LLaMA-Factory微调实操记录
1. LLaMA-Factory介绍
来源:国内开发,支持中文
简介:LLaMA Factory 是一个简单易用且高效的大型语言模型(Large Language Model)训练与微调平台。通过 LLaMA Factory,可以在无需编写任何代码的前提下,在本地完成上百种预训练模型的微调。
文档1:LLaMA-Factory文档1
文档2:LLaMA-Factory文档2
2.配置环境
安装步骤:
- 下载(上述文档有下载命令):git clone --depth https://github.com/hiyouga/LLaMA-Factory.git
- 解压下载的llamafactory:unzip llamafactory.zip
- 先创建环境:conda create -n llamafactory python==3.10 -y
- 激活环境:source activate llamafactory
- 安装所需要的包:pip install -e .(一定要安装在创建的环境中哈,操作之前:cd LLaMa_factoty 的目录下)
- 启动(使用可视化,在llamafactory根目录下启动):llamafactory-cli webui
启动之后的页面:

3. 使用LLaMA-Factory进行微调
下面我们来一一介绍如何设置页面上的参数:
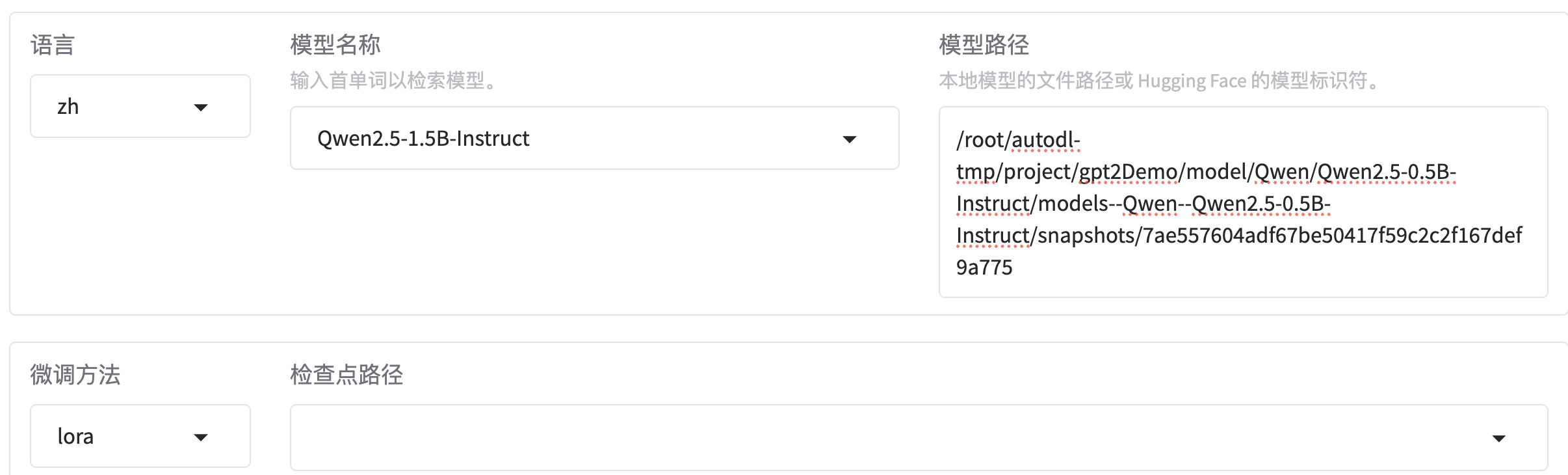
语言:选择中文
模型名称:根据你要训练的模型名称进行搜索
模型路径:选择你下载好的模型的绝对路径
微调方法:这里我们选择lora微调
检查点路径:这里我们第一次微调,没有检查点,所以先不填

对话模版:这里会自动匹配
其他参数:先使用默认参数即可

这里我们先关注以下参数:
- 数据集:我们选择要用于训练的数据集,如果数据集找不到,那就是放错目录了;这里可以同时放多个数据集
- 训练轮次:尽量设置的大一点,在训练过程中,如果效果达到预期我们可以随时叫停
- 截断长度:根据你要训练的数据集的对话长度设置,我们这里对话较短,所以选的比较小
- 批次处理大小:根据显卡能力的大小进行调整,保证显卡计算力在90%即可
- 验证集比例:这里可以不用设置,因为GPT类型的大模型进行验证的意义不大

上述参数保持默认即可,或者根据你的情况先进行调整。

准备就绪,开始训练

这就表示已经开始训练了,那么等到什么时候就可以停止训练了呢?
一般来说,等到loss趋向收敛的时候就可以停止训练了,如下所示:
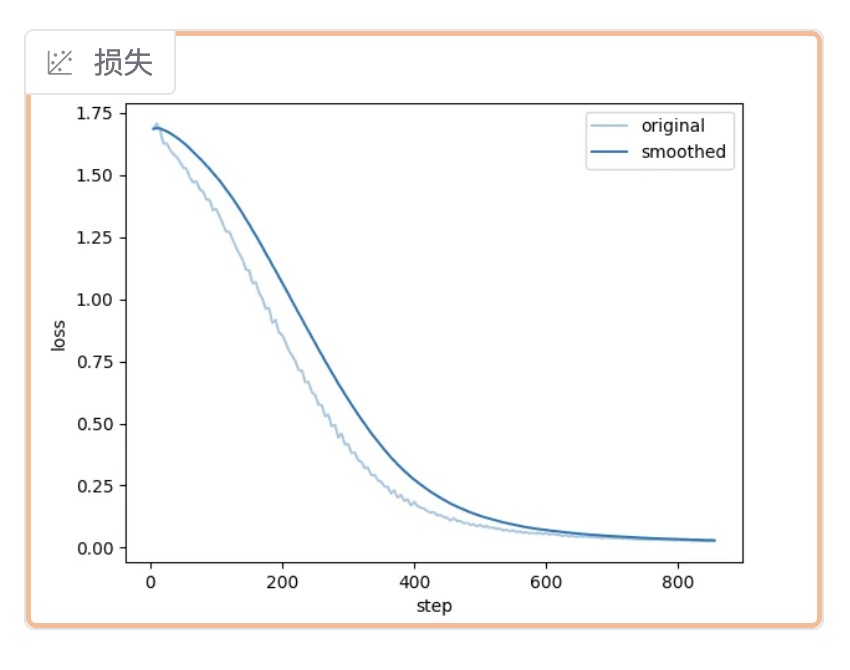
训练好的参数,保存在如下目录:

4. 测试微调后的模型
在测试之前,我们先得知道一个知识,就是:
我们这次微调采用的是lora微调,它是局部微调,所以微调得到的参数只是模型的一部分参数,我们不能单独使用上述图中的检查点进行测试,需要和原模型结合进行Chat 测试。具体操作如下:

加载模型之后,和他对话聊天,进行主观测评(我们可以先使用训练时用到的数据集中的数据进行测试):

5. 测试之后,进行模型的合并导出
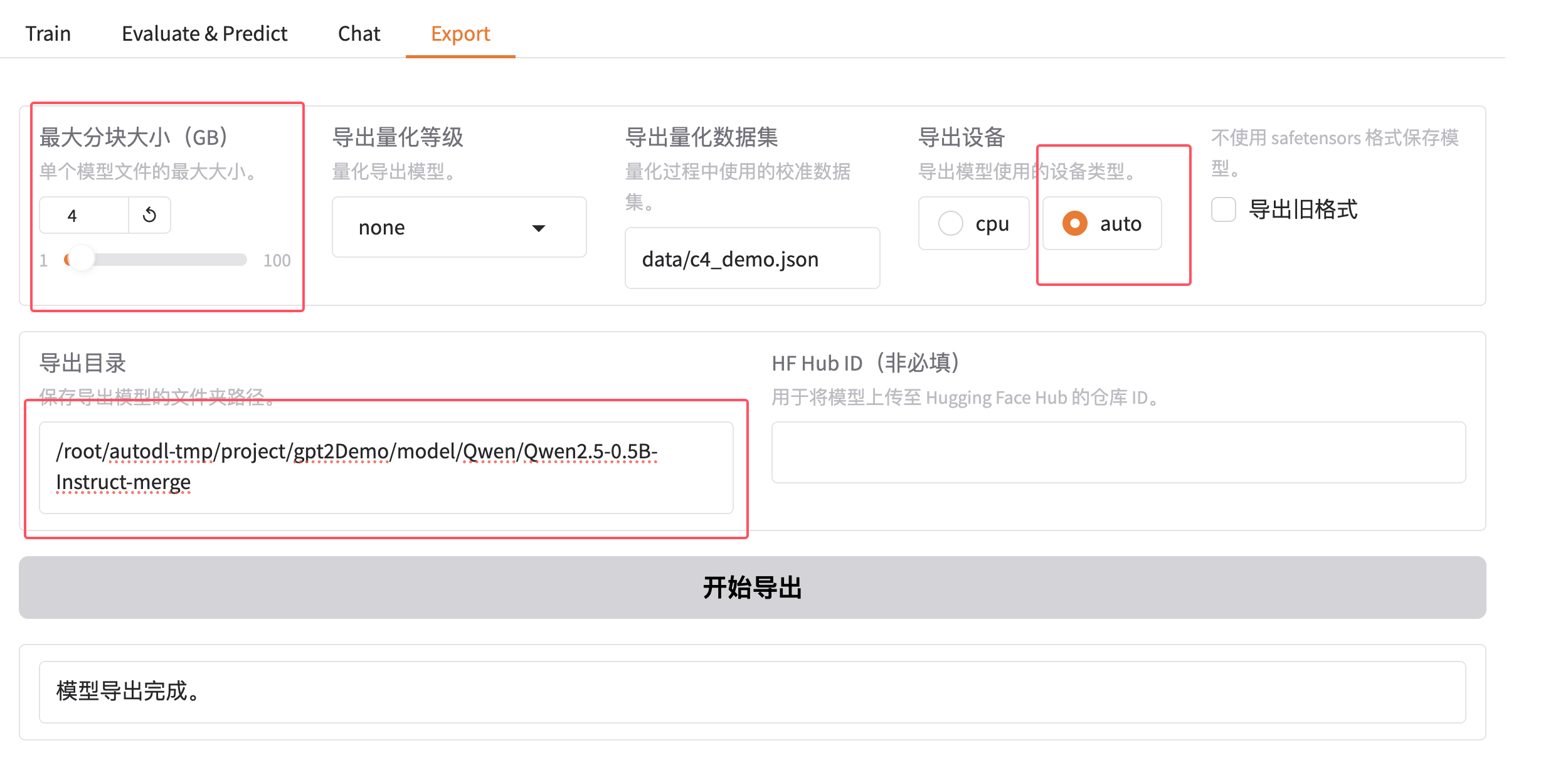
最大分块大小(GB):一般小于4GB
导出量化等级:就是阉割模型,这次我们先不量化
6. 合并导出之后,进行量化
6.1 量化目的以及优缺点
量化的目的是为了降低模型对设备的要求
- 量化一般是发生在特别大的模型上,像0.5B的这种一般是不需要量化的
- 优点:一般来说,量化之后模型的体积会变小,对机器的要求变低
- 缺点:量化之后的精度会变差,量化也是逐层量化,每层都会有误差,误差叠加起来之后的会比较影响模型精度
6.2 量化导出操作
注意:在LLaMA-Factory中量化时,不能直接把原模型和检查点结合,然后进行进行量化。只能量化原模型,或者原模型微调导出后的模型

- 最大分块大小(GB):一般小于4GB
- 导出量化等级:就是阉割模型,一般来说,选择量化为8位就行,模型实在太大就可以量化为4位
量化之后的效果:

对于这次实现的模型,模型只有0.5B,所以量化之后的模型几乎不可用了。
7 Lora和QLora微调
7.1 Lora和QLora微调的区别
-
QLora在就是在模型训练中进行量化微调,微调过程中的量化不会影响模型最后的参数大小。这就降低了对GPU的要求,但是相应的时间成本就增加了,因为需要把量化之后又得反解码。
-
Lora在微调过程中没有进行量化的操作,相比QLora而言,它对GPU的要求会更高。
更加详细的原理以及区别,请大家自行学习吧,我这也说不明白。
7.2 参数设置
量化等级一般为8,如果模型实在太大可以设置为4

LoRA参数:实验验证比较好的设置参数,这些都是超参,都是试出来的,具体的数学原理未知

LoRA的秩一般为:32~128,再大的话,显存的占用率会更高,效率会变低
总结:一般微调不会采用LoRA,而是采用QLoRA