【机器学习chp14 — 4】生成式模型—扩散模型 Diffiusion model(超详细分析,易于理解,推导严谨,一文就够了)
目录
四、扩散模型(DDPM)
1、扩散模型基本原理
(1)扩散模型:渐变生成
(2)为什么从噪声生成图像可行?
(3)核心模块:噪声预测器
(4)训练噪声预测器
4.1 训练思想
4.2 构造噪声预测器的训练样本
2、DDPM 算法
(1)DDPM的训练算法
1.1 前向扩散过程
1.2 噪声预测器与损失函数
1.3 多次添加噪声等价于一次添加噪声详细解析
(2)DDPM的生成算法
2.1 反向生成过程(Reverse Process)
2.2 生成过程的关键步骤
2.3 后向去噪与前向加噪的统一
3、从VAE角度看扩散模型
(1)基本思路
(2)数学推导与ELBO分解
2.1 分解对数似然下界
2.2 下界的具体分解
(3)参数化与噪声预测
3.1 引入噪声预测器
3.2 后向分布的参数化
(4)对比VAE与扩散模型
(5)总结
4、扩散模型的其他解读
5、其他解读—基于能量的模型和分数匹配(很重要,但有些还不太懂)
(1)能量模型视角
1.1 能量函数与概率分布
1.2 分数函数与梯度
(2)分数匹配(Score Matching)原理
2.1 传统分数匹配
2.2 去噪分数匹配
(3)扩散模型中的能量模型与分数匹配
3.1 前向扩散过程与噪声添加
3.2 逆过程与分数预测
3.3 目标函数的重新解释
(4)总结与思考
6、GAN 和 Diffusion 比较
7、扩散模型在音频和自然语言领域的应用
8、条件-扩散模型
9、Stable Diffusion
10、Diffusion Model推荐阅读材料
附录
1、后向去噪与前向加噪系数匹配的严格推导
(1)前向加噪过程的定义与推导
1.1 单步加噪过程
1.2 多步递推与闭式表达
(2)后向去噪过程的推导
2.1 目标与贝叶斯公式
2.2 具体推导结果
(3)利用噪声预测器实现逆向生成
3.1 解决 编辑 的未知问题
3.2 参数化的后向均值
(4)总结
四、扩散模型(DDPM)
全称为:Denoising Diffusion Probabilistic Models
1、扩散模型基本原理
(1)扩散模型:渐变生成
生成思想:图像的生成过程是一个由高噪声状态逐步“雕刻”出干净图像的过程,强调“渐进式”与“逐步去噪”的思路。如下图所示:

(2)为什么从噪声生成图像可行?
- 理论依据:扩散模型通过精心设计的正向加噪过程,建立了噪声与图像之间的映射关系。在反向过程中,只要能够准确预测并去除这些噪声,原始图像的信息就能够被恢复出来。
- 关键步骤:生成的核心不在于直接从零开始构造图像,而在于如何精确地“去除”噪声,从而显露出图像内在的结构与细节。整个过程类似于从一块大石头开始的雕塑,一步一步去除无用的东西。
- 生成图像的关键是去噪。
(3)核心模块:噪声预测器
去噪模块Denoise中最关键的就是噪声预测器。去噪模块构造如下图所示:

噪声预测器:在去噪过程中,负责预测当前噪声分布。
- 核心功能:噪声预测器通过学习如何从噪声图像中估计出被加入的噪声量,从而在反向过程中通过“移除”这些噪声逐步恢复图像。
- 模型设计:通常采用神经网络(如UNet)作为噪声预测器,通过大量样本训练,使其能够在不同噪声水平下准确估计噪声信息。
- 生成效果:预测器的准确性直接决定了去噪效果和最终生成图像的质量,因此其设计与训练成为扩散模型的关键难点之一。
(4)训练噪声预测器
4.1 训练思想

如图,噪声预测器的输入为红色圈出的,输出为蓝色圈出的。我们只需通过很多 “ 输入-输出 ” 对即可完成对噪声预测器的训练,这个噪声预测器是否是 “ 好的 ” 的前提是输出图像减去它输出的结果会使得输入图像变清晰。
训练噪声预测器的训练样本:可人为构造。
目标函数可以是:噪声的重构误差(L2损失)
4.2 构造噪声预测器的训练样本
噪声预测器的训练样本即为:很多 “ 输入-输出 ” 对,通过前向加噪产生。如下图所示:
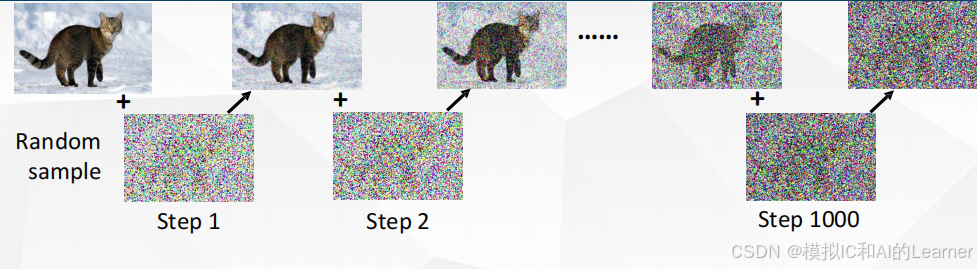
而噪声预测器的 “ 输入-输出 ” 对样本为:

2、DDPM 算法
(1)DDPM的训练算法
DDPM 的训练过程主要由两大模块构成:前向扩散过程(目的:获得噪声预测器的训练样本) 和 噪声预测器的训练,终极目标就是训练得到一个好的噪声预测器。
-
训练步骤总结:
- 从数据集中采样干净图像
。
- 随机采样时间步
(通常均匀分布于1至T)。
- 采样噪声
,生成带噪声图像
。
- 将
- 计算 L2 损失,反向传播更新网络参数。
- 从数据集中采样干净图像
1.1 前向扩散过程
-
目标与过程:
从一个干净图像- 每一步都会向图像中加入一小部分高斯噪声。
- 经过多次噪声叠加后,最终得到的
-
数学表达式:
文档给出了类似如下的公式(格式略有简化):其中:
- 这个式子表明,添加 t 次噪声后的图像可一次计算出来。
为累计保持原始信息的比例(与噪声调度有关),下面 1.3 有关于
1.2 噪声预测器与损失函数
-
噪声预测器:
训练目标是利用一个参数化的神经网络(通常基于 U-Net 架构)来预测在某一噪声水平下加入的噪声,记作。
- 网络接收带噪声的图像
- 网络接收带噪声的图像
-
训练目标与损失函数:
采用 L2 损失函数,比较预测噪声与实际添加的噪声:- 这种损失函数通过重参数化技巧简化了问题,使模型直接学会如何从噪声图像中恢复出原始图像的信息。
- 文档中通过多次加噪声与一次加噪声之间的数学推导,验证了前向过程的合理性和生成过程中噪声合成的正态性。
通过这种训练,模型逐步学会了如何在不同噪声水平下精确估计噪声,为后续的反向生成过程提供了可靠基础。
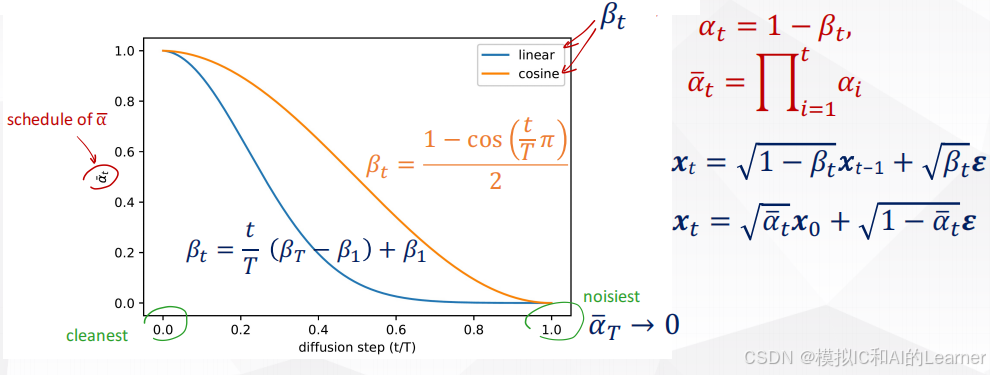
1.3 多次添加噪声等价于一次添加噪声详细解析
如下图,由于高斯分布的性质,多次加噪声可以通过一次加噪声实现。

推导过程:


由高斯分布的性质:两个正态分布的和仍然是正态分布,即
得总的噪声得方差系数为
即
扩展一下
令 ,
,则上式可写为
其中,
取值由噪声调度决定:
噪声调度(Noise Schedule):
噪声系数的设置,指出当
- 这一调度确保前向过程中的每一步均保持数学上的可逆性,为后续的生成提供理论基础。
两张图片非常接近时,用欧几里得距离才有意义。
- 当
与
;
- 当
(2)DDPM的生成算法
DDPM 的生成过程即为反向扩散过程,它通过逐步去噪将纯噪声还原为真实图像。过程框图如下:
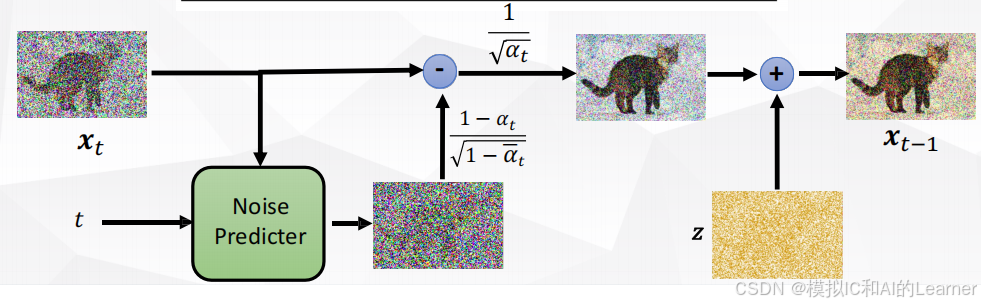
2.1 反向生成过程(Reverse Process)
-
初始状态:
生成过程从一个纯高斯噪声图像开始。
-
逆转噪声添加:
利用训练好的噪声预测器,逐步逆转前向过程中的噪声添加,每一步将- 反向过程可以表示为:
然后,从均值为
且方差
的高斯分布中采样得到
- 参数
与前向扩散的系数有关,下面 2.3 有详细的分析。
- 这里,
- 反向过程可以表示为:
2.2 生成过程的关键步骤
-
迭代去噪:
生成过程以迭代方式进行,从开始,依次递减时间步:
- 对于当前时间步
得到噪声估计。
- 根据预测噪声及当前噪声调度参数计算均值
- 从
中采样,得到
- 重复上述过程直至
,此时
- 对于当前时间步
-
数学一致性与概率匹配:
反向生成过程与前向噪声添加过程在概率分布上严格对应,保证了整个生成链条的数学一致性。- 下面 2.3 通过对“后向去噪过程”与“前向加噪声过程”的详细推导,证明了利用噪声预测器预测的噪声与前向过程中噪声的分布匹配,从而确保反向采样过程能够有效恢复出原始图像。
-
生成效果与计算代价:
虽然反向过程通常需要数百步迭代才能完成,但这种逐步去噪的策略能够保证生成图像的细节与稳定性。- 每一步通过精细控制噪声去除,逐步提取出图像中的结构信息,使得生成结果远超直接映射的方法。
2.3 后向去噪与前向加噪的统一
实现“后向去噪过程”与“前向加噪声过程”的匹配是通过严格使前向加噪 的系数和后向去噪
的系数在数学上严格统一来建立的。《 通过前向的系数来推导后向的系数的详细推导过程见附录1 》
3、从VAE角度看扩散模型
(1)基本思路
VAE基本框架:
在传统的VAE中,我们引入隐变量 来解释数据
,目标是最大化数据的对数似然
由于直接计算困难,引入变分分布 并利用ELBO(变分下界):
扩散模型的视角:
扩散模型(如DDPM)可以看作是一个逐步构建的VAE,其中数据生成过程被分解为多个小步骤。
这里, 充当了VAE中多个隐变量的角色,而前向过程的条件分布
就类似于编码器,后向过程的条件分布
则类似于解码器。
- 编码器(前向过程):
利用一系列小步的高斯噪声添加,将干净图像。
- 解码器(后向过程):
则从噪声 开始,逐步去除噪声,恢复出
(2)数学推导与ELBO分解
2.1 分解对数似然下界
对于数据 ,我们希望计算其对数似然
。利用一系列中间状态
,可写为:
由于积分难以直接计算,采用变分方法,构造下界(VLB):
在扩散模型中,前向过程 是已知的,其每一步都采用简单的高斯分布:
并且通过递归,可以得到
其中 。
2.2 下界的具体分解
利用变分推导,可以将下界分解为多个时间步的KL散度项和一个初始项。形式上(略去部分细节),下界可以写为:
其中各项的意义为:
- 重构项
:
对应于解码器从第一步噪声恢复出原始图像的能力,相当于VAE中的重构误差。 - 中间步骤的KL项:
每一步都衡量模型在后向过程与真实后验
之间的差距。
- 最后一步的KL项:
保证最末状态(通常取为标准正态分布)匹配。
由于前向过程的每一步都是简单的高斯分布,上述KL项均可以解析计算。这种分解使得整体目标变成对多个简单KL项和一个重构项的求和,与VAE的ELBO形式非常相似。
(3)参数化与噪声预测
3.1 引入噪声预测器
在生成(后向)过程中,直接利用 的形式是不可能的,因为
在生成时是未知的。解决方法是引入参数化模型
来预测噪声,并将
用
和预测噪声表示:
3.2 后向分布的参数化
将上述表达式代入到后向分布 的均值中,可以得到参数化的后向均值:
并令后向分布为:
这样的设计使得整个模型在训练时通过最小化各步KL散度项来学习如何从噪声中恢复出原始图像,与VAE中的重构和先验匹配损失相似。
(4)对比VAE与扩散模型
-
局部近似与全局建模:
VAE在全局上对数据分布做建模,因采用单一步骤的高斯假设,可能难以捕捉数据的复杂结构;
而扩散模型将生成过程分解为多个小步骤,每一步只需建模微小变化,正如“在小范围内曲线可以近似为直线”,这种局部线性近似更易于准确拟合复杂分布。 -
多步建模的优势:
每一步都只需预测小幅噪声,因此网络可以更精细地调整生成过程;
同时,多步KL散度的累积实际上构成了对整体对数似然的下界优化,类似于VAE的ELBO,但由于步骤划分更细,模型的表达能力更强。
(5)总结
-
VAE视角下的扩散模型:
- 将数据生成过程分解为多个隐变量
的状态转移,前向过程作为编码器,后向过程作为解码器。
- 与VAE类似,通过构造变分下界(ELBO)对整体对数似然进行优化。
- 将数据生成过程分解为多个隐变量
-
数学分解与目标函数:
- 下界由重构项和多步KL散度项组成,每一步的KL项均可解析计算。
- 参数化的后向分布通过噪声预测器实现,使得生成过程仅依赖于当前状态
-
优势与改进:
- 由于每步变化较小,简单的高斯假设足以准确描述局部变化,从而使得扩散模型在捕捉复杂数据分布上较传统VAE更具优势。
这种用VAE思想解释扩散模型的方法,不仅揭示了两者在目标函数上的共性,还展示了扩散模型如何通过多步细粒度建模来克服传统VAE在全局建模上的不足,为生成高质量图像提供了理论基础和实践依据。
4、扩散模型的其他解读
除了从VAE的角度解释扩散模型外,还能从其他角度解释扩散模型:
- 基于能量的模型和分数匹配
- 自回归模型
- SDE和ODE
- 标准化流程
- 循环神经网络
5、其他解读—基于能量的模型和分数匹配(很重要,但有些还不太懂)
(1)能量模型视角
1.1 能量函数与概率分布
在能量模型(Energy-Based Model, EBM)中,我们通常将数据分布写为
其中 是能量函数。由此可知,数据的对数概率可以写为
这里 是归一化常数(配分函数)。
这种表示方式的一个优势在于,我们只需要关心能量函数的梯度(也就是分数函数),而不必直接计算难以获得的归一化常数。
1.2 分数函数与梯度
分数函数定义为数据分布对数密度的梯度
由此可以看出,学习分数函数就等价于学习能量函数的负梯度。在扩散模型中,正是利用这一思想,通过对数据进行逐步噪声添加并构造对应的“扰动分布”,再用神经网络拟合这些扰动下的分数信息,从而达到建模复杂数据分布的目的。
(2)分数匹配(Score Matching)原理
2.1 传统分数匹配
原始的分数匹配方法由 Hyvärinen 提出,其目标是使模型预测的分数函数 与真实分数
尽可能接近。其损失函数形式为:
然而,由于真实数据分布 的分数函数难以直接计算,这一目标难以直接优化。
2.2 去噪分数匹配
为了解决上述问题,Vincent 等人提出了去噪分数匹配(Denoising Score Matching, DSM)的策略。主要思想是在数据上添加一定幅度的高斯噪声,使得我们获得一个平滑的扰动分布
此时其分数函数可写为
,(近似关系)
实际训练时,我们采样原始数据 并添加噪声得到
那么 DSM 的目标就是使网络预测的分数 与
接近,即最小化
其中 是针对不同噪声水平的权重因子。
(3)扩散模型中的能量模型与分数匹配
3.1 前向扩散过程与噪声添加
扩散模型中,我们定义一个前向过程,将干净数据 逐步添加噪声,得到一系列变量
。其中,每一步通常定义为:
经过多步迭代,可以证明 与
的关系为
其中
3.2 逆过程与分数预测
在生成阶段,由于我们无法直接获得 ,需要从
开始逐步还原到
。逆过程可以写为
关键在于利用分数函数将 表达为
和噪声的函数。通过对
取对数求梯度,可以得到真实的分数:
这意味着,若能预测出这个梯度(或其负值),就能获得关于 的信息。通常,我们引入一个参数化模型
逼近该分数,从而有:
这样一来,利用分数匹配的目标函数,就能训练网络以精确预测不同噪声水平下的分数信息,从而在逆过程(生成过程中)指导数据的恢复。
3.3 目标函数的重新解释
实际上,可以证明扩散模型训练中针对每一步KL散度的优化,与加权的去噪分数匹配损失在数学上是等价的。具体地,每一项KL散度衡量的正是网络预测的分数与真实分数(由高斯扰动模型计算得到)之间的差异。通过对所有时间步求和,整个变分下界(ELBO)的优化目标就转化为一个多尺度、加权的分数匹配损失。
这种推导展示了两点核心思想:
- 局部近似:在每一个小噪声添加的步骤中,由于噪声幅度较小,数据分布在局部可以近似为高斯分布,从而使得分数函数可以精确计算。
- 多尺度分数匹配:通过在不同噪声水平下匹配分数,模型可以逐步“理解”数据的局部结构,并在生成阶段利用这一信息进行高质量采样。
(4)总结与思考
基于能量模型和分数匹配的角度,扩散模型的核心思想可以概括为:
- 能量模型:将数据分布表示为
,重点在于学习能量函数(或其梯度,即分数函数),从而避免直接计算难以获得的归一化常数。
- 分数匹配:通过在不同噪声水平下使网络预测的分数函数接近真实(由高斯扰动计算的)分数,达到对数据分布的精确建模。去噪分数匹配的目标不仅易于计算,而且与扩散过程中的各步目标严格对应。
- 推导过程:从前向过程的噪声添加得到
的表达式,再计算其对数梯度,从而为逆过程提供理论依据。逆过程参数化中,利用分数预测重构
这种解释不仅为扩散模型提供了一个直观的能量视角,也使得它与经典的分数匹配方法建立了联系,从而解释了为什么通过逐步去噪可以有效捕捉数据分布的复杂结构,以及为何该方法在生成高质量样本时表现出色。
6、GAN 和 Diffusion 比较
生成对抗网络(GAN) 和 扩散模型(Diffusion) 在生成方式、训练目标以及控制能力等方面有所不同:
-
GAN(生成对抗网络):
- 生成速度:GANs 通常一次性生成样本,因此生成速度较快。
- 控制难度:由于生成器和判别器在对抗训练中博弈,控制生成内容变得较为复杂。
- 训练目标:GAN 使用对抗性训练,生成器通过最小化损失函数来骗过判别器。由于训练的不稳定性,可能会发生模式崩塌(mode collapse),即生成的样本质量多样性较差。
- 总结:GAN 在生成过程中速度较快,但在控制和稳定性方面存在挑战。
-
扩散模型(Diffusion Models):
- 生成过程:扩散模型采用多步迭代的方式,逐步从噪声中恢复数据,因此生成速度较慢。
- 控制性:由于生成过程逐步进行,扩散模型的生成过程相对容易控制,且通常能够生成质量更高的样本。
- 训练目标:扩散模型使用一个简单的去噪目标,无需复杂的对抗训练。因此,扩散模型的训练相对稳定,通常不会发生模式崩塌。
- 总结:扩散模型虽然速度较慢,但生成过程的控制性较强,且训练更加稳定。
7、扩散模型在音频和自然语言领域的应用
扩散模型已被成功应用于多个领域,包括音频和自然语言生成:
- 扩散模型在音频生成中的应用:
- WaveGrad 是一种扩散模型,特别应用于音频生成。该模型通过反向扩散去噪过程逐步恢复音频信号的质量。
- 参考文献:WaveGrad,该模型能够生成更自然、更连贯的语音或音频内容。

- 扩散模型在文本生成中的应用:
- 挑战:由于文本是离散的,直接使用扩散模型进行文本生成存在困难。文本生成要求将离散的文字转换为潜在空间中的连续表示。
- 解决方案:通过在潜在空间上加入噪声,扩散模型可以有效地在文本的潜在表示空间中进行去噪和生成。研究如 DiffuSeq 和 DiffusER 提供了这种方法的优化与应用。
扩散模型在这些领域的应用表明它能生成高质量的音频和文本,但在文本生成时需要创新的处理方式来应对离散与连续数据的差异。
8、条件-扩散模型
条件扩散模型(Conditional Diffusion Models)是一类根据给定条件生成数据的扩散模型。与标准扩散模型不同,条件扩散模型能够在生成过程中引入外部信息(如标签、描述等)来引导生成过程。外部信息加入的位置是在训练噪声预测器时作为输入,如下图所示,常见的应用包括:
- 文本到图像生成:通过文本描述(如“一个骑马的宇航员”),条件扩散模型能够生成与描述相匹配的图像。
- 图像翻译:条件扩散模型可以根据输入图像的特征,生成与其风格或内容相符的输出图像。
这种类型的模型在现实世界应用中展现了强大的潜力,能够在多种场景下生成与特定条件匹配的高质量数据。

9、Stable Diffusion
Stable Diffusion 是一种广泛应用的扩散生成模型,特别在文本到图像生成方面具有显著优势。其特点和关键技术包括:
- 多步去噪过程:Stable Diffusion 通过多次迭代去噪生成图像,从而能够生成更高质量的图像。
- 文本到图像的桥梁:它能够将自然语言描述(如“一个在雪地里的猫”)转换为对应的图像。
- U-Net架构:作为一种重要的图像生成结构,U-Net 在扩散过程中有着重要作用。它的编码-解码结构帮助模型从噪声中恢复清晰的图像。
- 自动编码器:Stable Diffusion 采用了自动编码器技术,有助于压缩图像数据并减少生成时的计算开销。
- 注意力机制:通过注意力机制,模型能够更加聚焦在图像的关键部分,从而提高生成图像的质量。
Stable Diffusion 在质量、控制性和多样性方面都表现出色,并在生成领域引领了新的趋势。
10、Diffusion Model推荐阅读材料
为了深入了解扩散模型的工作原理和应用,以下是一些推荐的阅读材料:
- Perspectives on Diffusion Models:由 Sander Dieleman 提供的扩散模型深入分析,适合对模型原理有更深兴趣的读者。
- 生成扩散模型漫谈系列:这是一系列由苏剑林编写的中文资料,详细探讨了生成扩散模型的各个方面,适合中文读者。
这些资料能够帮助读者进一步理解扩散模型的理论背景及实际应用,增强对该领域的知识储备。
附录
1、后向去噪与前向加噪系数匹配的严格推导
(1)前向加噪过程的定义与推导
1.1 单步加噪过程
- 定义
前向过程从干净图像其中:
表示每一步保留原图信息的比例,
1.2 多步递推与闭式表达
递归关系
由于每一步的转换都是高斯分布,通过递归迭代,可以将 与
直接建立关系。利用高斯分布线性组合的性质,有:
其中:
表示经过 步后,原始图像信息的累计保持率。
核心思想
这一推导利用了“两个正态分布之和仍为正态分布”的性质,使得前向过程从 到
的转换具有闭式表达,为后续逆过程的推导奠定基础。
(2)后向去噪过程的推导
2.1 目标与贝叶斯公式
目标
生成过程中,我们希望逆转前向过程,将纯噪声恢复成原始图像。具体来说,需要推导出:
表示在已知当前状态 以及原始图像
(训练时可利用,但生成时未知)的条件下,前一步
的分布。
利用贝叶斯定理
根据贝叶斯公式,有:
由于上面三个条件分布都是高斯分布,故该条件分布依然为高斯分布,其均值和方差可以通过标准的条件高斯分布公式求得。
2.2 具体推导结果
均值与方差
经过详细推导,可以得到:
其中均值 和方差
分别为:
这一推导依赖于已知前向过程 的闭式表达,以及高斯条件分布的性质。
(3)利用噪声预测器实现逆向生成
3.1 解决 的未知问题
问题
在生成过程中,(原始图像)是未知的,因此直接使用上式中的
计算均值不可行。
解决方案
引入参数化的噪声预测器 ,利用前向过程的重参数化公式:
从中可以解出:
3.2 参数化的后向均值
替换与重构
将 的表达式代入先前
中,经过重构和化简,可以得到参数化的后向均值:
这一形式使得在生成过程中,只需利用当前的带噪图像 和噪声预测器的输出,就可以计算出前一步
的采样均值。
生成步骤
生成过程中从 开始,逐步利用上述公式采样出
,直至获得
(即生成的图像)。同时,后向过程的方差
也可依据前向过程参数确定,从而确保采样的合理性。
(4)总结
整个推导过程可以总结为以下几点:
-
前向过程:
- 定义了一个逐步添加噪声的过程,使得
, 其中利用了多步高斯噪声叠加后的闭式表达。
- 定义了一个逐步添加噪声的过程,使得
-
后向过程:
- 利用贝叶斯定理,推导出在给定
- 利用贝叶斯定理,推导出在给定
-
噪声预测器的引入:
- 为了解决生成过程中
- 为了解决生成过程中
这种推导保证了前向加噪与后向去噪过程在数学上的严格对应,同时使得模型在训练过程中能够有效学习到如何从噪声中恢复出原始图像,从而在生成时实现高质量图像的采样。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.kler.cn/a/598981.html 如若内容造成侵权/违法违规/事实不符,请联系邮箱:809451989@qq.com进行投诉反馈,一经查实,立即删除!