DeepSeek 的组网方案介绍
DeepSeek 的组网方案会因不同的应用场景和硬件配置而有所不同,以下是一些常见的 DeepSeek 组网方案介绍:
-
分离网络架构:分为 Prefill 网络和 Decode 网络,分别负责本集群内流量,两个集群之间的流量通过互联网络实现。其优点是两个网络可分别运维管理,但缺点是 Prefill 和 Decode GPU 之间的流量至少需要 3 跳。
-
统一网络架构:单个网络同时负责集群内和集群间流量,借助 QoS、自适应路由技术对 Prefill 和 Decode 流量分别处理。网络统一运维管理,Prefill 和 Decode GPU 之间流量可一跳直达。在 GPU 服务器内部,每四个 GPU 作为一组,共享一个并行推理网卡,连接到同一个 PCI Switch,两组 GPU 之间的通信通过两个 PCI Switch 之间的直连通道完成;GPU 服务器之间,同一组号的 GPU 之间的通信通过交换机直接完成,不同组号的 GPU 之间的通信,先通过 PCI Switch 将流量路由到另一组的网卡,然后通过交换机完成。例如,16 个推理服务器(128 张 GPU)和 2 个 CX7 32Q - N 可组成一个 PoD,采用星融元提供的 CX - N 系列 AI 智算网络产品,包括基于 SONiC 的开放 NOS(AsterNOS)和 100G/200G/400G/800G 超低时延以太网交换机硬件,全端口支持 RoCEv2 和 EasyRoCE Toolkit。
-
单机部署方案:适用于本地低并发需求场景,如个人用户或小型团队进行简单的模型测试、开发和轻度使用。只需一台具备足够性能的服务器,安装好 DeepSeek 模型、相关框架及依赖软件即可。服务器需有大容量内存和较强的 CPU、GPU 计算能力,如配备 NVIDIA RTX 3090 及以上显卡、8GB 以上内存、20GB 可用磁盘空间,以支持模型的加载和运行。通过 Ollama 等工具可直接下载模型并在本地运行,若专网无法访问公网,可提前通过离线存储介质导入模型文件。
-
推理集群组网方案:对于需要高并发处理的大集群平台部署,常采用推理集群组网方案。当使用 Prefill - Decode 分离架构时,分为 Prefill 网络和 Decode 网络,或采用统一网络架构。
-
多机分布式部署方案:在一些企业级应用中,若单台服务器的计算资源仍无法满足需求,可采用多台服务器组成分布式集群。如配置 2 台 8 卡 H20 GPU 服务器,用于 DeepSeek 的推理服务,并通过 InfiniBand(IB)组网来确保网络性能达到最佳水平。根据 H20 机器配备的 CX7 400G 单口网卡,需组建 400G 的 IB 网,因此需要型号为 MQM9700 - NS2R 的 NDR 交换机,以及 800G 的光模块、400G 的光模块和 400G 的 mpo 光纤。管理网络包括带内和带外,由于 H20 配置的是 10G×2 的网卡和一个千兆的 BMC 管理口,管理网交换机需要上联到数据中心的核心交换机上或者 VPM 防火墙上。
案例分享
以部署DeepSeek 671B模型为集群推理,采用BF16数据格式进行推理,模型需要的HBM内存约为1340GB,推理最低配置4台Atlas 800I A2(8*64GB)或Atlas 800T A2(313T),需部署参数面网络(200G)。4台Atlas 800I A2集群共32个200G口,交换机出16个400G 1分2连到服务器。
推荐XH9210(32*400G),可扩至8机。
DeepSeek 4机组网案例参考:
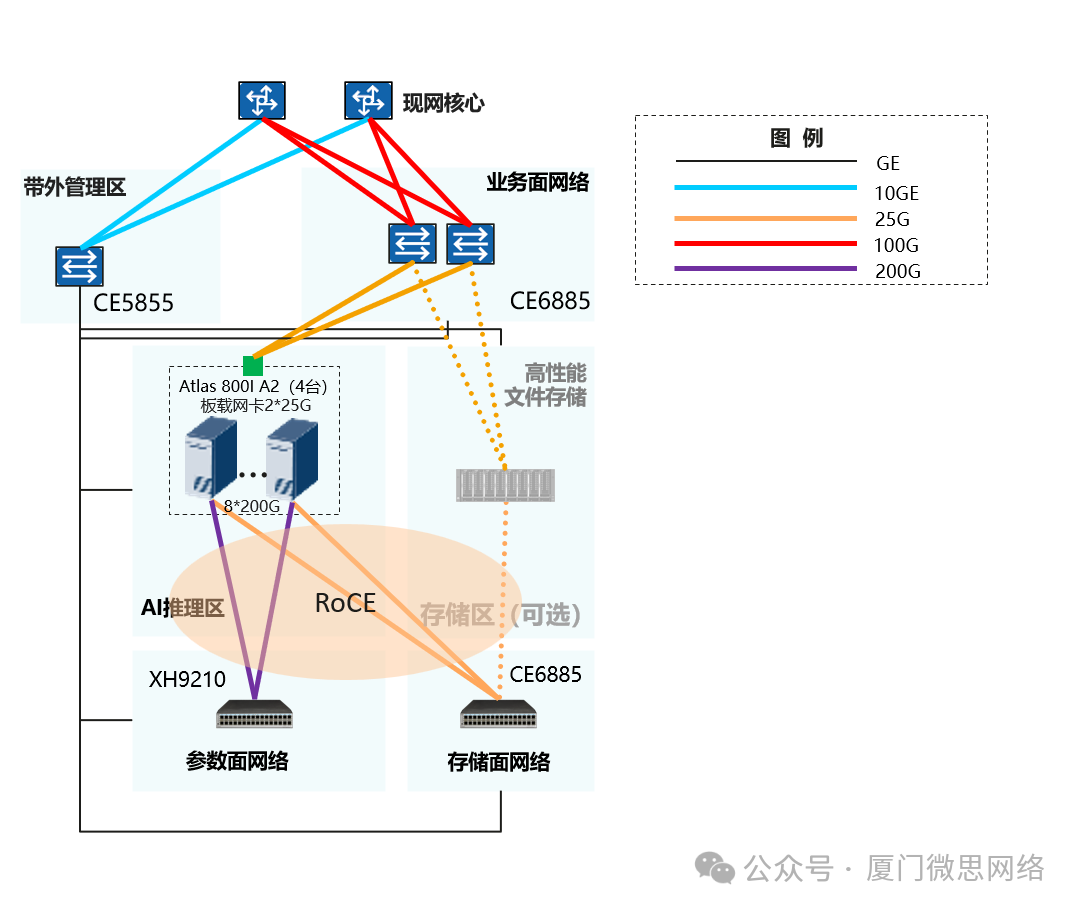
组网说明:
1. 业务面网络(CE6885,至少1台/推荐2台以增强健壮性)
用途:
-
推理平台与昇腾AI推理区之间的互访,例如任务调度、镜像拉取;
-
模型推理请求和响应通过业务面网络与外界交互 ;
-
推理平台或者互联网访问高性能文件存储(推理服务器和高性能文件存储都需要接入业务面网络)。
2. 推理参数面网络(XH9210,1台带4服务器,可扩至8机)
多机推理区的多机并行推理,采用ROCE网络互联
3. 推理存储面网络(CE6885)
4机方案原则上服务器自带SAS盘即可,存储面网络用于内置存储空间共享,后续扩容可选配独立存储(需部署ROCE)
4. 带外管理网络(CE5855-48T4XS)
计算、存储、网络设备通过带外网络与管理区的网管或运维设备对接。
5. 8机以上集群参数面需改为两层盒盒组网。更大集群规模参数面组网参考下图
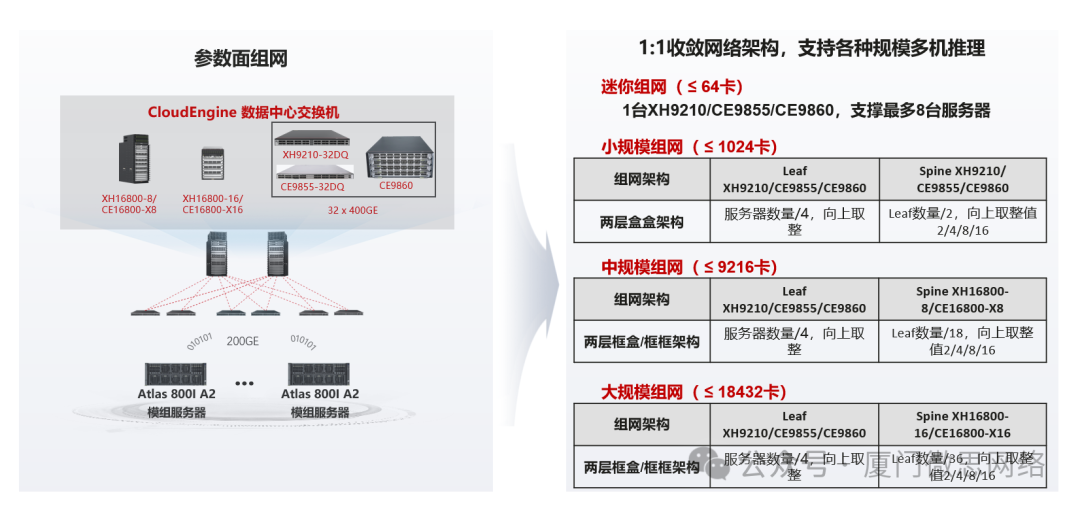
备注:参数面采用Spine-Leaf网络架构,遵从以下部署原则
-
根据业务需求确认服务器和推理卡数量,根据推理卡数量选择组网规模
-
单服务器的8网口接入到1台leaf交换机,1台leaf交换机可以接入4台服务器
-
平滑扩容要求初始部署最终规划规模的全部Spine设备,否则扩容Spine设备时需要修改leaf上行连线,会中断推理任务,Leaf可以按需部署,以1台的粒度扩容
-
参数面采用两层CLOS组网,Spine-Leaf间无收敛,即Leaf交换机上/下行收敛比为1:1
-
同一台Leaf交换机,需要保证与每台Spine交换机的Link数相同,即参数面Spine交换机数量能被Leaf交换机上行端口数量整除
-
Leaf上行口按照从左到右从上到下从小到大的端口顺序配置IP地址
配置说明(仅供参考)
1. Vlan配置
vlan batch 100
2. 无损参数配置
使能PFC功能基于DSCP映射后的优先级进行反压
dcb pfc dscp-mapping enable slot 1
手工配置芯片级Headroom缓存空间大小
qos buffer headroom-pool size 6 mbytes slot 1
全局使能PFC,使能无损队列为4队列,缺省情况下,优先级队列3已使能PFC功能,取消优先级队列3的PFC功能
dcb pfc
priority 4
undo priority 3
priority 4 turn-off threshold 90
3. 服务器接入配置
端口加入VLAN
interface 400GE 1/0/31:1
port default vlan 100
端口下使能PFC
dcb pfc enable mode manual
配置无损队列的缓存空间大小
dcb pfc buffer 4 guaranteed 5 kbytes
dcb pfc buffer 4 hdrm 1024 kbytes
dcb pfc buffer 4 xoff dynamic 4 xon offset 6 kbytes
qos buffer queue 4 shared-threshold static 33280 kbytes
配置接口队列0和4的调度模式为DRR模式及权值
qos drr 0 4
qos queue 0 drr weight 10
qos queue 4 drr weight 90
服务器信任DSCP时,配置信任报文的DSCP映射内部优先级
trust dscp