HTTP 缓存的工作原理
缓存是解决http1.1当中的性能问题主要手段。缓存可能存在于客户端浏览器上,也可以存在服务器上面,当使用过期缓存可能给用户展示的是错误的信息而导致一些bug。
HTTP 缓存:为当前请求复用前请求的响应
•
目标:减少时延;降低带宽消耗(可能压根没有发出任何请求,所以整个吞吐量下降了)
•
可选而又必要
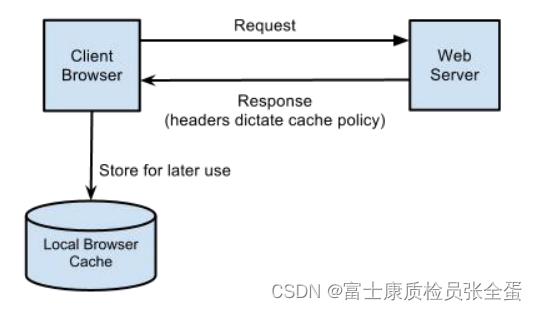
缓存其实是在时间维度上面的缓存,第一个请求缓存了,那么为后续的请求就可以使用第一个请求缓存住的响应。
request发出请求到web server发出的响应,其中这个响应当中可以得到一些信息,告诉我们这个响应是可以被缓存的,接下来缓存到本地的浏览器的缓存当中。
后面想要再次发起请求的时候,会先去判断浏览器当中的缓存是否过期了,因为在响应当中明确的指出js css只能存在几天,几个小时,之后就必须到服务器获取,如果没有过期,那么就直接使用本地的缓存。
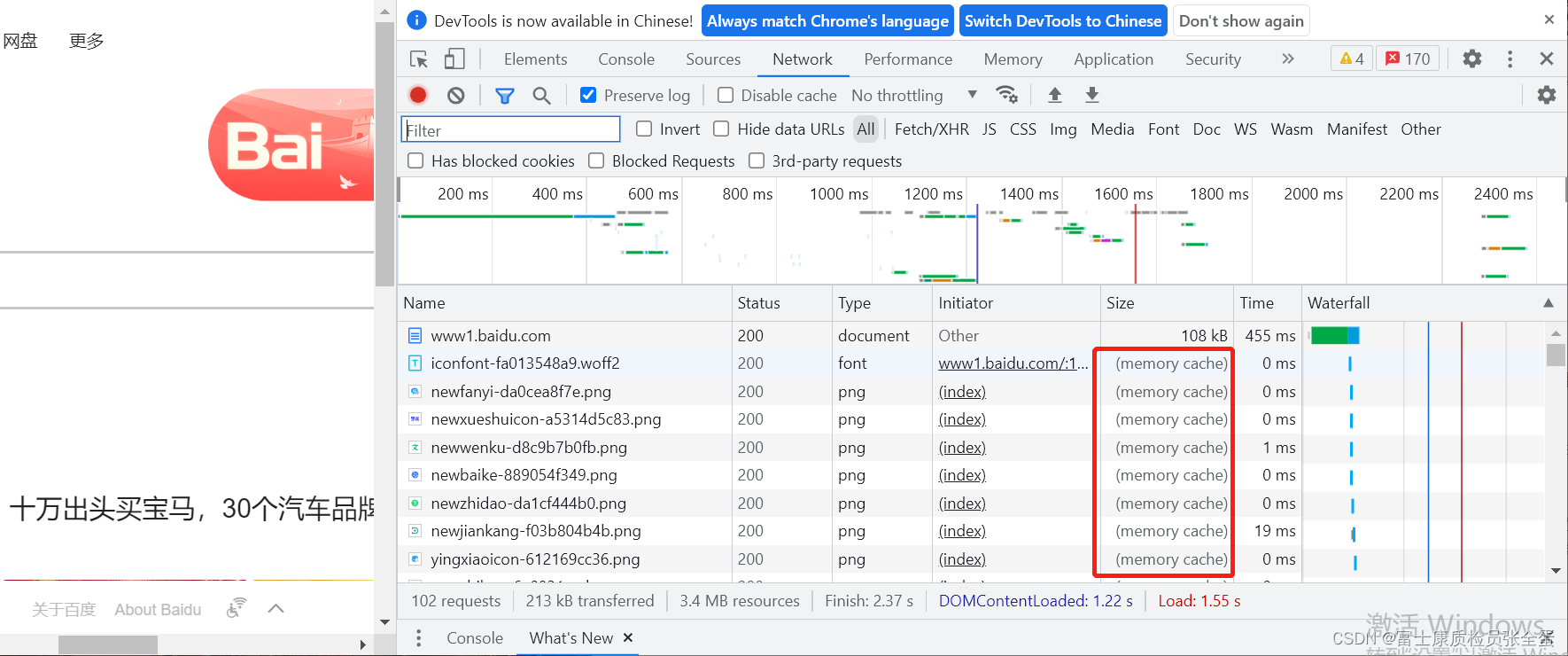
jss css文件都是使用的缓存。因为可以从size这里看到memory cache表示从缓存当中读出来的,也就是这个文件压根没有向服务器端发送(所以这些请求压根不会发送,也就是压根没有网络请求,没有网络带宽,这样用户体验也会好一些)。
如果缓存过期,则继续从服务器验证
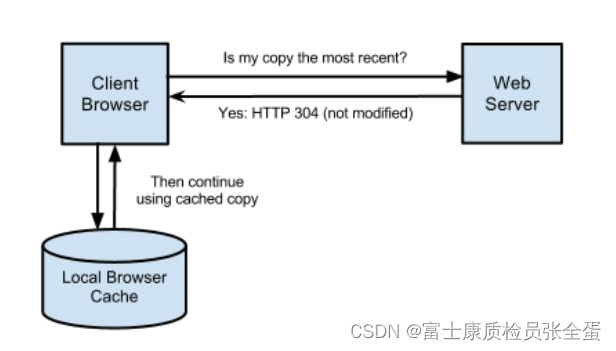
首先去看到缓存是过期了,但是缓存得有一个标签,这个标签告诉服务器再返回304你可以继续使用,那么直接可以和用户来展示。
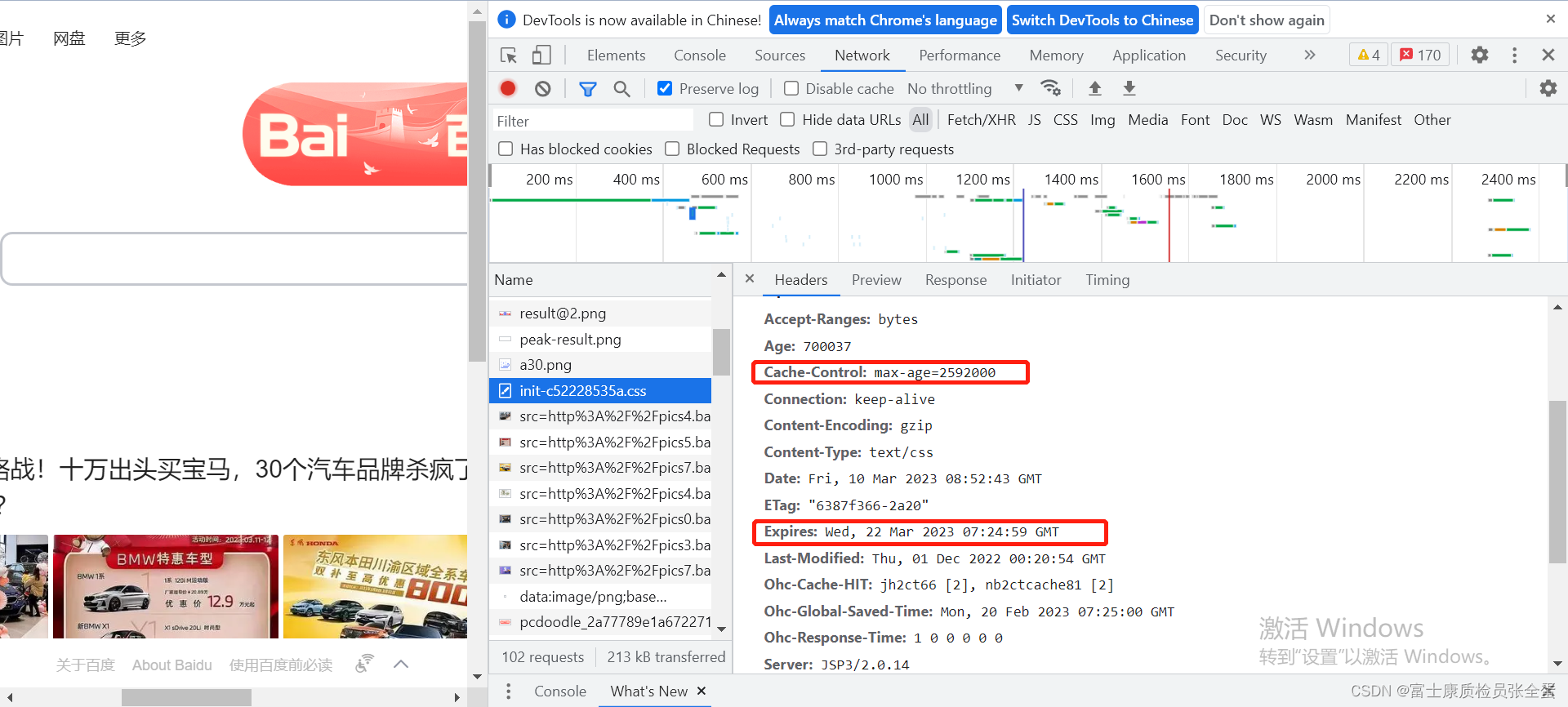
百度首页告诉我们过期时间还是挺久的,可以从max-age和expire这里看到过期时间还是很久的,浏览器要想认为它过期是比较难的。
curl 'http://ss.bdimg.com/static/superman/css/recommand/init-c52228535a.css' \
-H 'Referer: http://www1.baidu.com/' \
-H 'User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/110.0.0.0 Safari/537.36' \
--compressed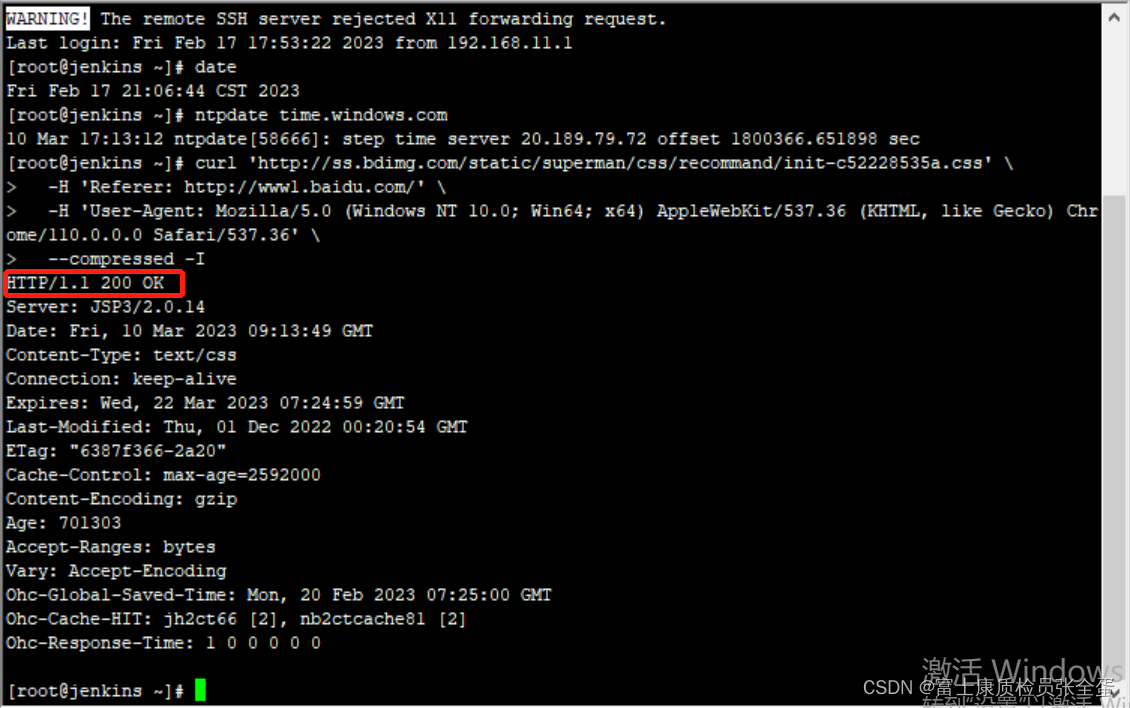
如果浏览器中有缓存,但是过期了会怎么样?那么浏览器会添加一些相应的头部
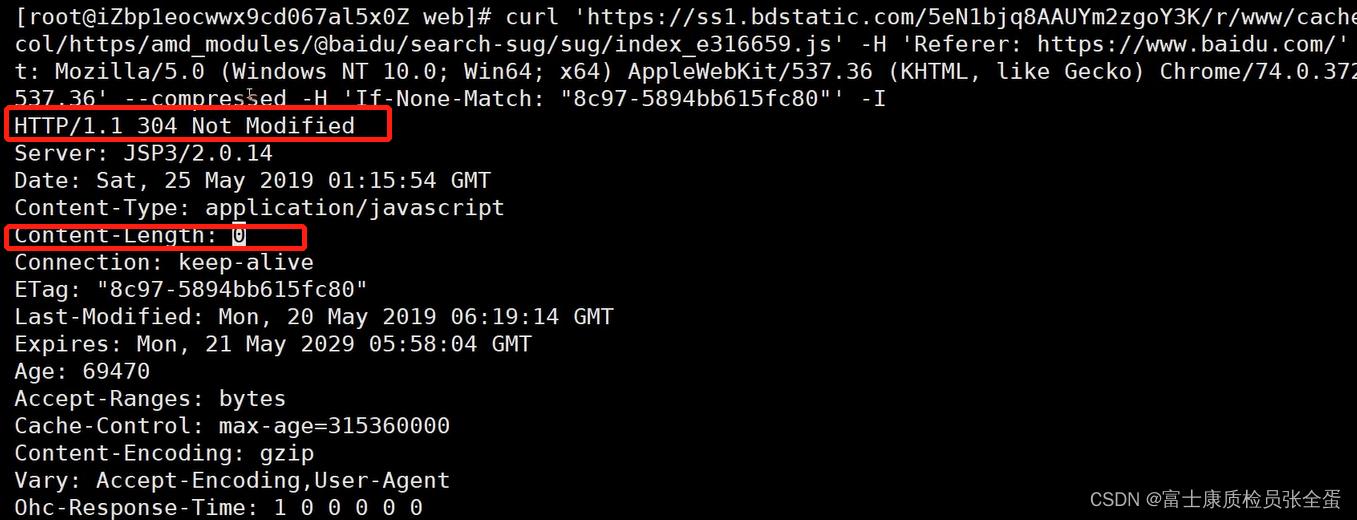
curl 'http://ss.bdimg.com/static/superman/css/recommand/init-c52228535a.css' \
-H 'Referer: http://www1.baidu.com/' \
-H 'User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/110.0.0.0 Safari/537.36' \
--compressed -H 'if-None-Match: "6387f366-2a20"' -Ietag就是响应的一个指纹,这个时候服务器就知道缓存了一个响应,服务器端会保存这个指纹,比较是Ok的,它就会返回304,好处就是content-length为0,这样就节约了大量的带宽。
这个时候浏览器客户端就知道了,直接使用缓存中的过期响应就行了。
私有缓存与共享缓存
- 私有缓存:仅供一个用户使用的缓存,通常只存在于如浏览器这样的客户端上
比如浏览器,那么只能提供给一个用户使用。
- 共享缓存:可以供多个用户的缓存,存在于网络中负责转发消息的代理服务器(对热点资源常使用共享缓存,以减轻源服务器的压力,并提升网络效率)
共享缓存都是放在服务器上面的,他可以供很多用户共同使用,比如热点视频,js这样的资源
,正向代理和反向代理都可以使用到缓存。
• Authentication 响应不可被代理服务器缓存(验证类型的响应是不能被代理服务器缓存的)
•
正向代理
•
反向代理