MLM之MiniCPM-o:MiniCPM-o的简介(涉及MiniCPM-o 2.6和MiniCPM-V 2.6)、安装和使用方法、案例应用之详细攻略
MLM之MiniCPM-o:MiniCPM-o的简介(涉及MiniCPM-o 2.6和MiniCPM-V 2.6)、安装和使用方法、案例应用之详细攻略
目录
MiniCPM-o的简介
0、更新日志
1、MiniCPM-o系列模型特点
MiniCPM-o 2.6 的主要特点
MiniCPM-V 2.6的主要特点
2、MiniCPM-o系列模型架构
MiniCPM-o 2.6
MiniCPM-V 2.6
3、MiniCPM-o系列模型评估
MiniCPM-o 2.6
MiniCPM-V 2.6
MiniCPM-o的安装和使用方法
1、安装
2、使用方法
T1、Online Demo
T2、本地 WebUI Demo
实时流式视频/语音通话demo:
启动model server:
启动web server:
浏览器打开https://localhost:8088/
Chatbot图文对话demo:
3、推理
模型库
多轮对话
多卡推理
Mac 推理
基于 llama.cpp、ollama、vLLM 的高效推理
4、微调
简易微调
使用 Align-Anything
使用 LLaMA-Factory
使用 SWIFT 框架
MiniCPM-o的案例应用
MiniCPM-o 2.6的典型示例
MiniCPM-V 2.6的典型示例
MiniCPM-o的简介
MiniCPM-o是基于MiniCPM-V升级的多模态大型语言模型(MLLM)系列。该系列模型能够以端到端的方式接收图像、视频、文本和音频作为输入,并提供高质量的文本和语音输出。自2024年2月以来,已经发布了6个版本的模型,目标是实现强大的性能和高效的部署。
MiniCPM-o 2.6:MiniCPM-o系列最新也是功能最强大的模型。它拥有80亿参数,在视觉、语音和多模态实时流媒体方面达到了与GPT-4o-202405相当的性能,使其成为开源社区中最通用和高性能的模型之一。新的语音模式支持双语实时语音对话,并可配置语音;还支持情绪/速度/风格控制、端到端语音克隆、角色扮演等有趣的功能。它还改进了MiniCPM-V 2.6的视觉能力,例如强大的OCR能力、可靠的行为、多语言支持和视频理解。由于其优越的token密度,MiniCPM-o 2.6首次支持在iPad等终端设备上的多模态实时流媒体。但是,MiniCPM-o 2.6存在一些局限性,例如语音输出不稳定、重复响应以及Web演示的高延迟。
MiniCPM-V 2.6:MiniCPM-V系列功能最强大的模型。它拥有80亿参数,在单图像、多图像和视频理解方面超越了GPT-4V。在单图像理解方面,它的性能优于GPT-4o mini、Gemini 1.5 Pro和Claude 3.5 Sonnet,并且首次支持在iPad上的实时视频理解。
总而言之,MiniCPM-o系列模型,特别是MiniCPM-o 2.6和MiniCPM-V 2.6,在多模态能力方面展现了强大的性能和效率,并在开源社区中具有重要的影响力。
GitHub地址:https://github.com/OpenBMB/MiniCPM-o
0、更新日志
[2025.01.24] ������ MiniCPM-o 2.6 技术报告已发布! 欢迎点击这里查看.
[2025.01.23] ������ MiniCPM-o 2.6 现在已被北大团队开发的 Align-Anything,一个用于对齐全模态大模型的框架集成,支持 DPO 和 SFT 在视觉和音频模态上的微调。欢迎试用!
[2025.01.19] �� 注意! 我们正在努力将 MiniCPM-o 2.6 的支持合并到 llama.cpp、ollama、vLLM 的官方仓库,但还未完成。请大家暂时先使用我们提供的 fork 来进行部署:llama.cpp、ollama、vllm。 合并完成前,使用官方仓库可能会导致不可预期的问题。
[2025.01.19] ⭐️⭐️⭐️ MiniCPM-o 在 GitHub Trending 上登顶, Hugging Face Trending 上也达到了第二!
[2025.01.17] 我们更新了 MiniCPM-o 2.6 int4 量化版本的使用方式,解决了模型初始化的问题,欢迎点击这里试用!
[2025.01.13] ������ 我们开源了 MiniCPM-o 2.6,该模型视觉、语音和多模态流式能力达到了 GPT-4o-202405 级别,进一步优化了 MiniCPM-V 2.6 的众多亮点能力,还支持了很多有趣的新功能。欢迎试用!
[2024.08.17] ������ llama.cpp 官方仓库正式支持 MiniCPM-V 2.6 啦!点击这里查看各种大小的 GGUF 版本。
[2024.08.06] ������ 我们开源了 MiniCPM-V 2.6,该模型在单图、多图和视频理解方面取得了优于 GPT-4V 的表现。我们还进一步提升了 MiniCPM-Llama3-V 2.5 的多项亮点能力,并首次支持了 iPad 上的实时视频理解。欢迎试用!
[2024.08.03] MiniCPM-Llama3-V 2.5 技术报告已发布!欢迎点击这里查看。
[2024.05.23] ������ MiniCPM-V 在 GitHub Trending 和 Hugging Face Trending 上登顶!MiniCPM-Llama3-V 2.5 Demo 被 Hugging Face 的 Gradio 官方账户推荐,欢迎点击这里体验!
1、MiniCPM-o系列模型特点
MiniCPM-o 2.6 的主要特点
>> 领先的视觉能力:在OpenCompass(8个流行基准的综合评估)上平均得分达到70.2。仅用80亿参数就超过了GPT-4o-202405、Gemini 1.5 Pro和Claude 3.5 Sonnet等广泛使用的专有模型的单图像理解能力;在多图像和视频理解方面也优于GPT-4V和Claude 3.5 Sonnet,并展现出良好的上下文学习能力。
>> 最先进的语音能力:支持英语和中文的双语实时语音对话,并可配置语音。在ASR和STT翻译等音频理解任务上优于GPT-4o-realtime,并在开源社区的语义和声学评估中展现出最先进的语音对话性能。还支持情绪/速度/风格控制、端到端语音克隆、角色扮演等有趣的功能。
>> 强大的多模态实时流媒体能力:MiniCPM-o 2.6可以接收独立于用户查询的连续视频和音频流,并支持实时语音交互。在StreamingBench(实时视频理解、全源(视频和音频)理解和多模态上下文理解的综合基准)上,其性能优于GPT-4o-202408和Claude 3.5 Sonnet,并在开源社区中展现出最先进的性能。
>> 强大的OCR能力和其他能力:继承了MiniCPM-V系列流行的视觉能力,MiniCPM-o 2.6可以处理任意纵横比和最多180万像素的图像。在OCRBench(250亿参数以下的模型)上取得了最先进的性能,超过了GPT-4o-202405等专有模型。基于最新的RLAIF-V和VisCPM技术,它具有可靠的行为,在MMHal-Bench上优于GPT-4o和Claude 3.5 Sonnet,并支持30多种语言的多语言能力。
>> 优越的效率:MiniCPM-o 2.6具有出色的token密度(即编码到每个视觉token中的像素数量)。处理180万像素图像时仅产生640个token,比大多数模型少75%。这直接提高了推理速度、首个token延迟、内存使用率和功耗。因此,MiniCPM-o 2.6能够高效地支持iPad等终端设备上的多模态实时流媒体。
>> 易于使用:支持llama.cpp(在本地设备上进行高效的CPU推理)、int4和GGUF格式量化模型、vLLM(高吞吐量和内存高效的推理)、LLaMA-Factory(在新的领域和任务上进行微调)、本地WebUI演示和在线Web演示。
MiniCPM-V 2.6的主要特点
>> 领先的性能:在最新的OpenCompass版本(8个流行基准的综合评估)上平均得分达到65.2。仅用80亿参数就超过了GPT-4o mini、GPT-4V、Gemini 1.5 Pro和Claude 3.5 Sonnet等广泛使用的专有模型的单图像理解能力。
>> 多图像理解和上下文学习:可以对多张图像进行对话和推理,在Mantis-Eval、BLINK、Mathverse mv和Sciverse mv等流行的多图像基准测试中取得了最先进的性能,并展现出良好的上下文学习能力。
>> 视频理解:可以接收视频输入,进行对话并为时空信息提供密集的字幕。在Video-MME(有/无字幕)上优于GPT-4V、Claude 3.5 Sonnet和LLaVA-NeXT-Video-34B。
>> 强大的OCR能力和其他能力:可以处理任意纵横比和最多180万像素的图像。在OCRBench上取得了最先进的性能,超过了GPT-4o、GPT-4V和Gemini 1.5 Pro等专有模型。基于最新的RLAIF-V和VisCPM技术,它具有可靠的行为,在Object HalBench上的幻觉率明显低于GPT-4o和GPT-4V,并支持英语、中文、德语、法语、意大利语、韩语等多种语言。
>> 优越的效率:具有出色的token密度。处理180万像素图像时仅产生640个token,比大多数模型少75%。这直接提高了推理速度、首个token延迟、内存使用率和功耗。因此,MiniCPM-V 2.6能够高效地支持iPad等终端设备上的实时视频理解。
>> 易于使用:支持llama.cpp和ollama(在本地设备上进行高效的CPU推理)、int4和GGUF格式量化模型、vLLM(高吞吐量和内存高效的推理)、Gradio(快速搭建本地WebUI演示)和在线Web演示。
2、MiniCPM-o系列模型架构
MiniCPM-o 2.6

MiniCPM-o 2.6采用端到端的全模态架构。不同的模态编码器/解码器以端到端的方式连接和训练,以充分利用丰富的多模态知识。模型以端到端的方式进行训练,只使用交叉熵损失。它还设计了一种多模态系统提示,包括传统的文本系统提示和新的音频系统提示来确定助手的语音,从而实现推理时的灵活语音配置,并促进端到端语音克隆和基于描述的语音创建。
>> 端到端全模态架构:通过端到端的方式连接和训练不同模态的编/解码模块以充分利用丰富的多模态知识。模型完全使用 CE 损失端到端训练。
>> 全模态流式机制: (1) 我们将不同模态的离线编/解码器改造为适用于流式输入/输出的在线模块。 (2) 我们针对大语言模型基座设计了时分复用的全模态流式信息处理机制,将平行的不同模态的信息流拆分重组为周期性时间片序列。
>> 可配置的声音方案:我们设计了新的多模态系统提示,包含传统文本系统提示词,和用于指定模型声音的语音系统提示词。模型可在推理时灵活地通过文字或语音样例控制声音风格,并支持端到端声音克隆和音色创建等高级能力。
MiniCPM-V 2.6
MiniCPM-V 2.6的架构细节未在提供的文本中详细说明,但它基于SigLip-400M和Qwen2-7B构建,总参数为80亿。
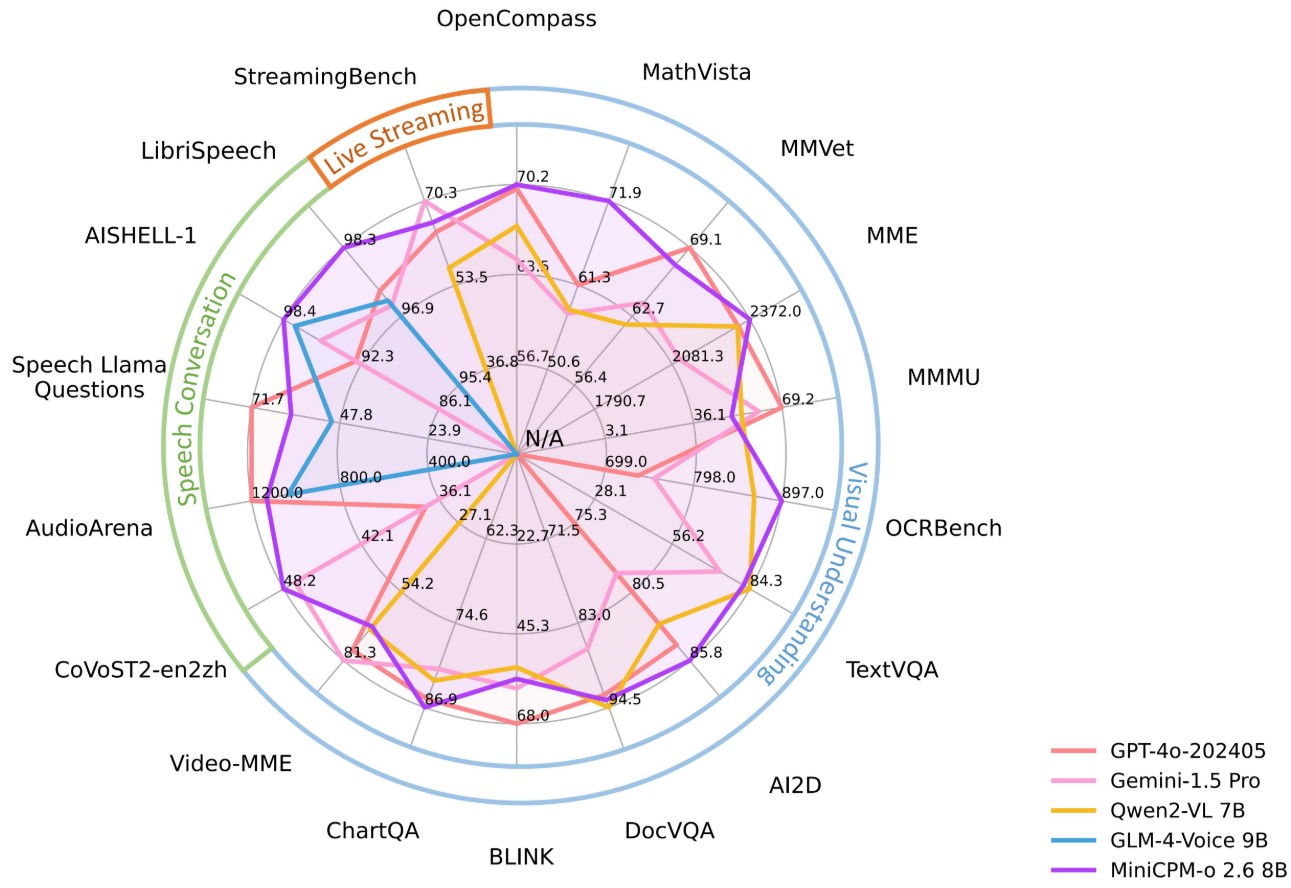
3、MiniCPM-o系列模型评估
MiniCPM-o 2.6和MiniCPM-V 2.6在多个基准测试中都取得了领先的性能,涵盖了图像理解、多图像理解、视频理解、音频理解、语音生成、端到端语音克隆和多模态实时流媒体等方面。 这些评估结果与GPT-4o、GPT-4V、Gemini 1.5 Pro和Claude 3.5 Sonnet等专有模型进行了比较。
MiniCPM-o 2.6
MiniCPM-V 2.6

MiniCPM-o的安装和使用方法
1、安装
使用pip install -r requirements_o2.6.txt安装MiniCPM-o 2.6所需的依赖项。
MiniCPM-V 2.6的依赖项类似,可能需要安装不同的requirements文件。
2、使用方法
大量的Python代码示例,涵盖了多轮对话、多图像对话、少样本学习、视频对话、语音对话(包括模仿、可配置语音的通用语音对话、作为AI助手的语音对话、指令到语音、语音克隆)、各种音频理解任务和多模态实时流媒体等场景。 这些示例代码展示了如何使用transformers库加载模型,并使用模型的chat方法进行推理。 对于实时语音/视频通话演示和聊天机器人演示,需要启动模型服务器和Web服务器。 此外,还提供了在多个GPU和Mac上进行推理的示例。 项目还支持使用llama.cpp、ollama和vLLM进行高效推理,以及使用Hugging Face、Align-Anything、LLaMA-Factory和SWIFT框架进行微调。
我们提供由 Hugging Face Gradio 支持的在线和本地 Demo。Gradio 是目前最流行的模型部署框架,支持流式输出、进度条、process bars 和其他常用功能。
T1、Online Demo
欢迎试用 Online Demo: MiniCPM-V 2.6 | MiniCPM-Llama3-V 2.5 | MiniCPM-V 2.0 。
T2、本地 WebUI Demo
您可以使用以下命令轻松构建自己的本地 WebUI Demo。更详细的部署教程请参考文档。
实时流式视频/语音通话demo:
启动model server:
pip install -r requirements_o2.6.txt
python web_demos/minicpm-o_2.6/model_server.py请确保 transformers==4.44.2,其他版本目前可能会有兼容性问题,我们正在解决。 如果你使用的低版本的 Pytorch,你可能会遇到这个错误"weight_norm_fwd_first_dim_kernel" not implemented for 'BFloat16', 请在模型初始化的时候添加 self.minicpmo_model.tts.float()
启动web server:
# Make sure Node and PNPM is installed.
sudo apt-get update
sudo apt-get install nodejs npm
npm install -g pnpm
cd web_demos/minicpm-o_2.6/web_server
# 为https创建自签名证书, 要申请浏览器摄像头和麦克风权限须启动https.
bash ./make_ssl_cert.sh # output key.pem and cert.pem
pnpm install # install requirements
pnpm run dev # start server浏览器打开https://localhost:8088/
开始体验实时流式视频/语音通话.
Chatbot图文对话demo:
pip install -r requirements_o2.6.txt
python web_demos/minicpm-o_2.6/chatbot_web_demo_o2.6.py浏览器打开http://localhost:8000/,开始体验图文对话Chatbot.
3、推理
模型库
| 模型 | 设备 | 资源 | 简介 | 下载链接 |
|---|---|---|---|---|
| MiniCPM-o 2.6 | GPU | 18 GB | 最新版本,提供端侧 GPT-4o 级的视觉、语音、多模态流式交互能力。 | 🤗 |
| MiniCPM-o 2.6 gguf | CPU | 8 GB | gguf 版本,更低的内存占用和更高的推理效率。 | 🤗 |
| MiniCPM-o 2.6 int4 | GPU | 9 GB | int4量化版,更低显存占用。 | 🤗 |
| MiniCPM-V 2.6 | GPU | 17 GB | 提供出色的端侧单图、多图、视频理解能力。 | 🤗 |
| MiniCPM-V 2.6 gguf | CPU | 6 GB | gguf 版本,更低的内存占用和更高的推理效率。 | 🤗 |
| MiniCPM-V 2.6 int4 | GPU | 7 GB | int4量化版,更低显存占用。 | 🤗 |
更多历史版本模型
多轮对话
请确保 transformers==4.44.2,其他版本目前可能会有兼容性问题
pip install -r requirements_o2.6.txtimport torch
from PIL import Image
from transformers import AutoModel, AutoTokenizer
torch.manual_seed(100)
model = AutoModel.from_pretrained('openbmb/MiniCPM-o-2_6', trust_remote_code=True,
attn_implementation='sdpa', torch_dtype=torch.bfloat16) # sdpa or flash_attention_2, no eager
model = model.eval().cuda()
tokenizer = AutoTokenizer.from_pretrained('openbmb/MiniCPM-o-2_6', trust_remote_code=True)
image = Image.open('./assets/minicpmo2_6/show_demo.jpg').convert('RGB')
# First round chat
question = "What is the landform in the picture?"
msgs = [{'role': 'user', 'content': [image, question]}]
answer = model.chat(
msgs=msgs,
tokenizer=tokenizer
)
print(answer)
# Second round chat, pass history context of multi-turn conversation
msgs.append({"role": "assistant", "content": [answer]})
msgs.append({"role": "user", "content": ["What should I pay attention to when traveling here?"]})
answer = model.chat(
msgs=msgs,
tokenizer=tokenizer
)
print(answer)多卡推理
您可以通过将模型的层分布在多个低显存显卡(12 GB 或 16 GB)上,运行 MiniCPM-Llama3-V 2.5。请查看该教程,详细了解如何使用多张低显存显卡载入模型并进行推理。
Mac 推理
点击查看 MiniCPM-Llama3-V 2.5 / MiniCPM-V 2.0 基于Mac MPS运行 (Apple silicon 或 AMD GPUs)的示例。
# test.py Need more than 16GB memory to run.
import torch
from PIL import Image
from transformers import AutoModel, AutoTokenizer
model = AutoModel.from_pretrained('openbmb/MiniCPM-Llama3-V-2_5', trust_remote_code=True, low_cpu_mem_usage=True)
model = model.to(device='mps')
tokenizer = AutoTokenizer.from_pretrained('openbmb/MiniCPM-Llama3-V-2_5', trust_remote_code=True)
model.eval()
image = Image.open('./assets/hk_OCR.jpg').convert('RGB')
question = 'Where is this photo taken?'
msgs = [{'role': 'user', 'content': question}]
answer, context, _ = model.chat(
image=image,
msgs=msgs,
context=None,
tokenizer=tokenizer,
sampling=True
)
print(answer)基于 llama.cpp、ollama、vLLM 的高效推理
llama.cpp 用法请参考我们的fork llama.cpp, 在iPad上可以支持 16~18 token/s 的流畅推理(测试环境:iPad Pro + M4)。
ollama 用法请参考我们的fork ollama, 在iPad上可以支持 16~18 token/s 的流畅推理(测试环境:iPad Pro + M4)。
点击查看, vLLM 现已官方支持MiniCPM-V 2.6、MiniCPM-Llama3-V 2.5 和 MiniCPM-V 2.0,MiniCPM-o 2.6 模型也可以临时用我们的 fork 仓库运行。
4、微调
简易微调
我们支持使用 Huggingface Transformers 库简易地微调 MiniCPM-o 2.6、MiniCPM-V 2.6、MiniCPM-Llama3-V 2.5 和 MiniCPM-V 2.0 模型。
使用 Align-Anything
我们支持使用北大团队开发的 Align-Anything 框架微调 MiniCPM-o 系列模型,同时支持 DPO 和 SFT 在视觉和音频模态上的微调。Align-Anything 是一个用于对齐全模态大模型的高度可扩展框架,开源了数据集、模型和评测。它支持了 30+ 开源基准,40+ 模型,以及包含SFT、SimPO、RLHF在内的多种算法,并提供了 30+ 直接可运行的脚本,适合初学者快速上手。
最佳实践: MiniCPM-o 2.6.
使用 LLaMA-Factory
我们支持使用 LLaMA-Factory 微调 MiniCPM-o 2.6 和 MiniCPM-V 2.6。LLaMA-Factory 提供了一种灵活定制 200 多个大型语言模型(LLM)微调(Lora/Full/Qlora)解决方案,无需编写代码,通过内置的 Web 用户界面 LLaMABoard 即可实现训练/推理/评估。它支持多种训练方法,如 sft/ppo/dpo/kto,并且还支持如 Galore/BAdam/LLaMA-Pro/Pissa/LongLoRA 等高级算法。
最佳实践: MiniCPM-o 2.6 | MiniCPM-V 2.6.
使用 SWIFT 框架
我们支持使用 SWIFT 框架微调 MiniCPM-V 系列模型。SWIFT 支持近 200 种大语言模型和多模态大模型的训练、推理、评测和部署。支持 PEFT 提供的轻量训练方案和完整的 Adapters 库支持的最新训练技术如 NEFTune、LoRA+、LLaMA-PRO 等。
参考文档:MiniCPM-V 1.0,MiniCPM-V 2.0 MiniCPM-V 2.6.
MiniCPM-o的案例应用
MiniCPM-o 2.6和MiniCPM-V 2.6在iPad等终端设备上的演示视频,展示了其在多模态实时流媒体和视频理解方面的能力。 代码示例中也包含了各种应用场景,例如图像问答、视频描述、语音转录、语音合成和多模态交互等。
MiniCPM-o 2.6的典型示例


MiniCPM-V 2.6的典型示例
