深度学习笔记——LSTM
大家好,这里是好评笔记,公主号:Goodnote,专栏文章私信限时Free。本文详细介绍面试过程中可能遇到的LSTM知识点。

文章目录
- LSTM(Long Short-Term Memory)
- LSTM 的核心部件
- LSTM 的公式和工作原理
- (1) 遗忘门(Forget Gate)
- (2) 输入门(Input Gate)
- (3) 更新记忆单元状态
- (4) 输出门(Output Gate)
- LSTM 的流程总结
- LSTM 的优点
- LSTM 的局限性
- 历史文章
- 机器学习
- 深度学习
LSTM(Long Short-Term Memory)
LSTM 是 RNN 的一种改进版本,旨在解决 RNN 的长时间依赖问题。LSTM 通过引入记忆单元(cell state) 和门控机制(gates) 来有效地控制信息流动,使得它在长序列建模中表现优异。
LSTM 的核心部件

LSTM 的核心结构由以下几部分组成:
- 记忆单元(Cell State):贯穿整个序列的数据流【图中的C】,能够存储序列中的重要信息,允许网络长时间保留重要的信息。
- 隐藏状态(Hidden State):每个时间步的输出,LSTM 通过它来决定当前的输出和对下一时间步的传递信息。【RNN中就有】
- 三个门控机制(Forget Gate、Input Gate、Output Gate):通过这些门控机制,LSTM 可以选择性地遗忘、存储、或者输出信息(具体在图中的结构参考下面具体介绍)。
LSTM 中最重要的概念是记忆单元状态和门控机制,它们帮助网络在长时间序列中保留重要的历史信息。
在 LSTM 中,隐藏状态是对当前时间步的即时记忆(短期记忆),而记忆单元是对整个序列中长期信息的存储(长期记忆)。
- 遗忘门(Forget Gate):根据当前输入和前一个时间步的隐藏状态,决定记忆单元哪些信息需要被遗忘;
- 输入门(Input Gate):根据当前输入和前一时间步的隐藏状态,决定当前时间步输入对记忆单元的影响;
- 输出门(Output Gate):根据当前的输入和前一时间步的隐藏状态以及记忆单元状态,决定当前时间步隐藏状态的输出/影响;(输出内容是从记忆单元中提取的信息);
LSTM 的公式和工作原理
在 LSTM 中,每个时间步 ( t ) 的计算分为以下几步:
图像参考:LSTM(长短期记忆网络)
(1) 遗忘门(Forget Gate)

- 计算公式:
f t = σ ( W f ⋅ [ h t − 1 , x t ] + b f ) f_t=\sigma(W_f\cdot[h_{t - 1},x_t]+b_f) ft=σ(Wf⋅[ht−1,xt]+bf)- f t f_t ft:遗忘门的输出,值介于0到1之间,表示记忆单元中的每个值需要被保留的比例。
- h t − 1 h_{t - 1} ht−1:上一时间步的隐藏状态(短期记忆)。
- x t x_t xt:当前时间步的输入。
- W f W_f Wf、 b f b_f bf:遗忘门的权重和偏置。
- σ \sigma σ:sigmoid函数,将值限制在0到1之间。
遗忘门的作用:它根据当前输入和前一个时间步的隐藏状态,选择哪些来自过去的记忆单元信息需要被遗忘。
(2) 输入门(Input Gate)

- 计算公式:
i t = σ ( W i ⋅ [ h t − 1 , x t ] + b i ) i_t=\sigma(W_i\cdot[h_{t - 1},x_t]+b_i) it=σ(Wi⋅[ht−1,xt]+bi)- i t i_t it:输入门的输出,值介于0到1之间,表示是否更新记忆单元。
- W i W_i Wi、 b i b_i bi:输入门的权重和偏置。
- 候选记忆生成:
C ~ t = tanh ( W c ⋅ [ h t − 1 , x t ] + b c ) \tilde{C}_t=\tanh(W_c\cdot[h_{t - 1},x_t]+b_c) C~t=tanh(Wc⋅[ht−1,xt]+bc)- C ~ t \tilde{C}_t C~t:候选记忆,是根据当前输入生成的新的记忆内容,值在 [ − 1 , 1 ] [- 1,1] [−1,1]之间。
- W c W_c Wc、 b c b_c bc:生成候选记忆的权重和偏置。
输入门的作用:输入门通过 sigmoid 激活函数决定当前输入 ( x t x_t xt ) 和前一时间步的隐藏状态 ( h t − 1 h_{t-1} ht−1 ) 对记忆单元的影响。结合候选记忆 ( C ~ t \tilde{C}_t C~t),输入门决定是否将当前输入的信息入到记忆单元中。
(3) 更新记忆单元状态

- 记忆单元状态更新公式:
C t = f t ∗ C t − 1 + i t ∗ C ~ t C_t=f_t*C_{t - 1}+i_t*\tilde{C}_t Ct=ft∗Ct−1+it∗C~t- f t ∗ C t − 1 f_t*C_{t - 1} ft∗Ct−1:遗忘门决定了哪些来自前一时间步的记忆单元信息被保留。
- i t ∗ C ~ t i_t*\tilde{C}_t it∗C~t:输入门决定了新的候选记忆 C ~ t \tilde{C}_t C~t需要被加入到记忆单元中的比例。
记忆单元的作用:记忆单元 ( C t C_t Ct ) 根据遗忘门和输入门的输出,保留了来自过去的长期信息,使得重要的历史信息能够长时间存储。
(4) 输出门(Output Gate)
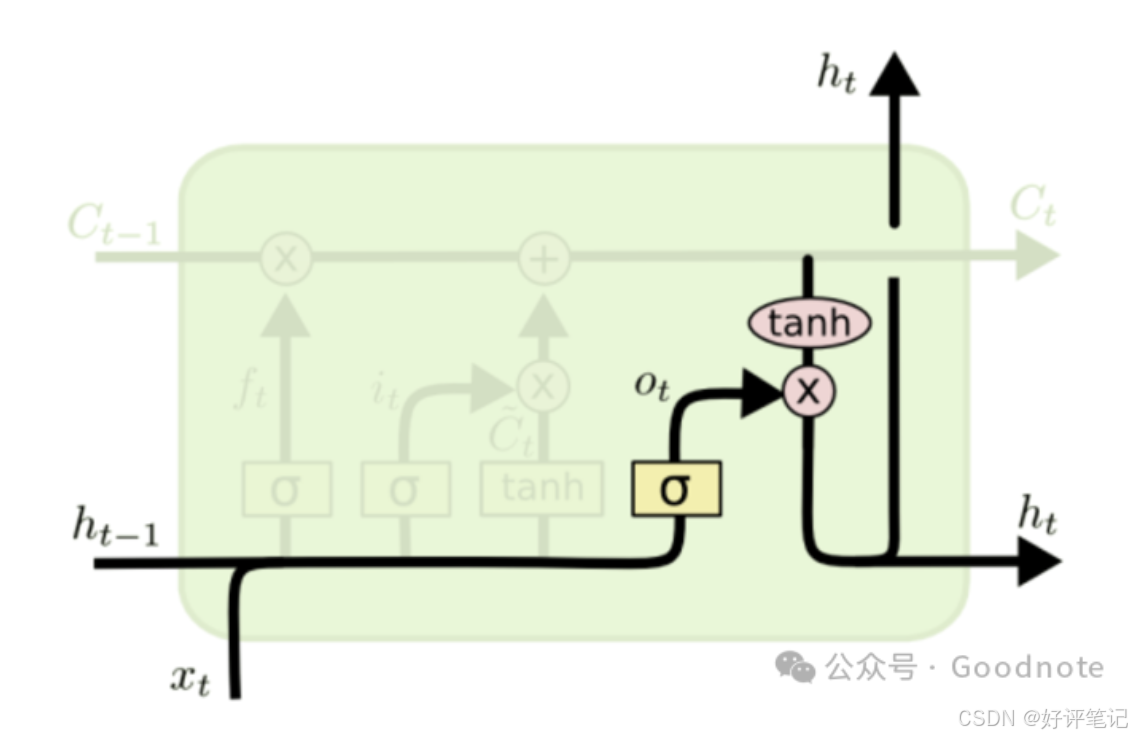
输出门控制从记忆单元中提取多少信息作为当前时间步的隐藏状态 h t h_t ht 并输出。
- 计算公式:
o t = σ ( W o ⋅ [ h t − 1 , x t ] + b o ) o_t=\sigma(W_o\cdot[h_{t - 1},x_t]+b_o) ot=σ(Wo⋅[ht−1,xt]+bo)- o t o_t ot:输出门的输出,决定隐藏状态的输出比例。
- W o W_o Wo、 b o b_o bo:输出门的权重和偏置。
- 生成当前隐藏状态:
h t = o t ∗ tanh ( C t ) h_t=o_t*\tanh(C_t) ht=ot∗tanh(Ct)- tanh ( C t ) \tanh(C_t) tanh(Ct):对当前的记忆单元状态 C t C_t Ct进行非线性变换,生成当前时间步的隐藏状态。
- 输出门 o t o_t ot决定了多少信息从记忆单元状态 C t C_t Ct中提取,并输出为当前时间步的隐藏状态。
输出门的作用:输出门根据当前的输入和前一时间步的隐藏状态以及记忆单元状态,决定当前的隐藏状态 ( h t h_t ht ) 的值,它不仅作为当前时间步的输出,还会传递到下一时间步。
LSTM 的流程总结
在每个时间步 ( t t t ),LSTM 会执行以下步骤:
- 遗忘门:根据当前输入和前一个时间步的隐藏状态,控制哪些来自上一个时间步的记忆单元信息需要被保留或遗忘。
- 输入门:根据当前输入和前一时间步的隐藏状态,决定当前输入信息是否更新到记忆单元中,通过候选记忆生成新的信息。
- 记忆单元状态更新:根据遗忘门和输入门的输出,更新当前时间步的记忆单元状态 ( C t C_t Ct )。
- 输出门:根据当前的输入和记忆单元状态,控制当前时间步的隐藏状态 ( h t h_t ht ) 的输出,隐藏状态会传递到下一时间步,作为当前的输出结果。
LSTM 的优点
LSTM 通过引入门控机制,可以选择性地控制信息的流动;记忆单元可以有效地保留长期信息,避免了传统 RNN 中的梯度消失问题。因此,LSTM 能够同时处理短期和长期的依赖关系,尤其在需要保留较长时间跨度信息的任务中表现优异。
LSTM 的局限性
LSTM 的门控机制使得它的结构复杂,训练时间较长,需要更多的计算资源,尤其是在处理大规模数据时。依赖于序列数据的时间步信息,必须按顺序处理每个时间步,难以并行化处理序列数据。
历史文章
机器学习
机器学习笔记——损失函数、代价函数和KL散度
机器学习笔记——特征工程、正则化、强化学习
机器学习笔记——30种常见机器学习算法简要汇总
机器学习笔记——感知机、多层感知机(MLP)、支持向量机(SVM)
机器学习笔记——KNN(K-Nearest Neighbors,K 近邻算法)
机器学习笔记——朴素贝叶斯算法
机器学习笔记——决策树
机器学习笔记——集成学习、Bagging(随机森林)、Boosting(AdaBoost、GBDT、XGBoost、LightGBM)、Stacking
机器学习笔记——Boosting中常用算法(GBDT、XGBoost、LightGBM)迭代路径
机器学习笔记——聚类算法(Kmeans、GMM-使用EM优化)
机器学习笔记——降维
深度学习
深度学习笔记——优化算法、激活函数
深度学习——归一化、正则化
深度学习笔记——前向传播与反向传播、神经网络(前馈神经网络与反馈神经网络)、常见算法概要汇总
深度学习笔记——卷积神经网络CNN