一行代码生成Tableau可视化图表
今天给大家介绍一个十分好用的Python模块,用来给数据集做一个初步的探索性数据分析(EDA),有着类似Tableau的可视化界面,我们通过对于字段的拖拽就可以实现想要的可视化图表,使用起来十分的简单且容易上手,学习成本低,并且不需要我们写一大推冗长的代码。
PyGWalker
接下来就给大家来介绍一下这款名叫PyGWalker的Python模块,在使用之前,我们先通过pip命令来将其下载安装,代码如下
pip install pygwalker
## 或者是
conda install pygwalker
我们将其与pandas模块相结合,毕竟我们这里还是需要它来读取CSV数据集的,这是一份共享单车的用户使用数据,代码如下
import pandas as pd
import pygwalker as pyg
模块导入完成之后便是对数据集的读取了,代码如下
df = pd.read_csv(r"bike_sharing_dc.csv", parse_dates=['date'])
df.head()
output

接下去便是PyGWalker该登场的时候了,代码如下
pyg.walk(df)
output
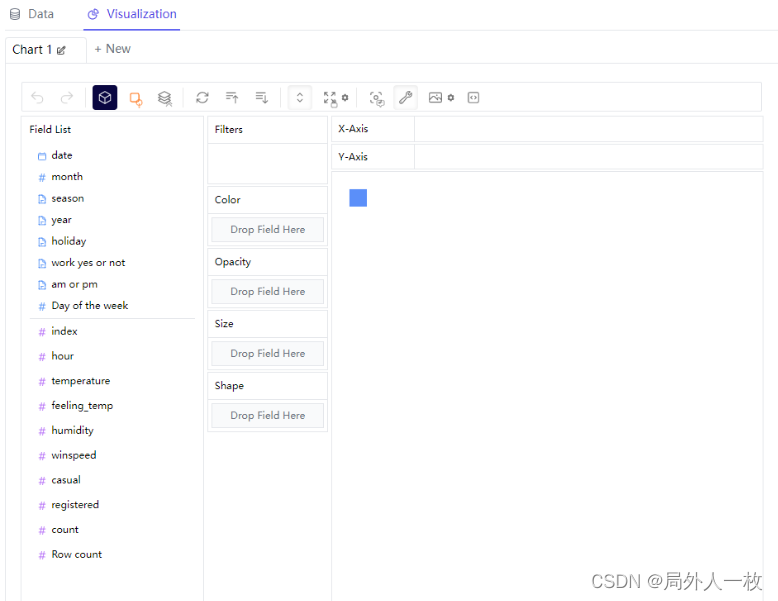
我们随后变回看到如上图所示的界面,是不是和Tableau的界面很像呢,同样在左边的一栏中,我们可以看到数据集中各个字段,被分成了离散型变量(categorical data)和数值型变量(numeric data)
绘制可视化图表
接下来我们尝试来绘制可视化图表,拖拽当中的字段放置到X轴或者Y轴当中,就会有可视化图表显示出来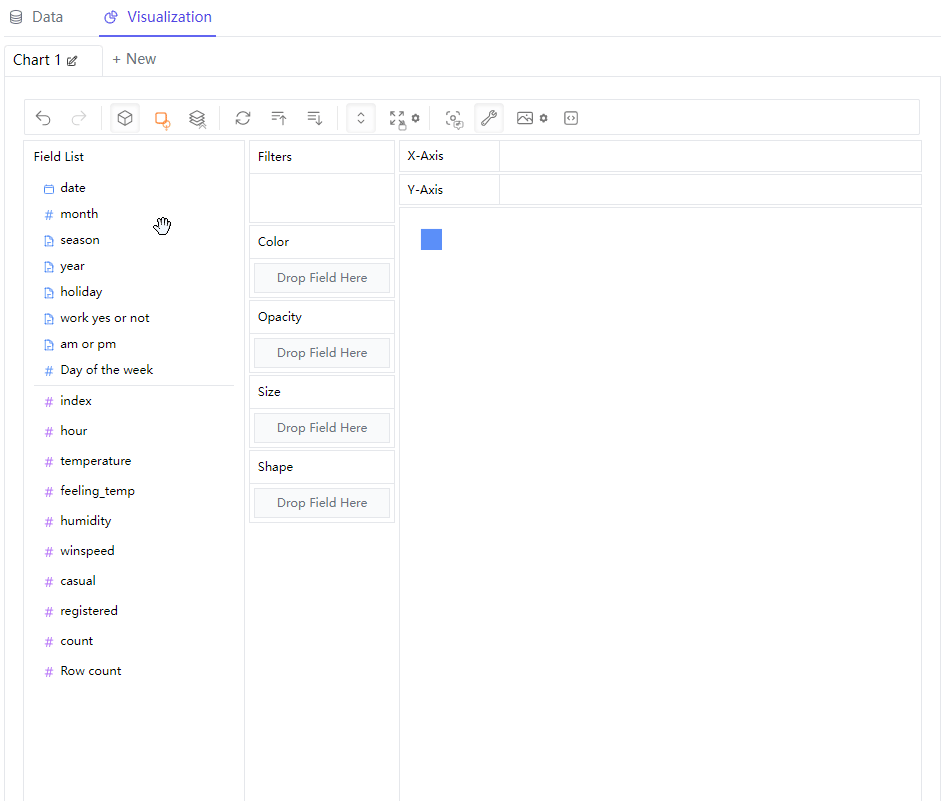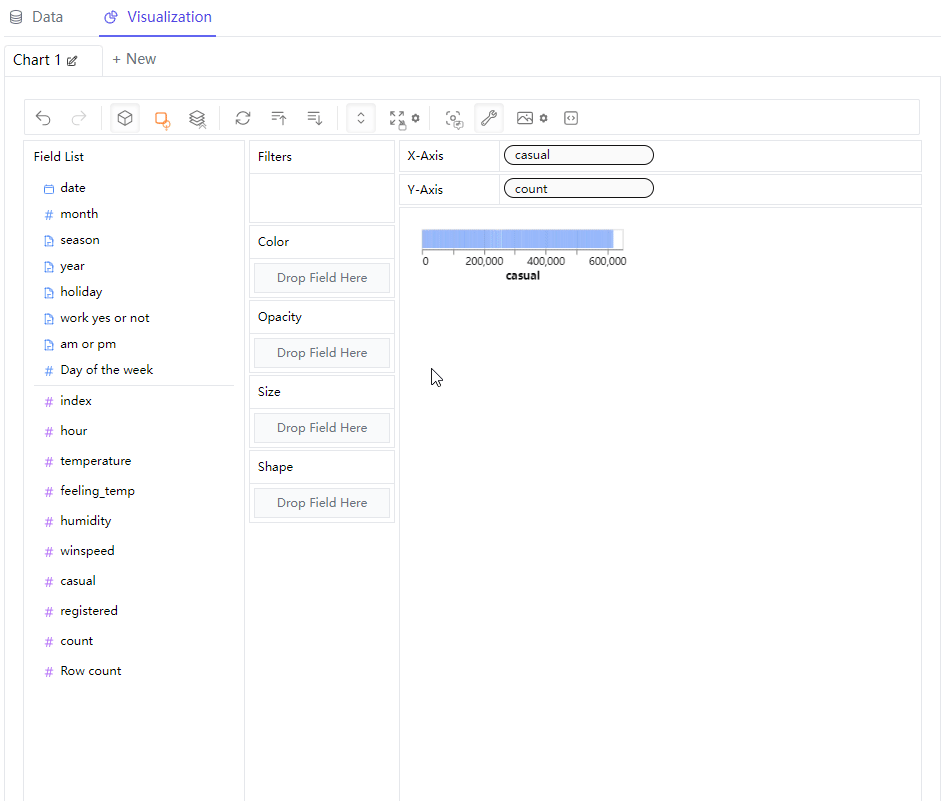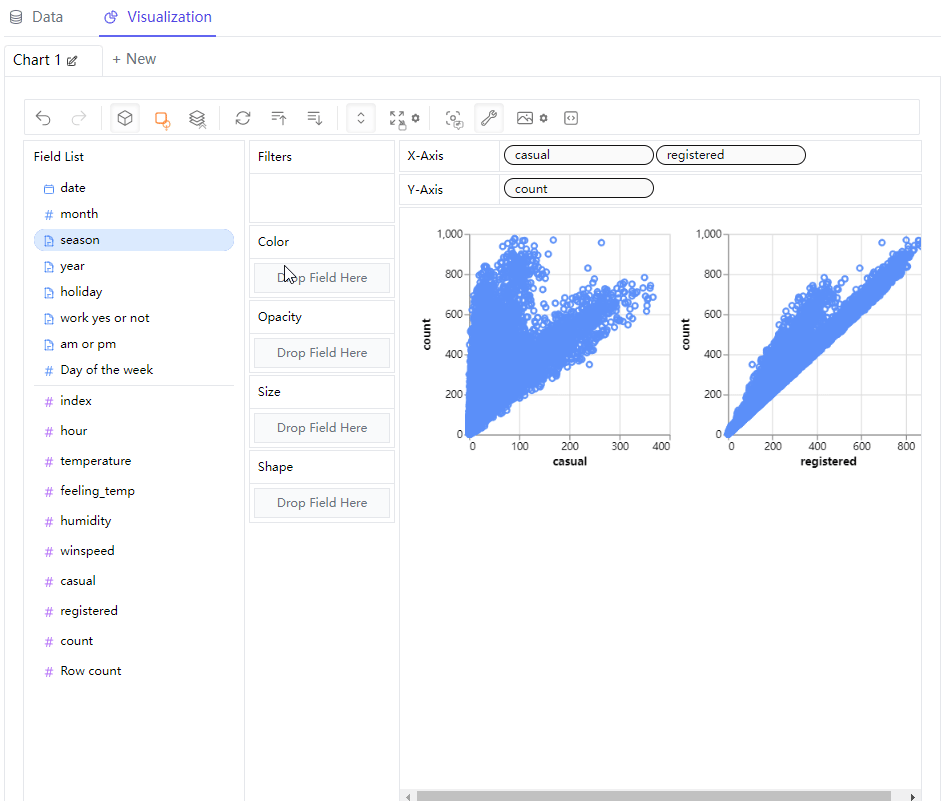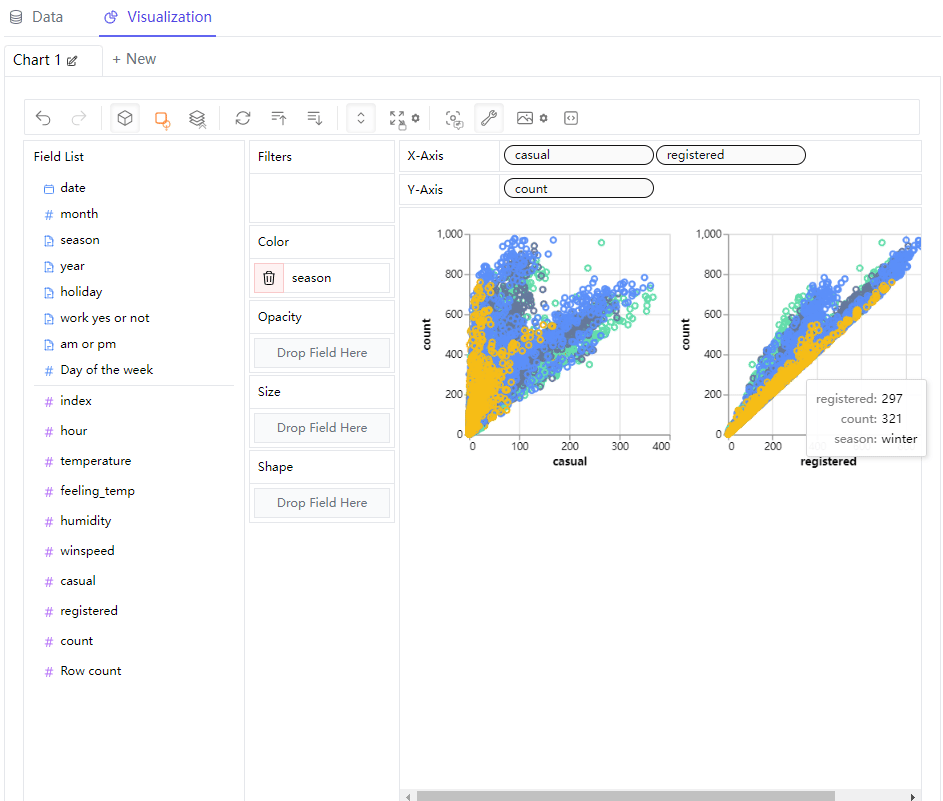
那么我们可以尝试绘制不同形态的图标,例如我们想要绘制折线图,例如我们在横轴放置的是“hour”这个离散型变量,"registered"字段也就是注册量作为纵轴,来查看不同时间段之下单车的使用量情况,同时在“Color”这一栏中放置的是“season”变量,代表的是不同的季节当中,不同时间段的单车App的注册量情况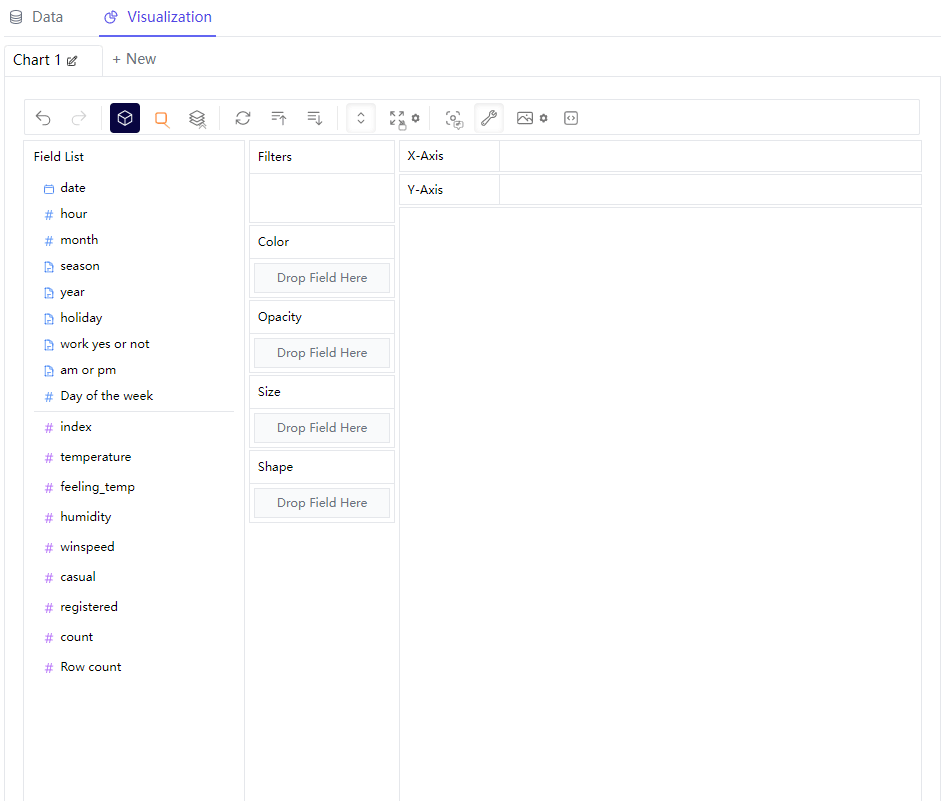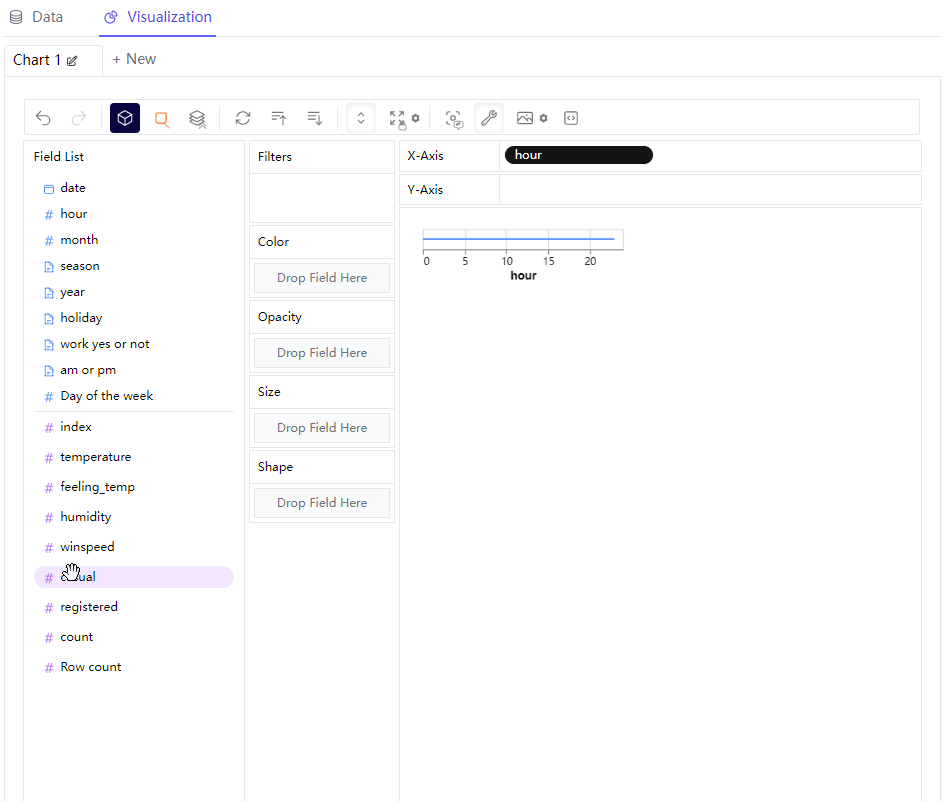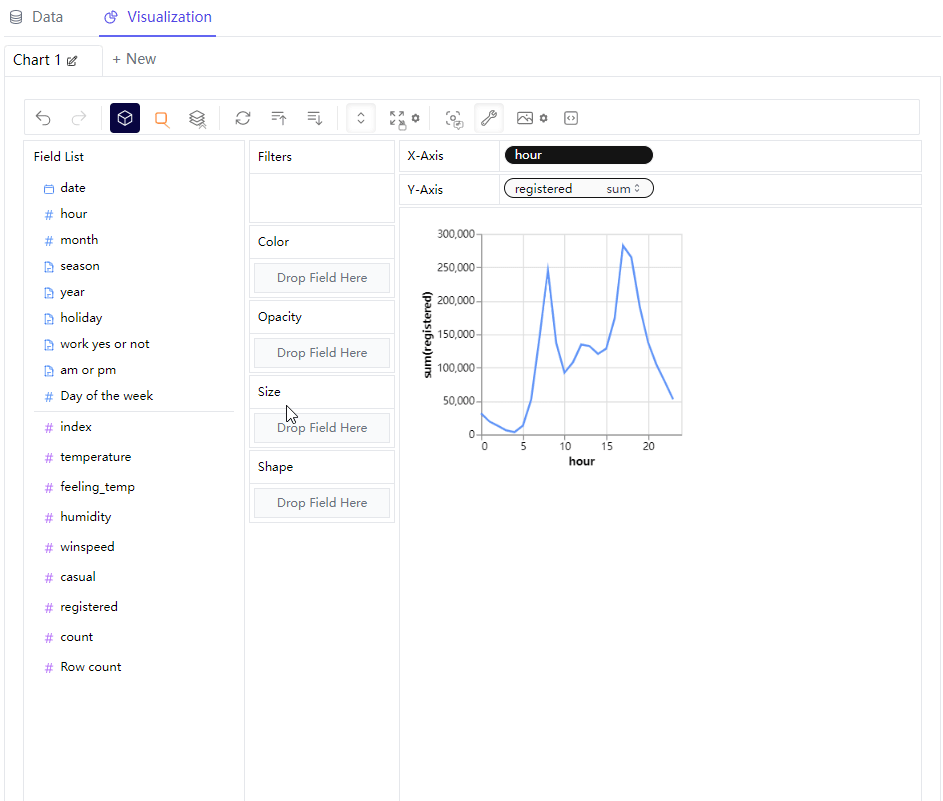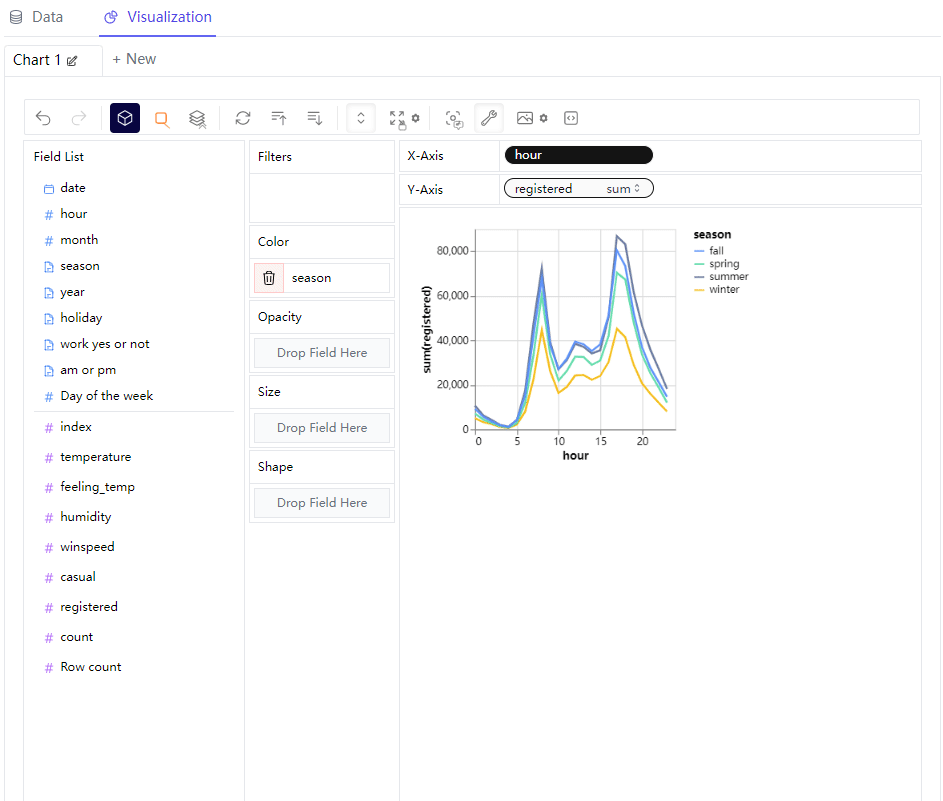
我们将图表的形态变成区域图,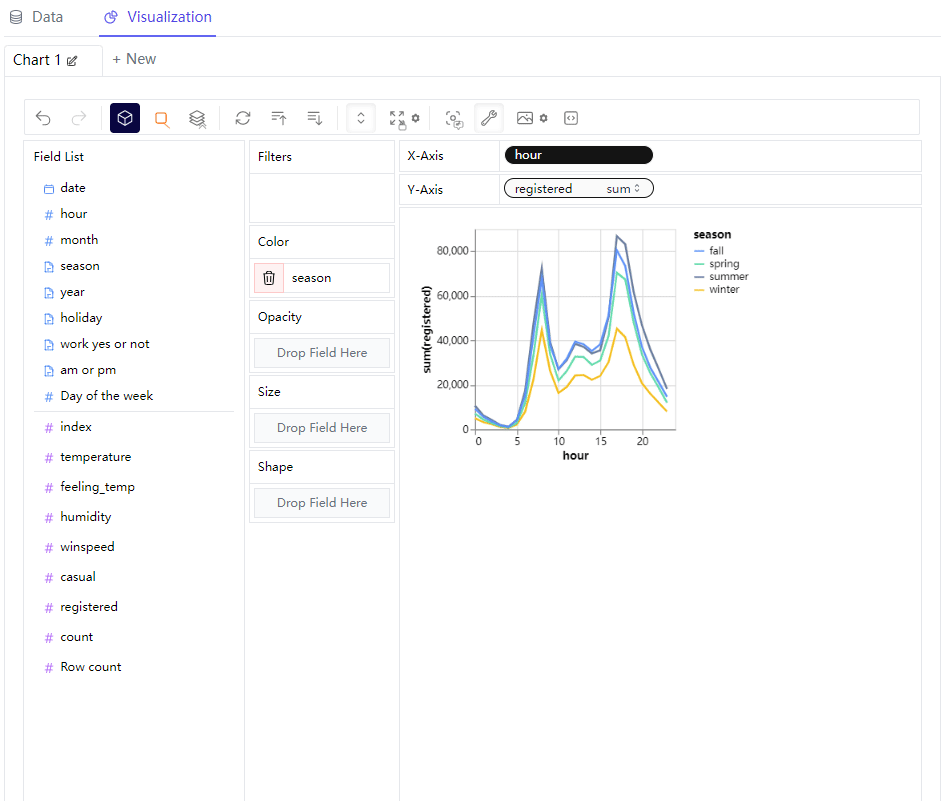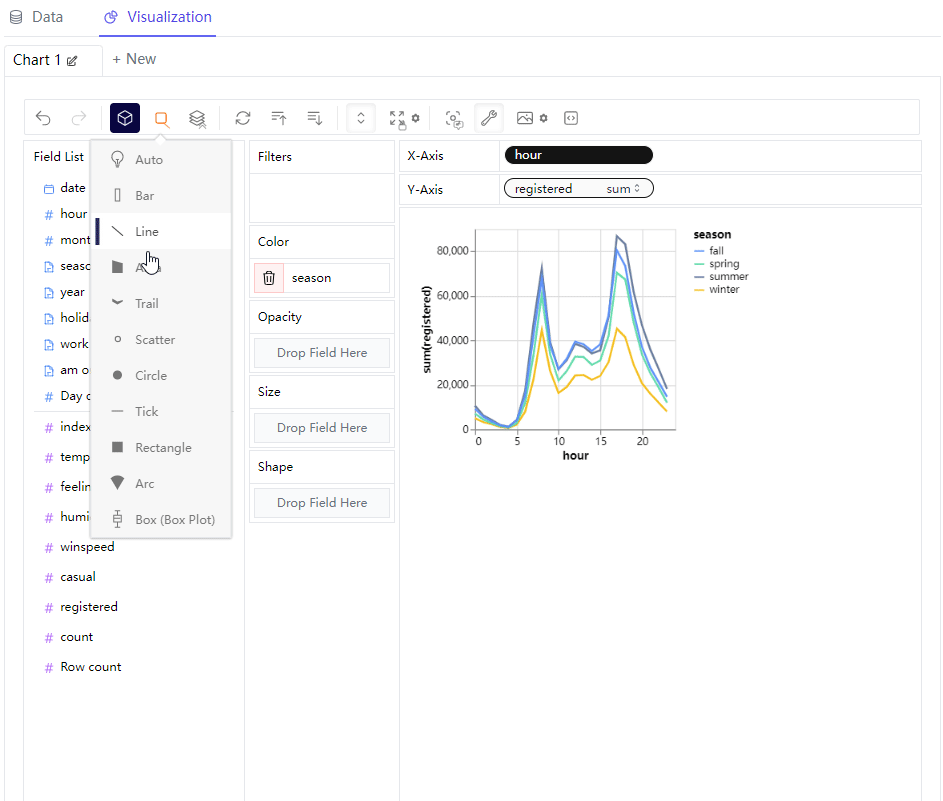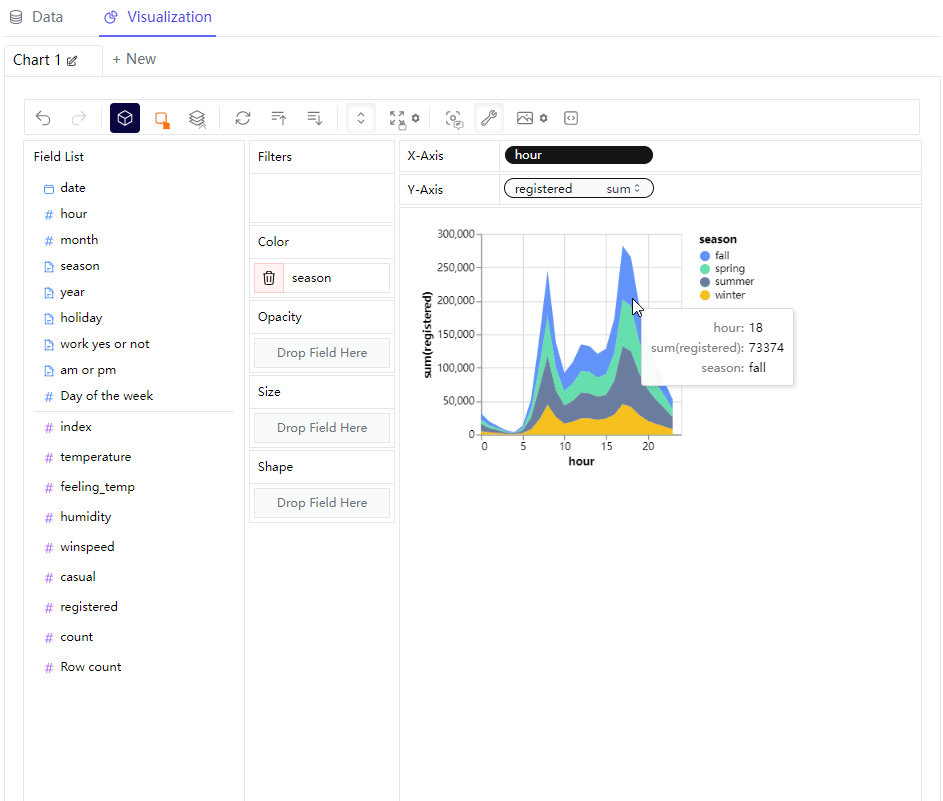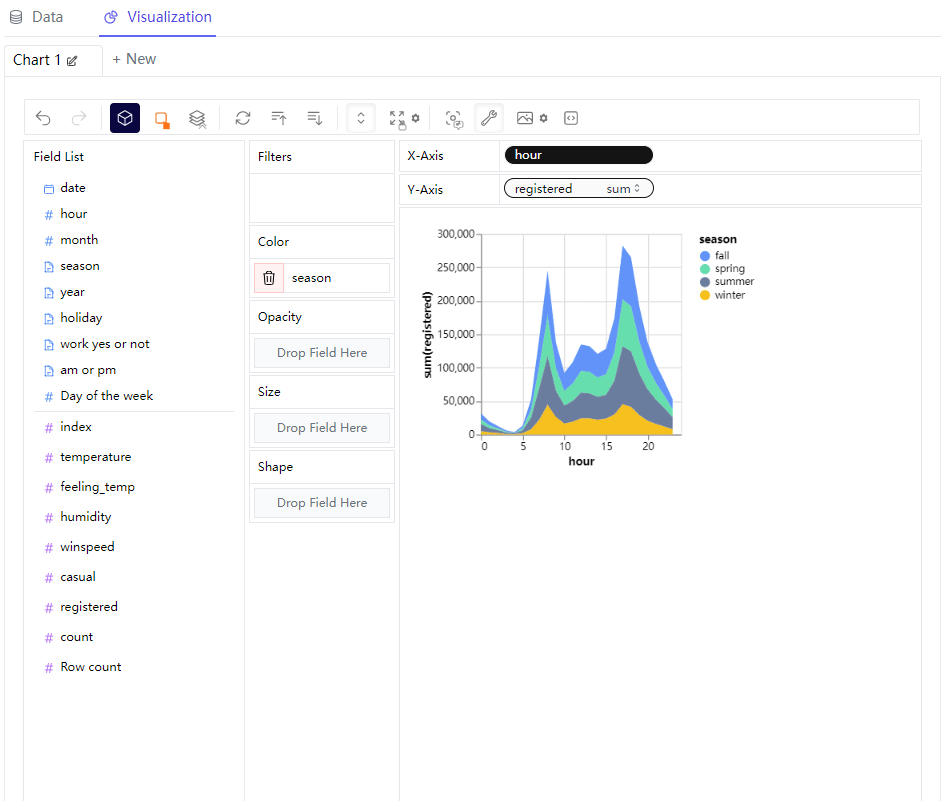
同时我们还可以来更改图表的大小,操作起来也十分的方便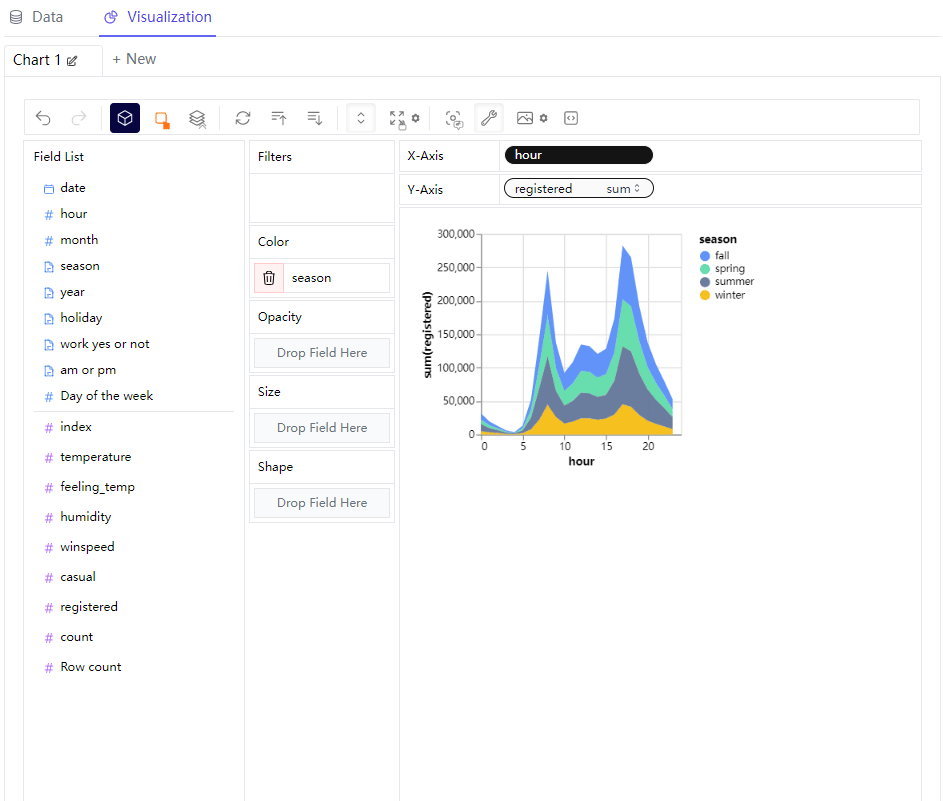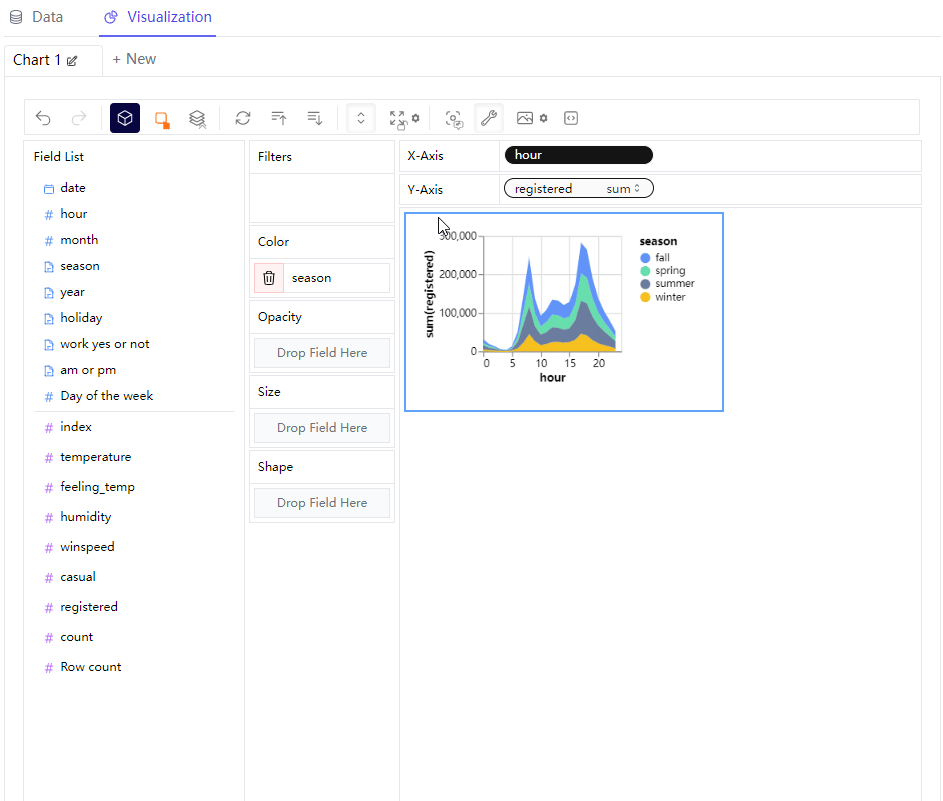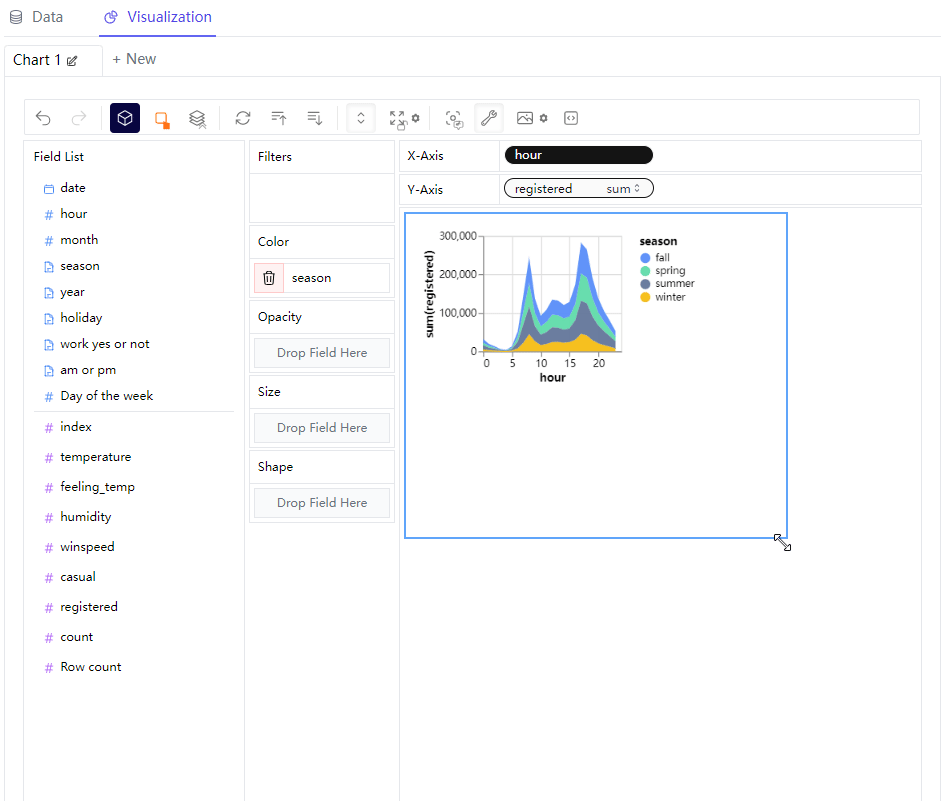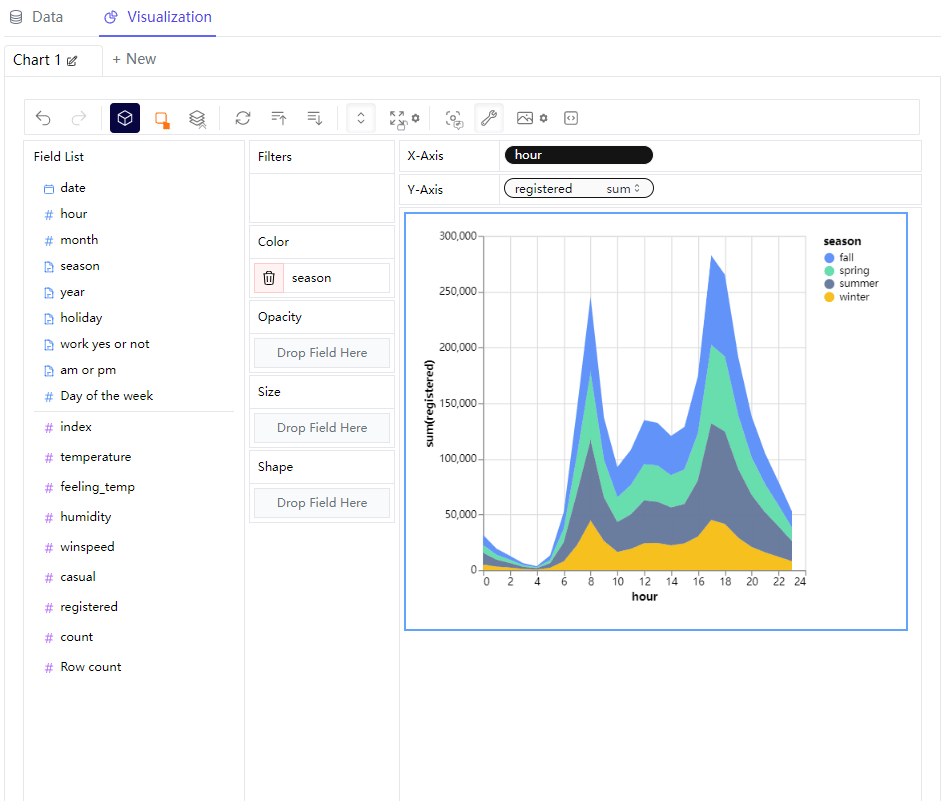
过滤数据
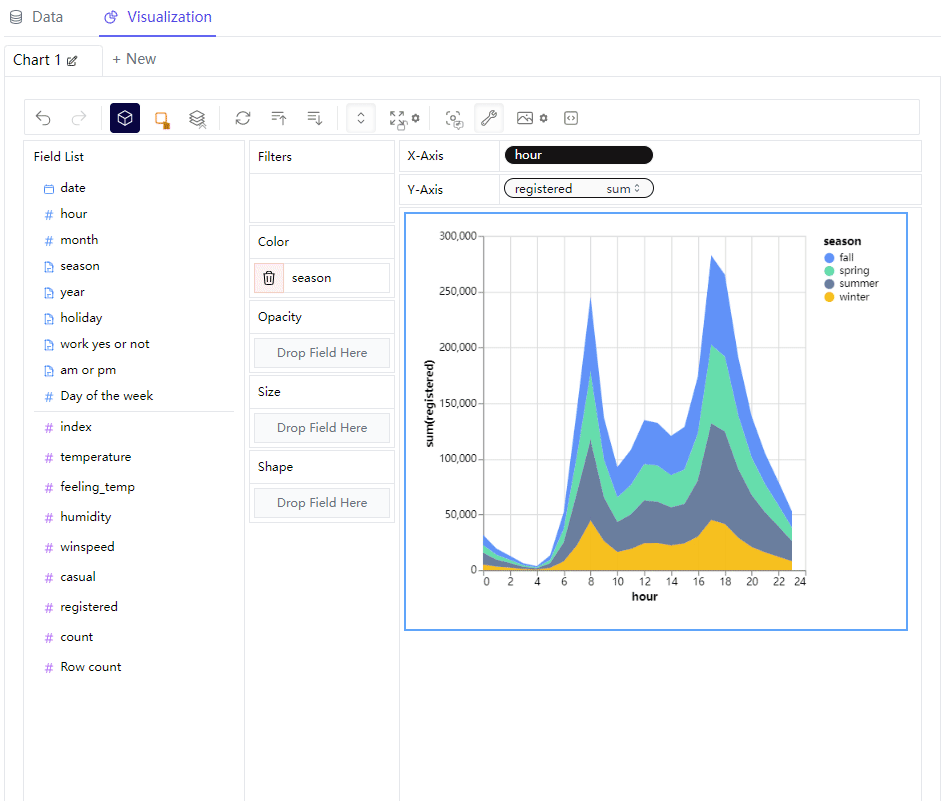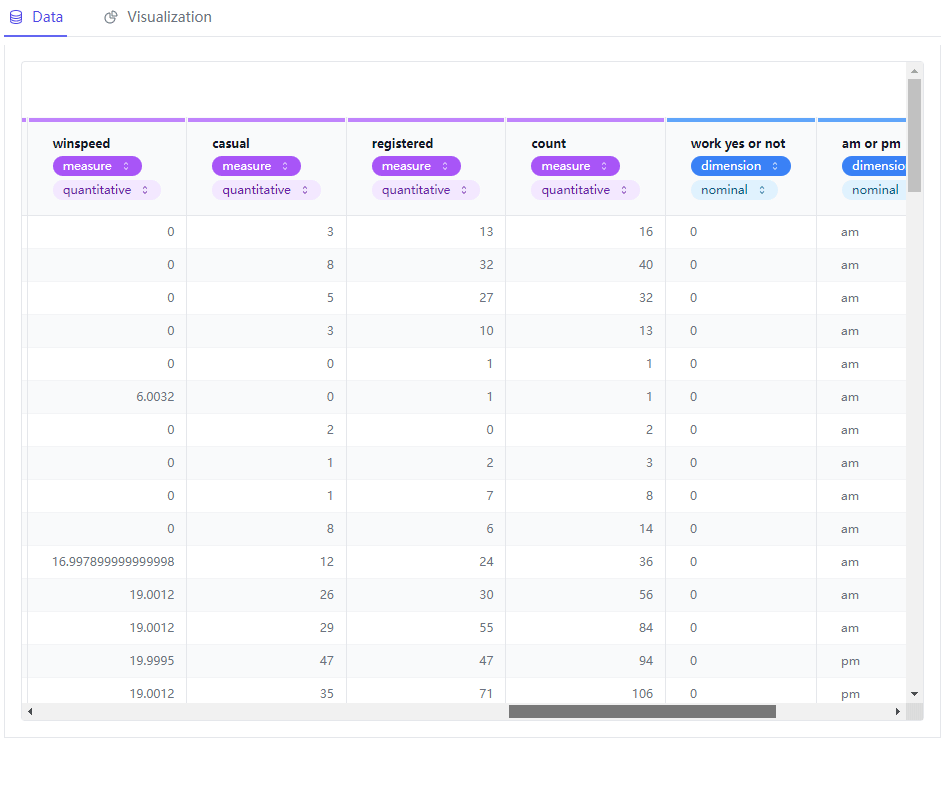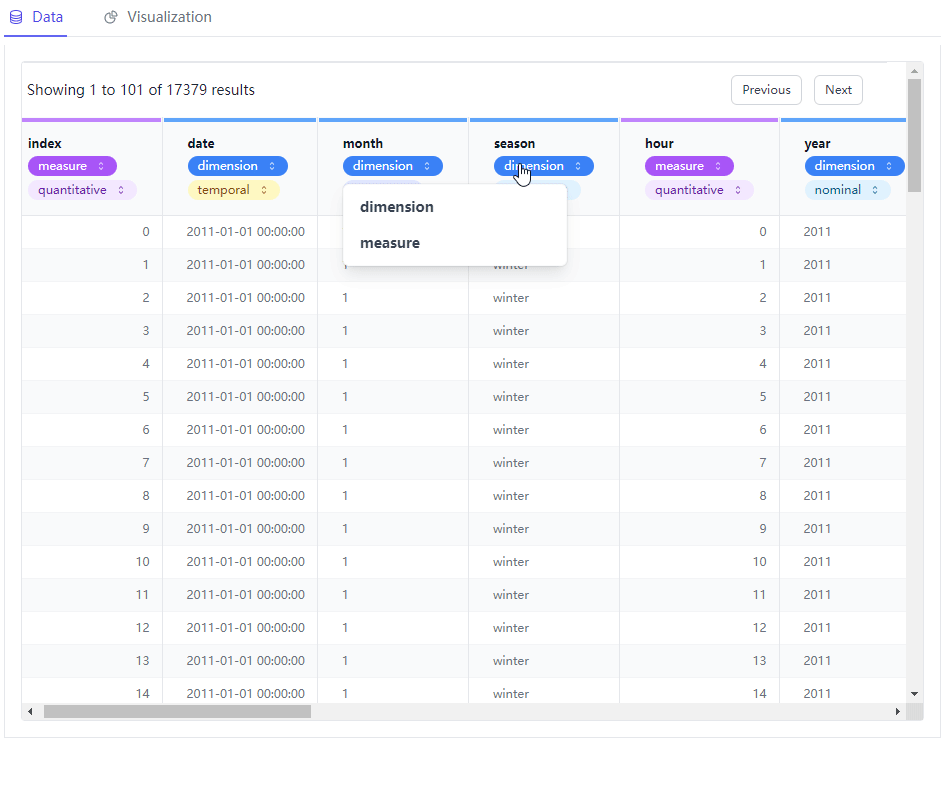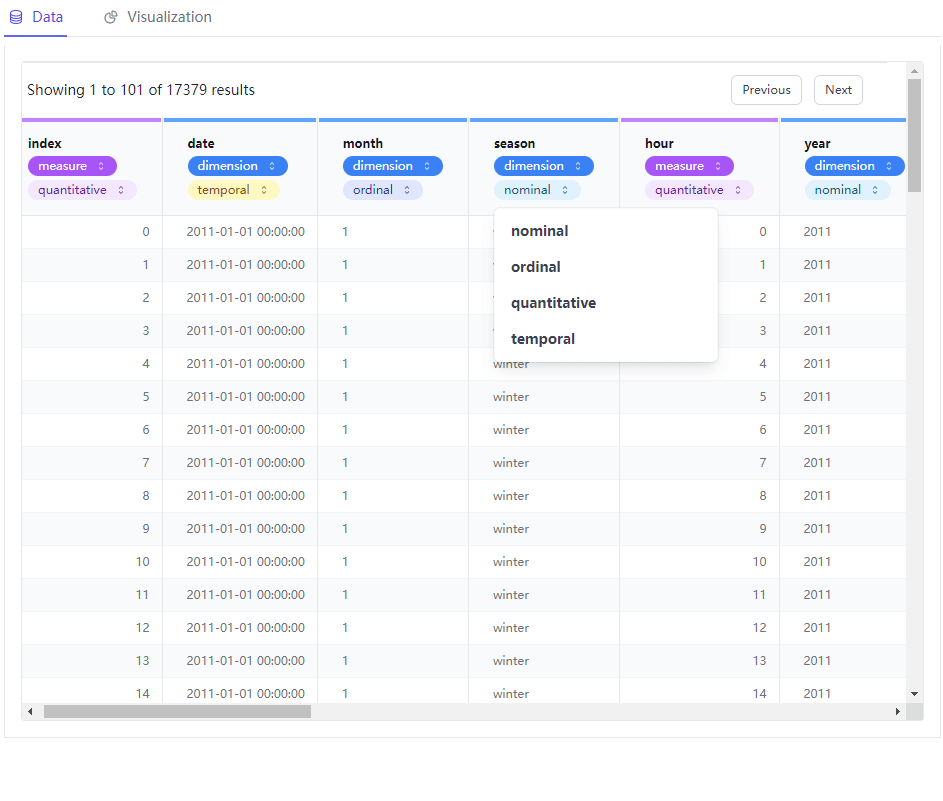
这里我们还可以来过滤数据,主要是在filter这一栏来进行操作,要是将离散型变量拖拽过去的话,可以指定筛选的条件是哪些,例如只查看“春天”和“夏天”这两者的数据,然后图表依据筛选出来的条件来呈现最终的样子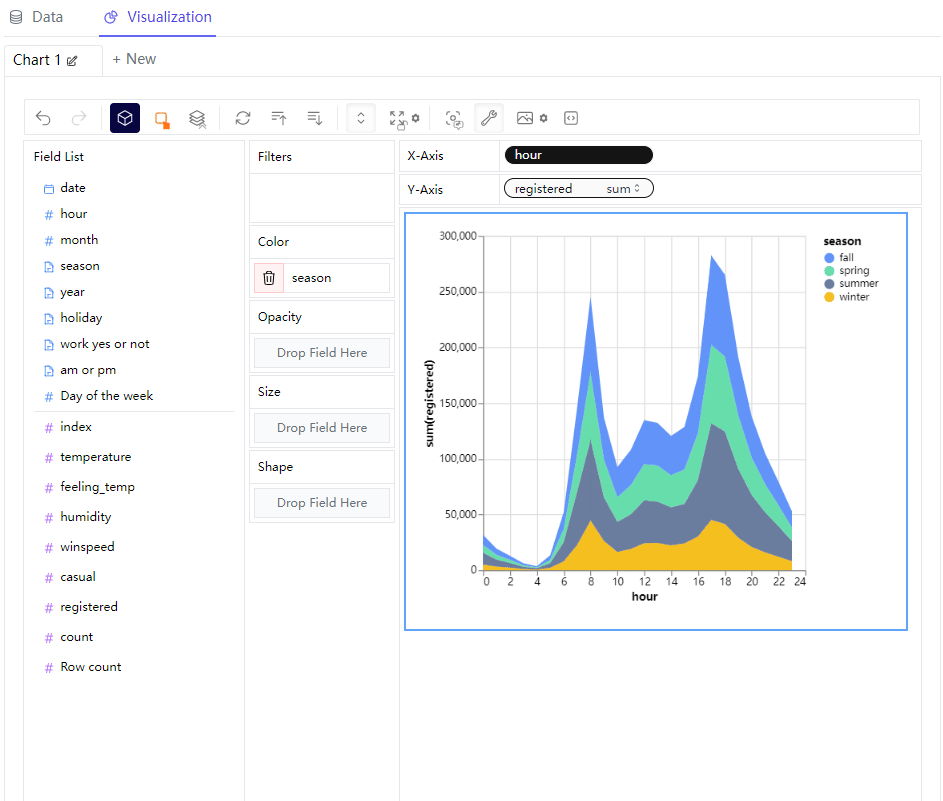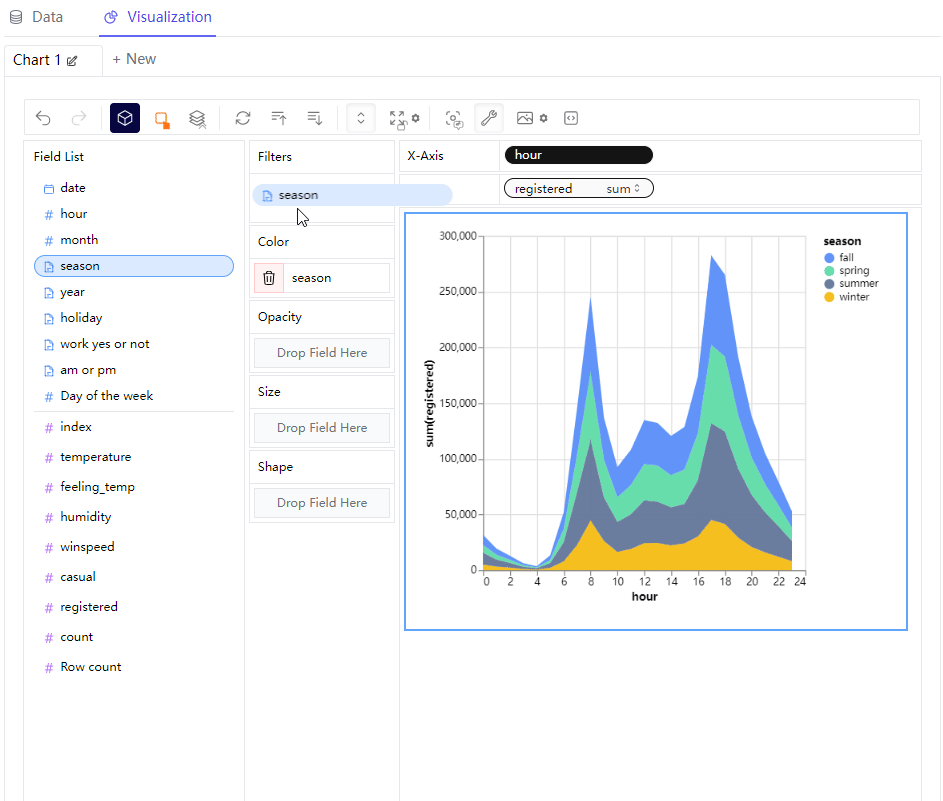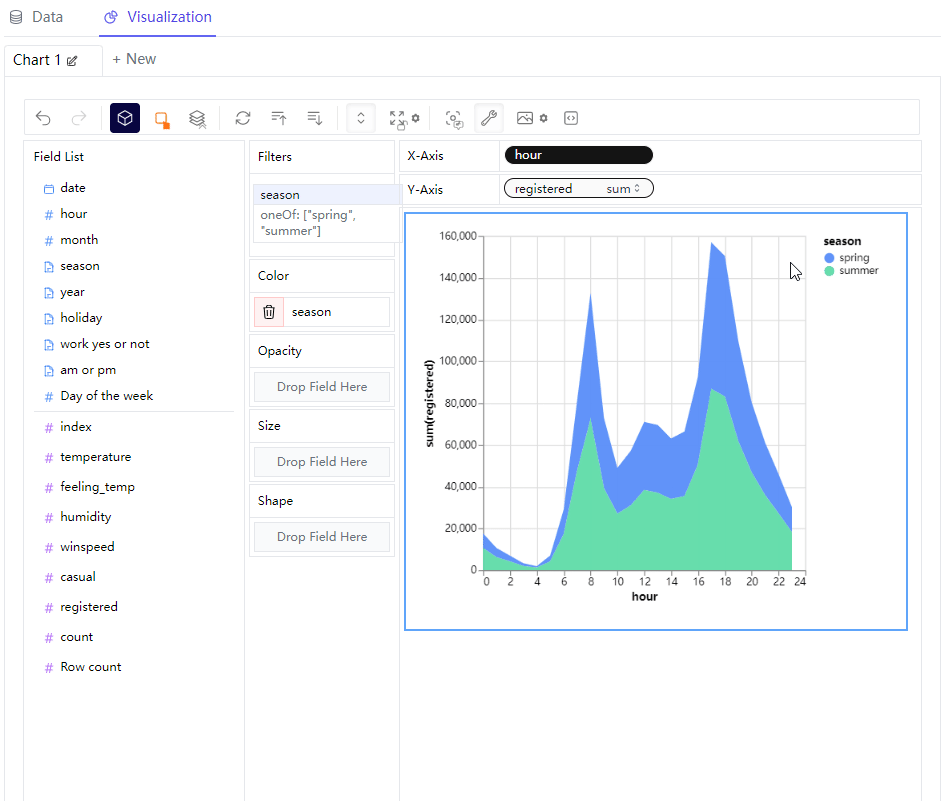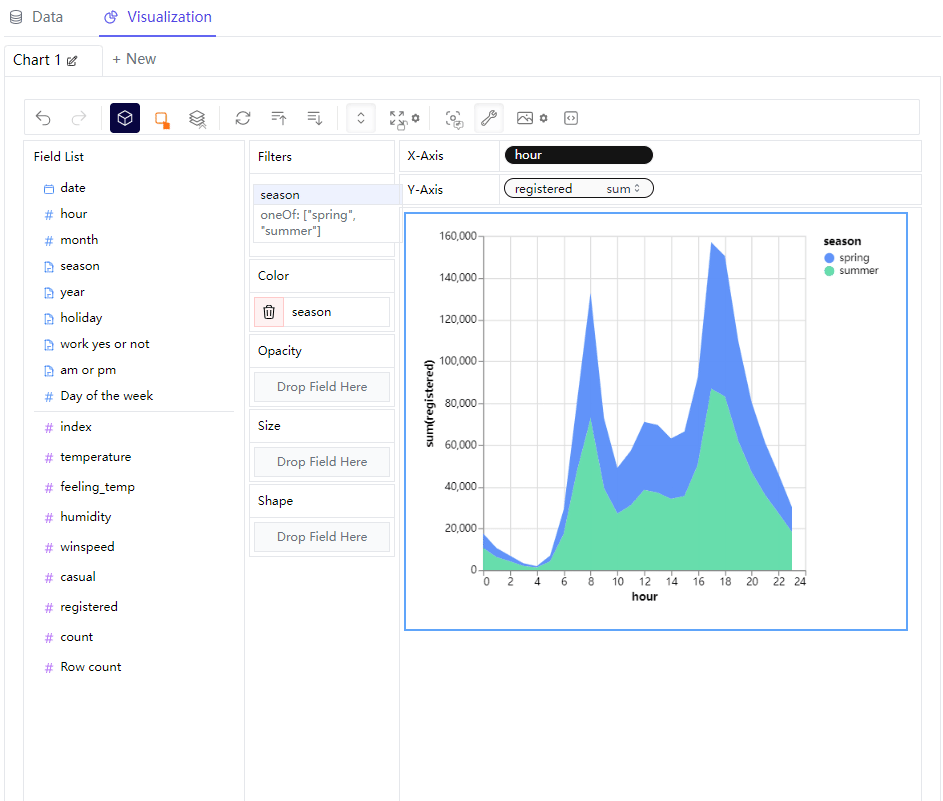
那么要是将数值型变量拖拽过去的话,会出来一个横向的数轴并且设定横轴的上下限,那么最终的图表也会根据筛选出来的条件来呈现最终的样子
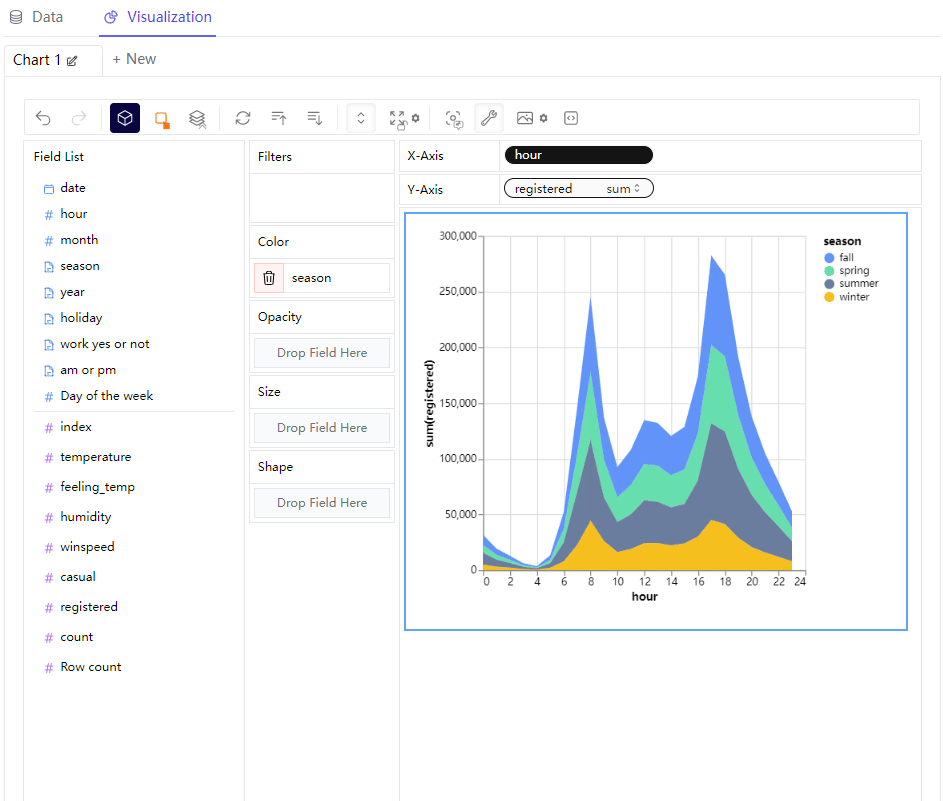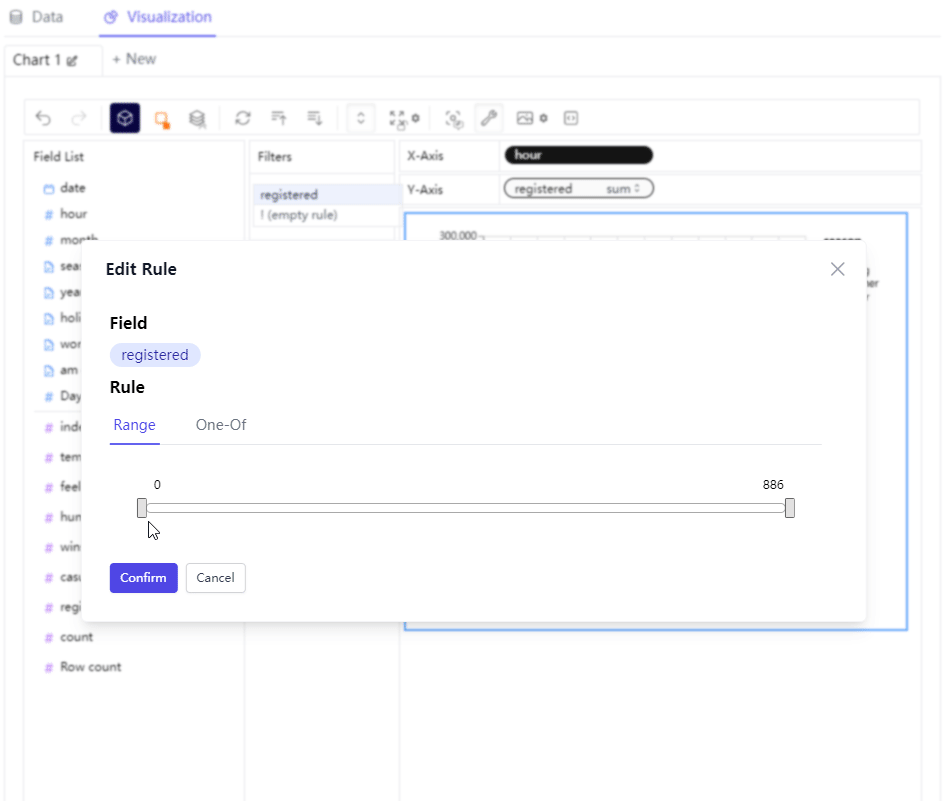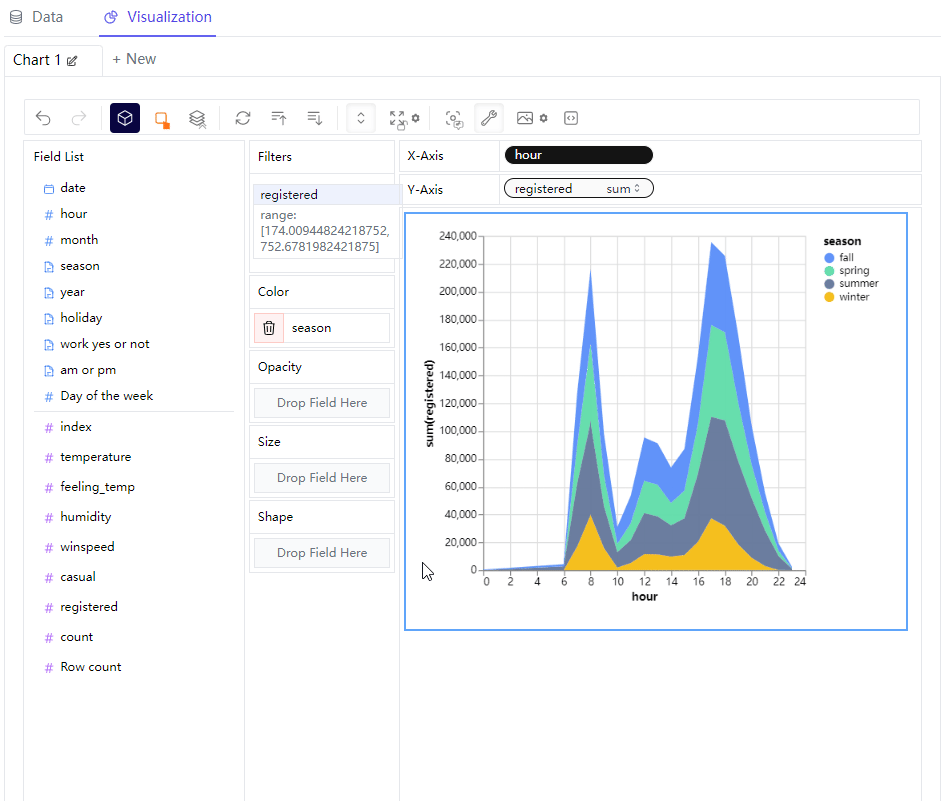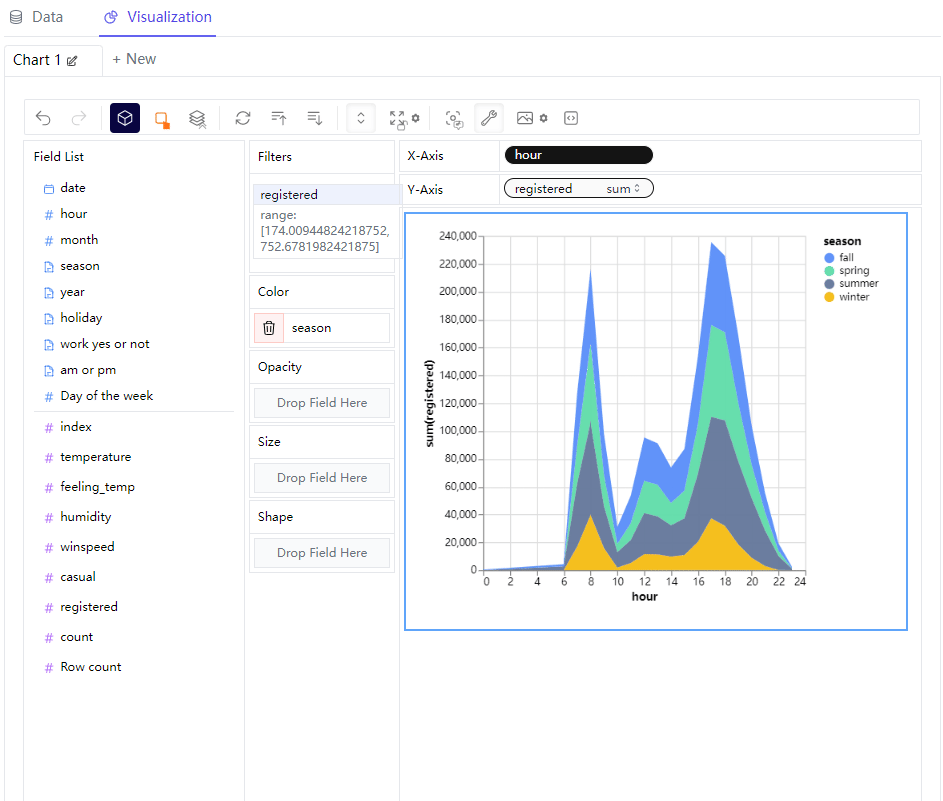
查看原始数据
最后要是我们想要查看原始数据,PyGWalker模块也提供了非常方便的途径,点击当中的“Data”选项