自然语言处理:高斯混合模型
介绍
大家好,博主又来给大家分享知识了,今天给大家分享的内容是自然语言处理中的高斯混合模型。
在自然语言处理这个充满挑战与机遇的领域,我们常常面临海量且复杂的文本数据。如何从这些数据中挖掘出有价值的信息,对文本进行有效的分类、聚类等操作,一直是研究人员和从业者努力攻克的难题。而高斯混合模型,就像是一把神奇的钥匙,为我们打开了一扇深入理解和处理文本数据的新大门。
高斯混合模型,英文简称为GMM(Gaussian Mixture Model)。它并不是一个单一的模型,而是多个高斯分布的巧妙组合。好了,话不多说,我们直接进入正题。
高斯混合模型
在自然语言处理(NLP)的复杂领域中,对文本数据进行精准建模和有效分析是实现诸多任务的关键,如文本分类、情感分析、主题模型构建等。高斯混合模型(Gaussian Mixture Model,GMM)作为一种强大的概率模型,在自然语言处理中发挥着独特且重要的作用。它能够通过对数据分布的拟合,挖掘文本数据中的潜在结构和特征。
基础概念
高斯分布
又叫正态分布,高斯分布是一种常见的概率分布,在自然界和许多领域都有广泛应用。其概率密度函数为:
其中,是均值,决定了分布的中心位置;
是方差,控制了分布的离散程度。例如,在学生考试成绩的分布中,成绩往往呈现出以平均成绩为中心,向两侧逐渐分散的趋势,这就近似符合高斯分布。在自然语言处理中,我们可以将文本的某些特征(如词频分布等)看作是符合高斯分布的变量。
高斯混合模型
高斯混合模型是由多个高斯分布组合而成的概率模型。假设存在 个高斯分布,每个高斯分布都有自己的均值
、方差
和权重
。那么,高斯混合模型的概率密度函数可以表示为:
直观地理解,高斯混合模型可以看作是多个高斯分布的“混合体”,每个高斯分布代表了数据中的一种潜在模式。在文本处理中,不同的高斯分布可以对应不同主题的文本,比如一个高斯分布代表科技类文本,另一个代表娱乐类文本等。通过对文本特征的建模,高斯混合模型能够将文本按照不同的潜在主题进行聚类。
期望最大化算法
期望最大化(Expectation - Maximization,EM)算法用于训练高斯混合模型(Gaussian Mixture Model,GMM),是借助EM算法来确定GMM中的参数,使得模型能够尽可能准确地拟合给定的数据。
期望最大化(EM)算法是训练高斯混合模型的常用方法。它是一个迭代的过程,主要包含两个步骤:
E步(期望步骤):根据当前模型参数(均值、方差和权重),计算每个数据点属于每个高斯分布的概率,即后验概率。这里
表示数据点属于第
个高斯分布,
是第
个数据点。通过贝叶斯公式计算:
M步(最大化步骤):利用E步计算得到的后验概率,更新模型的参数(均值、方差和权重)。
- 权重更新公式:
- 均值更新公式:
- 方差更新公式:
通过不断迭代E步和M步,直到模型参数收敛(即参数的变化小于某个预设的阈值),就可以得到一组相对较优的模型参数,从而完成高斯混合模型的训练。
代码实现
我们实现一个基于Python的高斯混合模型(Gaussian Mixture Model, GMM)的测试代码。高斯混合模型是一种用于对数据进行概率密度估计和聚类的强大工具,它假设数据是由多个高斯分布混合而成的。
完整代码
# 导入os模块,用于与操作系统进行交互,比如设置环境变量等操作
import os
# 导入numpy库,别名np,用于进行高效的数值计算和数组操作
import numpy as np
# 导入matplotlib库,用于绘制图形和可视化数据
import matplotlib
# 设置matplotlib的后端为tkAgg,这是一种图形用户界面后端,用于显示图形窗口
matplotlib.use('tkAgg')
# 定义一个字典config,用于设置matplotlib的字体和符号显示配置
config = {
"font.family": 'serif', # 设置字体族为衬线字体
"mathtext.fontset": 'stix', # 设置数学文本的字体集为stix
"font.serif": 'SimSun', # 设置衬线字体为宋体
'axes.unicode_minus': False # 解决负号显示问题
}
# 使用update方法将配置字典应用到matplotlib的全局参数中
matplotlib.rcParams.update(config)
# 从matplotlib中导入pyplot子模块,别名plt,用于绘制各种图形
import matplotlib.pyplot as plt
# 从sklearn库的mixture模块中导入GaussianMixture类,用于实现高斯混合模型
from sklearn.mixture import GaussianMixture
# 定义一个名为GaussianMixtureClustering的类,用于实现高斯混合模型聚类
class GaussianMixtureClustering:
# 类的初始化方法,用于设置类的属性初始值
def __init__(self, random_seed=50, n_components=2, figsize=(10, 6)):
# 初始化随机数种子,保证每次运行代码时生成的随机数相同,便于结果复现
self.random_seed = random_seed
# 初始化高斯分布的数量,即高斯混合模型中包含的高斯分量的个数
self.n_components = n_components
# 初始化图形窗口的大小,单位为英寸
self.figsize = figsize
# 初始化数据集,用于存储生成的样本数据
self.X = None
# 初始化高斯混合模型对象,后续用于模型训练和预测
self.gmm = None
# 初始化预测的类别标签,用于存储模型对数据的分类结果
self.labels = None
# 定义生成数据的方法,用于创建符合特定分布的数据集
def generate_data(self):
# 设置随机数种子,确保每次运行生成的数据相同
np.random.seed(self.random_seed)
# 生成100个符合二维多元正态分布的数据点,均值为 [0, 0],协方差矩阵为 [[1, 0], [0, 1]]
X1 = np.random.multivariate_normal(mean=[0, 0], cov=[[1, 0], [0, 1]], size=100)
# 生成100个符合二维多元正态分布的数据点,均值为 [5, 5],协方差矩阵为 [[1, 0], [0, 1]]
X2 = np.random.multivariate_normal(mean=[5, 5], cov=[[1, 0], [0, 1]], size=100)
# 将X1和X2这两个数组在垂直方向上堆叠,形成一个新的数据集X
self.X = np.vstack([X1, X2])
# 定义训练模型的方法,使用生成的数据集对高斯混合模型进行训练
def train_model(self):
# 创建一个GaussianMixture模型对象,设置高斯分布的数量为初始化时指定的值
self.gmm = GaussianMixture(n_components=self.n_components)
# 使用数据集X对高斯混合模型进行训练,让模型学习数据的分布特征
self.gmm.fit(self.X)
# 定义预测标签的方法,使用训练好的模型对数据集进行预测
def predict_labels(self):
# 使用训练好的高斯混合模型对数据集X进行预测,得到每个数据点所属的类别标签
self.labels = self.gmm.predict(self.X)
# 定义可视化结果的方法,将聚类结果以图形的形式展示出来
def visualize_results(self):
# 创建一个新的图形窗口,设置窗口的大小为初始化时指定的值
plt.figure(figsize=self.figsize)
# 绘制散点图,将数据集X的第一列作为x轴坐标,第二列作为y轴坐标
# 用标签labels来确定每个点的颜色,使用viridis颜色映射,点的大小为50,边缘颜色为黑色
plt.scatter(self.X[:, 0], self.X[:, 1], c=self.labels, cmap='viridis', s=50, edgecolor='k')
# 获取高斯混合模型中每个高斯分布的均值
means = self.gmm.means_
# 绘制每个高斯分布的均值点,颜色为红色,大小为200,标记形状为X
plt.scatter(means[:, 0], means[:, 1], c='red', s=200, marker='X')
# 设置图形的标题为'高斯混合模型聚类'
plt.title('高斯混合模型聚类')
# 设置x轴的标签为'特征 1'
plt.xlabel('特征1')
# 设置y轴的标签为'特征 2'
plt.ylabel('特征2')
# 显示绘制好的图形
plt.show()
# 定义运行方法,依次调用生成数据、训练模型、预测标签和可视化结果的方法
def run(self):
# 调用generate_data方法生成数据集
self.generate_data()
# 调用train_model方法对模型进行训练
self.train_model()
# 调用predict_labels方法进行标签预测
self.predict_labels()
# 调用visualize_results方法可视化聚类结果
self.visualize_results()
# 主程序入口,确保代码作为脚本直接运行时才会执行以下代码
if __name__ == "__main__":
# 设置环境变量LOKY_MAX_CPU_COUNT为4,用于限制并行计算时使用的CPU核心数
os.environ['LOKY_MAX_CPU_COUNT'] = '4'
# 创建GaussianMixtureClustering类的实例,使用默认参数
clustering = GaussianMixtureClustering()
# 调用实例的run方法,执行整个聚类流程
clustering.run()运行结果
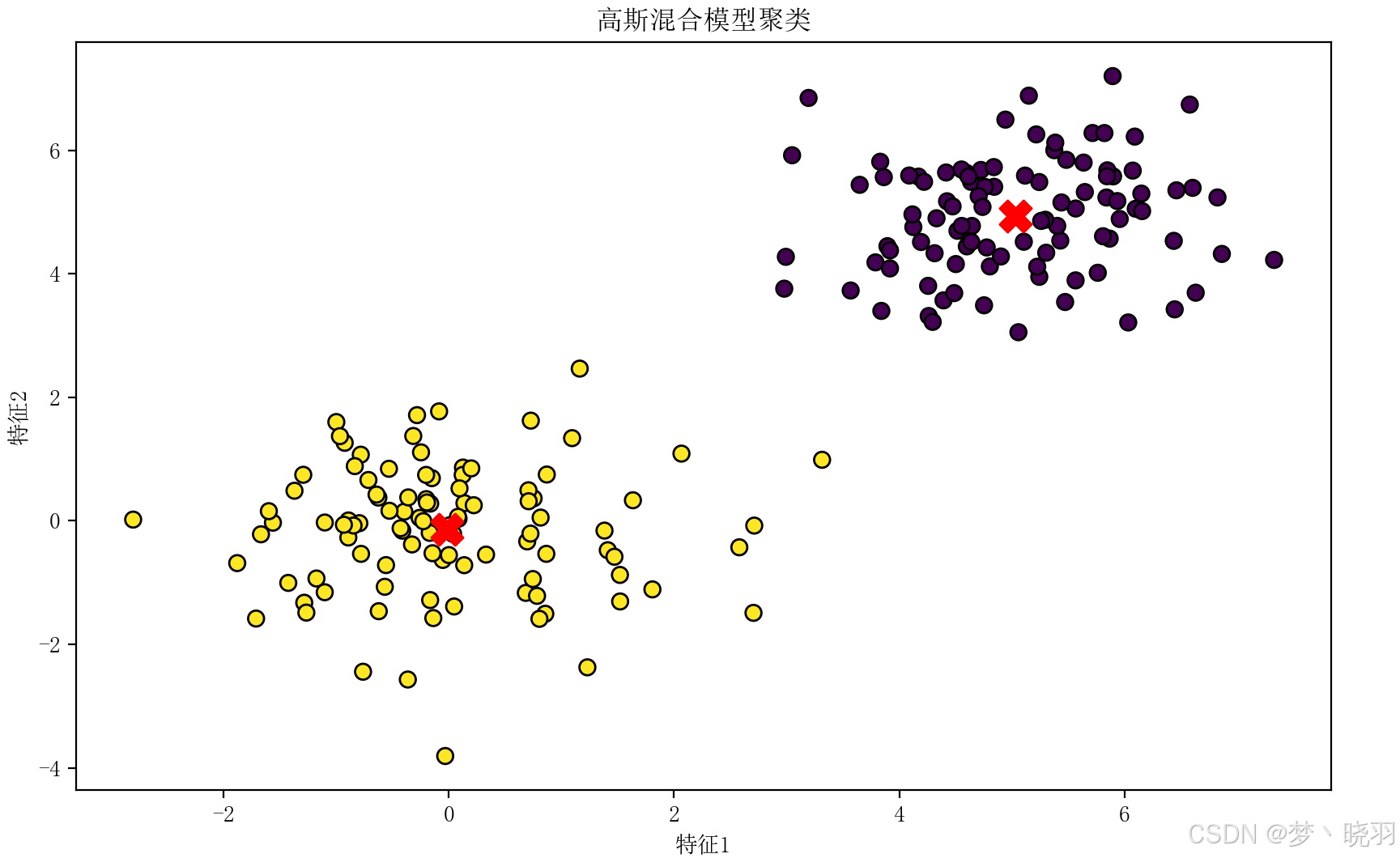
代码使用Python中的sklearn库实现高斯混合模型,并对生成的模拟数据进行聚类分析。通过这个代码,我们可以直观地看到高斯混合模型是如何对数据进行建模和聚类的,同时也能了解如何使用 sklearn库中的GaussianMixture类来完成这一任务。
通过运行这个代码,我们可以看到高斯混合模型是如何对数据进行聚类的,并且可以直观地看到每个高斯分布的中心位置。在实际项目中,高斯混合模型可用于数据聚类、异常检测、密度估计等任务。通过这个代码示例,我们可以将其作为一个基础模板,应用到更复杂的实际问题中。
模型优点
- 强大的建模能力:高斯混合模型能够灵活地拟合各种复杂的数据分布。由于它是多个高斯分布的组合,对于具有多模态分布的数据(如包含多种主题的文本数据),可以很好地捕捉不同模式之间的差异,相比单一的高斯分布模型,具有更强的表达能力。
- 无监督学习优势:作为一种无监督学习模型,高斯混合模型不需要预先标记的数据,能够自动从数据中发现潜在的结构和模式。在自然语言处理中,这一特性非常适合用于文本聚类任务,帮助我们在没有人工标注的情况下,将文本按照主题等特征进行分类,节省了大量的人力成本。
- 理论基础完善:高斯混合模型基于概率论和数理统计的理论,具有坚实的数学基础。其训练过程使用的期望最大化算法有严格的数学推导和收敛性证明,使得模型的训练和优化过程更加可靠和可解释。
模型缺点
- 对超参数敏感:高斯混合模型的性能很大程度上依赖于超参数的选择,如高斯分布的数量 K、协方差类型等。在实际应用中,选择合适的超参数并不容易,不同的超参数设置可能会导致截然不同的聚类结果。如果 K 设置不当,可能会出现聚类不足或过度聚类的问题。
- 计算复杂度较高:在训练过程中,尤其是当数据量较大或者高斯分布数量较多时,期望最大化算法的计算量会显著增加。每次迭代都需要计算每个数据点属于每个高斯分布的后验概率,以及更新模型的参数,这对于大规模文本数据处理来说,计算成本较高,可能会影响算法的效率。
- 模型可解释性受限:虽然高斯混合模型有一定的数学理论基础,但当高斯分布数量较多时,模型的结构会变得复杂,难以直观地解释每个高斯分布所代表的实际意义。在文本聚类中,可能难以清晰地阐述每个聚类所对应的主题,不利于对结果的深入理解和分析。
结论赋能
高斯混合模型作为自然语言处理中的一种重要模型,凭借其强大的建模能力和无监督学习的优势,在文本聚类等任务中发挥着重要作用。它能够自动挖掘文本数据中的潜在结构,为文本分析提供有价值的信息。
然而,其对超参数的敏感性、较高的计算复杂度以及可解释性受限等问题,也限制了它在某些场景下的应用。在实际使用中,需要根据具体的文本数据特点和任务需求,谨慎选择高斯混合模型,并结合其他技术(如特征选择、模型融合等)来弥补其不足,以实现更高效、更准确的自然语言处理任务。
结束
好了,以上就是本次分享的全部内容了,希望大家通过这次分享,对高斯混合模型在自然语言处理中的应用有了更多的理解。
我们知道了高斯分布在生活中随处可见,而高斯混合模型巧妙地将多个高斯分布组合起来,为我们处理复杂的文本数据提供了有力工具。通过期望最大化算法训练模型,不断调整参数,让模型能够更好地拟合数据,实现文本的聚类等任务。
所以在今后的学习和实践中,如果遇到自然语言处理的相关任务,比如文本聚类、情感分析等,大家可以考虑使用高斯混合模型,但要根据实际情况合理选择超参数,并结合其他技术来提升模型性能。如果在应用过程中遇到超参数选择的难题,可以尝试不同的取值进行实验,观察模型的表现;面对计算复杂度高的问题,可以优化数据处理流程,或者采用分布式计算的方式。而对于模型可解释性差的情况,可借助可视化工具或者结合领域知识来辅助理解。
那么本次分享就到这里了。最后,博主还是那句话:请大家多去大胆的尝试和使用,成功总是在不断的失败中试验出来的,敢于尝试就已经成功了一半。如果大家对博主分享的内容感兴趣或有帮助,请点赞和关注。大家的点赞和关注是博主持续分享的动力🤭,博主也希望让更多的人学习到新的知识。