ElasticStack简介及应用
文章目录
- 1.Elastic Stack 技术栈
- 2.ES 安装
- 2.1 准备
- 2.2 yum单机部署
- 2.3 集群部署
- 3.Kibana
- 3.1 安装配置
- 3.2 web访问
- 4.Filebeat
- 4.1 安装
- 4.2 配置 inputs
- 4.3 配置 output
- 4.4 索引
- 4.5 分片和副本
- 5.收集nginx日志
- 5.1 原生日志
- 5.2 nginx日志格式
- 5.3 filebeat 配置
- 6.logstash
- 6.1 安装
- 6.2 启动
- 6.3 logstash 对接 es
- 6.3 logstash 对接 filebeat
1.Elastic Stack 技术栈
官网:https://www.elastic.co/cn/



2.ES 安装
2.1 准备
三台主机

关闭防火墙、selinux
sed -i 's/SELINUX=enforcing/SELINUX=disabled/g' /etc/selinux/config
#临时关闭SELinux
setenforce 0
#关闭防火墙
systemctl stop firewalld.service
#永久关闭防火墙
systemctl disable firewalld.service
三台主机分别修改主机名
hostnamectl set-hostname elk1
hostnamectl set-hostname elk2
hostnamectl set-hostname elk3
三台主机分别修改hosts,可以通过主机名访问 ip
cat >> /etc/hosts << EOF
192.168.9.3 elk1
192.168.9.4 elk2
192.168.9.5 elk3
EOF
三台主机分别修改sshd服务优化
sed -ri 's/^#UseDNS yes/UseDNS no/g' /etc/ssh/sshd_config
sed -ri 's/^GSSAPIAuthentication yes/GSSAPIAuthentication no/g' /etc/ssh/sshd_config
grep '^UseDNS' /etc/ssh/sshd_config
grep '^GSSAPIAuthentication' /etc/ssh/sshd_config
在 elk1 主机生成密钥对,免密访问主机(可忽略)
ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa -q
ssh-copy-id elk1
ssh-copy-id elk2
ssh-copy-id elk3
ssh elk1
ssh elk2
ssh elk3
三台主机分别安装同步工具:rsync(可忽略)
yum -y install rsync
在 elk1 主机编写同步脚本
- 目的是在elk1 配置了 es脚本后,同步到其他主机用的
- 如果不做也可以,用scp网络拷贝或其他方式
vim /usr/local/sbin/data_rsync.sh
###########################################################################
#!/bin/bash
# 判断是否输入了一个参数
if [ $# -ne 1 ] ; then
echo "usage:$0 /path/file"
exit
fi
# 判断参数对应的文件或目录是否存在
if [ ! -e $1 ] ; then
echo "$1 not found"
exit
fi
# 获取父路径
parentpath=`dirname $1`
# 获取子路径
basename=`basename $1`
# 本机的文件循环同步到其他主机
for ((i=2;i<=3;i++))
do
echo "rsync to elk$i : $basename"
rsync -az $1 `whoami`@elk$i:$parentpath
if [ $? -eq 0 ] ; then
echo "rsync success"
fi
done
###########################################################################
在 elk1 主机给脚本授予执行权限,并测试,执行脚本后查看其他主机
注:也可以测试同步目录
chmod +x /usr/local/sbin/data_rsync.sh
cd
echo "hello" > a.txt
/usr/local/sbin/data_rsync.sh /root/a.txt
三台主机分别进行时间同步服务(防止日志不准确)
# 安装工具和服务
yum -y install ntpdate chrony
# 修改时间同步服务中的时间服务器为阿里云的服务器
vim /etc/chrony.conf
...
# 注释掉原来的时间服务器,换成国内的阿里云时间服务器
server ntp.aliyun.com iburst
server ntp1.aliyun.com iburst
server ntp2.aliyun.com iburst
server ntp3.aliyun.com iburst
server ntp4.aliyun.com iburst
server ntp5.aliyun.com iburst
...
# 开启启动时间同步服务、重启以让其工作
systemctl enable --now chronyd
systemctl restart chronyd
# 查看服务状态
systemctl status chronyd
2.2 yum单机部署
支持一览表:
https://www.elastic.co/cn/support/matrix
下载地址:
https://www.elastic.co/downloads/past-releases#elasticsearch
注意
- 根据支持一览表,某些版本需要先安装对应版本的 jdk,如 jdk1.8 或更高版本
- 如果用 yum 安装 es,某些版本中已经集成了 jdk,如本文档安装的 7.17.3 就集成了 openjdk18
yum 方式安装,需要先下载 rpm 安装包
# yum 安装
yum -y localinstall elasticsearch-7.17.3-x86_64.rpm
# 查看服务文件:vim /usr/lib/systemd/system/elasticsearch.service
# 发现1:安装时会自动创建用户elasticsearch,启动方式见下图
# 发现2:安装目录 /usr/share/elasticsearch/ 中安装了 18 版本的 openjdk,见下图


启动服务
systemctl start elasticsearch.service


配置文件,位置:/etc/elasticsearch

#切换目录
cd /etc/elasticsearch
#备份
cp elasticsearch.yml elasticsearch.yml.bak
#打开配置文件
vim elasticsearch.yml
#yml配置文件中必须要有空格
###################################################################
# 17 集群名 (默认是elasticsearch)
cluster.name: my-application
# 23 当前节点名(默认是主机名)需要修改成自己当前的主机名
node.name: es1
# 33 数据保存位置
#path.data: /var/lib/elasticsearch
# 37 日志保存位置
#path.logs: /var/log/elasticsearch
# 56 默认是127.0.0.1,只能本机访问
network.host: 0.0.0.0
# 70 在启动此节点时传递一个原始的主机列表以执行发现,可以写主机名或ip
discovery.seed_hosts: ["192.168.9.3"]
#discovery.seed_hosts: ["elk1"]
###################################################################
# 保存配置文件后,重启服务
systemctl restart elasticsearch.service
重启服务后,从windows或其他同网段其他主机访问

2.3 集群部署
在其他两个主机(elk2、elk3)上安装 es
# yum 安装
yum -y localinstall elasticsearch-7.17.3-x86_64.rpm
修改 elk1 的 es 配置
vim /etc/elasticsearch/elasticsearch.yml
# 70 集群中的所有节点,用主机名或ip表示
discovery.seed_hosts: ["192.168.9.3","192.168.9.4","192.168.9.5"]
#discovery.seed_hosts: ["elk1","elk2","elk3"]
# 74 设置集群中要初始化的主节点
cluster.initial_master_nodes: ["192.168.9.3","192.168.9.4","192.168.9.5"]
发送配置文件到其他两个主机(elk2、elk3)
# 传送文件,也可以用scp传送
data_rsync.sh /etc/elasticsearch/elasticsearch.yml
scp elasticsearch.yml elk2:/etc/elasticsearch

分别修改其他两个主机(elk2、elk3)的配置
vim /etc/elasticsearch/elasticsearch.yml
#23 修改节点名即可
node.name: es2
#node.name: es3
停止所有节点的es服务(如果开了),删除临时文件、数据文件、日志文件
systemctl stop elasticsearch.service
rm -rf /tmp/*
rm -rf /var/lib/elasticsearch/*
rm -rf /var/log/elasticsearch/*
启动所有节点的 es
systemctl start elasticsearch.service
可以观察日志,查看选举情况
tail -f /var/log/elasticsearch/my-es-cluster.log
# 显示基于 TCP 和 UDP 的网络连接的详细列表,如下图
ss -ntl

当个节点的服务都正常后,可以查看 http 9200 端口的数据

3.Kibana
3.1 安装配置
下载 kibana 要注意版本号与 es保持一致
yum 安装,安装到任意一台或同网络的主机上即可(本测试安装到了elk1上)
yum -y localinstall kibana-7.17.3-x86_64.rpm
配置
vim /etc/kibana/kibana.yml
###################################################################
# 7 允许所有ip访问kibana
server.host: "0.0.0.0"
# 29 也可以不修改
#server.name: "your-hostname"
# 32 es主机对应的ip地址
elasticsearch.hosts: ["http://192.168.9.3:9200","http://192.168.9.4:9200","http://192.168.9.5:9200"]
# 115 国际化语言
i18n.locale: "zh-CN"
###################################################################
# 启动服务,日志:/var/log/kibana/kibana.log
systemctl start kibana.service
ss -ntl
端口号不显示的话 建议启动新的虚拟机进行安装kibana
3.2 web访问
http://192.168.9.3:5601

堆栈监测


4.Filebeat
EFK 环境

4.1 安装
下载 filebeat 也要注意版本号与 es保持一致
yum安装,安装到要采集数据的主机上,如 tomcat、nginx服务器上,本测试安装到了elk2上
yum -y localinstall filebeat-7.17.3-x86_64.rpm
# 查看用法
filebeat -h
4.2 配置 inputs

配置参考网站:
https://www.elastic.co/guide/en/beats/filebeat/7.17/filebeat-overview.html
如:configure-inputs-log
https://www.elastic.co/guide/en/beats/filebeat/7.17/filebeat-input-log.html
测试1.监听标准输入
cd /etc/filebeat/
cp filebeat.yml filebeat.bak
vim filebeat.yml
###################################################################
# 清空配置文件,写入以下内容测试
filebeat.inputs:
- type: stdin
output.console:
pretty: true
###################################################################
# 删除之前的监听记录,再启动
rm -rf /var/lib/filebeat/*
# 启动
filebeat -e -c /etc/filebeat/filebeat.yml
# 随便输入信息,会被 filebeat 的 stdin 捕获,并显示到 console
测试2.监听日志文件
需要重新建配置文件
#复制原来的配置文件
cp filebeat.yml filebeat02.yml
# 删除之前的监听记录,再启动
rm -rf /var/lib/filebeat/*
# 启动
filebeat -e -c /etc/filebeat/filebeat02.yml
/tmp/test.log:监控单个文件
filebeat.inputs:
- type: log
paths:
- /tmp/test.log
output.console:
pretty: true
测试3.监听多个文件
#复制原来的配置文件
cp filebeat.yml filebeat03.yml
#复制原来的配置文件
cp filebeat.yml filebeat03.yml
# 删除之前的监听记录,再启动
rm -rf /var/lib/filebeat/*
# 启动
filebeat -e -c /etc/filebeat/filebeat03.yml
监听test.log的日记和后缀是txt的文件
/tmp/test.log:监控单个文件。/tmp/*.txt:监控/tmp目录下所有以.txt结尾的文件。
filebeat.inputs:
- type: log
paths:
- /tmp/test.log
- /tmp/*.txt
output.console:
pretty: true
测试4.路径通配符吃的
#复制原来的配置文件
cp filebeat.yml filebeat04.yml
#复制原来的配置文件
cp filebeat.yml filebeat04.yml
# 删除之前的监听记录,再启动
rm -rf /var/lib/filebeat/*
# 启动
filebeat -e -c /etc/filebeat/filebeat04.yml
/tmp/test.log:监控单个文件。/tmp/*.txt:监控/tmp目录下所有以.txt结尾的文件。/tmp/docker/*/*.log:监控/tmp/docker目录及其子目录下所有以.log结尾的文件。
filebeat.inputs:
- type: log
paths:
- /tmp/test.log
- /tmp/*.txt
- type: log
paths:
- /tmp/docker/*/*.log
output.console:
pretty: true
测试5.其他
- 第一个输入配置:
- type: log:指定输入类型为日志文件。
- enabled: false:此输入配置被禁用,Filebeat 不会监控这些路径。
- paths:指定要监控的日志文件路径。
/tmp/test.log:监控单个文件。/tmp/*.txt:监控/tmp目录下所有以.txt结尾的文件。
- tags: [“mytag-test”]:为这些日志文件添加标签
mytag-test。
- 第二个输入配置:
- type: log:指定输入类型为日志文件。
- enabled: true:此输入配置被启用,Filebeat 会监控这些路径。
- paths:指定要监控的日志文件路径。
/tmp/docker/*/*.log:监控/tmp/docker目录及其子目录下所有以.log结尾的文件。
- tags: [“mytag-docker”,“容器日志”]:为这些日志文件添加标签
mytag-docker和容器日志。 - fields:添加自定义字段。
key1: "value1":添加字段key1,值为value1。key2: "value2":添加字段key2,值为value2。
- fields_under_root: true:将自定义字段添加到日志事件的根目录下,而不是默认的
fields对象下。
filebeat.inputs:
- type: log
enabled: false
paths:
- /tmp/test.log
- /tmp/*.txt
tags: ["mytag-test"]
- type: log
enabled: true
paths:
- /tmp/docker/*/*.log
tags: ["mytag-docker","容器日志"]
fields:
key1: "value1"
key2: "value2"
fields_under_root: true
output.console:
pretty: true
# enabled:是否可用,默认是 true
# tags:标记,以后在es中容易查找
# fields:自定义字段,包含键值对
# fields_under_root:是放置于根节点下,默认是 false
4.3 配置 output
输出到 es
filebeat.inputs:
- type: log
enabled: false
paths:
- /tmp/test.log
- /tmp/*.txt
tags: ["mytag-test"]
- type: log
enabled: true
paths:
- /tmp/docker/*/*.log
tags: ["mytag-docker","容器日志"]
fields:
key1: "value1"
key2: "value2"
fields_under_root: true
output.elasticsearch:
hosts: ["http://192.168.9.3:9200","http://192.168.9.4:9200","http://192.168.9.5:9200"]
清空上次的结果,并且在filebeat重启后,在 kibana 中查看索引管理
menu -> stack managerment -> 索引管理

管理 -> 索引模式 -> 创建索引模式

menu -> discover -> 选择要展示的字段

注:实时日志也会在kibana中刷新展示
4.4 索引
官网参考:https://www.elastic.co/guide/en/beats/filebeat/7.17/configuration-template.html
在 output 中指定索引(在 es 中方便查询)
# 前面省略......
# 输出时用 index 指定索引
output.elasticsearch:
hosts: ["http://192.168.9.3:9200","http://192.168.9.4:9200","http://192.168.9.5:9200"]
index: "my-%{+yyyy.MM.dd}"
# 禁用索引生命周期管理(如果启用的话,自定义索引将被忽略)
setup.ilm.enabled: false
# 设置索引模板名称
setup.template.name: "my"
# 设置索引模板的匹配模式
setup.template.pattern: "my*"
清空上次的结果,并且在filebeat重启后,在 kibana 中查看索引管理中的索引模板
默认是下面5个,重启后会有新定义的显示出来(截图中没有刷新页面)
可以删除之前索引模式,再重新创建索引模式时匹配新定义的索引名称(略)
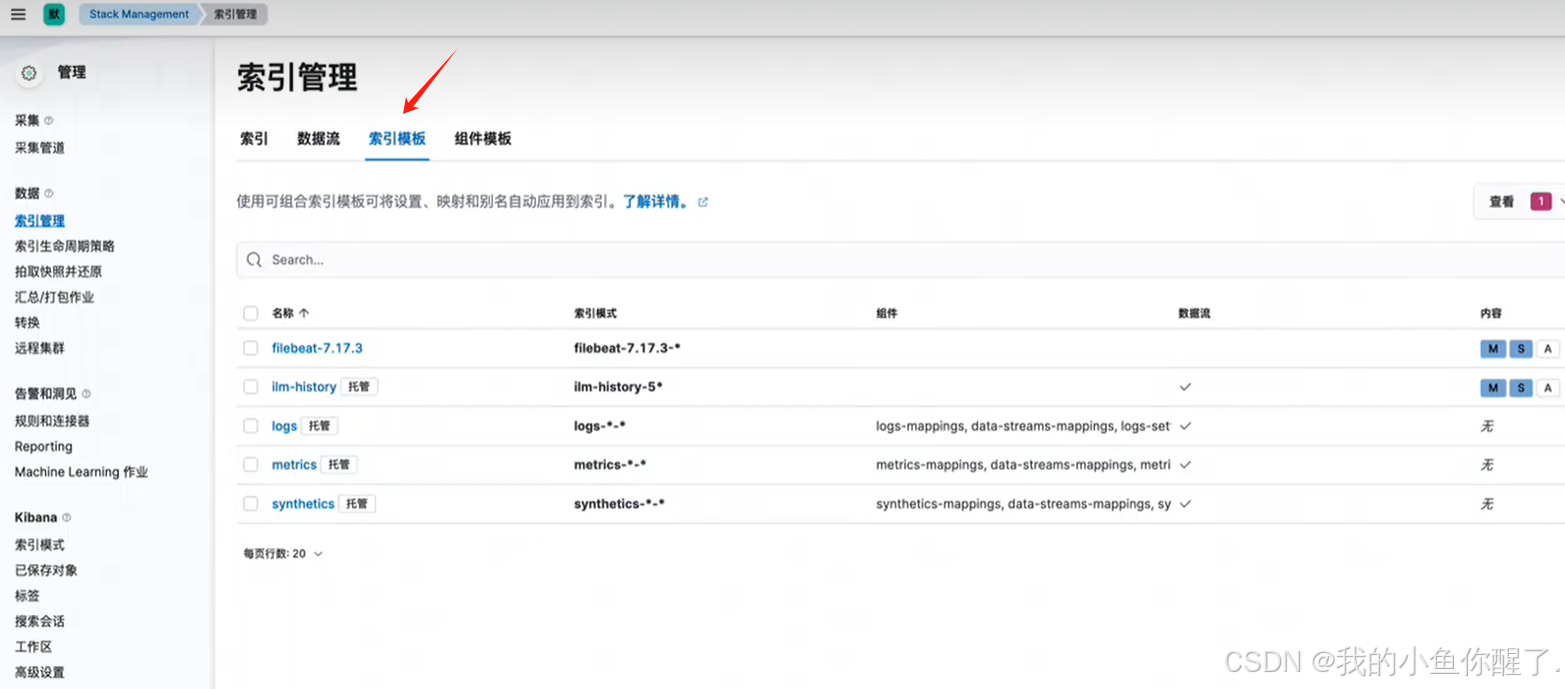
匹配多个索引
# 前面省略......
# 输出时用 indices 指定多个索引
# 用 when.contains 根据 tag 或 message 等属性进行筛选
output.elasticsearch:
hosts: ["http://192.168.9.3:9200","http://192.168.9.4:9200","http://192.168.9.5:9200"]
indices:
- index: "my-docker-%{+yyyy.MM.dd}"
when.contains:
tags: "mytag-docker"
- index: "my-test-%{+yyyy.MM.dd}"
when.contains:
tags: "mytag-test"
# 禁用索引生命周期管理(index lifecycle managerment,如果启用的话,自定义索引将被忽略)
setup.ilm.enabled: false
# 设置索引模板名称
setup.template.name: "my"
# 设置索引模板的匹配模式
setup.template.pattern: "my*"
清空上次的结果,并且在filebeat重启后,在 kibana 中查看索引管理中的索引模板
重新创建索引模式,重新 discover,可以根据索引分类查看日志了
4.5 分片和副本

# 前面省略......
# 禁用索引生命周期管理(index lifecycle managerment,如果启用的话,自定义索引将被忽略)
setup.ilm.enabled: false
# 设置索引模板名称
setup.template.name: "my"
# 设置索引模板的匹配模式
setup.template.pattern: "my*"
# 是否覆盖已有的索引模板
setup.template.overwrite: false
# 配置索引模板(3分片1副本)
setup.template.settings:
index.number_of_shards: 3
index.number_of_replicas: 1
删除索引模板、在索引管理中删除原来的索引,在 linux 清空上次的结果,把filebeat重启
(menu -> stack management -> 索引管理)
注:如果3分片3副本,则会变为黄色状态(可以测试)
5.收集nginx日志
5.1 原生日志
测试时,用 yum 安装 nginx,用 filebeat 收集其访问日志
filebeat 配置参考如下:
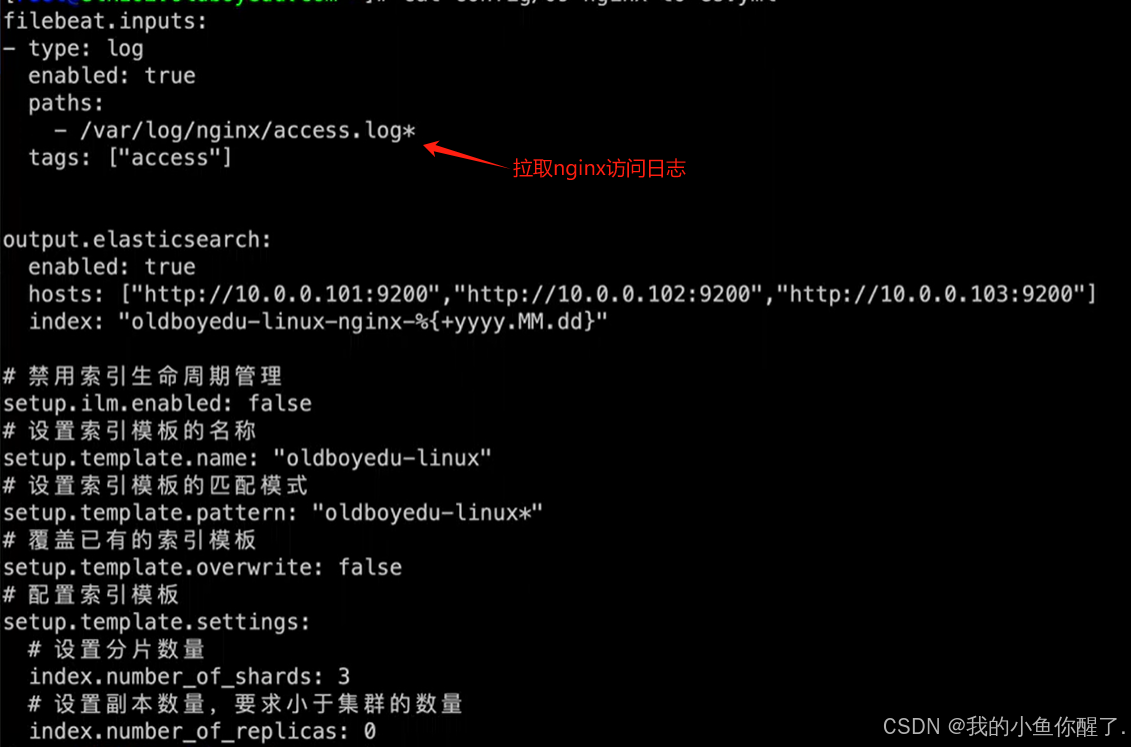
#可以对复制之前的配置文件
cp filebeat06.yml filebeat.yml
#############################################################
filebeat.inputs:
- type: log
enabled: true
paths:
- /var/log/nginx/access.log*
tags: ["mytag-nginx"]
output.elasticsearch:
hosts: ["http://192.168.9.3:9200","http://192.168.9.4:9200","http://192.168.9.5:9200"]
indices:
- index: "my-nginx-%{+yyyy.MM.dd}"
when.contains:
tags: "mytag-nginx"
setup.ilm.enabled: false
setup.template.name: "my"
setup.template.pattern: "my*"
setup.template.overwrite: false
setup.template.settings:
index.number_of_shards: 3
index.number_of_replicas: 1
#############################################################
kibana 中的日志如下:

nginx 的原生日志不太容易看懂,需要对其格式化
5.2 nginx日志格式
修改nginx 配置文件
vim /etc/nginx/nginx.conf
#############################################################
# json日志格式
log_format log_json '{"@timestamp": "$time_local", '
'"remote_addr": "$remote_addr", '
'"referer": "$http_referer", '
'"request": "$request", '
'"status": $status, '
'"bytes": $body_bytes_sent, '
'"agent": "$http_user_agent", '
'"x_forwarded": "$http_x_forwarded_for", '
'"up_addr": "$upstream_addr",'
'"up_host": "$upstream_http_host",'
'"up_resp_time": "$upstream_response_time",'
'"request_time": "$request_time"'
' }';
# 引用日志格式名称
access_log /var/log/nginx/access.log log_json;
#这一段配置文件中就有 但名字不一样 原本叫main 需要直接手动修改
#access_log /var/log/nginx/access.log main;
#############################################################
# 语法检查
nginx -t
# 重启nginx(在重启nginx之前最好先删除es中原来的索引:menu->stack management -> 索引管理)
systemctl restart nginx
# 清空原来的日志(以免两种日志格式混在一起)
> /var/log/nginx/access.log
从网页再次请求ngxin后,观察 kibana中的日志格式:

数据变为json格式了,但还需要优化
5.3 filebeat 配置
- json.keys_under_root: true 让json格式的数据在在根节点下展示
- 顺便i修改了索引名为:my-nginx-access-… 让语义性更明显
filebeat.inputs:
- type: log
enabled: true
paths:
- /var/log/nginx/access.log*
tags: ["nginx"]
json.keys_under_root: true
output.elasticsearch:
hosts: ["http://192.168.9.3:9200","http://192.168.9.4:9200","http://192.168.9.5:9200"]
index: "my-nginx-access-%{+yyyy.MM.dd}"
setup.ilm.enabled: false
setup.template.name: "my"
setup.template.pattern: "my*"
setup.template.overwrite: false
setup.template.settings:
index.number_of_shards: 3
index.number_of_replicas: 0
此时可以方便的查看信息了

6.logstash
6.1 安装
下载 logstash 要注意版本号与 es保持一致
yum 安装,安装到任意一台或同网络的主机上即可(本测试安装到了elk3上)
# 安装
yum -y localinstall logstash-7.17.3-x86_64.rpm
# 软连接
ln -sv /usr/share/logstash/bin/logstash /usr/local/bin/
6.2 启动
简单配置,测试是否可以正常启动
配置文件路径可以自定义,启动时用 -f 指定即可

# 新建配置文件
vim /etc/logstash/conf.d/logstash1.conf
###################################################
input {
stdin {}
}
output{
stdout{}
}
###################################################
# 检查语法
logstash -tf /etc/logstash/conf.d/logstash1.conf
# 启动
logstash -f /etc/logstash/conf.d/logstash1.conf
6.3 logstash 对接 es
vim /etc/logstash/conf.d/logstash2.conf
###################################################
input {
stdin {}
}
output{
elasticsearch {
hosts => ["192.168.9.3:9200","192.168.9.4:9200","192.168.9.5:9200"]
}
}
###################################################
# 检查语法
logstash -tf /etc/logstash/conf.d/logstash2.conf
# 启动
logstash -f /etc/logstash/conf.d/logstash2.conf
启动后,随意输入一些信息

在kibana中查看到了 es中的信息
访问浏览器的地址还是kibana主机的地址

创建索引模式后查看信息

6.3 logstash 对接 filebeat
修改 filebeat 配置,让其 output 到 logstash
filebeat.inputs:
- type: log
enabled: true
paths:
- /var/log/nginx/access.log*
tags: ["nginx"]
json.keys_under_root: true
output.logstash:
hosts: ["192.168.9.5:5044"]
#hosts:ip地址是安装logstash主机的地址
修改 logstash 配置,让其 input 来自 beats
vim /etc/logstash/conf.d/logstash3.conf
###################################################
input {
beats {
port => 5044
}
}
output{
elasticsearch {
hosts => ["192.168.9.3:9200","192.168.9.4:9200","192.168.9.5:9200"]
}
}
###################################################
# 检查语法
logstash -tf /etc/logstash/conf.d/logstash3.conf
# 启动
logstash -f /etc/logstash/conf.d/logstash3.conf
清空es中原来测试的索引等
启动 logstash,启动 filebeat,访问 niginx生成日志,在kibana查看es
