【大模型】大模型知识蒸馏 综述解读(Knowledge Distillation of Large Language Models)
知识蒸馏综述解读
- 论文: https://arxiv.org/abs/2402.13116 (2024.02.20)
- 代码: https://github.com/Tebmer/Awesome-Knowledge-Distillation-of-LLMs
之前虽然阅读了 2021年的综述 《Knowledge Distillation: A Survey》,并总结一篇笔记"【模型压缩+推理加速】知识蒸馏综述解读",但这一篇文章主要是梳理传统模型的中的蒸馏方法,没有涉及大模型蒸馏方法,比如Deepseek R1 中提到的蒸馏。
这里,我们找到一篇2024年2月份的来自香港大学的大模型知识蒸馏的综述《A Survey on Knowledge Distillation of Large Language Models》,其引用量也是24年以来最高的。这篇综述有43页,知识面非常全面,不仅仅包括大模型蒸馏的基本知识,还有大模型中SFT、强化学习训练、DPO等原理的梳理和总结。我们还是按照论文结构抓重点介绍。
论文结构:

文章目录
- 知识蒸馏综述解读
- 论文结构:
- @[toc]
- 1 INTRODUCTION
- 2. OVERVIEW
- 3.知识蒸馏算法
- 3.1 知识
- 1. Labeling(标注)
- 2. Expansion(扩展)
- 3. Data Curation(数据策展)
- 4. Feature(特征)
- 5. Feedback(反馈)
- 6. Self-Knowledge(自知识)
- 3.2 蒸馏
- 3.2.1 监督微调(Supervised Fine-Tuning)
- 3.2.2 散度和相似度(Divergence and Similarity)
- 3.2.3 强化学习(Reinforcement Learning)
- 3.2.4 排名优化(Ranking Optimization):DPO、RRHF、PRO
- 4 蒸馏技能(SKILL DISTILLATION)
- 4.1 (论文)方法总结
- 4.2 核心技能分类
- 引用
文章目录
- 知识蒸馏综述解读
- 论文结构:
- @[toc]
- 1 INTRODUCTION
- 2. OVERVIEW
- 3.知识蒸馏算法
- 3.1 知识
- 1. Labeling(标注)
- 2. Expansion(扩展)
- 3. Data Curation(数据策展)
- 4. Feature(特征)
- 5. Feedback(反馈)
- 6. Self-Knowledge(自知识)
- 3.2 蒸馏
- 3.2.1 监督微调(Supervised Fine-Tuning)
- 3.2.2 散度和相似度(Divergence and Similarity)
- 3.2.3 强化学习(Reinforcement Learning)
- 3.2.4 排名优化(Ranking Optimization):DPO、RRHF、PRO
- 4 蒸馏技能(SKILL DISTILLATION)
- 4.1 (论文)方法总结
- 4.2 核心技能分类
- 引用
1 INTRODUCTION
知识蒸馏(KD)的核心作用
- 能力迁移:通过监督微调(SFT)、反馈优化等技术,将专有模型的知识(如推理模式、价值观)转移至开源模型 [1]
- 模型压缩:结合量化、剪枝等技术,降低模型复杂度,提升部署效率 [2]
- 自改进:利用模型自身生成数据迭代优化,突破传统教师-学生范式 [3]

Fig. 1 详细说明了,知识蒸馏在大型语言模型中的三大核心作用:
-
- Primarily Enhancing Capabilities(主要能力增强) :缩小专有模型与开源模型的性能差距,通过知识迁移提升开源模型的能力。 方法包括: 监督微调(SFT)、数据增强(DA)、技能蒸馏。 比如:Vicuna基于ShareGPT对话数据训练,通过SFT模仿ChatGPT的多轮对话能力。 WizardMath结合Evol-Instruct(指令进化)与RLAIF(强化学习),在数学推理任务中超越ChatGPT。
-
- Traditional Compression for Efficiency(传统压缩以提升效率) :在减少模型规模的同时保持性能,降低部署成本。 技术有:量化、剪枝与低秩近似、知识蒸馏优化。 于此同事也存在挑战,专有模型的黑箱特性限制了中间层特征的提取,需依赖输出分布或反馈知识。
-
- Self-Improvement via Self-Generated Knowledge(自生成知识驱动的自我改进) :突破传统教师-学生范式,利用模型自身生成的数据迭代优化。 方法包括: 自指令(Self-Instruct)、自我反馈(Self-Feedback)、强化学习(RL)。 比如: Phi系列模型通过合成“教科书质量”数据(如Python代码解释),在小规模下实现高性能。 CoT-Distill通过自生成推理路径提升模型的多步推理能力。
2. OVERVIEW
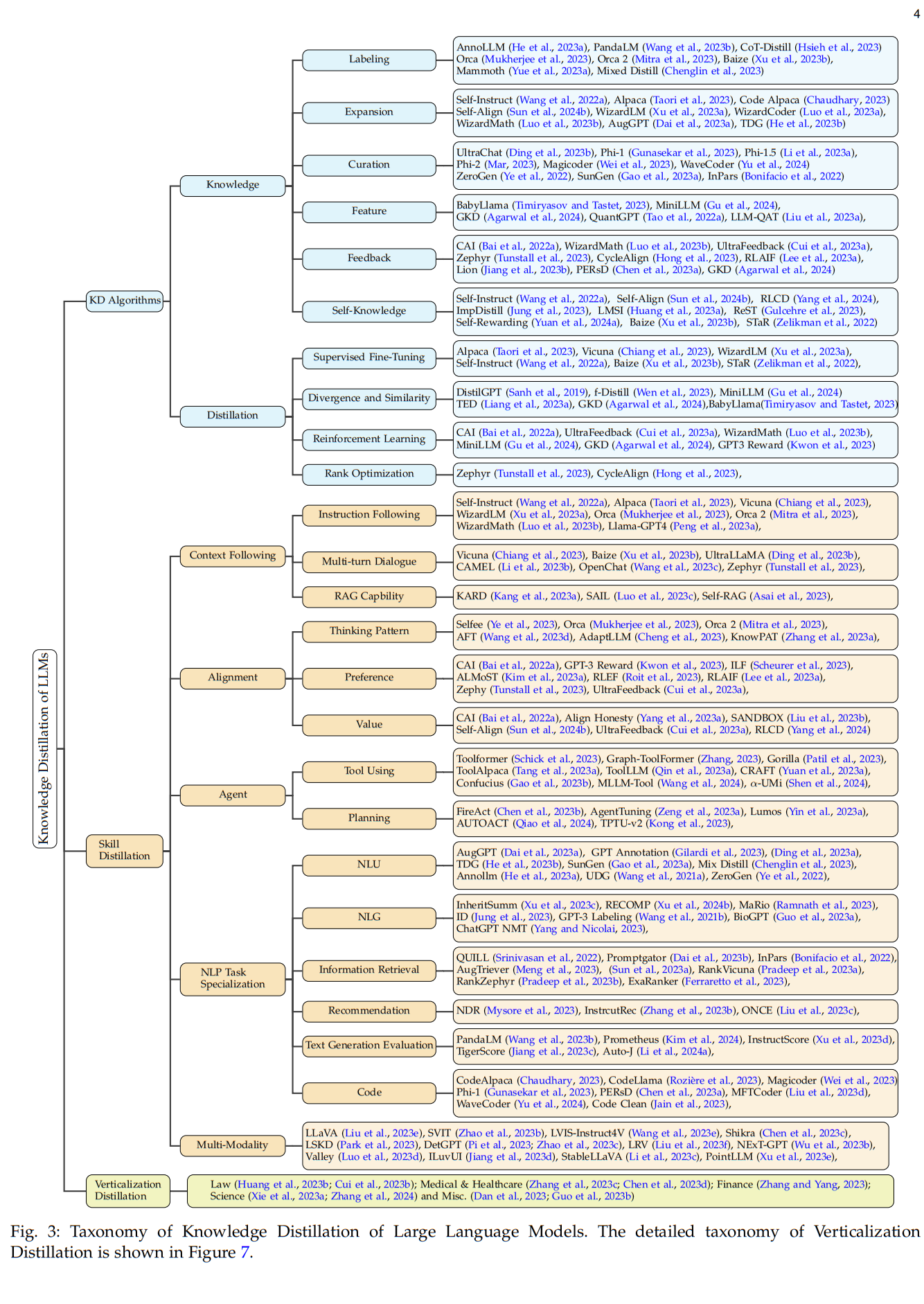
如Fig. 3所示,介绍了知识蒸馏在大型语言模型中的分类法:
知识蒸馏在大型语言模型中的分类法
├─ **知识蒸馏算法**
│ ├─ **知识**
│ │ ├─ 标注
│ │ │ - 教师模型直接标注数据(如Orca标注思维链解释)
│ │ ├─ 扩展
│ │ │ - 上下文学习生成新数据(如Self-Instruct扩展至52K指令)
│ │ ├─ 数据策展
│ │ │ - 基于元信息合成数据(如Phi生成“教科书级”代码)
│ │ ├─ 特征
│ │ │ - 提取中间层特征/输出分布(如MiniLLM反向KL散度)
│ │ ├─ 反馈
│ │ │ - 教师评估学生输出(如RLAIF优化无害性)
│ │ └─ 自知识
│ │ - 学生自生成数据(如Self-Align迭代优化)
│ └─ **蒸馏**
│ ├─ 监督微调(SFT)
│ │ - 优化交叉熵(如Vicuna基于ShareGPT训练)
│ ├─ 散度与相似性
│ │ - 最小化分布差异(如TED层间相似性)
│ ├─ 强化学习(RL)
│ │ - 奖励模型优化策略(如WizardMath结合RL)
│ └─ 排序优化
│ - 直接利用偏好数据(如Zephyr的DPO方法)
├─ **技能蒸馏**
│ ├─ **上下文遵循**
│ │ ├─ 指令遵循
│ │ │ - 复杂指令处理(如WizardLM通过Evol-Instruct)
│ │ ├─ 多轮对话
│ │ │ - 多轮对话能力(如UltraLLaMA基于1.5M对话)
│ │ └─ RAG能力
│ │ - 检索增强生成(如SAIL结合搜索结果)
│ ├─ **对齐**
│ │ ├─ 思维模式
│ │ │ - 模仿推理过程(如Orca标注思维链)
│ │ ├─ 偏好
│ │ │ - 用户偏好优化(如RLAIF结合AI反馈)
│ │ └─ 价值观
│ │ - 价值观对齐(如UltraFeedback标注诚实性)
│ ├─ **智能体**
│ │ ├─ 工具使用
│ │ │ - 调用外部工具(如Toolformer自动选择API)
│ │ └─ 规划
│ │ - 任务分解执行(如FireAct基于轨迹训练)
│ ├─ **NLP任务专业化**
│ │ ├─ 自然语言理解/生成
│ │ │ - 文本分类/生成(如AugGPT增强临床文本)
│ │ ├─ 代码/信息检索/推荐
│ │ │ - 代码生成/检索/推荐(如Code Alpaca专注编程)
│ └─ **多模态**
│ ├─ 视觉-语言
│ │ - 图文对齐(如LLaVA通过GPT-4生成对话)
└─ **垂直化蒸馏**
├─ 法律
│ - LawyerLLaMA(司法考试数据+ChatGPT生成咨询)
├─ 医疗健康
│ - HuatuoGPT(医患对话+GPT-4增强)
├─ 科学
│ - SciGLM(科学论文+自反思指令)
└─ 金融
- XuanYuan(自指令生成金融数据)
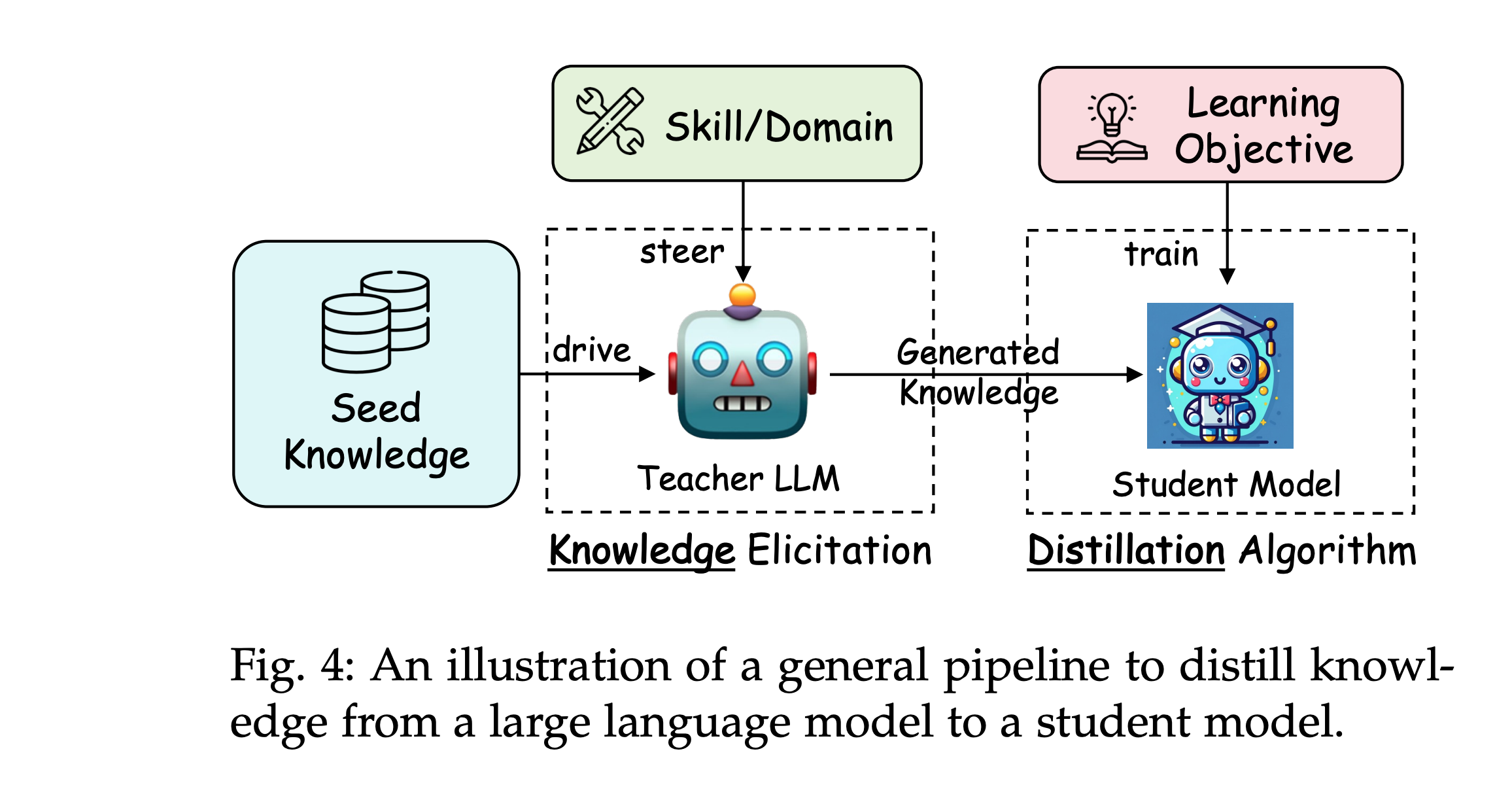
如图 Fig. 4 表示从大型语言模型到学生模型的知识蒸馏通用流程示意图。 通过“引导→激发→训练”的闭环,将教师模型的领域知识高效迁移至学生模型。过程如下:
-
- 目标技能或领域引导 :通过指令或模板(如医疗/法律领域)引导教师模型(如GPT-4)聚焦特定能力。
-
- 种子知识输入 : 提供少量种子数据(如示例问答),触发教师模型生成更多相关知识。
-
- 生成蒸馏知识 : 教师模型基于种子数据生成知识示例(如QA对、推理过程),可能包含文本、特征或反馈。
-
- 训练学生模型 : 使用生成的知识数据训练学生模型,通过损失函数(如交叉熵、KL散度)优化参数。
抽象公式
-
知识引出:
D I ( k d ) = { P a r s e ( o , s ) ∣ o ∼ p T ( o ∣ I ⊕ s ) , ∀ s ∼ S } \mathcal{D}_{I}^{(kd)}=\left\{Parse(o, s) | o \sim p_{T}(o | I \oplus s), \forall s \sim \mathcal{S}\right\} DI(kd)={Parse(o,s)∣o∼pT(o∣I⊕s),∀s∼S}
(教师模型根据指令 I I I 和种子 s s s 生成知识数据) -
学习目标:
L = ∑ I L I ( D I ( k d ) ; θ S ) \mathcal{L}=\sum_{I} \mathcal{L}_{I}\left(\mathcal{D}_{I}^{(kd)} ; \theta_{S}\right) L=I∑LI(DI(kd);θS)
(多任务联合优化, θ S \theta_S θS 为学生模型参数)
3.知识蒸馏算法
3.1 知识

Fig.5 展示了六种知识引出方法,涵盖从直接标注到自生成数据的全流程,通过不同策略(如监督、增强、反馈)将教师模型的知识高效迁移至学生模型。
1. Labeling(标注)
教师模型根据输入 x x x 和指令 I I I 生成输出标签 y y y,直接作为监督信号。 比如:Orca 使用 GPT-4 标注推理过程(Chain-of-Thought),用于训练学生模型的逻辑能力。
D ( l a b ) = { x , y ∣ x ∼ X , y ∼ p T ( y ∣ I ⊕ c ⊕ x ) } \mathcal{D}^{(lab)} = \left\{x, y \mid x \sim \mathcal{X}, y \sim p_{T}(y | I \oplus c \oplus x)\right\} D(lab)={x,y∣x∼X,y∼pT(y∣I⊕c⊕x)}
2. Expansion(扩展)
教师模型通过上下文学习(in-context learning),基于少量示范 c c c 生成更多相似数据。 比如:Self-Instruct 从 175 条指令扩展至 52K 指令数据,用于训练 Alpaca。
D ( e x p ) = { ( x , y ) ∣ x ∼ p T ( x ∣ I ⊕ c ) , y ∼ p T ( y ∣ I ⊕ x ) } \mathcal{D}^{(exp)} = \left\{(x, y) \mid x \sim p_{T}(x | I \oplus c), y \sim p_{T}(y | I \oplus x)\right\} D(exp)={(x,y)∣x∼pT(x∣I⊕c),y∼pT(y∣I⊕x)}
3. Data Curation(数据策展)
利用元信息(如主题、实体)引导教师模型合成高质量数据。 比如:Phi 系列模型通过“教科书级”元信息生成 Python 代码解释,提升学生模型的代码能力。
D ( c u r ) = { ( x , y ) ∣ x ∼ p T ( x ∣ I ⊕ m ) , y ∼ p T ( y ∣ I ⊕ x ) } \mathcal{D}^{(cur)} = \left\{(x, y) \mid x \sim p_{T}(x | I \oplus m), y \sim p_{T}(y | I \oplus x)\right\} D(cur)={(x,y)∣x∼pT(x∣I⊕m),y∼pT(y∣I⊕x)}
4. Feature(特征)
提取教师模型的中间层特征或输出分布(如 logits),作为软标签训练学生模型。 比如:MiniLLM 使用反向 KL 散度对齐教师与学生的输出分布。
D ( f e a t ) = { ( x , y , ϕ f e a t ( x , y ; θ T ) ) ∣ x ∼ X , y ∼ Y } \mathcal{D}^{(feat)} = \left\{\left(x, y, \phi_{feat}(x, y ; \theta_{T})\right) \mid x \sim \mathcal{X}, y \sim \mathcal{Y}\right\} D(feat)={(x,y,ϕfeat(x,y;θT))∣x∼X,y∼Y}
5. Feedback(反馈)
教师模型评估学生输出 y y y,提供偏好、修正或奖励信号。 比如:RLAIF 通过 GPT-4 生成无害性偏好数据,优化学生模型的伦理对齐。
D ( f b ) = { ( x , y , ϕ f b ( x , y ; θ T ) ) ∣ x ∼ X , y ∼ p S ( y ∣ x ) } \mathcal{D}^{(fb)} = \left\{\left(x, y, \phi_{fb}(x, y ; \theta_{T})\right) \mid x \sim \mathcal{X}, y \sim p_{S}(y | x)\right\} D(fb)={(x,y,ϕfb(x,y;θT))∣x∼X,y∼pS(y∣x)}
6. Self-Knowledge(自知识)
学生模型自我生成数据并筛选/优化,实现无外部教师的自改进。 Self-Align 通过教师模型生成详细反馈,迭代优化学生的输出质量。
D ( s k ) = { ( x , y , ϕ s k ( x , y ) ) ∣ x ∼ S , y ∼ p S ( y ∣ I ⊕ x ) } \mathcal{D}^{(sk)} = \left\{\left(x, y, \phi_{sk}(x, y)\right) \mid x \sim \mathcal{S}, y \sim p_{S}(y | I \oplus x)\right\} D(sk)={(x,y,ϕsk(x,y))∣x∼S,y∼pS(y∣I⊕x)}
3.2 蒸馏
3.2.1 监督微调(Supervised Fine-Tuning)
监督微调是知识蒸馏的基础方法,通过最小化交叉熵损失(公式9):
L
S
F
T
=
E
x
∼
X
,
y
∼
p
T
(
y
∣
x
)
[
−
log
p
S
(
y
∣
x
)
]
\mathcal{L}_{SFT} = \mathbb{E}_{x \sim \mathcal{X}, y \sim p_{T}(y | x)} \left[ -\log p_{S}(y | x) \right]
LSFT=Ex∼X,y∼pT(y∣x)[−logpS(y∣x)]
公式的核心是最小化交叉熵损失。 首先,教师输出引导:教师模型
p
T
p_T
pT为输入
x
x
x生成目标输出
y
y
y(如指令响应、对话回复)。 然后,学生模仿学习:学生模型
p
S
p_S
pS 通过最大化生成
y
y
y的概率(即最小化
−
log
p
S
(
y
∣
x
)
-\log p_S(y|x)
−logpS(y∣x) ),学习模仿教师的输出模式。 最后,期望平均:对所有输入
x
x
x 和对应
y
y
y 取平均,确保模型在整体数据分布上优化。 直接将教师的知识(如指令遵循能力)通过监督信号迁移至学生模型,是知识蒸馏的基础方法(如Alpaca、Vicuna的训练)。
为什么SFT公式中的 log p S ( y ∣ x ) \log p_{S}(y | x) logpS(y∣x) 前面没有 y T y_{T} yT?
答案:
- 传统分类场景下的交叉熵损失
在传统的分类问题中,交叉熵损失的公式是:
L
=
−
∑
i
y
i
log
p
i
L = -\sum_{i} y_i \log p_i
L=−i∑yilogpi
这里的
y
i
y_i
yi 代表的是真实标签的 one-hot编码。举例来说,当真实类别是第3类时,
y
=
[
0
,
0
,
1
,
0
]
y = [0, 0, 1, 0]
y=[0,0,1,0],那么损失就仅仅由第3项的
−
log
p
3
-\log p_3
−logp3 来决定。
- 序列生成场景下的交叉熵损失(公式9)
在序列生成任务中,比如语言模型生成文本,每个位置的预测都要单独计算损失,然后取平均值。其公式为:
L
S
F
T
=
E
x
,
y
[
−
log
p
S
(
y
∣
x
)
]
\mathcal{L}_{SFT} = \mathbb{E}_{x, y} \left[ -\log p_S(y | x) \right]
LSFT=Ex,y[−logpS(y∣x)]
此公式可进一步分解为对序列中每个token位置的交叉熵损失求平均:
L
S
F
T
=
1
T
∑
t
=
1
T
−
log
p
S
(
y
t
∣
x
,
y
<
t
)
\mathcal{L}_{SFT} = \frac{1}{T} \sum_{t=1}^T -\log p_S(y_t | x, y_{<t})
LSFT=T1t=1∑T−logpS(yt∣x,y<t)
这里的
y
t
y_t
yt 指的是序列中第
t
t
t个token的真实值,
p
S
(
y
t
∣
x
,
y
<
t
)
p_S(y_t | x, y_{<t})
pS(yt∣x,y<t) 是学生模型在给定输入
x
x
x和历史token
y
<
t
y_{<t}
y<t 的情况下,预测
y
t
y_t
yt 的概率。
- 公式9未显式写出 y y y的缘由
真实标签的隐含作用:在序列生成中, y y y 以token索引的形式存在,而非 one-hot向量。例如,当 y t = 5 y_t = 5 yt=5 时, − log p S ( y t ∣ x , y < t ) -\log p_S(y_t | x, y_{<t}) −logpS(yt∣x,y<t) 直接对应着第5个token的概率的负对数,这和传统交叉熵损失中 y i = 1 y_i = 1 yi=1 时的 − log p i -\log p_i −logpi 是等价的。
计算上的便利性:在实际操作中,我们通常会使用CrossEntropyLoss函数,它会自动处理从token索引到one - hot的映射。所以公式9里虽然没有显式写出
y
y
y的乘法操作,但在计算每个位置的损失时,已经隐含了这一过程。
公式9本质上就是序列生成任务中的交叉熵损失,它通过对每个token位置的 − log p S ( y t ∣ ⋅ ) -\log p_S(y_t | \cdot) −logpS(yt∣⋅) 求平均来实现监督学习。这和传统分类问题的交叉熵损失原理一致,只不过是针对序列生成的特性进行了适配。
3.2.2 散度和相似度(Divergence and Similarity)
Table 1 和Table 2 分别对应知识蒸馏中的散度类型和相似度函数。 散度用于概率分布优化,相似性函数用于特征层级对齐,共同提升知识迁移效果。
A.散度

Table 1 展示了量化教师模型与学生模型概率分布的差异。 其类型分三种:
- 正向KL散度: D ( p ∣ ∣ q ) = ∑ p ( t ) log p ( t ) q ( t ) D(p||q) = \sum p(t) \log \frac{p(t)}{q(t)} D(p∣∣q)=∑p(t)logq(t)p(t),强制学生覆盖教师分布的所有模式。
- 反向KL散度: D ( q ∣ ∣ p ) = ∑ q ( t ) log q ( t ) p ( t ) D(q||p) = \sum q(t) \log \frac{q(t)}{p(t)} D(q∣∣p)=∑q(t)logp(t)q(t),聚焦教师高概率区域,减少低质量生成。
- JS散度: J S ( p , q ) = 1 2 [ D ( p ∣ ∣ m ) + D ( q ∣ ∣ m ) ] JS(p, q) = \frac{1}{2}[D(p||m) + D(q||m)] JS(p,q)=21[D(p∣∣m)+D(q∣∣m)],对称平均前两者,稳定性更高。
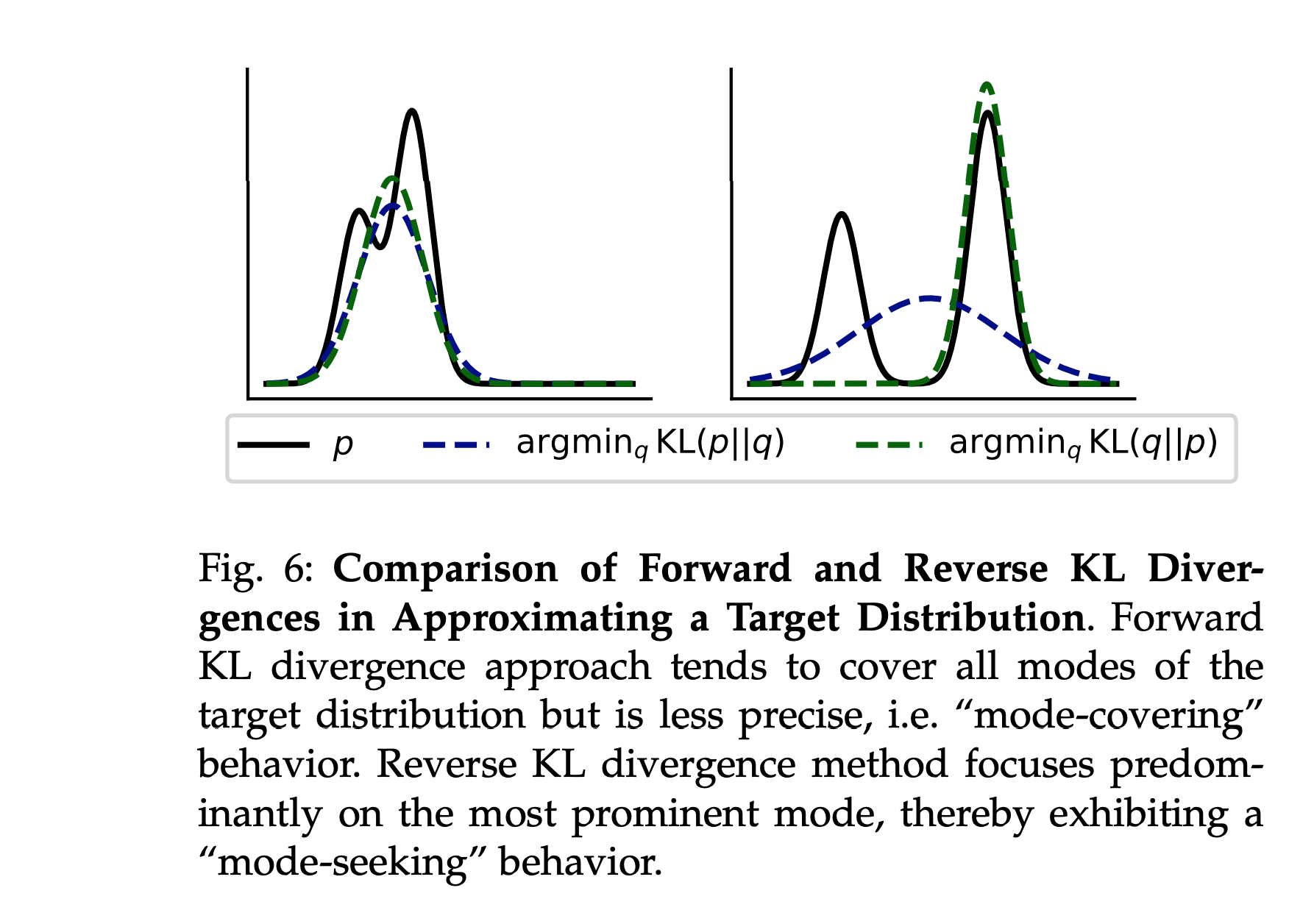
Figure 6 比较了 前向KL散度 和 反向KL散度 在逼近目标分布时的行为差异。
- 黑色曲线(目标分布) :表示教师模型 p T p_T pT (也就是图中的 p p p )的真实概率分布,即知识蒸馏的目标。 作为基准,用于对比学生模型的逼近效果。
- 蓝色曲线(前向KL散度) : 对应公式: D K L ( p T ∣ ∣ q S ) D_{KL}(p_T || q_S) DKL(pT∣∣qS) ( q S q_S qS 也就是图中的 q q q )。学生模型 q S q_S qS 的分布被迫覆盖教师模型的所有模式(包括次要峰值和低概率区域)。 学生模型试图全面覆盖教师模型的所有可能输出,但可能因过度泛化导致低质量生成(如蓝色曲线在低概率区域的冗余覆盖)。
- 绿色曲线(反向KL散度) :对应公式: D K L ( q S ∣ ∣ p T ) D_{KL}(q_S || p_T) DKL(qS∣∣pT) 。学生模型 p S p_S pS 的分布仅聚焦于教师模型的主要模式(高概率区域)。 学生模型优先匹配教师模型的主要模式,减少低概率区域的关注,提升生成准确性,但可能限制多样性(如绿色曲线仅覆盖主峰)。
B.相似度

Table 2 是对齐教师与学生模型的特征表示或输出。 方法也包括三种:
- L2范数: ∥ Φ T ( f T ) − Φ S ( f S ) ∥ 2 \| \Phi_T(f_T) - \Phi_S(f_S) \|_2 ∥ΦT(fT)−ΦS(fS)∥2,计算特征向量的欧氏距离。
- 交叉熵损失: − ∑ Φ T ( f T ) log Φ S ( f S ) -\sum \Phi_T(f_T) \log \Phi_S(f_S) −∑ΦT(fT)logΦS(fS),直接匹配输出概率。
- 最大均值差异(MMD):通过核函数比较特征分布,适用于深层特征对齐。
3.2.3 强化学习(Reinforcement Learning)
通过教师反馈训练奖励模型,引导学生策略优化,实现偏好对齐与能力提升。
-
教师偏好 -> 奖励模型训练(公式12)
学习区分教师偏好的输出对( y w y_w yw 为“赢”, y l y_l yl 为“输”)。比如,RLAIF 使用 GPT-4 生成无害性偏好数据,训练奖励模型评估学生输出。
L R M = − E ( x , y w , y l ) ∼ D ( f d ) [ log σ ( r ϕ ( x , y w ) − r ϕ ( x , y l ) ) ] \mathcal{L}_{RM} = -\mathbb{E}_{\left(x, y_{w}, y_{l}\right) \sim \mathcal{D}^{(fd)}}\left[\log \sigma\left(r_{\phi}(x, y_{w}) - r_{\phi}(x, y_{l})\right)\right] LRM=−E(x,yw,yl)∼D(fd)[logσ(rϕ(x,yw)−rϕ(x,yl))]
公式的目标是,训练奖励模型 r ϕ r_{\phi} rϕ 区分教师偏好的输出对。 输入:教师标注的偏好数据 ( x , y w , y l ) (x, y_w, y_l) (x,yw,yl) ,其中 y w ≻ y l y_w \succ y_l yw≻yl 。 损失函数:通过逻辑函数 σ \sigma σ 将奖励差值转化为概率,最大化正确排序的对数似然。 -
学生能力 -> 策略优化(公式13)
最大化奖励 r ϕ r_{\phi} rϕ ,同时通过 KL 散度约束避免偏离参考策略(如 SFT 预训练模型)。 比如,WizardMath 通过 RL 优化提升数学推理能力,结合 Evol-Instruct 生成复杂指令。
max π θ E [ r ϕ ( x , y ) ] − β D K L [ π θ ( y ∣ x ) ∥ π ref ( y ∣ x ) ] \max_{\pi_{\theta}} \mathbb{E}\left[r_{\phi}(x, y)\right] - \beta D_{KL}\left[\pi_{\theta}(y|x) \| \pi_{\text{ref}}(y|x)\right] πθmaxE[rϕ(x,y)]−βDKL[πθ(y∣x)∥πref(y∣x)]
优化学生策略 π θ \pi_{\theta} πθ ,平衡奖励最大化与稳定性。 奖励项:最大化奖励模型 r ϕ r_{\phi} rϕ 的期望分数(如回答质量)。 约束项:通过 KL 散度 D K L D_{KL} DKL 限制新策略 π θ \pi_{\theta} πθ 与参考策略 π ref \pi_{\text{ref}} πref (如 SFT 预训练模型)的偏离程度,防止性能骤降。 参数: β \beta β 控制约束强度,避免过度探索。
基于上面强化学习(奖励模型训练+策略优化)的典型代表方法有两个:RLAIF:用 AI 反馈替代人类标注,优化无害性与帮助性。DPO(Direct Preference Optimization):简化 RL 流程,直接利用偏好数据训练策略(如 Zephyr)。
公式13中的 π ref ( y ∣ x ) \pi_{\text{ref}}(y|x) πref(y∣x) 是否为教师模型的输出分布?
答案:否。
- πref(y∣x) 表示学生模型的初始策略分布,通常是经过监督微调(SFT)后的模型输出分布(如Alpaca、Vicuna的SFT阶段),而非教师模型(如GPT-4)的分布。
通过KL散度项 D K L [ π θ ( y ∣ x ) ∥ π ref ( y ∣ x ) ] D_{KL}\left[\pi_{\theta}(y|x) \| \pi_{\text{ref}}(y|x)\right] DKL[πθ(y∣x)∥πref(y∣x)] 约束学生模型在强化学习过程中不要过度偏离初始策略,防止性能骤降(如训练早期探索导致不稳定)。比如,在WizardMath中,πref是SFT阶段训练后的模型,用于约束后续RL优化的探索范围。
教师模型的输出分布 p T ( y ∣ x ) p_T(y|x) pT(y∣x) 是知识蒸馏的目标,而πref是学生模型自身的初始分布,用于稳定性控制。
3.2.4 排名优化(Ranking Optimization):DPO、RRHF、PRO
直接利用偏好数据优化模型,无需显式奖励模型,提升训练稳定性与效率。
-
Direct Preference Optimization (DPO)(公式14)
L D P O = E ( x , y w , y l ) ∼ D ( i ) [ log σ ( β log π θ ( y w ∣ x ) π ref ( y w ∣ x ) − β log π θ ( y l ∣ x ) π ref ( y l ∣ x ) ) ] \mathcal{L}_{DPO} = \mathbb{E}_{\left(x, y_{w}, y_{l}\right) \sim \mathcal{D}^{(i)}}\left[\log \sigma\left(\beta \log \frac{\pi_{\theta}(y_{w}|x)}{\pi_{\text{ref}}(y_{w}|x)} - \beta \log \frac{\pi_{\theta}(y_{l}|x)}{\pi_{\text{ref}}(y_{l}|x)}\right)\right] LDPO=E(x,yw,yl)∼D(i)[logσ(βlogπref(yw∣x)πθ(yw∣x)−βlogπref(yl∣x)πθ(yl∣x))]
公式目标是,最大化学生模型对教师偏好对( y w ≻ y l y_w \succ y_l yw≻yl )的排序概率。 具体是通过逻辑函数 σ \sigma σ 将对数概率比转化为置信度, β \beta β 控制优化强度, π ref \pi_{\text{ref}} πref 为参考策略(如SFT模型),防止过度偏离初始能力。 -
Rank Responses to Align Human Feedback (RRHF)
L R R H F = ∑ r i < r j max ( 0 , p i − p j ) \mathcal{L}_{RRHF} = \sum_{r_i < r_j} \max\left(0, p_i - p_j\right) LRRHF=ri<rj∑max(0,pi−pj)
公式目标是,最小化学生模型生成低偏好响应的概率,其中 r i r_i ri 为教师评分, p i p_i pi 为学生生成概率。 -
Preference Ranking Optimization (PRO)
L P R O = − ∑ k = 1 n − 1 log exp ( p k ) ∑ i = k n exp ( p i ) \mathcal{L}_{PRO} = -\sum_{k=1}^{n-1} \log \frac{\exp(p_k)}{\sum_{i=k}^{n} \exp(p_i)} LPRO=−k=1∑n−1log∑i=knexp(pi)exp(pk)
公式目标是,直接优化多响应排序,逐步提升偏好最高响应的概率。
排名优化相比RL方法,计算成本更低(无需采样),稳定性更高。 通过直接比较偏好对,优化学生模型的输出分布,在减少计算开销的同时实现偏好对齐(如Zephyr的DPO方法)。
4 蒸馏技能(SKILL DISTILLATION)
4.1 (论文)方法总结

Table 3 是知识蒸馏的(论文)方法总结。归纳了通过数据(如指令、对话、多模态)和训练方法(SFT、RL、数据增强),将复杂技能(如对齐、工具使用、多模态)蒸馏到开源模型的核心框架,附典型模型示例(如Alpaca、LLaVA)。 横向:按技能领域(如对齐、多模态)划分,每个领域包含具体能力(如偏好优化、图文理解)。纵向:每类能力对应方法(如SFT、DA)和模型案例(如Alpaca擅长指令,LLaVA擅长图文)。
4.2 核心技能分类
| 技能领域 | 子技能/目标 | 方法/数据 | 典型模型示例 |
|---|---|---|---|
| 上下文遵循 | 理解指令、多轮对话、检索增强(RAG) | SFT(监督微调)、对话数据(如ShareGPT) | Alpaca、WizardLM、SAIL |
| 对齐 | 推理思维、用户偏好、价值观 | CoT(思维链)、RLAIF/DPO优化、原则数据 | Orca、Zephyr、Self-Align |
| 智能体能力 | 工具使用、任务规划 | API调用数据、轨迹/规划数据 | Toolformer、FireAct、AUTOACT |
| NLP任务专业化 | 代码生成、文本评估 | 指令数据、教师评分标准 | Code Alpaca、PandaLM、Phi-1 |
| 多模态 | 视觉-语言对齐 | 图文对话数据(如GPT-4生成) | LLaVA、SVIT |
上述关键方法可以总结为3点: 监督微调(SFT):直接模仿教师模型输出(如Vicuna学对话,Code Alpaca学代码)。数据增强(DA):生成扩展数据(如Self-Instruct造指令,Evol-Instruct生成复杂任务)。反馈优化(RL/RO):用偏好数据对齐(如WizardMath的RLAIF,Zephyr的DPO排名优化)。
5 特殊领域的垂直蒸馏
该部分聚焦于知识蒸馏在特定领域的应用,通过定制化训练提升模型在专业场景的性能。领域知识的深度整合、数据隐私保护、实时性要求及模型泛化能力平衡。通过教师模型生成领域数据与针对性微调,显著提升模型在垂直场景的实用性。具体包括:

-
法律(Law)
- 通过持续预训练法律语料库(如中国司法考试数据)和教师模型(如ChatGPT)生成案例问答数据,增强模型对法律术语、条文的理解与应用能力(如LawyerLLaMA、LawGPT)。
-
医疗与健康(Medical & Healthcare)
- 结合真实医患对话数据与教师模型(如GPT-4)生成的医学指令数据,训练模型处理诊断、药物推荐等任务(如HuatuoGPT、MedAlpaca)。
-
金融(Finance)
- 利用教师模型生成金融领域指令数据,训练模型进行市场趋势分析、风险评估和个性化服务(如XuanYuan)。
-
科学(Science)
- 数学领域通过强化学习与链式思维数据提升推理能力(如WizardMath);航天、化学、生物等子领域通过多模态数据与领域知识蒸馏优化专业任务(如G-LLaVA、Prot2Text)。
-
其他领域(Miscellaneous)
- 教育(EduChat)、IT运维(Owl)等领域通过领域特定指令数据和微调增强模型专业性。
6 挑战
当前知识蒸馏研究面临以下关键挑战:
-
数据选择优化 :如何自动筛选高质量蒸馏数据并确定最小数据量(需平衡质量与效率)。
-
轻量级蒸馏方法 :探索更高效的模型压缩(量化、剪枝)和微调技术,降低资源消耗。
-
多教师知识整合 :研究如何融合多个教师模型的知识,提升学生模型的综合能力。
-
深层知识利用 :挖掘教师模型的反馈、特征等内在知识,超越简单的输出模仿。
-
灾难性遗忘问题 :在持续训练中保持模型原有能力,避免任务间知识冲突。
-
可信蒸馏机制 :确保模型在安全性、公平性、鲁棒性等伦理维度的可靠性。
-
弱到强蒸馏 :利用弱监督信号(如小模型输出)增强强模型的泛化能力。
-
自主对齐能力 :推动模型通过自我反馈提升对齐效果,减少对外部偏好数据的依赖。
引用
[1]. “Knowledge distillation: A survey,” International Journal of Computer Vision, vol. 129, pp. 1789–1819, 2021.
[2]. “MiniLLM: Knowledge distillation of large language models,” in The Twelfth International Conference on Learning Representations, 2024.’
[3]. “Self-rewarding language models,” 2024.
[4]. “Stanford alpaca: An instruction-following llama model,”https://github.com/tatsu-lab/stanford alpaca, 2023.