使用FastExcel时的单个和批量插入的问题
在我们用excel表进行插入导出的时候,通常使用easyexcel或者FastExcel,而fastexcel是easy的升级版本,今天我们就对使用FastExcel时往数据库插入数据的业务场景做出一个详细的剖析
场景1
现在我们数据库有一张组织表,组织表的字段如下
package com.example.tabledemo.pojo.entity;
import com.baomidou.mybatisplus.annotation.TableField;
import com.baomidou.mybatisplus.annotation.TableName;
import com.example.tabledemo.pojo.BaseEntity;
import lombok.Data;
/**
* @Author: wyz
* @Date: 2025-03-25-10:18
* @Description:
*/
@TableName("organization")
@Data
public class OrganizationEntity extends BaseEntity {
/**
* 组织代码
* <p>
* 组织的唯一代码,用于标识不同的组织,不能为空。
* </p>
*/
@TableField("org_code")
private String orgCode;
/**
* 学院/组织名称
* <p>
* 组织的名称,用于描述组织的具体名称,不能为空。
* </p>
*/
@TableField("org_name")
private String orgName;
/**
* 组织类型
* <p>
* 组织的类型,用于描述组织的分类或性质,可以为空。
* </p>
*/
@TableField("org_type")
private String orgType;
}现在我们业务要求是,组织code和组织name在插入的过程中是唯一性,也就是说这两个字段的数据是唯一的,那我们对这种情况有两种处理方式
方式1
我们应该最先想到的是在业务层进行重复值的判断,具体的流程如下

然后我们按照此流程进行插入,但是这样会出现一个典型的多线程问题,就是我再查询结束之后,进行插入的时候,有另外一个线程也插入了,这时候我又插入成功,不是出现了问题,那么解决这个问题的方法也很简单,对资源上锁就行了
方式2
我们为org_name 和org_code分别在数据库中设置一个唯一性约束
create table organization
(
id bigint auto_increment comment '序号,主键,自增'
primary key,
org_code varchar(50) not null comment '组织代码',
org_name varchar(100) not null comment '学院/组织名称',
org_type varchar(50) null comment '类型',
status int default 0 null comment '状态,默认为0(可用)',
create_time datetime default CURRENT_TIMESTAMP null comment '创建时间,插入时自动填充',
update_time datetime default CURRENT_TIMESTAMP null on update CURRENT_TIMESTAMP comment '更新时间,插入和更新时自动填充',
is_deleted int default 0 null comment '逻辑删除标志,0表示未删除,1表示已删除',
constraint org_code
unique (org_code),
constraint org_name
unique (org_name)
)
comment '组织信息表';这样的话,在我们后台我们只需要关注插入的问题就行了,甚至修改的时候都不需要关心数据重复性的问题,因为在mysql底层,他会为每一个设置唯一性约束的字段创建一个索引,索引是b+树结构的,每次插入的时候会查询是否有这个索引,没有就插入,有就会报错
对应的java代码如下,我们不需要加事务是因为 这是对单表进行的纯插入删除操作,无需回滚,插入不成功我们数据库有唯一性约束数据库会自动禁止插入,而且在 mybatisplus的saveOrupdate方法中也有事务管理

@Override
// @Transactional(rollbackFor = Exception.class)无需事务
public Result add(OrganizationRequest.addOrganization addOrganization) {
OrganizationEntity organizationEntity = new OrganizationEntity();
BeanUtil.copyProperties(addOrganization,organizationEntity);
try {
boolean b = saveOrUpdate(organizationEntity);
return Result.success(b);
}catch (Exception e){
if (e.getCause() instanceof SQLException) {
SQLException sqlException = (SQLException) e.getCause();
if (sqlException.getErrorCode() == 1062) { // MySQL 唯一性约束错误码
return Result.fail("组织名称或代码已存在,请勿重复插入!");
}
}
return Result.fail("数据库操作失败:" + e.getMessage());
}
}问题1
当我们组织表信息量大了以后,我们每一次数据的插入都会使得mysql底层的索引的b+树结构改变,这种IO带来的开销无疑是越来越大的,所以,根据这个延申出来的解决方案也有几种
对mysql进行分库分表,然后让name和code做一次hash,根据不同的hash找到不同的表,然后进行数据的插入等这样能减少重建索引带来的IO开销。但是无论是哪种方法,都有一定的优缺点,看我们如何选择了吧
场景二
现在做的是一个excel表,我们填充完数据之后,需要批量导入,这时候org_name 和org_code也是需要唯一的,同样的也有两种方式,就是我们上文所说的,只是问题从 单个插入变成了批量插入。
而批量插入在数据库中的事务也同样延申出来的许多的问题
问题1
我在使用数据库 原始的sql进行批量插入的时候,假如有3条数据ABC,B数据和C数据一样,这时候如果我加了唯一性约束,会不会导致A插入成功,B,C两条数据没有插入成功下面我们来测试一下
我们现在拿到的是最新的数据

我们插入一下看看

我们再次查询一下数据库看一下

数据并没有变化,说明了在我们用values的时候,如果加了唯一性约束,这些批量插入的后面是同一个事务的,只要有一个失败,就会回滚所有的数据。
那我们再看同一个事务下,三条数据分批次插入的情况


显而易见,分批次插入的话,只有出现异常的数据不会被插入。
那么我们再来分析,假如说 现在 我们批量插入上面三条数据,那么第一条成功了,那么第二条还没有插入的时候,这时候这个字段的唯一索引变化是怎么样的,这时候唯一索引会带来额外的额外的io开销吗?
我们看下面一张图
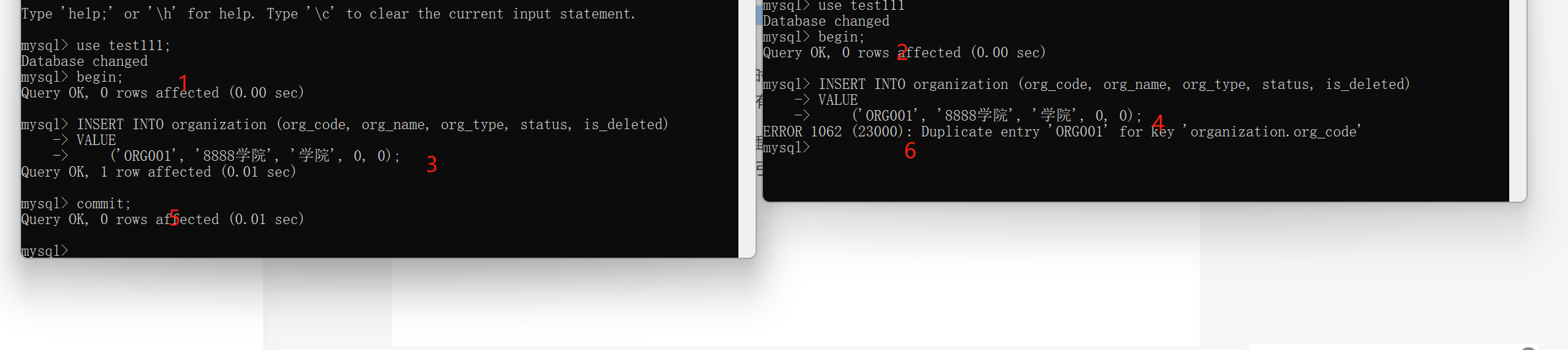
我是按照红字的顺序进行事务的数据插入操作的,当我进行到4的时候,我5没有提交事务,这时候4会一直阻塞,原因是 REPEATABLE READ 隔离级别下,事务会持有插入的行的排他锁(X Lock),直到事务提交或回滚。
我们再回来看索引的问题,当我们事务没有提交的时候,也就是步骤进行到3的时候,其实mysql已经为我们插入的这条数据加了唯一性索引了,假如这时候出现了异常,导致了事务回滚,那么索引就会重新取消,这也时带来io开销
其实解决情况已经很明了了,如果不想让数据库有多的索引的io开销,那么我们就要在代码层面控制,先查询所有数据,然后比对唯一性,要么就是 数据库层面控制,
如果是在数据库层面控制,要注意 插入的时候不要用for循环单条插入,而是saveBacth批量插入,如果非用for循环单挑插入,记得使用spring的事务注解,就跟我们前面说的一样,如果是设计多条数据的改变,而且需要回滚所有,这时候记得加事务
@Override
// @Transactional(rollbackFor = Exception.class)
public void doAfterAllAnalysed(AnalysisContext context) {
log.info("所有数据解析完成!");
// 字段唯一性约束 可以 用mysql 自己的 也可用 代码逻辑判断
List<OrganizationEntity> organizationEntities = BeanUtil.copyToList(list, OrganizationEntity.class);
// boolean b = organizationService.saveBatch(organizationEntities);
// log.info("保存成功");
try {
boolean b = organizationService.saveBatch(organizationEntities);
log.info("保存成功");
}catch (Exception e){
if (e.getCause() instanceof SQLException) {
SQLException sqlException = (SQLException) e.getCause();
if (sqlException.getErrorCode() == 1062) { // MySQL 唯一性约束错误码
throw new RuntimeException("组织名称或代码已存在,请勿重复插入!");
}
}
throw new RuntimeException("数据库操作失败:" + e.getMessage());
}
}而在我的代码中为什么我把事务注解注释掉了,因为再mybatisplus中,他的saveBatch方法默认加了事务