【教学类-89-04】20250130新年篇04——九叠篆印章(九叠篆站+Python下载图片+Python组合文字)幼儿名字印章

背景需求:
曾经给6位大班幼儿做过一个插入纸盒茶杯,底部有幼儿的姓名印章(李四光印)
【教学类-21-02】20221210《青花茶杯-A4纸插入式纸盒-不同花纹》(大班主题《我是中国人-青花瓷》)_大班青花瓷主题网络图-CSDN博客文章浏览阅读281次。【教学类-21-02】20221210《青花茶杯-A4纸插入式纸盒-不同花纹》(大班主题《我是中国人-青花瓷》)_大班青花瓷主题网络图https://blog.csdn.net/reasonsummer/article/details/128269100https://blog.csdn.net/reasonsummer/article/details/128269100https://blog.csdn.net/reasonsummer/article/details/128269100https://blog.csdn.net/reasonsummer/article/details/128269100https://blog.csdn.net/reasonsummer/article/details/128269100https://blog.csdn.net/reasonsummer/article/details/128269100https://blog.csdn.net/reasonsummer/article/details/128269100https://blog.csdn.net/reasonsummer/article/details/128269100https://blog.csdn.net/reasonsummer/article/details/128269100https://blog.csdn.net/reasonsummer/article/details/128269100https://blog.csdn.net/reasonsummer/article/details/128269100https://blog.csdn.net/reasonsummer/article/details/128269100![]() https://blog.csdn.net/reasonsummer/article/details/128269100
https://blog.csdn.net/reasonsummer/article/details/128269100
我想让每位孩子都有一个自己名字的“印章”
2024年12月7日 网络查询后,发现“印章”多用“篆书”“隶书”“楷书”等



因为我经常听到“篆刻”,而且篆书排在第一,所以想用篆书
大篆

小篆

九叠篆(塞满,艺术性强、宋代国朝官印)

花鸟篆(文字以花鸟形式替代)

小结:
考虑到操作便利性和艺术性,我选了“九叠篆”,四四方方更适合印章效果。

字体下载
测试一:下载白舟九叠篆


复制到font下


问题1:部分字无法用篆刻九叠篆样式写出来

解决1:把名字转成繁体,再用九叠篆(hkkjtr),部分姓氏变成篆体了

问题2:还是有部分姓氏、名字无法转

2、测试二:下载一个图章生成器

有木马,自动删除了,下载不了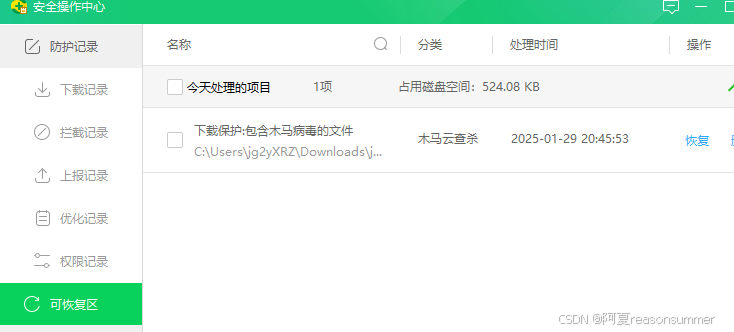
3、测试三:“九叠篆”在线字体网,直接做4字印章(2*2)
九叠篆字形在线生成制作印章图 - 九叠篆,国潮私印,书法字典,字体,篆刻,在线转换生成http://jiudiezhuan.com/createseal.asphttp://jiudiezhuan.com/createseal.asphttp://jiudiezhuan.com/createseal.asphttp://jiudiezhuan.com/createseal.asphttp://jiudiezhuan.com/createseal.asphttp://jiudiezhuan.com/createseal.asphttp://jiudiezhuan.com/createseal.asphttp://jiudiezhuan.com/createseal.asphttp://jiudiezhuan.com/createseal.asphttp://jiudiezhuan.com/createseal.asphttp://jiudiezhuan.com/createseal.asphttp://jiudiezhuan.com/createseal.asphttp://jiudiezhuan.com/createseal.asp![]() http://jiudiezhuan.com/createseal.asp
http://jiudiezhuan.com/createseal.asp
(1)字体布局
两个名字:从左向右,从上到下

我希望是从上到下,从右到左(古代右向左),把名字和印章两字调整顺序

三个名字


四个名字



小结:这个在线平台能把孩子们的名字生成四字印章图片,我可以用UIBOT自动将繁体名字复制到这个在线平台里。获取九叠篆印章图案
(2)特殊字体设置
可能1:部分繁体字没有九叠篆字体
我把几个特殊字体输入试试看。好多字的确没有九篆体

可能2:繁体转简体出现九叠篆字体
我把名字改回简体字,再试试,姓氏出来了。那就只有第二个名字没有。

可能3:简繁体都没有的文字请网站开发者设计
这位开发者很厉害,对于不存在的字,他也会愿意设计!,我先手动测试哪些字(简体或繁体)都不存在,需要被设计。


人工搜索后,发现有4个字不存在,需要设计。

等开学后,再光顾网站,看看汉字的九叠篆样式是否存在。
然后写UIBOT代码,自动读取EXCLE的简体字,重新组合字序,下载名字图片。再用Python,进行图案处理(红色转黑色,水平翻转做镜像字,批量调整大小等)。制作成学具。让幼儿把印章图片贴在KT版上,然后沿着线戳洞。制作一个可以按印泥的印章。

感谢这个网站的大神,提供了九叠篆印章的图片!
实验四:已有字拼合出生僻字
考虑到这个网站不挣钱,开发者未必会经常登录并设计,所以我想利用网站上已有的九叠篆字,提取边旁部首,PS合成图片
“琬”:王字旁的“环玲珠珍”
让AI写一点王字旁的字
关键词:王字旁的字,只要字,表格形式呈现,

放到搜索字体里面,一共19字

可以发现 王字旁有三种写法

其中“珍”的“王”这种写法出现次数最多

“琬”:宛的字不多
关键词:汉字里面有宛字旁,左右结构,只要字,不要任何说明,表格形式呈现

宛字的九叠篆写法都一样:保留一个“婉”

同样方法测试:“炎,宣、斤、页”


如果发现找不到字,就重新新建一个对话框,再搜索



这个斤是左右结构,但是每个字有大小的
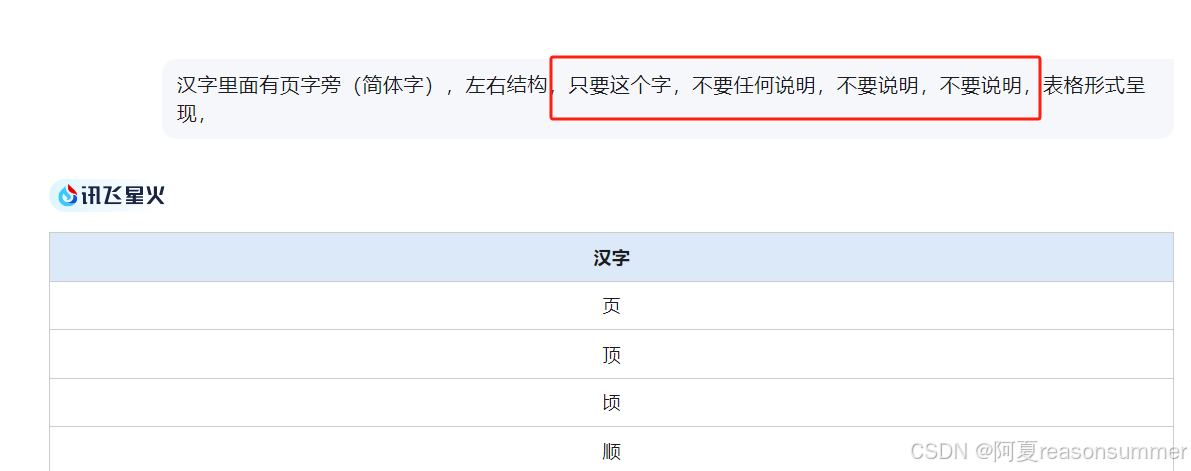
都是一样的“页”,也是有“宽”有“窄”

由此,可以通过查找相关的汉字,获取,获取特殊汉字的边旁部首,进行组合
琬:珍和婉

琰:珍和淡


因为暄只有一个写法,只能三个王字里面选:但是三个王都比日宽,所以

所以恐怕要把宣字左右缩小了、
颀=顷+斯


保存后的效果图

接下来就是UIBOT写代码,读取文字,重新组合位置,制作右向左的四个字,生成图片(等30秒),另存为“学号+名字.png”

因为UIBOT程序一直在下载其他图片,
所以我还是用Python写了一个代码,Python识别屏幕坐标比较烦,不像UIBOT可以识别屏幕。它只能一次次测试,获取坐标数字
'''
查找坐标位置的代码
阿夏
20250130
'''
import time
import pyautogui
import pyperclip
time.sleep(2)
# 获取当前鼠标的位置
x, y = pyautogui.position()
print("Current mouse position:", x, y)
全部代码
'''
根据名字,下载九叠篆姓名印章(四字) 英文拼音输入法状态,先打开一个百度界面
星火讯飞、阿夏
20250130
'''
import pandas as pd
path = r'C:\Users\jg2yXRZ\OneDrive\桌面\20250130篆章九叠篆'
# 读取 Excel 文件
df = pd.read_excel(path + r'\姓名.xlsx', usecols=[0, 1])
# 打印第一列和第二列组合的文字(图片名称) 创建图片名称列表
image_names = []
# 打印第一列和第二列组合的文字(图片名称)并添加到列表中
for index, row in df.iterrows():
image_name = f"{row[0]:02} {row[1]}"
# print(image_name)
image_names.append(image_name)
print(image_names)
# 定义一个函数来根据字数添加后缀
def add_suffix(cell):
if len(str(cell)) == 2:
return str(cell) + '印章'
elif len(str(cell)) == 3:
return str(cell) + '印'
else:
return cell
# 需要做图章的四个文字
# df[df.columns[1]] = df[df.columns[1]].apply(add_suffix)# [1,'余三',
df = df[df.columns[1]].apply(add_suffix)# ['余三',
# 将修改后的 DataFrame 转换为列表
modified_list = df.values.tolist()
print(modified_list)
for i in range(len(image_names[19:])):
# 进入自动点击屏幕设置(打开九叠篆网站)
import pyautogui
import pyperclip
import time
# 移动鼠标到指定的坐标位置
# 新建页面
pyautogui.moveTo(287,22)
# 执行鼠标左键点击操作
pyautogui.click()
# 打开网站
pyautogui.moveTo(259, 64)
# 执行鼠标左键点击操作
pyautogui.click()
# 等待一小段时间以确保点击生效
time.sleep(1)
# 输入网址
url = 'http://jiudiezhuan.com/createseal.asp'
pyautogui.typewrite(url)
time.sleep(3)
# 按下回车键以访问网址
pyautogui.press('enter')
# 弹框
pyautogui.moveTo(1130,179)
# 执行鼠标左键点击操作
pyautogui.click()
# 输入框
# 将中文文字复制到剪贴板
pyautogui.moveTo(794, 377)
pyautogui.click()
text = modified_list[19:][i]
pyperclip.copy(text)
# 模拟按下Ctrl+V粘贴文本
pyautogui.hotkey('ctrl', 'v')
# 再按回车键
pyautogui.press('enter')
time.sleep(5)
# 生成图片
pyautogui.moveTo(1741,617)
pyautogui.click()
time.sleep(20)
# 右击另存你好,世界!
# x, y = 1000, 2000
pyautogui.moveTo(876, 452)
# 执行鼠标右击操作
pyautogui.rightClick()
time.sleep(2)
pyautogui.moveTo(917,504)
# 执行鼠标右击操作
pyautogui.rightClick()
time.sleep(5)
# # 文件名输入
# pyautogui.moveTo(175,802)
# # 执行鼠标右击操作
# pyautogui.rightClick()
# # 文件名
text = image_names[19:][i]
pyperclip.copy(text)
# 模拟按下Ctrl+V粘贴文本
pyautogui.hotkey('ctrl', 'v')
# 再按回车键
pyautogui.press('enter')
time.sleep(3)
# 关闭页面
pyautogui.moveTo(497,18)
# 执行鼠标左键点击操作
pyautogui.click()
画了半个小时,才把30+4个名字图片生成好

这是最基础的左向右、上到下的布局。如果我想变成上到下,右到左又要这么来一次,不仅费时,几个拼图字还要合成两次。
所以我发现完全可以把30个名字,每个字单独拆开来,去掉重复字(我们班“王、一”比较多)”,然后依次生成单个字,用Python遍历读取方式,提取需要的四个字,用活字印刷的方式布局,那么想怎么布局就能怎么布局,还可以更改印章、之印、专章等字)
python 用代码读取每个汉字,去掉重复。
'''
根据名字,下载九叠篆姓名印章(单字)活字印刷拼合 英文拼音输入法状态,先打开一个百度界面
星火讯飞、阿夏
20250130
'''
import pandas as pd
start=22
path = r'C:\Users\jg2yXRZ\OneDrive\桌面\20250130篆章九叠篆'
# 读取 Excel 文件
df = pd.read_excel(path + r'\姓名.xlsx', usecols=[0, 1])
# 创建图片名称集合
image_names_set = set()
# 打印第一列和第二列组合的文字(图片名称)并添加到集合中,把每个名字变成单个的字
for index, row in df.iterrows():
# 假设单元格内容是用逗号分隔的
cell_content = str(row[1])
elements = cell_content.split(',')
for element in elements:
element = element.strip()
# 将元素中的每个字符拆分成单独的元素
for char in element:
image_names_set.add(char)
# 将集合转换为列表
image_names = (list(image_names_set))
# 排序,否则文字下载的时候每次的顺序都不同,如果断了,不知道从那个字开始
image_names.sort()
print(image_names)
print(len(image_names))
# 77
把终端显示的所有单个汉字,复制(77字)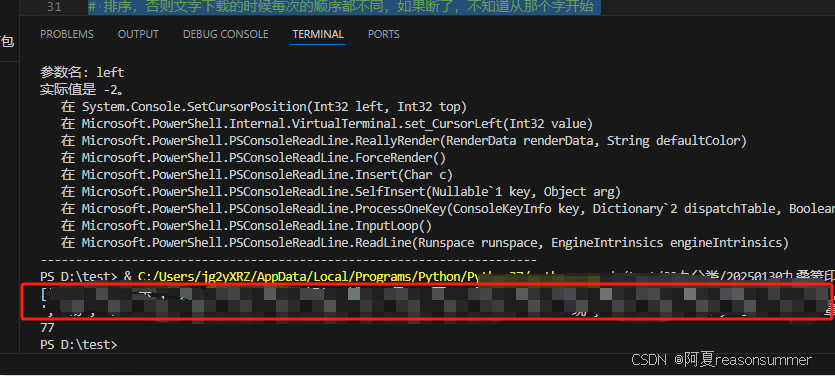
黏贴到“九叠篆-搜索字形”的文字框里(100字以内)
所有字体都显示出来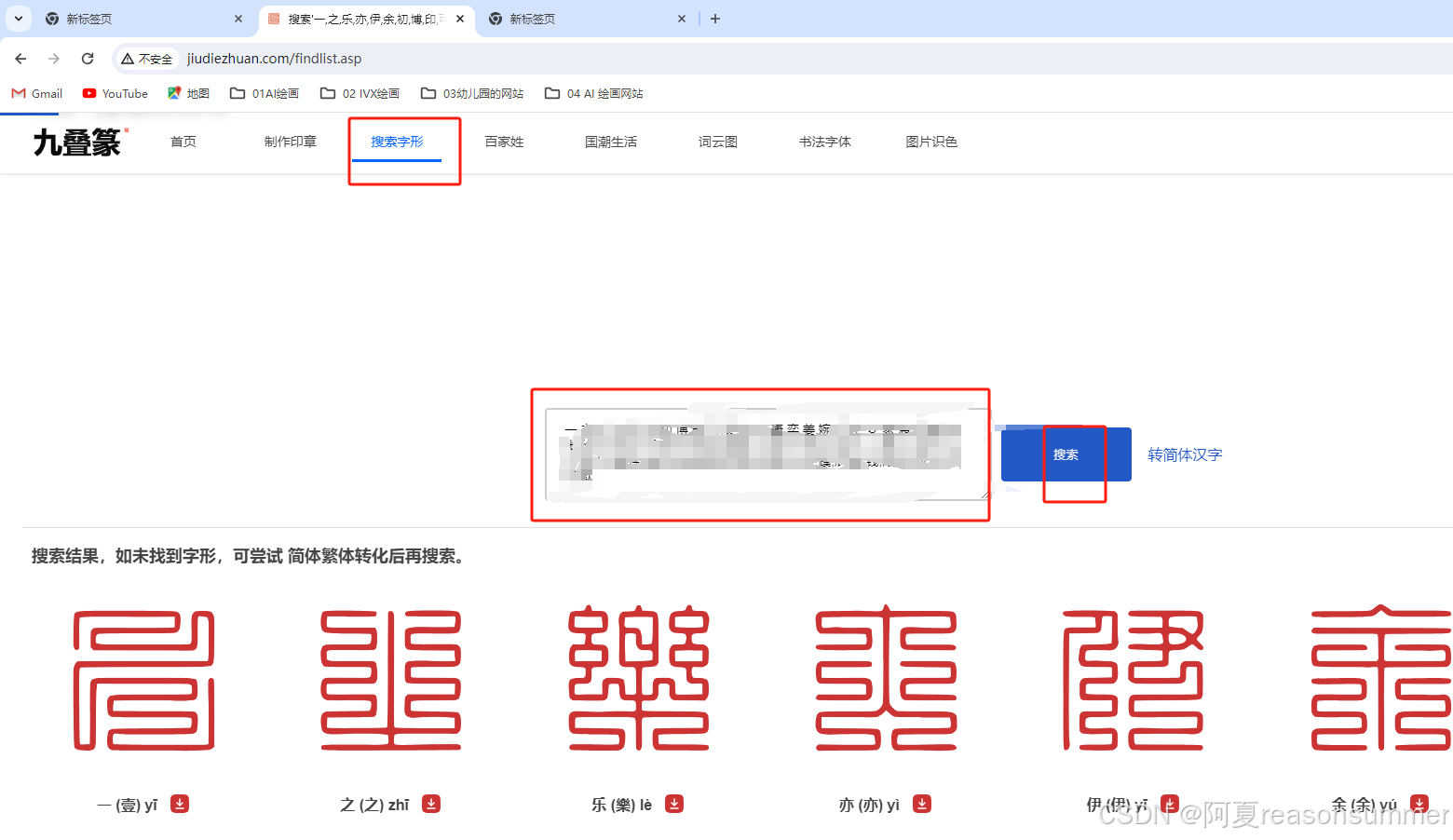
4个汉字没有

'''
根据名字,下载九叠篆姓名印章(单字)活字印刷拼合 英文拼音输入法状态,先打开一个百度界面
星火讯飞、阿夏
20250130
'''
import pandas as pd
import time
import pyautogui
import pyperclip
start=54
path = r'C:\Users\jg2yXRZ\OneDrive\桌面\20250130篆章九叠篆'
# 读取 Excel 文件
df = pd.read_excel(path + r'\姓名.xlsx', usecols=[0, 1])
# 创建图片名称集合
image_names_set = set()
# 打印第一列和第二列组合的文字(图片名称)并添加到集合中,把每个名字变成单个的字
for index, row in df.iterrows():
# 假设单元格内容是用逗号分隔的
cell_content = str(row[1])
elements = cell_content.split(',')
for element in elements:
element = element.strip()
# 将元素中的每个字符拆分成单独的元素
for char in element:
image_names_set.add(char)
# 将集合转换为列表
image_names = (list(image_names_set))
# 排序,否则文字下载的时候每次的顺序都不同,如果断了,不知道从那个字开始
image_names.sort()
print(image_names)
print(len(image_names))
# 77
# 打开网址(只有1次)
pyautogui.moveTo(287,22)
# 执行鼠标左键点击操作
pyautogui.click()
time.sleep(1)
# 输入网址
url = 'http://jiudiezhuan.com/findlist.asp'
pyautogui.typewrite(url)
# 按下回车键以访问网址
pyautogui.press('enter')
time.sleep(1)
# 弹框
pyautogui.moveTo(1130,179)
# 执行鼠标左键点击操作
pyautogui.click()
time.sleep(2)
for i in range(len(image_names[start:])):
# 进入自动点击屏幕设置(打开九叠篆网站)
# 输入框
# 将中文文字复制到剪贴板
pyautogui.moveTo(697,293)
pyautogui.click()
# pyautogui.moveTo(1527,778)
# pyautogui.click()
# # 双击
pyautogui.doubleClick()
text = image_names[start:][i]
pyperclip.copy(text)
# 模拟按下Ctrl+V粘贴文本
pyautogui.hotkey('ctrl', 'v')
time.sleep(2)
# 再按回车键
pyautogui.moveTo(1109,320)
pyautogui.click()
time.sleep(2)
# 下载按钮
pyautogui.moveTo(142,590)
pyautogui.click()
# 下载png高清图
pyautogui.moveTo(249,605)
pyautogui.click()
time.sleep(3)
# 保存
pyautogui.press('enter')
time.sleep(3)
一次只下载一个字,这一次用了17分钟就下载了73个字,速度快多了。



PPTX,把两张图片叠放在一起,重新组合


左右部首都缩窄一点

琬

琰

颀

用两种颜色区分




组合图片效果

放到单字字库里

制作图片组合
'''
活字拼合:根据名字,提取对应九叠篆文字的图片,组合成2*2印章形状
星火讯飞、阿夏
20250130
'''
import pandas as pd
from PIL import Image
import os
from PIL import Image, ImageDraw
# 画布大小(正方形)
pic=500
# 边距线框粗细
bj=10
start = 30
path = r'C:\Users\jg2yXRZ\OneDrive\桌面\20250130篆章九叠篆'
# 读取 Excel 文件
df = pd.read_excel(path + r'\姓名.xlsx', usecols=[0, 1])
# 打印第一列和第二列组合的文字(图片名称) 创建图片名称列表
image_names = []
for index, row in df.iterrows():
image_name = f"{int(row[0]):02} {row[1]}"
image_names.append(image_name)
print(image_names)
# 定义一个函数来根据字数添加后缀
def add_suffix(cell):
if len(str(cell)) == 2:
return str(cell) + '印章'
elif len(str(cell)) == 3:
return str(cell) + '印'
else:
return cell
# 需要做图章的四个文字
df[df.columns[1]] = df[df.columns[1]].apply(add_suffix)
# 将修改后的 DataFrame 转换为列表
modified_list = df[df.columns[1]].values.tolist()
print(modified_list)
# 只要前面30个人
modified_list = modified_list[:start]
# 使用列表推导式将每个名字拆分成单个字符
split_chars = [char for name in modified_list for char in name]
print(split_chars)
print(len(split_chars))
# 定义文件夹路径和目标文件名列表
folder_path = path + r'\01 单字下载'
# 获取文件夹中的所有文件
all_files = os.listdir(folder_path)
# 按照姓名出现的顺序依次读取字的图片(活字)
matched_files = []
for char in split_chars:
matched_files.extend([os.path.join(folder_path, file) for file in all_files if char in file])
print(matched_files)
# 将字符列表按每4个一组进行嵌套(四个字一组)
nested_chars = [matched_files[i:i+4] for i in range(0, len(matched_files), 4)]
print(nested_chars)
print(len(nested_chars))
# 遍历每个位置并插入对应的图片
output_folder = os.path.join(path, '02 图片组合')
if not os.path.exists(output_folder):
os.makedirs(output_folder)
# 遍历每个位置并插入对应的图片
for i, group in enumerate(nested_chars):
# 创建一个500x500的透明背景图
background = Image.new('RGBA', (pic, pic), (255, 255, 255, 0))
# 定义插入图片的位置(左上,左下 ,右上,右下)
# 坐标两款
z1=bj
z2=int(pic/2)
# 图片大小
z3=z2-bj
positions = [(z1, z1), (z1, z2), (z2, z1), (z2,z2)]
for pos, image_path in zip(positions, group):
try:
img = Image.open(image_path).convert("RGBA")
img = img.resize((z3,z3)) # 调整图片大小为250x250
background.paste(img, pos, img) # 使用alpha通道粘贴图片
except Exception as e:
print(f"Error processing {image_path}: {e}")
# 在500x500背景上添加红色边框5磅
draw = ImageDraw.Draw(background)
border_color = (255, 0, 0) # 红色
border_width = bj # 5磅
for j in range(border_width):
draw.rectangle([j, j, 499-j, 499-j], outline=border_color)
output_path = os.path.join(output_folder, f"{image_names[i]}.png")
background.save(output_path)
print(f"Saved combined image to {output_path}")图片效果(透明背景)

按学号排序(用了学号和姓名做文件名)

4个坐标位置(10,10)(10,250)(250,10)(250,250)


把坐标更换一下


我喜欢的上到下,右向左,


黑色框都是“印”

这个代码可以自动调整红色边框线。

如果我想加粗红色边框,缩小汉字


太神奇了。
后续还有3个思路要继续制作:
1、图片水平翻转(制作打孔的线条印章,真的能印)
2、线条变成黑色(非透明部分转黑色,打印机彩打红色,浪费墨)
3、九叠篆字体“笔底龙蛇”“笔画蜿蜒”,艺术性强,但基本无法辨认姓名,需要再做一个隶书版本(包含学号)。便于老师和幼儿确认物权。
WORD模版


代码展示:
线条变成黑色,图像左右翻转(镜像字 才能印出来是正的字)
'''
活字拼合:根据名字,提取对应九叠篆文字的图片,组合成2*2印章形状(图片文字颜色变成黑色,图片左右翻转镜像)
星火讯飞、阿夏
20250131
'''
import pandas as pd
from PIL import Image
import os
from PIL import Image, ImageDraw
# 画布大小(正方形)
pic=500
# 边距线框粗细(靠边)
# bj=10
# # 边距线框粗细(留白边)
bj=20
# 只要前面30个人
start = 30
path = r'C:\Users\jg2yXRZ\OneDrive\桌面\20250130篆章九叠篆'
# 读取 Excel 文件
df = pd.read_excel(path + r'\姓名.xlsx', usecols=[0, 1])
# 打印第一列和第二列组合的文字(图片名称) 创建图片名称列表
image_names = []
for index, row in df.iterrows():
image_name = f"{int(row[0]):02} {row[1]}"
image_names.append(image_name)
print(image_names)
# 定义一个函数来根据字数添加后缀
def add_suffix(cell):
if len(str(cell)) == 2:
return str(cell) + '印章'
elif len(str(cell)) == 3:
return str(cell) + '印'
else:
return cell
# 需要做图章的四个文字
df[df.columns[1]] = df[df.columns[1]].apply(add_suffix)
# 将修改后的 DataFrame 转换为列表
modified_list = df[df.columns[1]].values.tolist()
print(modified_list)
# 只要前面30个人
modified_list = modified_list[:start]
# 使用列表推导式将每个名字拆分成单个字符
split_chars = [char for name in modified_list for char in name]
print(split_chars)
print(len(split_chars))
# 定义文件夹路径和目标文件名列表
folder_path = path + r'\01 单字下载'
# 获取文件夹中的所有文件
all_files = os.listdir(folder_path)
# 按照姓名出现的顺序依次读取字的图片(活字)
matched_files = []
for char in split_chars:
matched_files.extend([os.path.join(folder_path, file) for file in all_files if char in file])
print(matched_files)
# 将字符列表按每4个一组进行嵌套(四个字一组)
nested_chars = [matched_files[i:i+4] for i in range(0, len(matched_files), 4)]
print(nested_chars)
print(len(nested_chars))
# 遍历每个位置并插入对应的图片
output_folder = os.path.join(path, '03 图片组合(非镜像)')
if not os.path.exists(output_folder):
os.makedirs(output_folder)
# 遍历每个位置并插入对应的图片
for i, group in enumerate(nested_chars):
# 创建一个500x500的透明背景图
background = Image.new('RGBA', (pic, pic), (255, 255, 255, 0))
# 定义插入图片的位置(左上,左下 ,右上,右下)
# 坐标两款
z1=bj
z2=int(pic/2)
# 图片大小
z3=z2-bj
# (左上1,左下2 ,右上3,右下4)
# positions = [(z1, z1), (z1, z2), (z2, z1), (z2,z2)]
# # (左上1,右上2 ,左下3,右下4)
# positions = [(z1, z1), (z2, z1), (z1, z2),(z2,z2)]
# (右上1,右下2 ,左上3,左下4)3412
positions = [(z2, z1), (z2,z2),(z1, z1), (z1, z2)]
# 翻转后的效果是(左上1,左下2 ,右上3,右下4)1234
# positions = [(z1, z1), (z1, z2), (z2, z1), (z2,z2)]
for pos, image_path in zip(positions, group):
try:
img = Image.open(image_path).convert("RGBA")
img = img.resize((z3,z3)) # 调整图片大小为250x250
background.paste(img, pos, img) # 使用alpha通道粘贴图片
except Exception as e:
print(f"Error processing {image_path}: {e}")
# # 在500x500背景上添加红色边框5磅(靠着边框)
# draw = ImageDraw.Draw(background)
# border_color = (255, 0, 0) # 红色
# border_width = bj # 5磅
# for j in range(border_width):
# draw.rectangle([j, j, pic-j, pic-j], outline=border_color)
# 创建绘图对象(与边框有距离)
draw = ImageDraw.Draw(background)
# 定义边框颜色和宽度
border_color = (255, 0, 0) # 红色
border_width = int(bj/2) # 10磅
margin = int(bj/2) # 边距10磅
# 画红色边框
for j in range(border_width):
draw.rectangle([j + margin, j + margin, pic - j - margin, pic - j - margin], outline=border_color)
# background.save('output_image.png')
output_path = os.path.join(output_folder, f"{image_names[i]}.png")
background.save(output_path)
print(f"Saved combined image to {output_path}")
# 把非透明的部分变成黑色
from PIL import Image
import os
# 设置文件夹路径
folder_path = output_folder
new_path = path + r'\04 黑色文字(非镜像)'
os.makedirs(new_path, exist_ok=True)
# 遍历文件夹中的所有文件
for filename in os.listdir(folder_path):
if filename.endswith('.png'):
# 拼接完整的文件路径
file_path = os.path.join(folder_path, filename)
# 打开图片
with Image.open(file_path) as img:
# 确保图片是RGBA模式(即包含透明度通道)
if img.mode != 'RGBA':
img = img.convert('RGBA')
# 加载图片数据
data = img.getdata()
# 创建一个新的数据列表
new_data = []
# 遍历每个像素
for item in data:
# 如果像素不是完全透明的,则将其设置为黑色
if item[3] != 0:
new_data.append((0, 0, 0, item[3]))
else:
new_data.append(item)
# 更新图片数据
img.putdata(new_data)
# 保存修改后的图片到新路径
new_file_path = os.path.join(new_path, filename)
img.save(new_file_path)
# 左右翻转
from PIL import Image
import os
# 设置文件夹路径
source_folder = new_path
destination_folder = path+r'\04 黑色文字(镜像)'
# 创建目标文件夹(如果不存在)
os.makedirs(destination_folder, exist_ok=True)
# 遍历源文件夹中的所有文件
for filename in os.listdir(source_folder):
if filename.endswith('.png') or filename.endswith('.jpg') or filename.endswith('.jpeg'):
# 拼接完整的文件路径
file_path = os.path.join(source_folder, filename)
# 打开图片
with Image.open(file_path) as img:
# 左右翻转图片
flipped_img = img.transpose(Image.FLIP_LEFT_RIGHT)
# 拼接新的目标文件路径
new_file_path = os.path.join(destination_folder, filename)
# 保存翻转后的图片
flipped_img.save(new_file_path)
print("所有图片已成功左右翻转并保存到新的文件夹中。")
我用这些名字做范例(2-4个名字)

在“九叠篆“网站上下载图片”

运行代码





再制作一个隶书字体(为知道这是谁的名字)
'''
活字拼合:根据名字,制作隶书字体,组合成2*2印章形状
星火讯飞、阿夏
20250131
'''
import pandas as pd
import os
from PIL import Image, ImageDraw, ImageFont
# 画布大小(正方形)
pic=500
# 边距线框粗细(靠边)
# bj=10
# # 边距线框粗细(留白边)
bj=20
# 只要前面30个人
start = 30
path = r'C:\Users\jg2yXRZ\OneDrive\桌面\20250130篆章九叠篆'
# 读取 Excel 文件
df = pd.read_excel(path + r'\姓名.xlsx', usecols=[0, 1])
# 打印第一列和第二列组合的文字(图片名称) 创建图片名称列表
image_names = []
for index, row in df.iterrows():
image_name = f"{int(row[0]):02} {row[1]}"
image_names.append(image_name)
print(image_names)
# 定义一个函数来根据字数添加后缀
def add_suffix(cell):
if len(str(cell)) == 2:
return str(cell) + '印章'
elif len(str(cell)) == 3:
return str(cell) + '印'
else:
return cell
# 需要做图章的四个文字
df[df.columns[1]] = df[df.columns[1]].apply(add_suffix)
# 将修改后的 DataFrame 转换为列表
modified_list = df[df.columns[1]].values.tolist()
print(modified_list)
# 只要前面30个人
modified_list = modified_list[:start]
# 使用列表推导式将每个名字拆分成单个字符
split_chars = [char for name in modified_list for char in name]
print(split_chars)
print(len(split_chars))
# # 定义文件夹路径和目标文件名列表
# folder_path = path + r'\01 单字下载'
# # 获取文件夹中的所有文件
# all_files = os.listdir(folder_path)
# 将字符列表按每4个一组进行嵌套(四个字一组)
nested_chars = [split_chars[i:i+4] for i in range(0, len(split_chars), 4)]
print(nested_chars)
print(len(nested_chars))
# 遍历每个位置并插入对应的图片
# 定义字体路径和大小
font_path = r'C:\Windows\Fonts\simli.ttf' # 请确保这个路径是正确的华文隶书字体路径
font_size = 200
font = ImageFont.truetype(font_path, font_size)
small_font_size = 40 # 小一点的字号
small_font = ImageFont.truetype(font_path, small_font_size)
# 定义文件夹路径和目标文件名列表
output_folder = os.path.join(path, '05 隶书组合')
if not os.path.exists(output_folder):
os.makedirs(output_folder)
# 遍历每个位置并插入对应的文字
for i, group in enumerate(nested_chars):
# 创建一个500x500的透明背景图
background = Image.new('RGBA', (pic, pic), (255, 255, 255, 0))
draw = ImageDraw.Draw(background)
# 定义插入文字的位置(左上,左下 ,右上,右下)中心点
z1 = pic/4
z2 = pic/4*3
z3 = z2 - bj
positions = [(z2, z1), (z2, z2), (z1, z1), (z1, z2)]
for pos, char in zip(positions, group):
try:
text_width, text_height = draw.textsize(char, font=font)
text_x = pos[0] - text_width // 2
text_y = pos[1] - text_height // 2
draw.text((text_x, text_y), char, font=font, fill=(200, 200, 200)) # 黑色文字
except Exception as e:
print(f"Error processing {char}: {e}")
# 保存图像
output_path = os.path.join(output_folder, f'{image_names[i]}.png')
background.save(output_path)
print(f"Saved {output_path}")
# # 在500x500背景上添加红色边框5磅(靠着边框)
# draw = ImageDraw.Draw(background)
# border_color = (255, 0, 0) # 红色
# border_width = bj # 5磅
# for j in range(border_width):
# draw.rectangle([j, j, pic-j, pic-j], outline=border_color)
# # 创建绘图对象(与边框有距离)考虑不名字带框,不吉利,隶书字体就不用加框了
# draw = ImageDraw.Draw(background)
# # 定义边框颜色和宽度
# border_color = (255, 0, 0) # 红色
# border_width = int(bj/2) # 10磅
# margin = int(bj/2) # 边距10磅
# # 画红色边框
# for j in range(border_width):
# draw.rectangle([j + margin, j + margin, pic - j - margin, pic - j - margin], outline=border_color)
# # 在中心点画一个20磅直径的空心圆,线条是黑色5磅
# center_circle_radius = 30 # 半径为10像素,直径为20磅
# center_circle_thickness = 5 # 线条宽度为5磅
# draw.ellipse([(pic/2 - center_circle_radius, pic/2 - center_circle_radius), (pic/2 + center_circle_radius, pic/2+ center_circle_radius)], outline='black', width=center_circle_thickness)
# # 在顶部20,250的地方画一个20磅直径的空心圆,线条是黑色5磅,里面加入数字
top_circle_radius = 30 # 半径为10像素,直径为20磅
top_circle_thickness = 5 # 线条宽度为5磅
draw.ellipse([(250 - top_circle_radius, 40 - top_circle_radius), (250 + top_circle_radius, 40 + top_circle_radius)], outline='black', width=top_circle_thickness)
# 在顶部圆中添加数字,字号小一点
if int(i + 1)<10: # 1个数,数字局中需要向右移动
draw.text((250+5 - top_circle_radius // 2,33 - top_circle_radius // 2), str(i + 1), font=small_font, fill=(0, 0, 0))
elif 10<=int(i + 1)<20: # 1X数,数字局中需要向右移动
draw.text((250-7 - top_circle_radius // 2,33 - top_circle_radius // 2), str(i + 1), font=small_font, fill=(0, 0, 0))
else: # 2X数,数字局中需要向左移动
draw.text((250-5 - top_circle_radius // 2,33 - top_circle_radius // 2), str(i + 1), font=small_font, fill=(0, 0, 0))
# draw.ellipse([(250 - center_circle_radius, 250 - center_circle_radius), (30 + center_circle_radius, pic/2+ center_circle_radius)], outline='black', width=center_circle_thickness)
# 在图片中心左侧画一个正方形。20边长,边框线黑色5磅,填充灰色。
square_size = 20
square_thickness = 5
left_square_x = pic/2 - square_size // 2 - 100 // 2 - square_size // 2
left_square_y = pic/2 - square_size // 2
draw.rectangle([(left_square_x, left_square_y), (left_square_x + square_size*2), left_square_y + square_size*3], width=square_thickness, fill='lightgray')
# 在图片中心右侧画一个正方形。20边长,边框线黑色5磅,填充灰色。
right_square_x = pic/2 + square_size // 2 + 100 // 2 - square_size // 2
right_square_y = pic/2 - square_size // 2
draw.rectangle([(right_square_x, right_square_y), (right_square_x + square_size*2, right_square_y + square_size*3)], width=square_thickness, fill='lightgray')
output_path = os.path.join(output_folder, f"{image_names[i]}.png")
background.save(output_path)
print(f"Saved combined image to {output_path}")
# # 把非透明的部分变成黑色
# from PIL import Image
# import os
# # 设置文件夹路径
# folder_path = output_folder
# new_path = path + r'\03 黑色左右旋转'
# os.makedirs(new_path, exist_ok=True)
# # 遍历文件夹中的所有文件
# for filename in os.listdir(folder_path):
# if filename.endswith('.png'):
# # 拼接完整的文件路径
# file_path = os.path.join(folder_path, filename)
# # 打开图片
# with Image.open(file_path) as img:
# # 确保图片是RGBA模式(即包含透明度通道)
# if img.mode != 'RGBA':
# img = img.convert('RGBA')
# # 加载图片数据
# data = img.getdata()
# # 创建一个新的数据列表
# new_data = []
# # 遍历每个像素
# for item in data:
# # 如果像素不是完全透明的,则将其设置为黑色
# if item[3] != 0:
# new_data.append((0, 0, 0, item[3]))
# else:
# new_data.append(item)
# # 更新图片数据
# img.putdata(new_data)
# # 保存修改后的图片到新路径
# new_file_path = os.path.join(new_path, filename)
# img.save(new_file_path)
# # 左右翻转
# from PIL import Image
# import os
# # 设置文件夹路径
# source_folder = new_path
# destination_folder = path+r'\04 水平翻转'
# # 创建目标文件夹(如果不存在)
# os.makedirs(destination_folder, exist_ok=True)
# # 遍历源文件夹中的所有文件
# for filename in os.listdir(source_folder):
# if filename.endswith('.png') or filename.endswith('.jpg') or filename.endswith('.jpeg'):
# # 拼接完整的文件路径
# file_path = os.path.join(source_folder, filename)
# # 打开图片
# with Image.open(file_path) as img:
# # 左右翻转图片
# flipped_img = img.transpose(Image.FLIP_LEFT_RIGHT)
# # 拼接新的目标文件路径
# new_file_path = os.path.join(destination_folder, filename)
# # 保存翻转后的图片
# flipped_img.save(new_file_path)
# print("所有图片已成功左右翻转并保存到新的文件夹中。")

灰色隶书汉字,让幼儿描图
黑色学号圆圈,便于分发和了解摆放方向(数字在顶部)
中间灰色方块:黏贴印章按钮(提手)便于取放

最后的图片合并
'''
活字拼合:把九叠篆图片(正)和隶书文字(旋转180度)拼图,制作学具
星火讯飞、阿夏
20250131
'''
import os,time
from docx import Document
from PIL import Image
from docx.enum.table import WD_CELL_VERTICAL_ALIGNMENT
from PyPDF2 import PdfFileMerger
from docx.shared import Cm # Import Cm here
import pikepdf
# 定义文件夹路径
path = r'C:\Users\jg2yXRZ\OneDrive\桌面\20250130篆章九叠篆'
folder_123 = path + r'\04 黑色文字(镜像)'
folder_234 = path + r'\05 隶书组合'
temp_folder = path + r'\零时'
output_folder = os.path.dirname(folder_123)
os.makedirs(temp_folder, exist_ok=True)
# 读取123文件夹下的图片路径
images_123 = [os.path.join(folder_123, f) for f in os.listdir(folder_123) if f.endswith(('png', 'jpg', 'jpeg'))]
while len(images_123) % 3 != 0:
images_123.append("")
print(len(images_123))
# 读取234文件夹下的图片路径
images_234 = [os.path.join(folder_234, f) for f in os.listdir(folder_234) if f.endswith(('png', 'jpg', 'jpeg'))]
while len(images_234) % 3 != 0:
images_234.append("")
print(len(images_234))
# 打开现有的Word文档模板
doc_template_path = os.path.join(path, r'20250131印章.docx')
doc_template = Document(doc_template_path)
# 获取文档中的表格(假设文档中已经有一个表格)
tables = doc_template.tables
if len(tables) < 1:
raise ValueError("The document does not contain enough tables to insert images.")
# 创建多个文档,每个文档插入一组图片
num_docs = len(images_123) // 3
for i in range(num_docs):
doc = Document(doc_template_path)
table1 = doc.tables[0]
# 添加第一行图片到第一张表格的第一行
for j in range(3):
cell = table1.cell(0, j)
image_path = images_123[i * 3 + j] if (i * 3 + j) < len(images_123) else ""
if image_path:
run = cell.paragraphs[0].add_run()
run.add_picture(image_path, width=Cm(9.5), height=Cm(9.5))
cell.vertical_alignment = WD_CELL_VERTICAL_ALIGNMENT.CENTER
# 添加第三行图片到第一张表格的第三行(旋转180度)
for j in range(3):
cell = table1.cell(2, j)
image_path = images_234[i * 3 + j] if (i * 3 + j) < len(images_234) else ""
if image_path:
# 打开图片并旋转180度
with Image.open(image_path) as img:
img = img.rotate(180, expand=True)
img_path = os.path.join(temp_folder, f"temp_{i}_{j}.png")
img.save(img_path)
run = cell.paragraphs[0].add_run()
run.add_picture(img_path, width=Cm(9.5), height=Cm(9.5))
cell.vertical_alignment = WD_CELL_VERTICAL_ALIGNMENT.CENTER
# 删除临时文件
os.remove(img_path)
# 保存修改后的文档
doc_path = os.path.join(temp_folder, f"{i+1:02}.docx")
doc.save(doc_path)
import os
from docx import Document
from reportlab.pdfgen import canvas
from PyPDF2 import PdfFileMerger
from docx2pdf import convert
# 获取所有docx文件
docx_files = [f for f in os.listdir(temp_folder) if f.endswith('.docx')]
# 获取所有docx文件
# 将每个docx文件转换为PDF
for docx_file in docx_files:
doc_path = os.path.join(temp_folder, docx_file)
pdf_path = os.path.join(temp_folder, docx_file.replace('.docx', '.pdf'))
convert(doc_path, pdf_path)
time.sleep(1)
# 合并所有的PDF文件
# 获取所有生成的PDF文件
pdf_files = [f for f in os.listdir(temp_folder) if f.endswith('.pdf')]
# 创建PdfFileMerger对象
merger = PdfFileMerger()
# 将所有PDF文件添加到合并器中
for pdf_file in pdf_files:
pdf_path = os.path.join(temp_folder, pdf_file)
merger.append(pdf_path)
# 输出合并后的PDF文件
output_pdf_path = os.path.join(path, f'(范例)九叠篆篆章_中2班_幼儿姓名{len(images_123)}人{int(len(images_123)/3)}张.pdf')
# output_pdf_path = os.path.join(path, f'九叠篆篆章_中2班_幼儿姓名{len(images_123)}人{int(len(images_123)/3)}张.pdf')
merger.write(output_pdf_path)
merger.close()
print(f"所有PDF文件已合并到 {output_pdf_path}")
import shutil
shutil.rmtree(temp_folder)



这样镜像的九叠篆就和下面倒置的隶书字上下对称了。
接下去考虑用什么板材做印章?(快递盒纸板?KT版?)
印泥最大有14.5CM 。我设计的是9.5CM,买个小号的就行。
