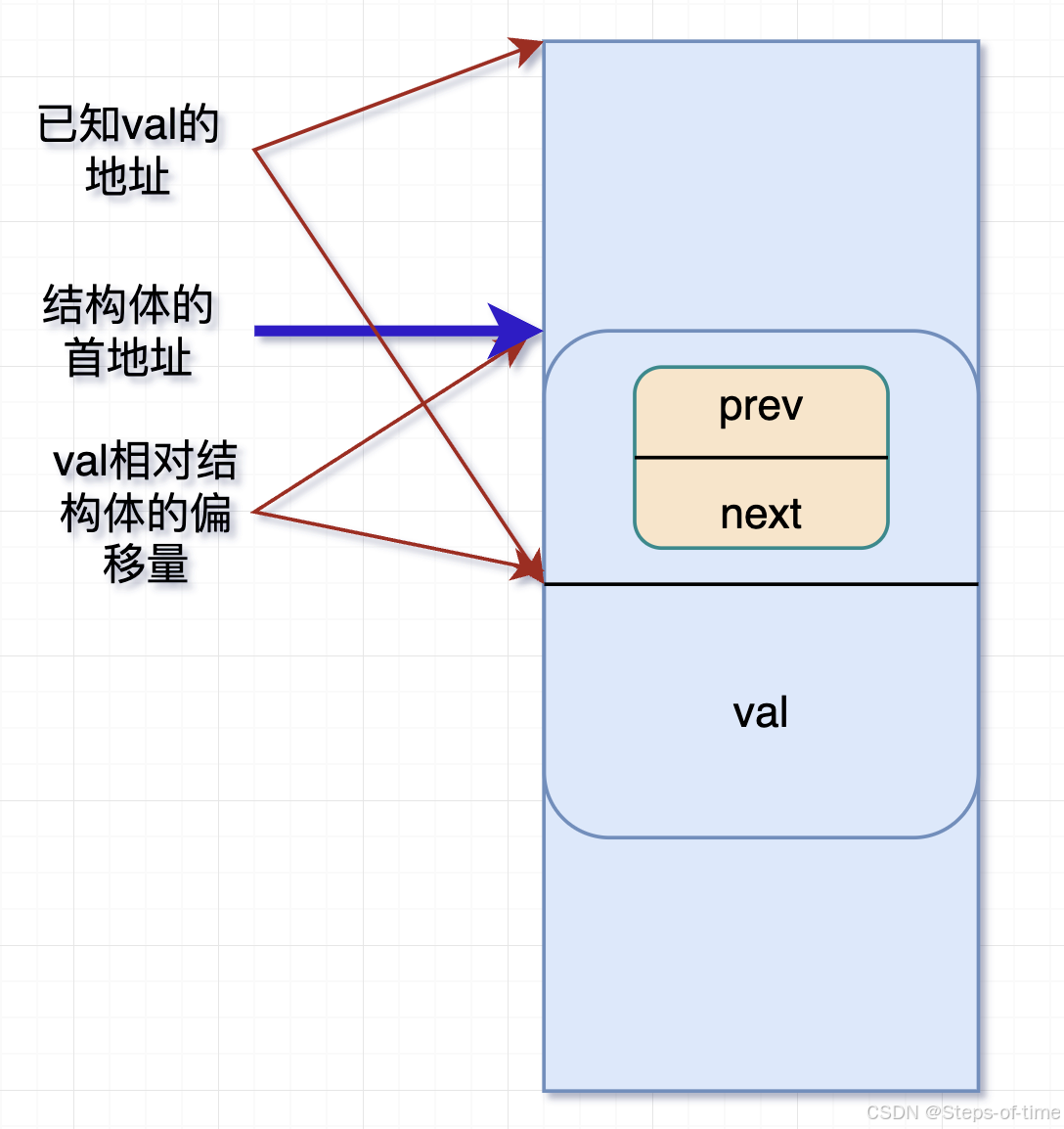
1.offsetof宏定义
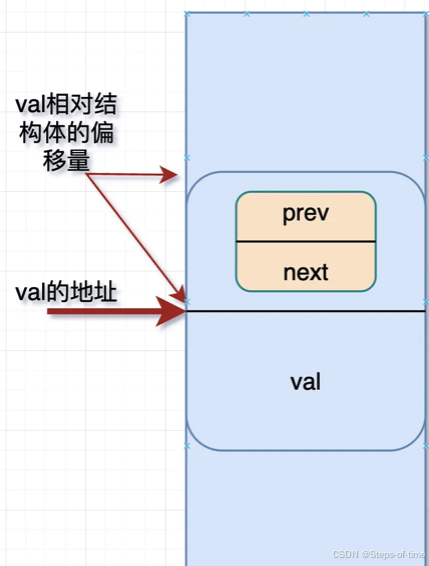
#define offsetof(TYPE, MEMBER) ((size_t) &((TYPE *)0)->MEMBER)该宏定义的功能是通过类型TYPE以及成员MEMBER,求解出成员MEMBER在类型TYPE结构中的地址偏移量。(TYPE *)0中,表示将0值强转成TYPE类型的地址,通过->MEMBER指向对应的成员,再通过取地址符&求解其MEMBER成员地址偏移量。虽然同0地址开始,强转成TYPE结构了,尽管结构体可能实际不从0开始,但是成员member相对结构的偏移量是一致的。这就是offsetof的妙用点。
例如:
size_t offset = offsetof(struct my_data,val);图解:
2.container_of宏定义
/**
* container_of - cast a member of a structure out to the containing structure
* @ptr: the pointer to the member.
* @type: the type of the container struct this is embedded in.
* @member: the name of the member within the struct.
*
*/
#define container_of(ptr, type, member) ({ \
const typeof(((type *)0)->member)*__mptr = (ptr); \
(type *)((char *)__mptr - offsetof(type, member)); })上述宏定义结构解释:
ptr:结构中某个成员的地址
type:具体结构类型
member:具体结构的成员名称
首先通过将ptr的地址赋予__mptr,将其转化成type结构类型的member成员类型。(typeof是内制关键字,获取变量具体类型,typeof(((type *)0)->member)获取member类型),将其转化为char*单位的字节,再通过减去member在结构type中偏移量,从而得到整个结构type的首地址。之后就能利用指针变量通过->访问type结构中的成员数据。
例如:通过m的成员val求结构体m的首地址
struct my_data m;
struct my_data *ptr = container_of(&m.val,(struct my_data*),list);图解:
c.linux内核提供双向链表的实现
通过a,b两个前提概述描述结论,都是为后续内核提供的相关接口实现作准备。好了,直接来看内核如何针对双向链表的实现&提供的相关宏和接口使用。
1.链表初始化
宏初始化:
#define LIST_HEAD_INIT(name) { &(name), &(name) }
#define LIST_HEAD(name) \
struct list_head name = LIST_HEAD_INIT(name)内核使用的双向链表的头节点并无任何数据域,仅含有两个指针成员。初始化的节点的prev跟next都指向了自身节点。
接口初始化:
static inline void INIT_LIST_HEAD(struct list_head *list)
{
list->next = list;
list->prev = list;
}图示:
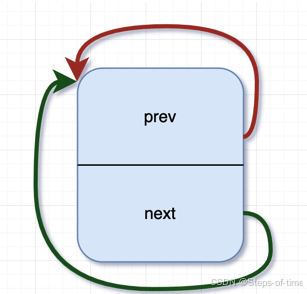
上图判断链表是否为空也通过该指向是否为自己作为判断条件(head->next == head)。
2.添加新链表节点
增加分为两种头插法跟尾插法,如下两种分别介绍:
公共内置方法:
/*
* Insert a new entry between two known consecutive entries.
*
* This is only for internal list manipulation where we know
* the prev/next entries already!
*/
static inline void __list_add(struct list_head *new,
struct list_head *prev,
struct list_head *next)
{
next->prev = new;
new->next = next;
new->prev = prev;
prev->next = new;
}头插法方法 list_add:
/**
* list_add - add a new entry
* @new: new entry to be added
* @head: list head to add it after
*
* Insert a new entry after the specified head.
* This is good for implementing stacks.
*/
static inline void list_add(struct list_head *new, struct list_head *head)
{
__list_add(new, head, head->next);
}如上代码,头插法直接在头节点跟其下一个节点之间加入新的节点,直接通过list_add,内部调用__list_add方法操作即可。采用头插法的链表节点是反序的。因双向循环,可以通过prev反向遍历就能得到正向的数据序列。
图示:
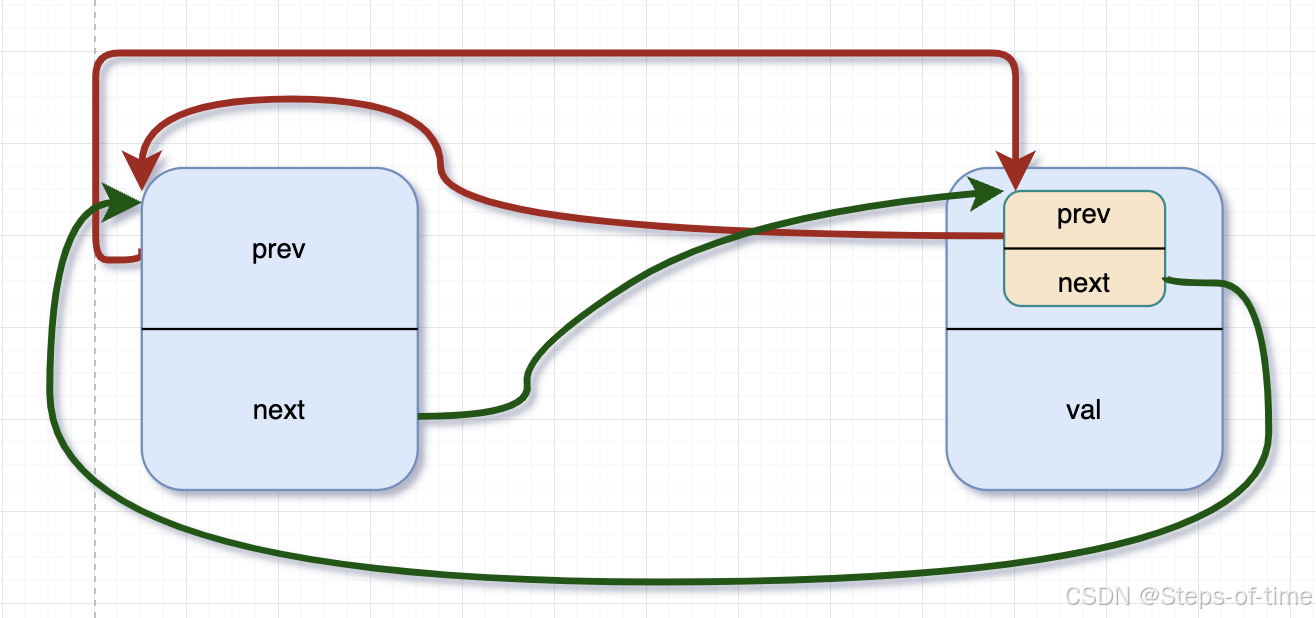
add New ndoe:虚线为增加节点时,指针指向变动
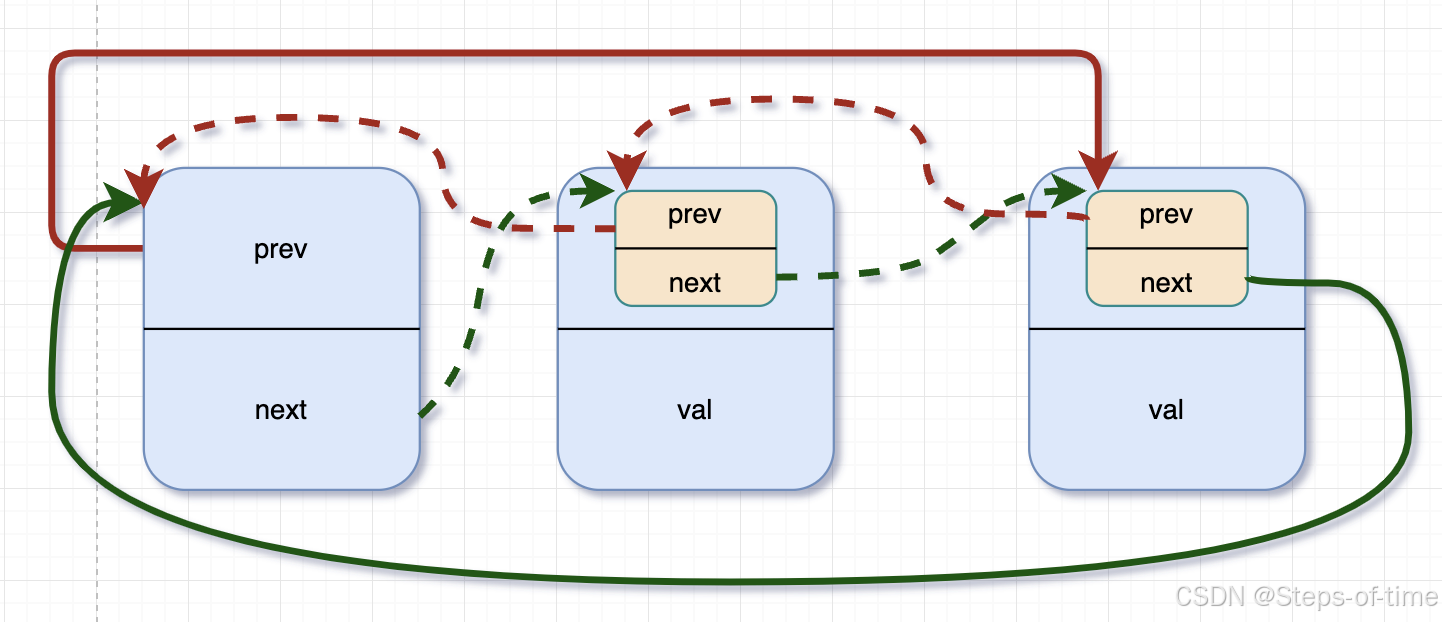
尾插法 list_add_tail:
/**
* list_add_tail - add a new entry
* @new: new entry to be added
* @head: list head to add it before
*
* Insert a new entry before the specified head.
* This is useful for implementing queues.
*/
static inline void list_add_tail(struct list_head *new, struct list_head *head)
{
__list_add(new, head->prev, head);
}尾插法在单向链表中尾部增加节点时,因其指针单向,插入节点时先找到尾部最后节点,再将新增加的节点加入。(或者设置尾部指针,用于通过尾插法时直接插入)。双向节点其实也是利用该特性,在尾部插入新节点,因双向循环链表,可通过头节点的prev直接找到尾部节点位置,通过上述代码操作将新节点加入链表。
图示:
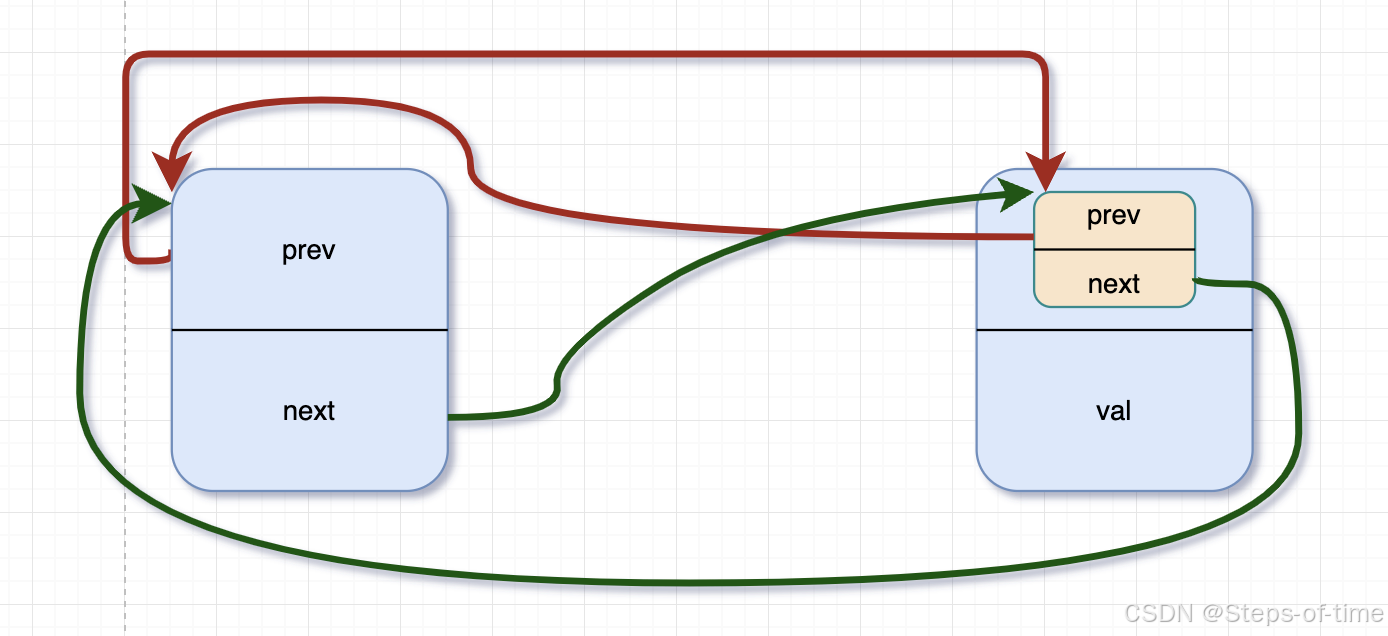
add new ndoe:虚线为增加节点时,指针指向变动
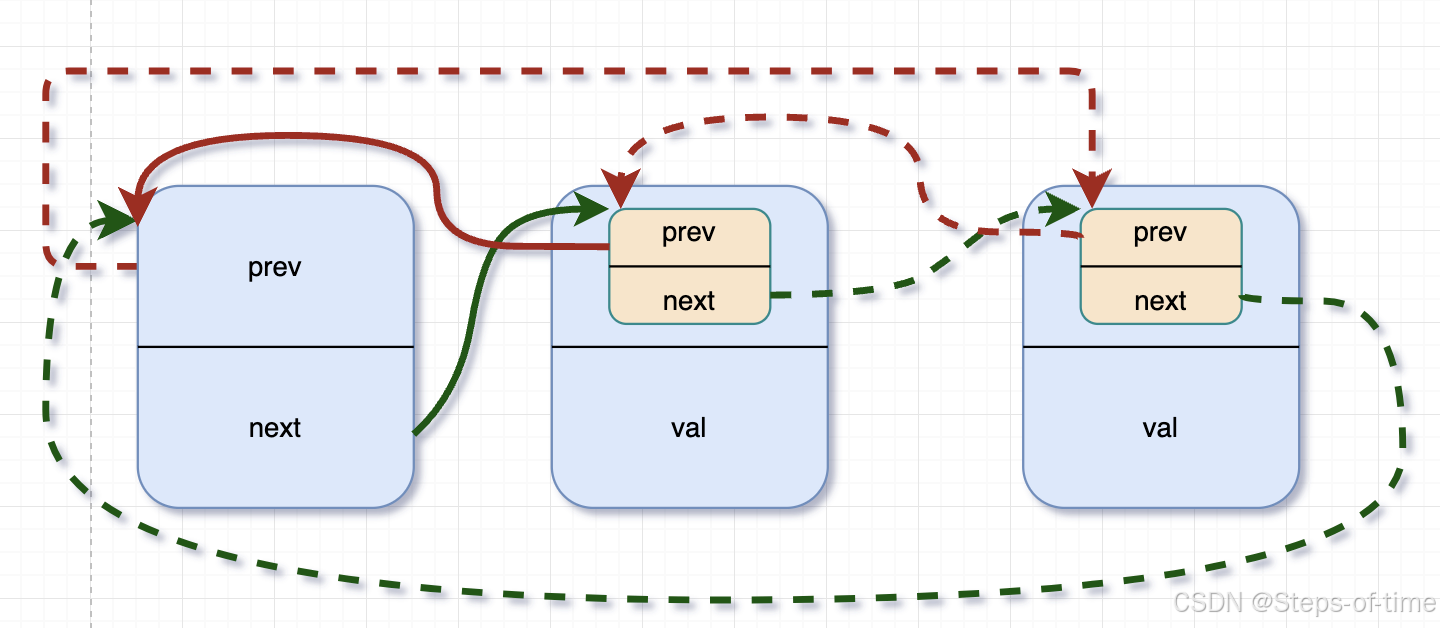
3.遍历链表
宏 :list_for_each_entry进行链表的访问遍历
/**
* list_entry - get the struct for this entry
* @ptr: the &struct list_head pointer.
* @type: the type of the struct this is embedded in.
* @member: the name of the list_struct within the struct.
*/
#define list_entry(ptr, type, member) \
container_of(ptr, type, member)
/**
* list_for_each_entry - iterate over list of given type
* @pos: the type * to use as a loop cursor.
* @head: the head for your list.
* @member: the name of the list_struct within the struct.
*/
#define list_for_each_entry(pos, head, member) \
for (pos = list_entry((head)->next, typeof(*pos), member); \
&pos->member != (head); \
pos = list_entry(pos->member.next, typeof(*pos), member))pos: 循环遍历的游标指针(每次通过list_entry获取下一个节点结构的地址)
head:链表的头节点指针
member:结构体中定义的list_head结构成员名称
4.删除链表
接口list_del:
/*
* Delete a list entry by making the prev/next entries
* point to each other.
*
* This is only for internal list manipulation where we know
* the prev/next entries already!
*/
static inline void __list_del(struct list_head * prev, struct list_head * next)
{
next->prev = prev;
prev->next = next;
}
static inline void list_del(struct list_head *entry)
{
__list_del(entry->prev, entry->next);
entry->next = LIST_POISON1;
entry->prev = LIST_POISON2;
}当找到要删除节点,利用双向指针特性操作,将删除节点前后节点的指针相互挂链,再释放掉当前节点占据内存。可能有人会问,上述到代码中LIST_POISON1跟LIST_POISON2表示什么意思?通过调查,这两个宏是系统用于标记已经删除或者未初始化的链表节点,帮助检测和调试潜在内存错误,例如访问已经释放or未初始化内存问题。另外也可以当删除一个链表节点前,再通过初始化函数将要删除的节点的prev跟next重新初始化后,再行释放掉当前节点的内存。
上述讲解了如何删除某个具体节点,如何确定某个节点要被删除呢?可能立马想到了3中叙述的宏。找到节点后,直接删除掉即可。但是实际上,使用3中的宏配合4种的接口删除某个节点会导致内核崩溃从而导致系统无法使用。原因是,当pos位置要被删除时,虽然链表前后已经重新挂链,pos指向的内存已经kfree,后面再通过pos向后游走,就会访问不可访问的内存错误,从而导致系统崩溃问题。那么因该如何正确找到要删除节点,并且安全正常的删除呢?见5描述讲解。
5.安全访问链表并删除
宏:list_for_each_entry_safe
/**
* list_for_each_entry_safe - iterate over list of given type safe against removal of list entry
* @pos: the type * to use as a loop cursor.
* @n: another type * to use as temporary storage
* @head: the head for your list.
* @member: the name of the list_struct within the struct.
*/
#define list_for_each_entry_safe(pos, n, head, member) \
for (pos = list_entry((head)->next, typeof(*pos), member), \
n = list_entry(pos->member.next, typeof(*pos), member); \
&pos->member != (head); \
pos = n, n = list_entry(n->member.next, typeof(*n), member))该宏跟3中描述的宏有些许差异,从上述代码宏来看,采用了双指针来遍历当前链表(跳过头指针开始)。利用pos游标判别是否要删除的节点,再联合list_del函数进行删除某个节点(具体涉及业务层面)。因其双向循环,当&pos->member != (head)条件成立,表示遍历完成。
图示:
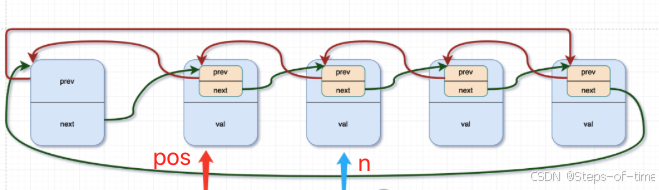
遍历结束:
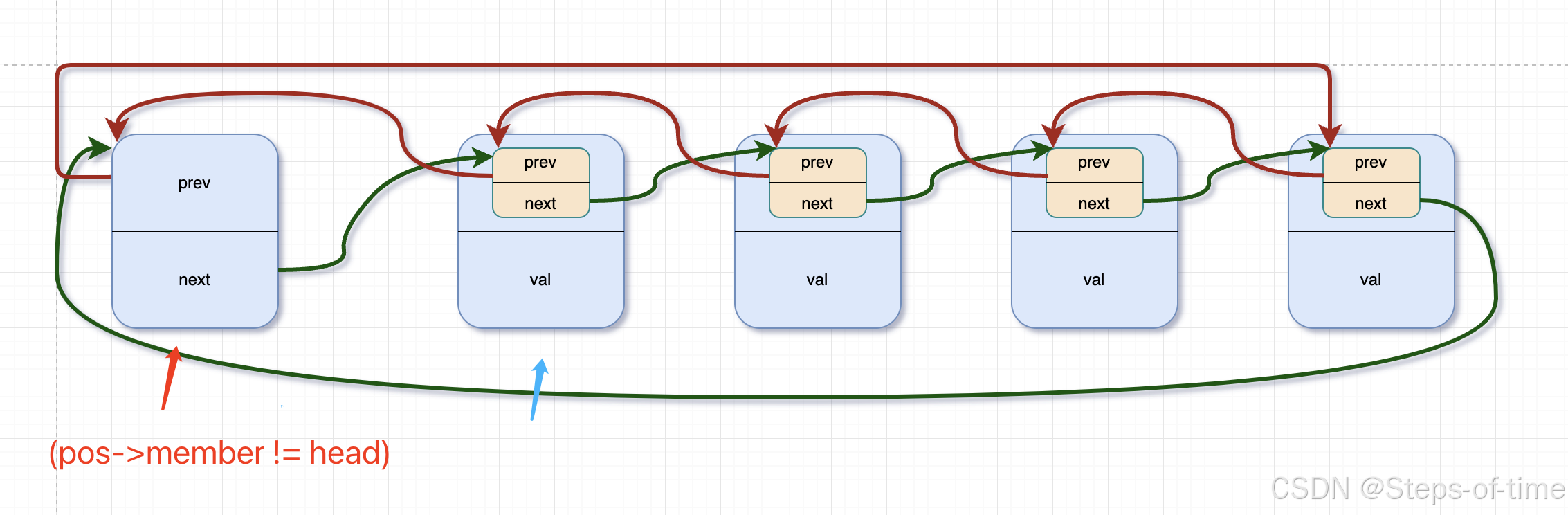
遍历过程中删除:(删除pos指向的节点)
查找删除节点pos
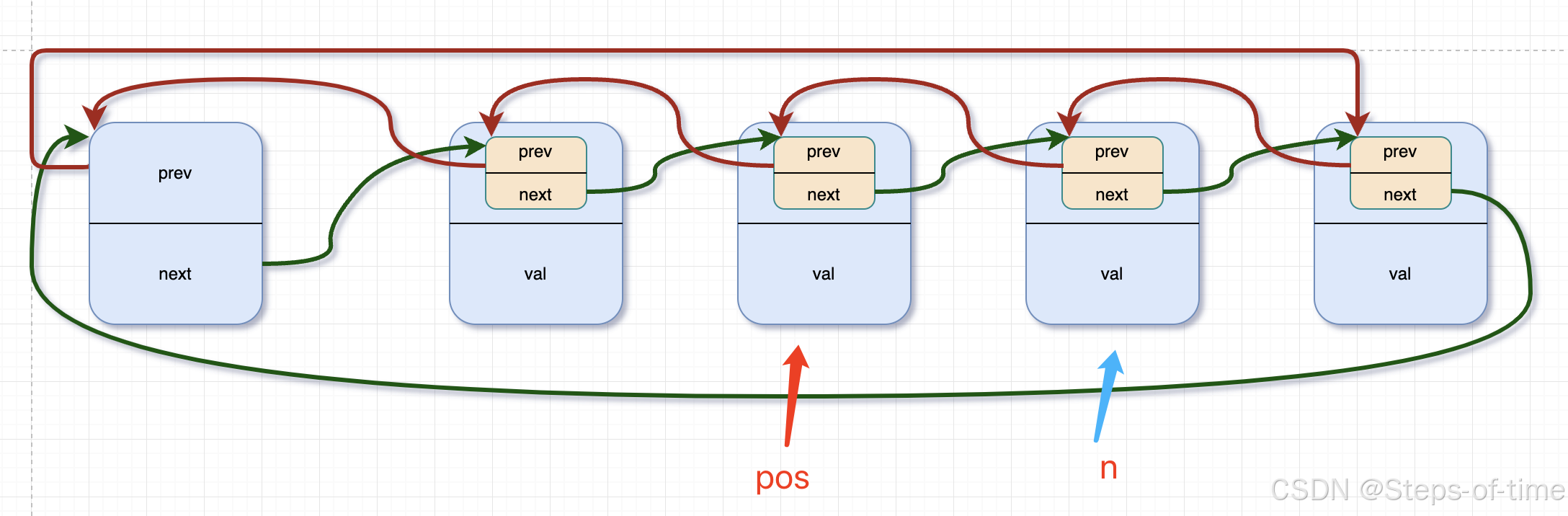
删除pos节点后:
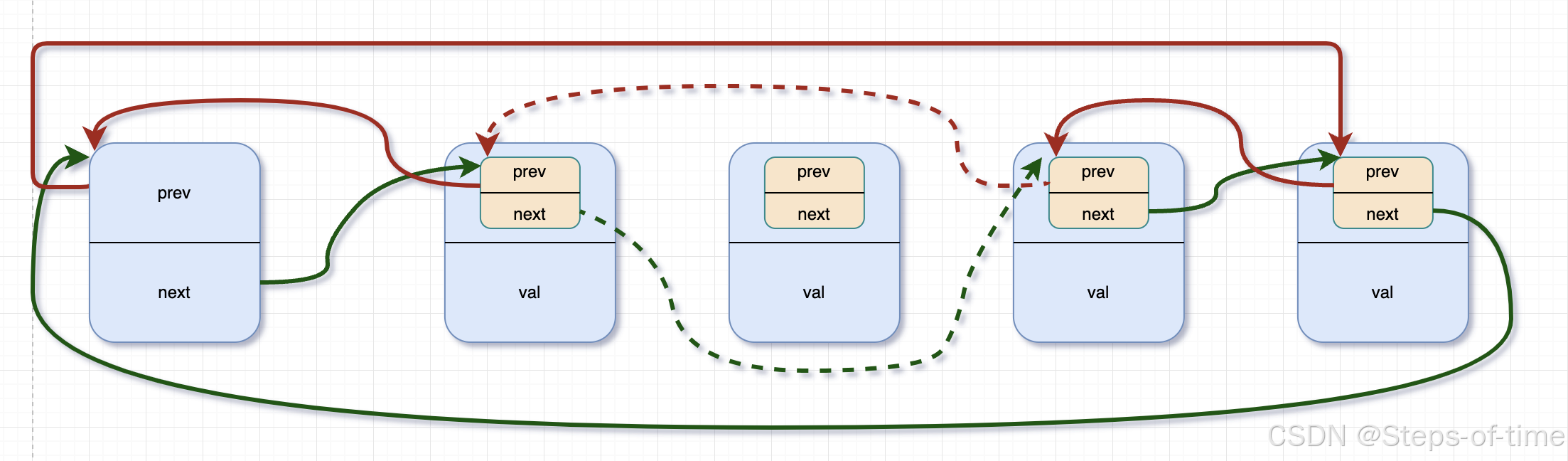
6.内核链表使用举例
#include <linux/module.h>
#include <linux/kernel.h>
#include <linux/init.h>
#include <linux/list.h>
#include <linux/slab.h>
struct my_data {
struct list_head list;
int value;
int haha;
};
struct my_data_mgr {
struct list_head head;
int nums;
};
static struct my_data_mgr my_data_hander;
// 插入一个新的节点到链表尾部
void addNode(struct my_data *data) {
list_add_tail(&data->list, &my_data_hander.head);
}
// 从链表中删除一个节点
void delNode(struct my_data *data) {
list_del(&data->list);
}
// 打印
void printlink(void) {
struct my_data *entry;
// 使用 list_for_each_entry 宏遍历链表
list_for_each_entry(entry, &my_data_hander.head, list) {
printk(KERN_INFO "%d - %d - %d\n", entry->value,entry->haha,my_data_hander.nums);
}
}
// fun 函数遍历查找某个节点且删除
void fun()
{
struct my_data *entry, *tmp;
list_for_each_entry_safe(entry, tmp, &my_data_hander.head, list) {
if(entry->value == 30){
remove_from_list(entry);
kfree(entry);
}
}
}
void link_fun()
{
INIT_LIST_HEAD(&my_data_hander.head);
my_data_hander.nums = 0;
// 分配内存并初始化数据
struct my_data *data1 = (struct my_data*)kmalloc(sizeof(struct my_data), GFP_KERNEL);
if (!data1) {
return -ENOMEM;
}
data1->value = 10;
data1->haha = 44;
struct my_data *data2 = (struct my_data*)kmalloc(sizeof(struct my_data), GFP_KERNEL);
if (!data2) {
return -ENOMEM;
}
data2->value = 20;
data2->haha = 55;
struct my_data* data3 = (struct my_data*)kmalloc(sizeof(struct my_data), GFP_KERNEL);
if (!data3) {
return -ENOMEM;
}
data3->value = 30;
data3->haha = 66;
struct my_data* data4 = (struct my_data*)kmalloc(sizeof(struct my_data), GFP_KERNEL);
if (!data4) {
return -ENOMEM;
}
data4->value = 40;
data4->haha = 77;
// 将数据添加到链表
addNode(data1);
my_data_hander.nums++;
addNode(data2);
my_data_hander.nums++;
addNode(data3);
my_data_hander.nums++;
addNode(data4);
my_data_hander.nums++;
// 打印链表内容
printlink();
fun();
printlink();
}
static int __init my_ker_list_init(void) {
link_fun();
return 0;
}
static void __exit my_ker_list_exit(void) {
struct my_data *entry, *tmp;
list_for_each_entry_safe(entry, tmp, &my_data_hander.head, list) {
printk(KERN_INFO "%d - %d will del\n", entry->value,entry->haha);
delNode(entry);
kfree(entry);
}
printk(KERN_INFO "exited\n");
}
module_init(my_ker_list_init);
module_exit(my_ker_list_exit);
MODULE_LICENSE("GPL");
MODULE_AUTHOR("VisionFocus");
MODULE_DESCRIPTION("VisionFocus's kernel list");内核打印的日志:
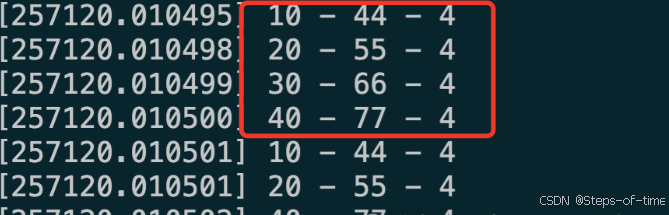
三.总结
以上就是针对linux内核实现的双向循环链表的补习笔记总结,先通过最初的基本链表引入,再对比两种形态的差别,后再深入针对内核源码相关实现进行讲解概述了内核双向循环链表的实现过程,每个点相关都有相关的图例供给增加理解。其中最经典的就是内核实现的offsetof跟container_of两个宏,堪称一绝。总之理解透彻,受益匪浅。(以上的内核源码参考3.10.0-1160.el7.x86_64版本)