spark君第一篇图文讲解Delta源码和实践的文章
Delta 乐观锁并发事务控制
http://spark.coolplayer.net/?p=3717
Delta 常见问题
http://spark.coolplayer.net/?p=3722
实践例子
打包编译 delta,只需要运行 sbt package 就可以了,打包编译的时候, 这时候一定要注意, 编译 spark 的 scala 版本和 delta 的scala 编译版本一定要保持一致,delta 默认配合 spark 2.4.2 才可以使用,官网提供的默认都是基于 scala 2.12 的,你自己编译 delta 也要保证 scala 是 2.12 的,否则会报错:

我们在 spark-shell 中启动一个 structured streaming job, 启动命令,使用 --jars 带上需要的包:

我们在 spark-shell 中启动一个流,读取kafka 数据,然后写入 delta,代码如下:

执行一段时间,我们来看下checkpointLocation 目录里面的文件,下文中,我会解释这些文件都是干啥的,已经文件内容的含义

Delta 核心原理
整体看下来,Delta 实现的蛮简单的,我们基于上文中的例子,我解释说明一下delta的一些实现
Delta 支持数据的多版本管理,在批读取的时候,可以使用 Time Travel 功能指定你获取哪个版本, 这个版本是怎么来的呢,什么动作会触发产生一个新版本,通过在 spark shell 里面测试,在_delta_log 目录下面,保存了很多的json 文件:
文件名后缀从0依次变大,这里的0 到 28 就代表Delta Lake的数据版本。
每个版本的json文件里面保存了,这个版本的 commitInfo, 每个commitInfo 就代表一次提交,一次对 Delta Lake 数据的变动。每次提交变动就会产生一个新版本,所以如果我们使用 structured streaming 从 kafka 读取数据流式写入delta, 每一次微批处理就会产生一个数据新版本, 下面这个图例中展示了0这个批次提交的操作类型为 STREAMING UPDATE(流式更新),epochId为0, 写入的模式是Append,还有Structured Streaming 的queryId:

然后是这次提交记录的事务信息,version 为0, 就指定这次提交后,数据的版本为0, 和 上面提交信息的 epochId 是一一对应的。
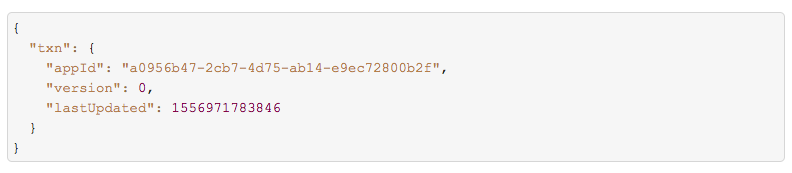
json 文件中剩下的部分就是本次提交对 Delta Lake 产生的文件变化日志,注意这里记录的是 Action动作,跟数据库里面的 redo 日志一样,可以看到,我们demo中消费的topic一共3个分区,所以每个batch 会落地3个文件到 delta,所以每次增加 3个 parquet 文件。

我们都知道,对于数据库,我们如果有全部的 redo 日志,我们就可以从任意一个时间点数据库的状态对数据进行 redo replay 从而得到我们想要的任何状态。
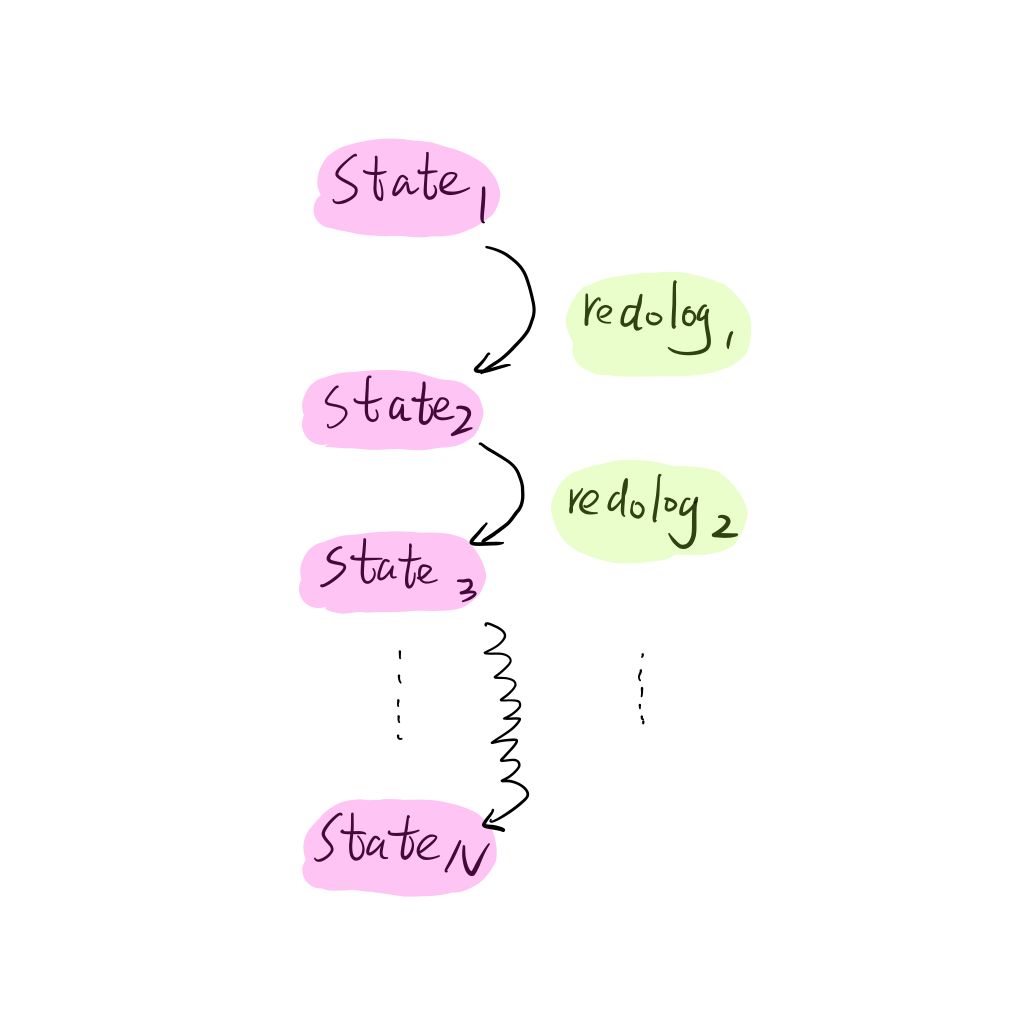
这里 Delta 也是一样的,不过数据变动的最小粒度是文件,我们例子中,每次数据版本变化都是增加了3个文件,0 到 28 个json 文件中都记录了每次变动文件 delta 日志,这些 Delta日志中记录了对文件命名空间的变动(包括 add增加一个文件 和 remove删除一个文件两类),这样我们从任意一个 文件命名空间的状态开始,都可以对命名空间 replay delta日志,到下一个命名空间的状态。
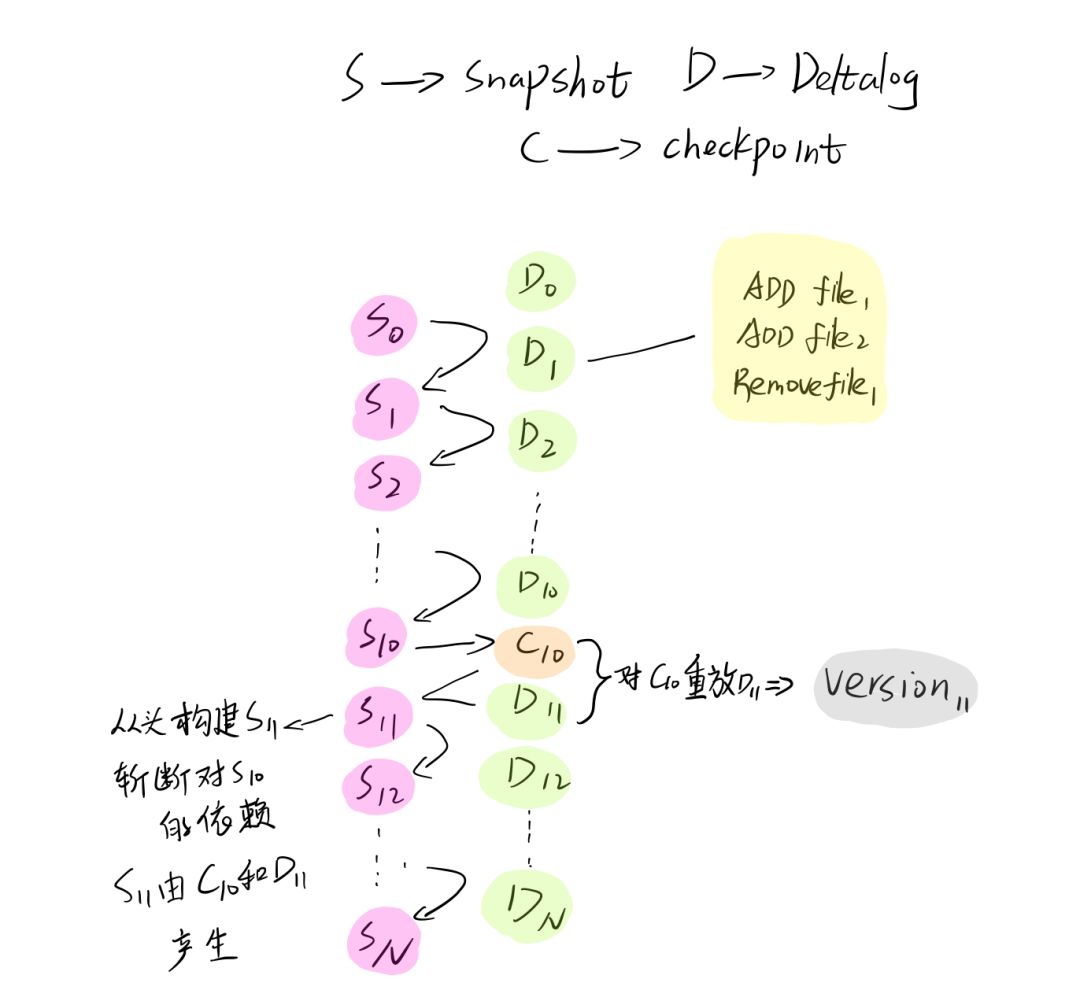
如果说到这里,我们很自然的就想到一个问题就是要有检查点,就是过一段时间,要对 命名空间进行 checkpoint, 不然每次都从 0 开始重放恢复,依赖链会过长,这个会导致性能问题和内存stackoverflow 文件。
下图中 S0 ~ Sn 都代表delta 命名空间的状态,也就是 Snapshot0 ~ SnapshotN, D0 ~ DN代表Delta日志,C10 代表 /delta/events/_delta_log/00000000000000000010.checkpoint.parquet 这个 checkpoint 文件。
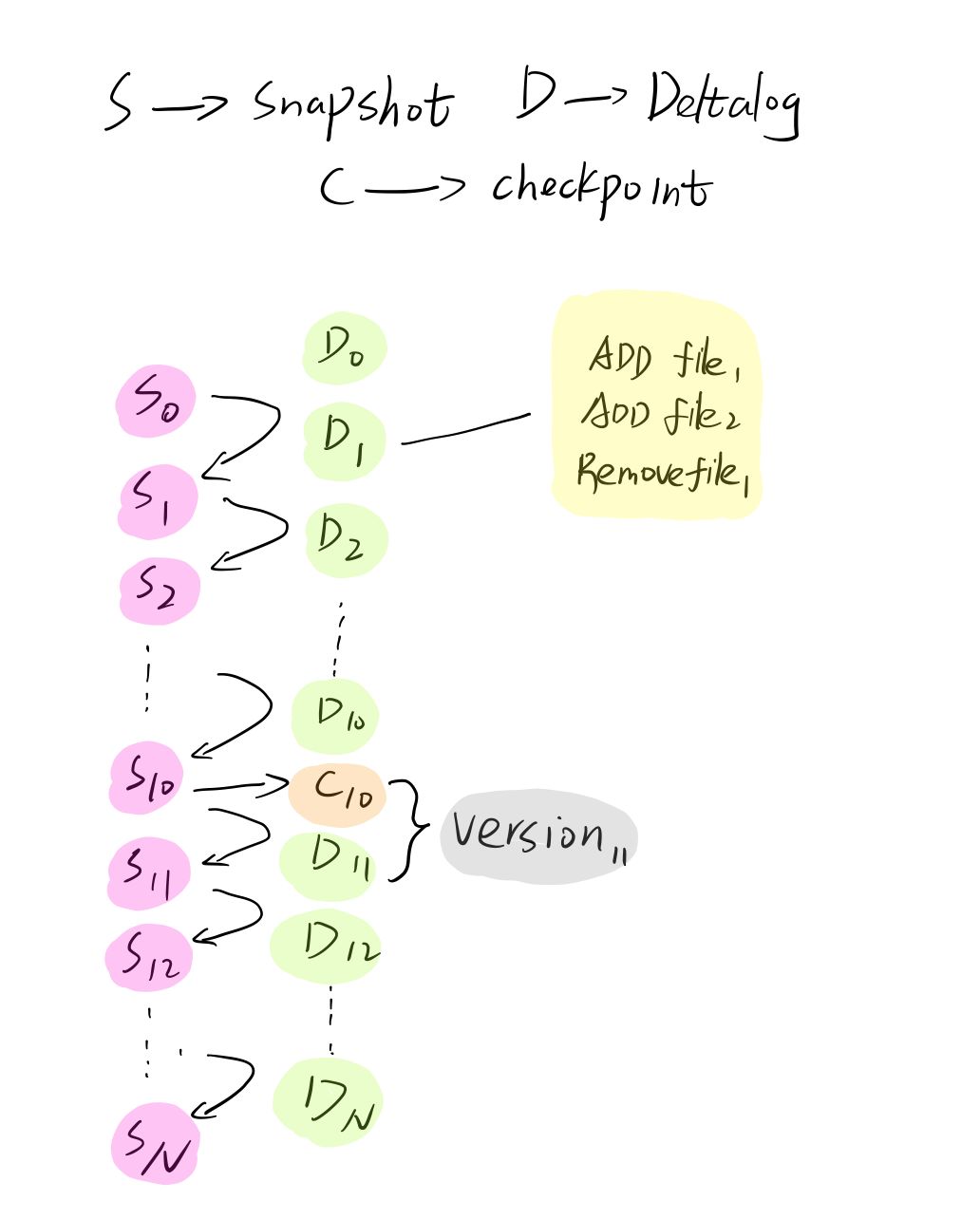
所以 Delta 也是这样做的,我们可以看到,Delta 默认10个版本就会做一次checkpoint(比如图解中的C10), 这样的话,如果我们需要获取第11个版本的数据,只需要load 进来 /delta/events/_delta_log/00000000000000000010.checkpoint.parquet 这个checkpoint 文件,然后replay /delta/events/_delta_log/00000000000000000011.json 这一个 deltalog 日志就可以了。
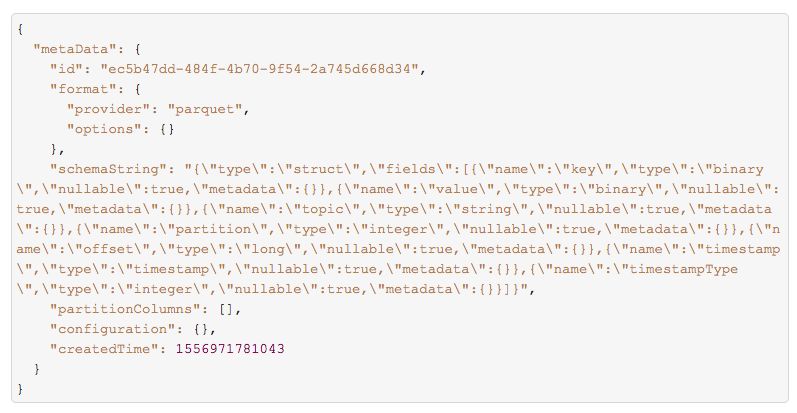
Delta log 中还有一部分记录当前这个表的meta信息, 我们测试中使用的是kafka数据源,产生的 DataFrame 就是key,value,topic,partitiion,timestamp等字段,这里就记录着这些字段的元信息。
通过以上的例子,我们可以看到Delta 的基本玩法了,我们也知道 Deltalog日志里面都记录的哪些东西(版本信息,提交信息,Action日志,meta信息)。
下面我们看下 DeltaLog 这个核心的类实现

代码贴太多影响理解,我尽量抽取一些特别重要的类和方法来说明,
我们可以看到 DeltaLog 继承了 Checkpoint 方法,所以会在指定的时间间隔内把内存中的命名空间,checkpoint 到文件系统中,这样就相当于固化落地了一个状态(图例中的C10),所以我们需要某个版本的状态时候,就不需要从头开始去一个一个 deltalog 文件去replay 重放了,只需要找到最靠近的 checkpoint 文件,然后去replay 就好了, 我们上文中已经举例说明。注意这里的 checkpoint 文件也是 parquet 格式的。
我们在提交事务的时候,就会调用这里的update 方法,来异步的更新内存中的 文件命名空间,产生一个新的内存空间的 Snapshot, 注意这里每次产生的 Snapshot 都是上一个版本的Snapshot的引用加上本次增量更新的 delta 文件,也就是每次新的状态实例都是上一次状态的加上一些 deltalog 日志文件。还有一个 参数 maxSnapshotLineageLength控制依赖长度 ,这个依赖的血缘关系不能太长,不然会产生 StackOverflowError, 所以超过这个长度后,就会从头构建这个 SnapShot,原理就是找到最近的一个 checkpoint 文件,load进来命名空间,然后再 replay 最新的一些 deltalog 文件,从而斩断依赖链。
还有一个 LogStoreProvider, 这个是提供保存我们上文说的这些文件的存储,默认是用 HDFSLogStoreImpl 来实现的。
getsnapshotAt 这个方法很重要,Delta 就是使用这个逻辑来实现 Time Travel 功能,这里的逻辑是找到靠近指定版本最近的 checkpoint 文件,然后再replay 从这个checkpoint 的版本到需要的版本之间的几个 deltalog文件,就可以获取指定版本的状态文件了。比如上文例子中,我们需要23 版本的数据集,我们只需要 load 20 版本的checkpoint 文件,然后 replay 21,22,23 三个 deltalog 文件就可以了。
还有一个方法是 startTransaction,我们从外面进行并发的读写,都需要从 Deltalog 这个类实例中获取一个乐观事务管理器,否则可能就不会检查冲突。
比如我们在 structured streaming 里面流式输出的时候:

就会先申请一个 乐观事务管理器(这里说明下为啥要用乐观锁,这种方式在数据湖场景下面很适用,因为多次写入/修改相同的文件很少发生, 然后输出文件,然后提交,下面是并发写事务的3个阶段:
-
Read: 读取最新版本的数据,作为一个数据集的一个 snapshot,每次获取乐观锁的时候,都会获取最新当前状态的一个 snapshot。
-
Write : 输出数据,然后更新产生一个新版本,里面记录本次变动的文件。
-
Validate and commit : 在提交之前,检测是不是有其他已经提交的Deltalog 文件,和本事务变动的文件有冲突,如果没有冲突,本次staged 的changes 就提交,产生一个新的数据集版本,如果有冲突,就会抛出一个并发修改异常,放弃修改。 OptimisticTransaction 这个类里面 commit过程都会经过prepareCommit -> doCommit -> postCommit 这三步,判断是否冲突的方式,就是写入DeltaFile的时候判断当前 version+1 的delta文件是不是已经写过了,如果写过了就会抛出 ConcurrentModificationException 异常,本次输出的文件也就不会产生任何效果,因为不体现在命名空间里面,当然在 spark structured streaming上层逻辑如果一个增量batch输出失败,就会重试,这样的话,就相当于进行下一轮的输出,所以在整个过程中,不会污染现有数据,冲突了就等待下一次重新输出成功,当然如果冲突很频繁,就会有性能问题,每次 postCommit 方法里面也会检查是不是符合做checkpoint的间隔了。
Delta 和 spark 的计算层整合
Delta 使用 DeltaDataSource 和 Spark Sql 的 批流APIs 进行整合。