大模型微调技术总结及使用GPU对VisualGLM-6B进行高效微调
1. 概述
在深度学习中,微调(Fine-tuning)是一种重要的技术,用于改进预训练模型的性能。在预训练模型的基础上,针对特定任务(如文本分类、机器翻译、情感分析等),使用相对较小的有监督数据集对模型进行进一步训练的过程。预训练模型学习到了语言的一般规律,如语法、语义等知识,通过微调,模型可以利用预训练过程中学习到的知识,并结合特定任务的数据,在该任务上达到更好的准确率、召回率等性能指标。
在微调过程中,通常会冻结预训练模型的一部分参数,只训练模型的顶层或特定层,以便模型能够针对新任务进行调整。所需的Fine-tuning量取决于预训练语料库和任务特定语料库之间的相似性。如果两者相似,可能只需要少量的Fine tuning。如果两者不相似,则可能需要更多的Fine tuning。

为什么需要微调?
- 微调的价值:可以帮助我们更好地利用预训练模型的知识,加速和优化新任务的训练过程,同时减少对新数据的需求和降低训练成本。
- 减少对新数据的需求:从头开始训练一个大型神经网络通常需要大量的数据和计算资源,而在实际应用中,我们可能只有有限的数据集。通过微调预训练模型,我们可以利用预训练模型已经学到的知识,减少对新数据的需求,从而在小数据集上获得更好的性能。
- 降低训练成本:由于我们只需要调整预训练模型的部分参数,而不是从头开始训练整个模型,因此可以大大减少训练时间和所需的计算资源。这使得微调成为一种高效且经济的解决方案,尤其适用于资源有限的环境。
2. 微调的分类
-
全微调(Full Fine-tuning):这是一种比较直接的方法,使用特定任务的数据集对整个预训练模型的所有参数进行微调,适用于任务和预训练模型之间存在较大差异的情况,或任务需要模型具有高度灵活性和自适应能力的情况。这种方法需要较大的计算资源和时间,但可以获得更好的性能。也可能会出现 “灾难性遗忘” 的问题,即模型在微调过程中过度拟合特定任务的数据,而忘记了预训练过程中学习到的一些通用知识。
-
参数高效微调(Parameter-Efficient Fine-Tuning, PEFT):为了解决全微调的问题,参数高效微调方法应运而生。通过微调少量参数来达到接近微调全量参数的效果,使得在GPU资源不足的情况下也可以微调大模型。PEFT技术包括LoRA、QLoRA、适配器调整(Adapter Tuning)、前缀调整(Prefix Tuning)、提示调整(Prompt Tuning)及P-Tuning v2等多种方法。

3. 常见的微调技术
3.1 LoRA
LoRA(Low-Rank Adaptation)由微软在2021年提出,通过在模型的关键层次中引入小型、低秩的矩阵来实现模型行为的微调,而无需对整个模型结构进行大幅度修改。简单来说,Lora的本质就是对所有权重矩阵套了一层“壳”,这些壳会对原来的预训练权重矩阵进行加减使其更加适合下游任务,即实现微调。他的假设前提是预训练模型具有低的"内在维度",因此认为在模型适配下游任务的过程中,权重更新也应该具有低的“内在秩”。通常只需要全模型微调的 10%-20% 的计算资源。因此在资源受限的环境下,LoRA 可以轻松实现大规模语言模型的微调。LoRA 通常与 Transformer 架构结合使用,特别是在自注意力模块和前馈神经网络中。在实际应用中,LoRA 可以与其他参数高效微调方法(如适配器调整、前缀调整等)结合使用,以进一步提高微调效果。
具体来说,权重矩阵会被分解成两个小矩阵的乘积。假设原始权重矩阵为 W,尺寸为 d×d。LoRA 会将其更新为 W ′ =W+ΔW,其中 ΔW=A×B,A 和 B 是两个低秩矩阵。矩阵 A 用于降维(从大维度到小维度),矩阵 B 用于升维(从小维度回到大维度),B 和 A 的尺寸分别为 d×r 和 r×d,而 r≪d。这种方法在训练时只更新 A 和 B,而原始权重矩阵 W 保持不变,从而大大减少了训练参数量,提高了计算效率。矩阵 A 会使用高斯初始化,矩阵 B 则初始化为零矩阵。这样在训练初期,新增的通路对模型的影响为零,训练开始时不会对原有模型的行为产生影响。

3.2 QLoRA
2023 年 5 月 23 日 QLoRA 的推出,它代表具有低秩适配器的量化 LLM,这是一种能够以最小的内存使用量高效微调大型语言模型的方法。QLoRA 不会从头开始重新训练整个模型,而是向模型添加少量新参数,这些参数专门针对新任务进行训练,同时将原始预训练语言模型参数保持在 4 位量化状态。
QLoRA 背后的关键理念是通过减少内存使用量来提高 LLM 的效率,同时保持可靠的性能。它通过几个步骤实现这一目标:引入 4 位量化、一种称为 4 位 NormalFloat (NF4) 的新数据类型、双量化和分页优化器。
(1)4 位量化
传统的深度学习模型通常使用 32 位浮点数(float32)或 16 位浮点数(float16)进行计算。这些数据类型占用较多内存,尤其是在处理大型语言模型时,内存需求会非常高。而 QLoRA 引入了 4 位量化,即将模型的权重和激活值从 32 位或 16 位浮点数压缩到 4 位。这种量化可以显著减少内存占用,从而提高模型的效率。
(2)4位NormalFloat (NF4) 数据类型
在量化过程中,选择合适的数据类型至关重要。不同的数据类型在精度和内存占用之间需要权衡。NF4 是一种针对正态分布权重优化的 4 位数据类型。与其他4位数据类型(如INT4)相比,NF4 在实验中表现出更好的性能,能够在量化后保持较高的精度。
(3)双量化
即使使用了 4 位量化,量化过程中仍然会引入一些量化常数,这些常数本身也需要占用内存。因此,QLoRA 通过进一步量化这些量化常数,进一步减少内存占用。
(4)分页优化器
在训练大型模型时,梯度检查点(gradient checkpointing)是一种常用的技巧,用于减少内存占用。然而,这种方法在某些情况下会导致内存峰值问题。QLoRA 通过将模型参数划分为多个小组,并分别处理每个小组,从而避免了梯度检查点期间的内存峰值问题。此外,它还使用NVIDIA统一内存(Unified Memory)来管理内存页面,进一步优化内存使用。

3.3 Adapter Tuning
Adapter Tuning 方法由 Houlsby N 等人在2019年提出,它涉及将称为适配器的小型神经网络模块整合到Transformer模型中,这些适配器模块作为每个Transformer层内的附加组件。针对每一个 Transformer 层,增加了两个 Adapter 结构(分别是多头注意力的投影之后和第二个 feed-forward 层之后),在训练时,固定住原来预训练模型的参数不变,只对新增的 Adapter 结构和 Layer Norm 层进行微调,从而保证了训练的高效性。虽然通过增加模型层数来引入额外的灵活性,但这也导致了额外的推理延迟。
什么是适配器模块?
我们从三点来看一下适配器模块在 transformer 架构中的应用:
- 适配器模块(右)首先将原始 d 维特征投影到较小的 m 维向量,应用非线性,然后将其投影回 d 维。
- 可以看出,该模块具有跳跃连接功能——有了它,当投影层的参数初始化为接近零时,最终导致模块的接近恒等初始化。这对于稳定的微调是必需的,并且很直观,因为有了它,我们基本上不会干扰预训练的学习。
- 在变压器块(左)中,适配器直接应用于每个层(注意力和前馈)的输出。
如何确定m的值?
- 适配器模块中的大小 m 决定了可优化参数的数量,因此存在参数与性能的权衡。
- 原始论文通过实验调查了不同适配器尺寸 m 的性能保持相当稳定,因此对于给定模型,所有下游任务都可以使用固定尺寸。

3.4 Prefix Tuning
前缀微调(Prefix tuning)是一种用于语言模型的技术,其中在每个Transformer层中添加了一组可训练的连续向量序列,这些向量被称为前缀。这些前缀是特定于任务的,可以被视为虚拟的标记嵌入。在训练过程中,仅更新这些前缀参数,而模型的其余部分保持不变。
前缀向量的优化是通过一种重参数化技巧实现的。不是直接优化前缀,而是学习一个MLP(多层感知器)函数,它将一个较小的矩阵映射到前缀的参数矩阵。这种重参数化技巧有助于实现稳定的训练。优化完成后,映射函数会被丢弃,只保留推导出的前缀向量,以增强特定任务的性能。这种方法专注于仅训练前缀参数,使其成为一种参数高效的模型优化方法。

3.5 Prompt Tuning
提示微调(Prompt tuning)是一种与前缀微调不同的技术(也就是我们常说的P-Tuning),它侧重于在语言模型的输入层引入可训练的提示向量。该方法基于离散提示方法(人工设计,如文本模板),并通过在输入文本中包含软提示标记(以自由形式或前缀形式)来扩展输入文本。在实现过程中,特定任务的提示嵌入与输入文本嵌入相结合,并输入到语言模型中。简单来说,就是通过设计或学习一个固定的提示,将其与输入文本结合,引导模型生成期望的输出。
该方法在少样本或零样本学习中表现较好,但对提示的设计依赖较强。

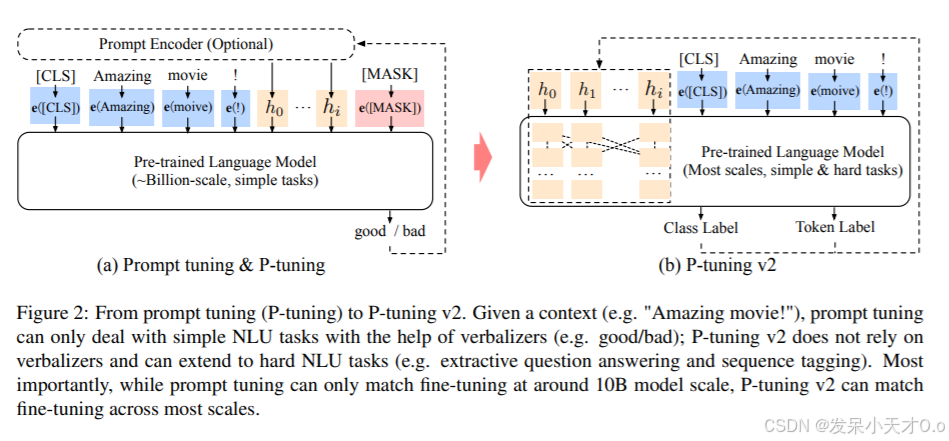
3.6 P-Tuning v2
P-Tuning v2 是 Prompt Tuning 的改进版本,通过引入连续提示嵌入和多层提示机制,提升提示的表达能力和模型性能。
- 连续提示嵌入:将离散提示替换为可学习的连续向量,增强了提示的灵活性。
- 多层提示:在模型的不同层引入提示嵌入,捕捉多层次的语义信息。
- 提示编码器:使用双向 LSTM 或 Transformer 编码提示嵌入,进一步提升提示的语义表达能力。
- 通用性:适用于多种预训练模型(如BERT、GPT等),且在少样本学习中表现更稳定。
4. 微调步骤
笔者重点介绍怎么使用参数高效微调方法微调视觉语言大模型。
VisualGLM-6B 是一个结合视觉和语言的多模态大模型,支持图像和文本的联合理解与生成。对其进行参数高效微调(Parameter-Efficient Fine-Tuning, PEFT)可以显著降低计算和存储成本。以下是针对使用 GPU 对VisualGLM-6B 的高效微调步骤:
(1)选择高效微调方法
笔者推荐使用 LoRA 或 Adapter,因为它们在多模态任务中表现良好。
(2)环境部署
- 安装 PyTorch 和 Hugging Face Transformers。
- 安装 PEFT 库(如 peft)和 VisualGLM-6B 相关依赖。笔者已经在之前的博客中介绍过 VisualGLM-6B 的环境部署与推理。
- 注意:GPU 需要至少 24GB 显存(如 NVIDIA A100、RTX 3090 等)。
conda create -n visualglm python=3.8 -y
conda activate visualglm
conda install pytorch==2.0.0 torchvision==0.15.0 torchaudio==2.0.0 pytorch-cuda=11.7 -c pytorch -c nvidia
pip install transformers peft datasets accelerate
(2)加载预训练模型
使用 Hugging Face 加载 VisualGLM-6B 的预训练模型和分词器。将模型移动到 GPU。同样笔者已经在之前的博客中介绍过如何加载本地模型。
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
# 加载模型和分词器
model_name = "THUDM/visualglm-6b"
model = AutoModelForCausalLM.from_pretrained(model_name, trust_remote_code=True)
tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)
# 将模型移动到 GPU
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.to(device)
(3) 应用高效微调方法
以 LoRA 为例,使用 peft 库实现:
- 配置 LoRA
from peft import get_peft_model, LoraConfig, TaskType
# 配置 LoRA
lora_config = LoraConfig(
task_type=TaskType.CAUSAL_LM, # 任务类型
r=8, # 低秩矩阵的秩
lora_alpha=32, # 缩放因子
lora_dropout=0.1, # Dropout 概率
target_modules=["query_key_value"], # 目标模块(VisualGLM-6B 中的注意力层)
)
# 应用 LoRA
model = get_peft_model(model, lora_config)
model.to(device) # 将 LoRA 模型移动到 GPU
(4)准备数据
加载多模态数据集(如图像-文本对),并对图像和文本进行预处理。
from datasets import load_dataset
from torchvision import transforms
from PIL import Image
# 加载本地数据集
dataset = load_dataset("json", data_files="dataset/annotations.json")
# 图像预处理
image_transform = transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor(),
])
# 文本预处理
def preprocess_function(examples):
examples["image"] = [image_transform(Image.open(img).convert("RGB")) for img in examples["image_path"]]
examples["text"] = tokenizer(examples["text"], padding="max_length", truncation=True, return_tensors="pt")
return examples
tokenized_dataset = dataset.map(preprocess_function, batched=True)
(5)设置训练参数
from transformers import TrainingArguments
training_args = TrainingArguments(
output_dir="./results",
per_device_train_batch_size=4, # 根据 GPU 显存调整
per_device_eval_batch_size=4,
num_train_epochs=100,
learning_rate=1e-4,
evaluation_strategy="epoch",
save_strategy="epoch",
logging_dir="./logs",
fp16=True, # 启用混合精度训练以节省显存
gradient_accumulation_steps=2, # 梯度累积
)
(6)训练模型
使用 Trainer 进行训练。
from transformers import Trainer
trainer = Trainer(
model=model,
args=training_args,
train_dataset=tokenized_dataset["train"],
eval_dataset=tokenized_dataset["test"],
)
# 开始训练
trainer.train()
(7)评估模型
在测试集上评估模型性能。计算任务相关指标(如生成文本的 BLEU 分数或图像-文本匹配准确率)。
results = trainer.evaluate()
print(results)
(8)保存模型
保存微调后的模型和配置。
model.save_pretrained("./fine-tuned-visualglm-6b")
tokenizer.save_pretrained("./fine-tuned-visualglm-6b")
(9)部署与推理
from transformers import pipeline
from PIL import Image
# 加载微调后的模型
model = AutoModelForCausalLM.from_pretrained("./fine-tuned-visualglm-6b", trust_remote_code=True)
tokenizer = AutoTokenizer.from_pretrained("./fine-tuned-visualglm-6b", trust_remote_code=True)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.to(device)
# 推理示例
image = Image.open("image.jpg").convert("RGB")
text = "Describe the image:"
inputs = tokenizer(text, return_tensors="pt").to(device)
image_input = image_transform(image).unsqueeze(0).to(device)
outputs = model.generate(inputs["input_ids"], image_input=image_input)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
5. 自定义数据集
数据集结构:
- 图像文件:存储图像的文件夹。
- 标注文件:存储图像-文本对的元数据(如 JSON、CSV 文件)。
示例
dataset/
├── images/
│ ├── 1.jpg
│ ├── 2.jpg
│ └── 3.jpg
└── annotations.json
标注文件(如 annotations.json)通常包含以下信息:
- 图像路径:指向图像文件的路径。
- 文本描述:与图像相关的文本描述。
JSON 格式示例:
[
{
"image_path": "images/1.jpg",
"text": "A cat sitting on a wooden table."
},
{
"image_path": "images/2.jpg",
"text": "A group of people playing soccer in a field."
},
{
"image_path": "images/3.jpg",
"text": "A beautiful sunset over the mountains."
}
]
CSV 格式示例:
image_path,text
images/1.jpg,"A cat sitting on a wooden table."
images/2.jpg,"A group of people playing soccer in a field."
images/3.jpg,"A beautiful sunset over the mountains."