<论文>DeepSeek-R1:通过强化学习激励大语言模型的推理能力
一、摘要
本文跟大家来一起阅读DeepSeek团队发表于2025年1月的一篇论文《DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning | Papers With Code》,新鲜的DeepSeek-R1推理模型,作者规模属实庞大。

译文:
我们推出了第一代推理模型 DeepSeek-R1-Zero 和 DeepSeek-R1。DeepSeek-R1-Zero 是一个通过大规模强化学习(RL)训练而成的模型,在初步阶段没有进行有监督的微调(SFT),它展示出了卓越的推理能力。通过强化学习,DeepSeek-R1-Zero 自然地呈现出许多强大而有趣的推理行为。然而,它也面临着一些挑战,如可读性差和语言混合。为了解决这些问题并进一步提高推理性能,我们推出了 DeepSeek-R1,它在强化学习之前结合了多阶段训练和冷启动数据。DeepSeek-R1 在推理任务上实现了与 OpenAI-o1-1217 相当的性能。为了支持研究社区,我们开源了 DeepSeek-R1-Zero、DeepSeek-R1 以及六个从 DeepSeek-R1 基于 Qwen 和 Llama 提炼出的密集模型(1.5B、7B、8B、14B、32B、70B)。
二、核心创新点
论文指出,以往的工作严重依赖大量的有监督数据来提升模型性能,而作者在这篇论文中证明了即使不使用有监督微调SFT作为冷启动,通过大规模的强化学习RL也能显著提升模型的推理能力。此外,加入少量冷启动数据可以进一步提升性能。论文介绍了两个推理模型,一个是DeepSeek-R1-Zero,这是直接将RL应用于基础模型,不使用任何SFT数据的模型;另一个是DeepSeek-R1,该模型从一个用数千个长思维链样例微调过的checkpoint开始应用RL。
1、DeepSeek-R1-Zero训练策略
1.1 强化学习策略Group Relative Policy Optimization(GRPO)
为了节省强化学习的成本,作者使用了GRPO技术。该技术舍弃了通常与策略模型大小相同的critic模型,取而代之的是从Group分数中来评估baseline。具体来说,对于每个问题q,GRPO从旧策略中采样一组输出
,接着通过最大化以下目标来优化策略模型
:

其中,和
是超参数,
是优势,使用与每个组内的输出相对应的一组奖励
来计算:
1.2 奖励模型
奖励是训练信号的来源,决定了强化学习的优化方向。为了训练DeepSeek-R1-Zero,作者采用了一个基于规则的奖励系统,由两种类型的奖励构成:
- 准确率奖励:准确率奖励模型评估响应是否正确。例如对于具有确定性结果的数学问题,模型需要以指定格式提供最终答案。
- 格式奖励:格式奖励模型强制受训练的模型将其思考过程放在“<think>”和“</think>”标签之间。
作者指出,在开发DeepSeek-R1-Zero时不应用结果或者过程神经奖励模型是因为神经奖励模型在大规模强化学习的过程中可能会受到奖励黑客攻击。
1.3 训练模板
作者设计了一个简单的模板来引导基础模型遵循指定的指令。这个模板要求模型先生成推理过程,然后给出最终答案。

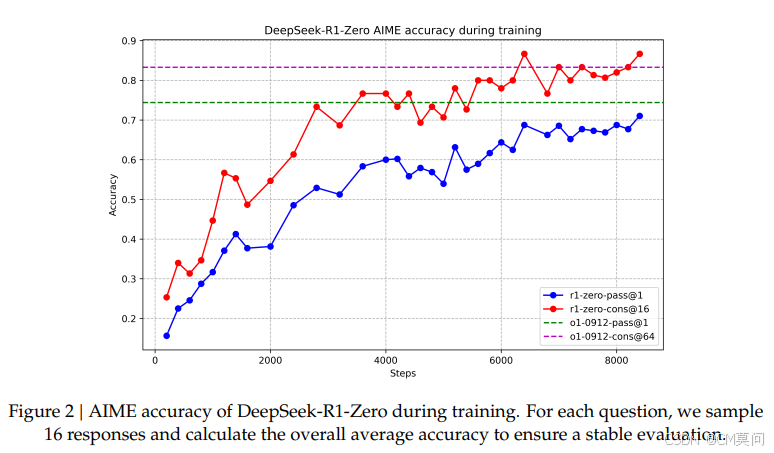
2、DeepSeek-R1
在对DeepSeek-R1-Zero的训练过程中,出现了两个自然的问题:一个是通过加入少量高质量数据作为冷启动,推理性能能否进一步提高?另一个是如何训练一个用户友好的模型,该模型不仅能够产生清晰连贯的思维链,还能展示出强大的通用能力?由此,作者设计了一个用于训练DeepSeek-R1的pipeline。
2.1 冷启动
与DeepSeek-R1-Zero不同,为了防止基础模型中强化学习训练的早期不稳定冷启动阶段,对于DeepSeek-R1,作者构建并收集少量的长思维链数据,以微调模型作为初始的强化学习actor。这里,作者收集了数千个冷启动数据,以微调DeepSeek-V3-Base作为RL的起点。与DeepSeek-R1-Zero相比,冷启动数据的优势在于:
- 可读性:DeepSeek-R1-Zero的一个关键限制是其内容通常不适合阅读。回复可能会混合多种语言或缺乏Markdown格式来突出显示给用户的答案。相比之下,在为DeepSeek-R1创建冷启动数据时,作者设计了一种可读的模式,即在每个回复的末尾包含一个摘要,并过滤掉不便于读者阅读的回复。在这里,作者将输出格式定义为:|特殊标记|<推理过程>|特殊标记|<摘要>,其中推理过程是查询的思维链,而摘要用于总结推理结果。
- 潜力:通过使用人类先验仔细设计冷启动数据的模式,DeepSeek-R1-Zero的性能更好。
2.2 面向推理的强化学习
在对DeepSeek-V3-Base在冷启动数据上进行微调后,作者应用与DeepSeek-R1-Zero相同的大规模强化学习训练过程。这个阶段侧重于增强模型的推理能力,特别是在编码、数学、科学和逻辑推理等推理密集型任务中。
在训练过程中,思维链(CoT)经常出现语言混合,特别是当强化学习提示涉及多种语言时。为了缓解语言混合问题,作者在强化学习训练期间引入了语言一致性奖励,该奖励通过统计思维链中目标语言单词的比例来计算。尽管消融实验表明这种对齐会导致模型性能略有下降,但作者认为这种奖励符合人类偏好,使其更具可读性。最后,作者将推理任务的准确性和语言一致性奖励直接相加,形成最终奖励。然后,在微调后的模型上应用强化学习训练,直到模型在推理任务上达到收敛。
2.3 抑制采样和有监督微调
当以推理为导向的强化学习收敛时,作者利用得到的checkpoint为下一轮收集有监督微调数据。与最初主要侧重于推理的冷启动数据不同,这个阶段结合了来自其他领域的数据,以增强模型在写作、角色扮演和其他通用任务方面的能力。具体来说,按照以下方式生成数据并微调模型:
- 推理数据:作者整理了推理提示,并通过从上述强化学习训练的checkpoint进行抑制采样来生成推理轨迹。在这个阶段合并了额外的数据来扩展数据集,其中一些数据通过将真实结果和模型预测输入到DeepSeek-V3中进行判断来使用生成式奖励模型。最后,作者收集了大约 60 万个与推理相关的训练样本。
- 非推理数据:对于非推理数据,如写作、事实性问答、自我认知和翻译,作者采用DeepSeek-V3 的pipeline,并复用DeepSeek-V3的SFT数据集的部分内容。对于某些非推理任务,作者通过提示调用DeepSeek-V3在回答问题之前生成一个潜在的思维链。然而,对于更简单的查询,如“你好”,则在响应中不提供思维链。最后,收集了总共约 20 万个与推理无关的训练样本。
2.4 通用化
为了进一步使模型与人类偏好保持一致,作者还实施了一个二级强化学习阶段,旨在提高模型的有用性和无害性,同时改进其推理能力。具体来说,使用奖励信号和多样化提示分布的组合来训练模型。对于推理数据,遵循DeepSeek-R1-Zero中概述的方法,该方法利用基于规则的奖励来指导数学、代码和逻辑推理领域的学习过程。对于一般数据,作者采用奖励模型来捕捉复杂和微妙场景中的人类偏好。以DeepSeek-V3 pipeline为基础,并采用类似的偏好对和训练提示分布。
对于有用性,作者仅关注最终总结,确保评估强调响应对用户的实用性和相关性,同时最大限度地减少对底层推理过程的干扰。对于无害性,作者评估模型的整个响应,包括推理过程和总结,以识别和减轻生成过程中可能出现的任何潜在风险、偏差或有害内容。最终,奖励信号和多样化数据分布的整合使作者能够训练出在推理方面表现出色的模型,同时优先考虑有用性和无害性。