代码随想录算法训练营第五十八天 | 拓扑排序精讲 dijkstra(朴素版)精讲
拓扑排序精讲
卡码网:117. 软件构建(opens new window)
题目描述:
某个大型软件项目的构建系统拥有 N 个文件,文件编号从 0 到 N - 1,在这些文件中,某些文件依赖于其他文件的内容,这意味着如果文件 A 依赖于文件 B,则必须在处理文件 A 之前处理文件 B (0 <= A, B <= N - 1)。请编写一个算法,用于确定文件处理的顺序。
输入描述:
第一行输入两个正整数 N, M。表示 N 个文件之间拥有 M 条依赖关系。
后续 M 行,每行两个正整数 S 和 T,表示 T 文件依赖于 S 文件。
输出描述:
输出共一行,如果能处理成功,则输出文件顺序,用空格隔开。
如果不能成功处理(相互依赖),则输出 -1。
输入示例:
5 4
0 1
0 2
1 3
2 4
输出示例:
0 1 2 3 4
提示信息:
文件依赖关系如下:
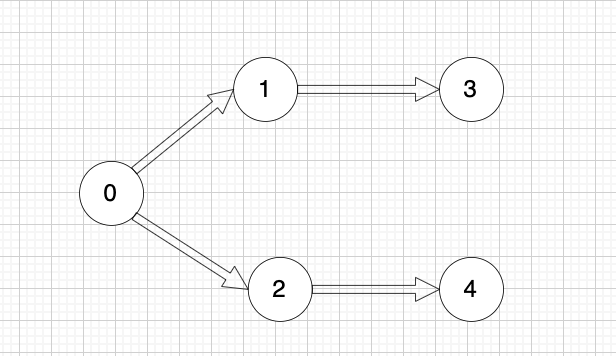
所以,文件处理的顺序除了示例中的顺序,还存在
0 2 4 1 3
0 2 1 3 4
等等合法的顺序。
数据范围:
- 0 <= N <= 10 ^ 5
- 1 <= M <= 10 ^ 9
拓扑排序指的是一种 解决问题的大体思路, 而具体算法,可能是广搜也可能是深搜。
大家可能发现 各式各样的解法,纠结哪个是拓扑排序?
其实只要能在把 有向无环图 进行线性排序 的算法 都可以叫做 拓扑排序。
实现拓扑排序的算法有两种:卡恩算法(BFS)和DFS
卡恩1962年提出这种解决拓扑排序的思路
一般来说我们只需要掌握 BFS (广度优先搜索)就可以了,清晰易懂,如果还想多了解一些,可以再去学一下 DFS 的思路,但 DFS 不是本篇重点。
接下来我们来讲解BFS的实现思路。
以题目中示例为例如图:
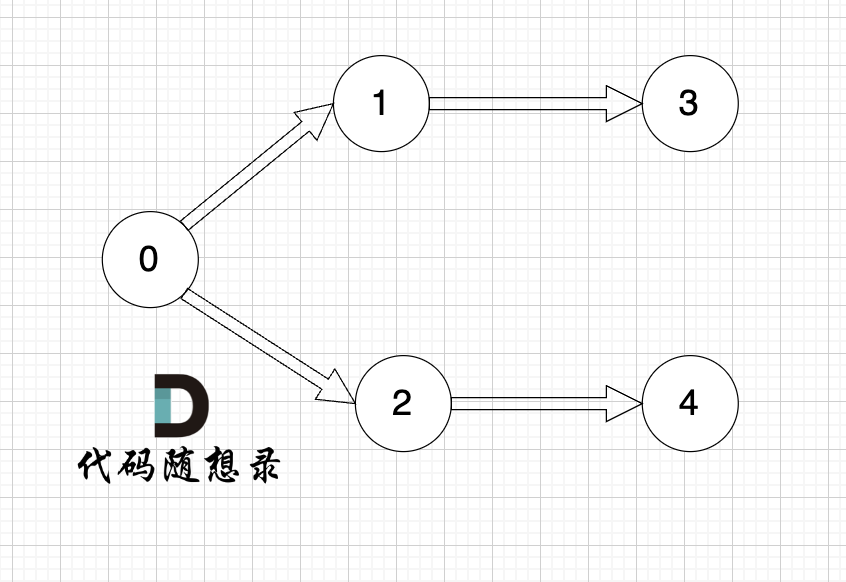
做拓扑排序的话,如果肉眼去找开头的节点,一定能找到 节点0 吧,都知道要从节点0 开始。
但为什么我们能找到 节点0呢,因为我们肉眼看着 这个图就是从 节点0出发的。
作为出发节点,它有什么特征?
你看节点0 的入度 为0 出度为2, 也就是 没有边指向它,而它有两条边是指出去的。
节点的入度表示 有多少条边指向它,节点的出度表示有多少条边 从该节点出发。
所以当我们做拓扑排序的时候,应该优先找 入度为 0 的节点,只有入度为0,它才是出发节点。 理解以上内容很重要!
接下来我给出 拓扑排序的过程,其实就两步:
- 找到入度为0 的节点,加入结果集
- 将该节点从图中移除
循环以上两步,直到 所有节点都在图中被移除了。
结果集的顺序,就是我们想要的拓扑排序顺序 (结果集里顺序可能不唯一)
import java.util.*;
public class Main {
public static void main(String[] args) {
Scanner scanner = new Scanner(System.in);
int n = scanner.nextInt();
int m = scanner.nextInt();
List<List<Integer>> umap = new ArrayList<>(); // 记录文件依赖关系
int[] inDegree = new int[n]; // 记录每个文件的入度
for (int i = 0; i < n; i++)
umap.add(new ArrayList<>());
for (int i = 0; i < m; i++) {
int s = scanner.nextInt();
int t = scanner.nextInt();
umap.get(s).add(t); // 记录s指向哪些文件
inDegree[t]++; // t的入度加一
}
Queue<Integer> queue = new LinkedList<>();
for (int i = 0; i < n; i++) {
if (inDegree[i] == 0) {
// 入度为0的文件,可以作为开头,先加入队列
queue.add(i);
}
}
List<Integer> result = new ArrayList<>();
// 拓扑排序
while (!queue.isEmpty()) {
int cur = queue.poll(); // 当前选中的文件
result.add(cur);
for (int file : umap.get(cur)) {
inDegree[file]--; // cur的指向的文件入度-1
if (inDegree[file] == 0) {
queue.add(file);
}
}
}
if (result.size() == n) {
for (int i = 0; i < result.size(); i++) {
System.out.print(result.get(i));
if (i < result.size() - 1) {
System.out.print(" ");
}
}
} else {
System.out.println(-1);
}
}
}dijkstra(朴素版)精讲
卡码网:47. 参加科学大会(opens new window)
【题目描述】
小明是一位科学家,他需要参加一场重要的国际科学大会,以展示自己的最新研究成果。
小明的起点是第一个车站,终点是最后一个车站。然而,途中的各个车站之间的道路状况、交通拥堵程度以及可能的自然因素(如天气变化)等不同,这些因素都会影响每条路径的通行时间。
小明希望能选择一条花费时间最少的路线,以确保他能够尽快到达目的地。
【输入描述】
第一行包含两个正整数,第一个正整数 N 表示一共有 N 个公共汽车站,第二个正整数 M 表示有 M 条公路。
接下来为 M 行,每行包括三个整数,S、E 和 V,代表了从 S 车站可以单向直达 E 车站,并且需要花费 V 单位的时间。
【输出描述】
输出一个整数,代表小明从起点到终点所花费的最小时间。
输入示例
7 9
1 2 1
1 3 4
2 3 2
2 4 5
3 4 2
4 5 3
2 6 4
5 7 4
6 7 9
输出示例:12
【提示信息】
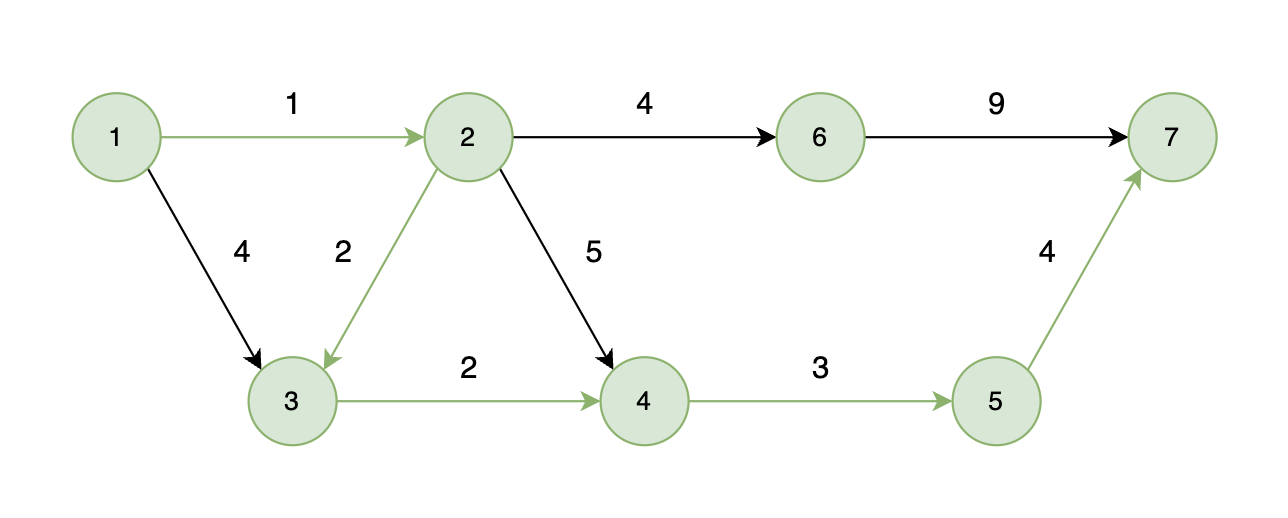
能够到达的情况:
如下图所示,起始车站为 1 号车站,终点车站为 7 号车站,绿色路线为最短的路线,路线总长度为 12,则输出 12。
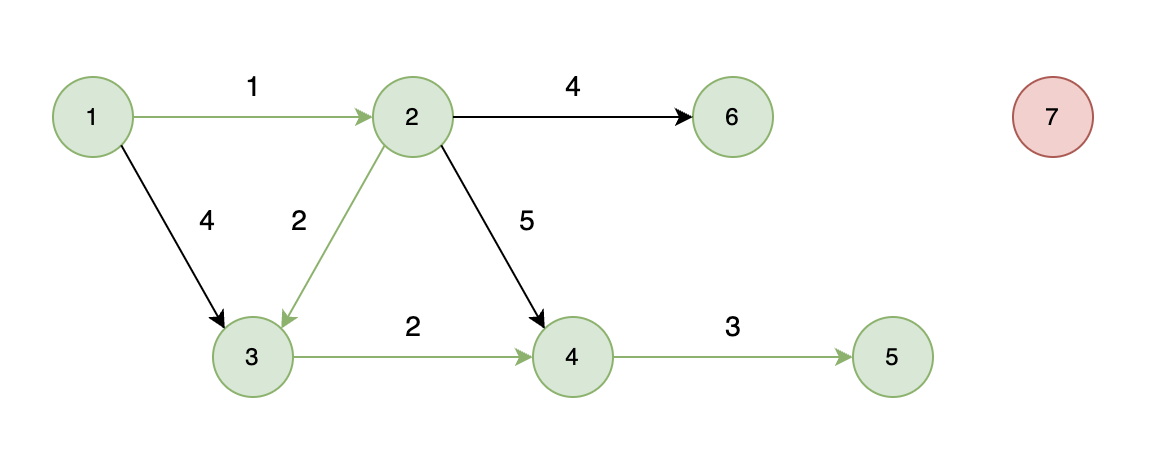
不能到达的情况:
如下图所示,当从起始车站不能到达终点车站时,则输出 -1。
数据范围:
1 <= N <= 500; 1 <= M <= 5000
本题就是求最短路,最短路是图论中的经典问题即:给出一个有向图,一个起点,一个终点,问起点到终点的最短路径。
接下来,我们来详细讲解最短路算法中的 dijkstra 算法。
dijkstra算法:在有权图(权值非负数)中求从起点到其他节点的最短路径算法。
需要注意两点:
- dijkstra 算法可以同时求 起点到所有节点的最短路径
- 权值不能为负数
(这两点后面我们会讲到)
如本题示例中的图:
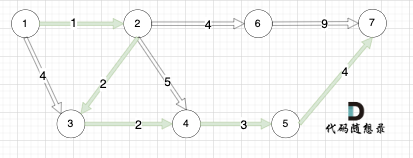
起点(节点1)到终点(节点7) 的最短路径是 图中 标记绿线的部分。
最短路径的权值为12。
其实 dijkstra 算法 和 我们之前讲解的prim算法思路非常接近,如果大家认真学过prim算法,那么理解 Dijkstra 算法会相对容易很多。(这也是我要先讲prim再讲dijkstra的原因)
dijkstra 算法 同样是贪心的思路,不断寻找距离 源点最近的没有访问过的节点。
这里我也给出 dijkstra三部曲:
- 第一步,选源点到哪个节点近且该节点未被访问过
- 第二步,该最近节点被标记访问过
- 第三步,更新非访问节点到源点的距离(即更新minDist数组)
大家此时已经会发现,这和prim算法 怎么这么像呢。
我在prim算法讲解中也给出了三部曲。 prim 和 dijkstra 确实很像,思路也是类似的,这一点我在后面还会详细来讲。
在dijkstra算法中,同样有一个数组很重要,起名为:minDist。
minDist数组 用来记录 每一个节点距离源点的最小距离。
理解这一点很重要,也是理解 dijkstra 算法的核心所在。
大家现在看着可能有点懵,不知道什么意思。
没关系,先让大家有一个印象,对理解后面讲解有帮助。
我们先来画图看一下 dijkstra 的工作过程,以本题示例为例: (以下为朴素版dijkstra的思路)
(示例中节点编号是从1开始,所以为了让大家看的不晕,minDist数组下标我也从 1 开始计数,下标0 就不使用了,这样 下标和节点标号就可以对应上了,避免大家搞混)
import java.util.Arrays;
import java.util.Scanner;
public class Main {
public static void main(String[] args) {
Scanner scanner = new Scanner(System.in);
int n = scanner.nextInt();
int m = scanner.nextInt();
int[][] grid = new int[n + 1][n + 1];
for (int i = 0; i <= n; i++) {
Arrays.fill(grid[i], Integer.MAX_VALUE);
}
for (int i = 0; i < m; i++) {
int p1 = scanner.nextInt();
int p2 = scanner.nextInt();
int val = scanner.nextInt();
grid[p1][p2] = val;
}
int start = 1;
int end = n;
// 存储从源点到每个节点的最短距离
int[] minDist = new int[n + 1];
Arrays.fill(minDist, Integer.MAX_VALUE);
// 记录顶点是否被访问过
boolean[] visited = new boolean[n + 1];
minDist[start] = 0; // 起始点到自身的距离为0
for (int i = 1; i <= n; i++) { // 遍历所有节点
int minVal = Integer.MAX_VALUE;
int cur = 1;
// 1、选距离源点最近且未访问过的节点
for (int v = 1; v <= n; ++v) {
if (!visited[v] && minDist[v] < minVal) {
minVal = minDist[v];
cur = v;
}
}
visited[cur] = true; // 2、标记该节点已被访问
// 3、第三步,更新非访问节点到源点的距离(即更新minDist数组)
for (int v = 1; v <= n; v++) {
if (!visited[v] && grid[cur][v] != Integer.MAX_VALUE && minDist[cur] + grid[cur][v] < minDist[v]) {
minDist[v] = minDist[cur] + grid[cur][v];
}
}
}
if (minDist[end] == Integer.MAX_VALUE) {
System.out.println(-1); // 不能到达终点
} else {
System.out.println(minDist[end]); // 到达终点最短路径
}
}
}