bluecode-20240913_1_数据解码
时间限制:C/C++ 1000MS,其他语言 2000MS
内存限制:C/C++ 256MB,其他语言 512MB
难度:困难
内存限制:C/C++ 256MB,其他语言 512MB
难度:困难
数据解码
指定有一段经过编码的二进制数据,数据由0个或多个"编码单元"组成。"编码单元"的编码方式存在如下两种:
1简单编码单元如下所示,其中:
- TAG所占长度须为1字节,其值须为0xF0
- SINGLE-VALUE的长度定为4字节
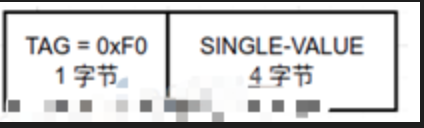
2.复杂编码单元如下所示,其中:
- TAG所占长度须为1字节,其值须为0xF1
- REPEAT所占长度固定为1字节,用于指示值在解码后消息中重复的次数
- LEN所占长度固定为4字节,用于指示值的字节数,LEN使用大端序表示
- 值部分必须由0个或多个"编码单元"组成,且长度必须为LEN字设所指示的字节数

编码后的数据必须完全符合上述两个原则,不允许有任何冗余的字节,请构造符合上述规则的10个编码:
请根据上述规则对一段编码后的数据进行校验,如果完全符合上述约束则输出解码后的长度,否则输出-1
输入描述
输入一行编码后的二进制数据,按字节16进制表示,如
F0 00 08 09 00
表示一串5字节的编码后数据
输入的字节数n,0<=n<=100000
输出描述
输出解码后的值的字节数,不符合约束返回-1
用例输入 1
F1 02 00 00 00 05 F0 01 02 03 04
用例输出 1
8
用例输入 2
F1 01 00 00 00 04 F0 01 05
用例输出 2
-1
提示
样例1解释:该码流存在一个复杂编码单元,其中包含一个简单编码单元(内容4字节),复杂编码单元的重复数为2,所以解码后的总长度为8字节
样例2解释:第一个编码单元为复杂编码单元,重复数为1,长度为6,其中的内容从第一个字节开始为一个简单编码单元,但简单编码单元后存在数据0303既不属于简单编码单元,也不属于复杂编码单元,为冗余数据,整体数据不合法,应输出-1
#include <iostream>
#include <vector>
#include <cstdint>
using namespace std;
// Helper function to parse a single encoding unit
pair<int, int> parseUnit(const vector<uint8_t>& data, int index) {
if (index >= data.size()) {
return {-1, -1}; // Invalid input
}
uint8_t tag = data[index];
index++;
if (tag == 0xF0) {
// Simple encoding unit: 1 byte TAG + 4 bytes SINGLE-VALUE
if (index + 4 > data.size()) {
return {-1, -1}; // Not enough bytes for SIMPLE-VALUE
}
return {index + 4, 4}; // Move past the SIMPLE-VALUE and return decoded length
} else if (tag == 0xF1) {
// Complex encoding unit: 1 byte TAG + 1 byte REPEAT + 4 bytes LEN + LEN bytes content
if (index + 5 > data.size()) {
return {-1, -1}; // Not enough bytes for REPEAT and LEN
}
uint8_t repeat = data[index];
index++;
// Read LEN (4 bytes, big-endian)
uint32_t len = 0;
for (int i = 0; i < 4; ++i) {
len = (len << 8) | data[index++];
}
// Check if we have enough bytes for the content
if (index + len > data.size()) {
return {-1, -1}; // Not enough bytes for the content
}
// Parse the content recursively
int contentStart = index;
int totalDecoded = 0;
while (index < contentStart + len) {
auto [newIndex, decodedLen] = parseUnit(data, index);
if (newIndex == -1) {
return {-1, -1}; // Invalid content
}
index = newIndex;
totalDecoded += decodedLen;
}
// Ensure no extra bytes in the content
if (index != contentStart + len) {
return {-1, -1}; // Extra bytes found
}
return {index, totalDecoded * repeat};
} else {
// Invalid TAG
return {-1, -1};
}
}
// Main function to decode the length
int decodeLength(const vector<uint8_t>& data) {
auto [index, decodedLen] = parseUnit(data, 0);
// Ensure all bytes are consumed
if (index == static_cast<int>(data.size())) {
return decodedLen;
} else {
return -1; // Redundant bytes found
}
}
// Helper function to convert hex string to byte array
vector<uint8_t> hexToBytes(const string& hex) {
vector<uint8_t> bytes;
for (size_t i = 0; i < hex.length(); i += 2) {
string byteString = hex.substr(i, 2);
uint8_t byte = static_cast<uint8_t>(stoul(byteString, nullptr, 16));
bytes.push_back(byte);
}
return bytes;
}
int main() {
string hexInput;
getline(cin, hexInput);
// Remove spaces from the input
string cleanedInput;
for (char c : hexInput) {
if (c != ' ') {
cleanedInput += c;
}
}
// Convert hex string to byte array
vector<uint8_t> data = hexToBytes(cleanedInput);
// Decode the length
int result = decodeLength(data);
cout << result << endl;
return 0;
}