排序--归并排序--非递归
一,引言
归并排序通常使用递归的方式进行实现,但是当数据过于极端,或者数据量大或者特殊时,可能回出现栈溢出的风险,因此本文为了解决这个问题,来进行讲解归并排序的非递归的逻辑思想以及代码实现。
二,逻辑讲解
首先来看一组动图:

在递归的逻辑中,通过一次次递归,直到最小分组之后进行排序。而非递归的思路是:我们可不可以先按照最小分组进行比较,之后逐步扩大分组,以便于达到相同的目的。
第一次排序:
通过一个变量进行控制每组的个数,从一开始,代表每一组只有一个数据,之后亮亮进行比较,
直到该数组比较结束。如图:

红色的两组进行两两比较,使其变成升序,如图:

第二步:
使每组个数提高一倍,再次进行分组如图:

再次两两比较进行升序排序。如图:

第三步:
再次扩大每组个数,增大一倍进行分组:
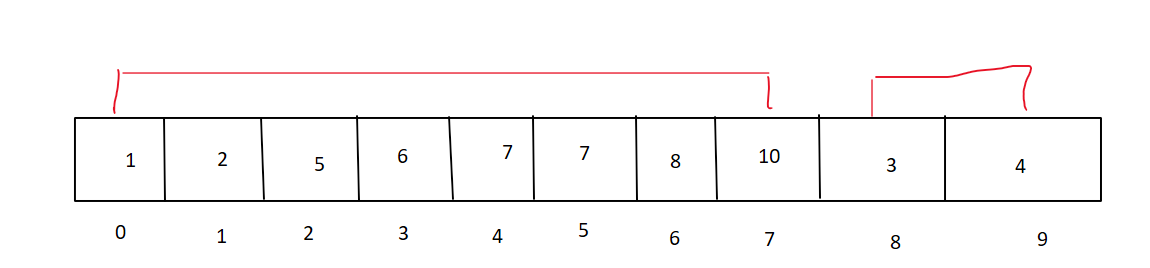
这两组继续进行升序排序,两两比较,进行排序。当单组个数大于等于总个数时排序结束。
单趟排序逻辑:
首先需要新开辟一个数组和原数组大小一样的空间,之后,两组的数值进行依次比较,依次拷贝到新开辟的数值中,拷贝结束后,将新数组的值拷贝回原数组。单趟排序结束。
以第三步为例,如图:

全部拷贝结束,将新数组的值拷贝回原数组。至此排序结束。
三,代码实现
void MergeNo_Re(int* p, int* q, int left, int right)
{
for (int gap=1; gap <= right; gap = gap * 2)
{
for (int begin1 = 0; begin1 <= right; begin1 )
{
int begin = begin1;
int tag = begin1;
int end1 = begin1 + gap - 1;
int begin2 = begin1 + gap;
int end2 = begin1 + 2 * gap - 1;
int end = end2;
if (begin2 > right)
{
break;
}
if (end2 >= right)
{
end2 = right;
end = end2;
}
while (begin1 <= end1 && begin2 <= end2)
{
if (p[begin1] < p[begin2])
{
q[tag] = p[begin1];
begin1++;
}
else
{
q[tag] = p[begin2];
begin2++;
}
tag++;
}
while (begin2 <= end2)
{
q[tag] = p[begin2];
begin2++;
tag++;
}
while (begin1 <= end1)
{
q[tag] = p[begin1];
begin1++;
tag++;
}
memcpy(p + begin, q + begin, (end - begin + 1) * sizeof(int));
begin1 = begin + 2 * gap;
}
}
}
后面三个while循环的进行单个比较拷贝,第二个for循环进行,两两组的比较,在每组个数一定的情况下,使得该数组的全部组数都比较完毕。第一个for循环进行每组个数的控制,依次翻倍处理。
注意事项:
1,首先传参第一个的原数组的地址,第二个是新数组的地址,第三个是该数组的头位置,第四个是该数组的尾位置。
2,注意第一个for循环的判断结束条件,只要小于个数就要继续进行比较。
3,第二个for循环中,如果两两比较,出现没有第二组和第一组比较的情况,就不需要进行比较了,若第二组的数组已经小于尾部的位置,那么需要将第二组数据控制尾部的变量进行再次赋值,以防止数据越界。
4,在最后的memcpy的函数中,要提前标记相比较的两组的首位位置,以防止在最后的拷贝过程中找不到相对位置。
四,总结
归并非递归排序的思想比较抽象,需要同学们多多思考,多多练习,才能熟练掌握,有任何问题评论区进行留言。