ArrayBlockingQueue源码分析
文章目录
- 概述
- 一、ArrayBlockingQueue
- 1.1、put
- 1.2、take
- 1.3、小结
概述
阻塞队列,是针对一般而言的队列数据结构,增加了阻塞的特性:
- 作为
生产者方的线程,向队列中存放元素时,如果队列已满,则生产者陷入阻塞,并且唤醒消费者去进行消息的消费。 - 作为
消费者方的线程,从队列中获取元素时,如果队列已空,则消费者陷入阻塞,并且唤醒生产者去进行消息的生产。
完美契合了生产者-消费者模型,并且阻塞队列作为第三方进行了两者间的解耦操作。
继承体系:
 Collection是List和Set集合的顶级接口,定义了集合共有的行为
Collection是List和Set集合的顶级接口,定义了集合共有的行为
 Queue接口继承了Collection,在其中增加了作为队列的特有方法
Queue接口继承了Collection,在其中增加了作为队列的特有方法
- offer(E e):如果无法插入目标元素,就返回false。

- remove():删除队列的头部元素,如果队列为空,则抛出异常。

- poll():删除队列的头部元素,如果队列为空,就返回null。

- element():查找队列的头部元素,如果队列为空,就抛出异常。

- peek():查找队列的头部元素,如果队列为空,就返回null。

 BlockingQueue是一个接口,定义了所有阻塞队列的规范,其继承了父类的add,offer,remove,contains,并增加了一些作为阻塞队列特有的方法
BlockingQueue是一个接口,定义了所有阻塞队列的规范,其继承了父类的add,offer,remove,contains,并增加了一些作为阻塞队列特有的方法
- put(E e):放入元素,队列已满则会陷入阻塞。

- offer(E e, long timeout, TimeUnit unit):放入元素,队列已满则会陷入阻塞,可以自己设置阻塞时间。

- take():元素出队,队列已空则会阻塞

- poll(long timeout, TimeUnit unit):元素出队,队列已空则会阻塞,可自己设定阻塞等待时间。

本篇主要介绍ArrayBlockingQueue阻塞队列的实现
一、ArrayBlockingQueue
ArrayBlockingQueue是有界的阻塞队列,有界体现在构造ArrayBlockingQueue时,必须设置初始大小,并且ArrayBlockingQueue不支持扩容。
 ArrayBlockingQueue的底层是
ArrayBlockingQueue的底层是数组实现,并且存取元素各维护一个指针。
 ArrayBlockingQueue的读,写共用一把锁,这就意味着不同线程间的读,写都是互斥的,必须等到某个线程释放锁后,其他线程才可以继续操作。
ArrayBlockingQueue的读,写共用一把锁,这就意味着不同线程间的读,写都是互斥的,必须等到某个线程释放锁后,其他线程才可以继续操作。
 这里重点看下它的入队put和出队take的源码分析。
这里重点看下它的入队put和出队take的源码分析。
1.1、put
public void put(E e) throws InterruptedException {
//保证入队的元素不能为Null
checkNotNull(e);
//获取到锁
final ReentrantLock lock = this.lock;
//当前线程记为T,如果有A线程给T线程设置了打断标记,那么T线程在运行到这段代码时会直接抛出异常(一)
lock.lockInterruptibly();
try {
//队列的元素已满
while (count == items.length){
//生产者陷入阻塞
notFull.await();
}
//否则入队(二)
enqueue(e);
} finally {
lock.unlock();
}
}
//一、java.util.concurrent.locks.AbstractQueuedSynchronizer#acquireInterruptibly
public final void acquireInterruptibly(int arg)
throws InterruptedException {
if (Thread.interrupted())
throw new InterruptedException();
if (!tryAcquire(arg))
doAcquireInterruptibly(arg);
}
//二
private void enqueue(E x) {
// assert lock.getHoldCount() == 1;
// assert items[putIndex] == null;
//获取当前的数组
final Object[] items = this.items;
//数组的putIndex指针下标赋值给新的元素
items[putIndex] = x;
//putIndex指针下标 + 1 后 和 数组的length 相等,代表着加入了新元素后队列刚好满了。
//为什么要++i?因为数组的最大下标 = length - 1
if (++putIndex == items.length){
//将写指针下标设置为数组的第0个位置
putIndex = 0;
}
//数组的长度+1
count++;
//唤醒消费者进行消费
notEmpty.signal();
}
1.2、take
public E take() throws InterruptedException {
//获取到锁
final ReentrantLock lock = this.lock;
//和put同理
lock.lockInterruptibly();
try {
//队列已空
while (count == 0){
//消费者阻塞
notEmpty.await();
}
//出队(一)
return dequeue();
} finally {
lock.unlock();
}
}
//一
private E dequeue() {
// assert lock.getHoldCount() == 1;
// assert items[takeIndex] != null;
//获取当前的数组
final Object[] items = this.items;
@SuppressWarnings("unchecked")
//从数组的读指针下标位置取出元素
E x = (E) items[takeIndex];
//数组的读指针下标位置设置为null
items[takeIndex] = null;
//数组中的元素刚好读取完成
if (++takeIndex == items.length){
//读指针设置为0的位置
takeIndex = 0;
}
//数组元素-1
count--;
if (itrs != null)
itrs.elementDequeued();
//唤醒生产者线程进行生产
notFull.signal();
return x;
}
1.3、小结
take和put的过程,可以如图所示,假设队列目前的状况如图,为什么写指针在数组下标为5的位置?那是因为在下标为4的30元素被put时,进行if (++putIndex == items.length)判断,putIndex 变成了5:
 在调用put方法时:
在调用put方法时:
 再次执行到if (++putIndex == items.length)代码,5 + 1 = 6(数组的长度),故putIndex重置为0:
再次执行到if (++putIndex == items.length)代码,5 + 1 = 6(数组的长度),故putIndex重置为0:

假设前5个元素已经被获取,在调用take方法时:(为何读指针此时指向下标5?和写指针同理)
 取出下标5的元素,并且置空。
取出下标5的元素,并且置空。
 再次执行到if (++takeIndex== items.length)代码,5 + 1 = 6(数组的长度),故takeIndex重置为0:
再次执行到if (++takeIndex== items.length)代码,5 + 1 = 6(数组的长度),故takeIndex重置为0: 还有一点值得注意,为什么count方法没有使用线程更加安全的原子整数?
还有一点值得注意,为什么count方法没有使用线程更加安全的原子整数?
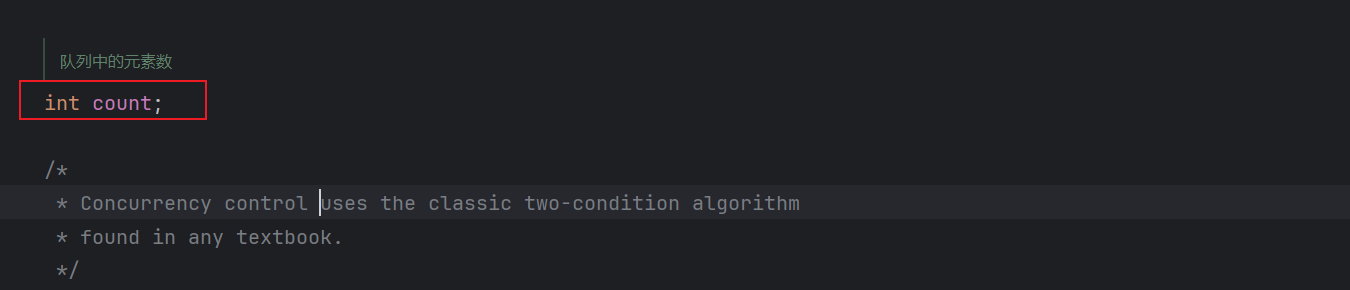 原因在于获取ArrayBlockingQueue的size的方法中,专门有加锁,这样也就导致ArrayBlockingQueue的并发度不高。(获取size还要专门加锁)
原因在于获取ArrayBlockingQueue的size的方法中,专门有加锁,这样也就导致ArrayBlockingQueue的并发度不高。(获取size还要专门加锁)
