Python 高级编程(文件操作)
文件:存储在某种长期存储设备上的数据!!包括(硬板 u 盘 移动硬盘 光盘) 计算机中临时的数据: 存储在内存中,一旦操作结束,内存中的空间就会被释放
文件(特指普通文本)的基本操作包括:
1.打开文件 2.读写文件 读文件: 将文件中的内容存储在内存中 写文件: 将内存的数据写入文件中 文件存储的位置是磁盘 磁盘是长期存储数据 内存是短期存储 当你的程序运行完成后内存中的内容就会被释放 3.关闭文件 在python中操作文件通常使用4个函数(函数) 1.open 打开文件 返回文件操作的对象 2.read 读取文件,将文件中的内容读取到内存中 3.write 写文件 将指定的内容写入到磁盘中 4.close 关闭文件
文件指针 -- 光标 标记了从哪个位置开始读取数据 首次打开文件的时候,并没有指定它的模式,文件指针指向文本的开始位置
下面这些操作只是针对文本文件就是 .txt 格式
1. 打开文件:
str = open(r'D:\500px\test\test1.txt','r')
2.读取文件
str2 = str.read() print(str2)
3.关闭文件
str.close
完整项目
#根据文件读写案例,进行文件复制
f = open('makdir.txt','r') #打开文件而且是只读模式
f2 = open('new_file_copy','w') #打开文件而且只是写入模式
content = f.read() #读取makdir.txt 文件中的内容
f2.write(content) #将从makdir.txt文件中读取到的内容写入new_file_copy 文件中
f.close() #关闭makdir.txt
f2.close() #关闭new_file_copy
上面是一些小的文本内容,如果是一些比较大的文件,我们在读取的时候用到 readlines,逐行读,逐行写,而不是简单的一次性读完写入
# 大文件操作 对于大文件我进行的是逐行的读写操作
f3 = open('makdir.txt','r')
f4 = open('big_file.txt','w')
while True: # 这是一个死循环只能使用break 方可跳出循环
content = f3.readline() # 逐行读取文件
if not content: # 如果 content 为空
break #跳出 while 循环
f4.write(content) # 否则将content写入新的f3中
f3.close()
f4.close()
读写bytes类型数据(在计算机的底层都是以二进制的形式存储文件内容)
因为视频图片的存储形式都是bytes 流
#rb wb ab 是对字节的操作 rb : 以二进制 (字节) 的格式打开一个文件用于只读,文件指针放在开头,如果文件不存在则会抛出异常 wb : 打开一个文件用于写入二进制(字节) ,如果该文件已经存在,会先清空或者覆盖 然后将文件放在文件开头,如果不存在,就会创建该文件 ab :对一个文件用于二进制的形式进行追加,如果该文件存在,文件指针则会指向原来文本内容的末尾
以下只针对二进制数据
1.读模式
f1 = open(r'C:\Users\HP\Desktop\爬虫.png','rb')
2.写模式
f1 = open(r'C:\Users\HP\Desktop\爬虫1.png','wb')
3.追加模式
f1 = open(r'C:\Users\HP\Desktop\爬虫1.png','ab')
需要注意的是,在写入模式下,如果文件存在则会清空文件中的内容,如果不存在则会创建一个文件。
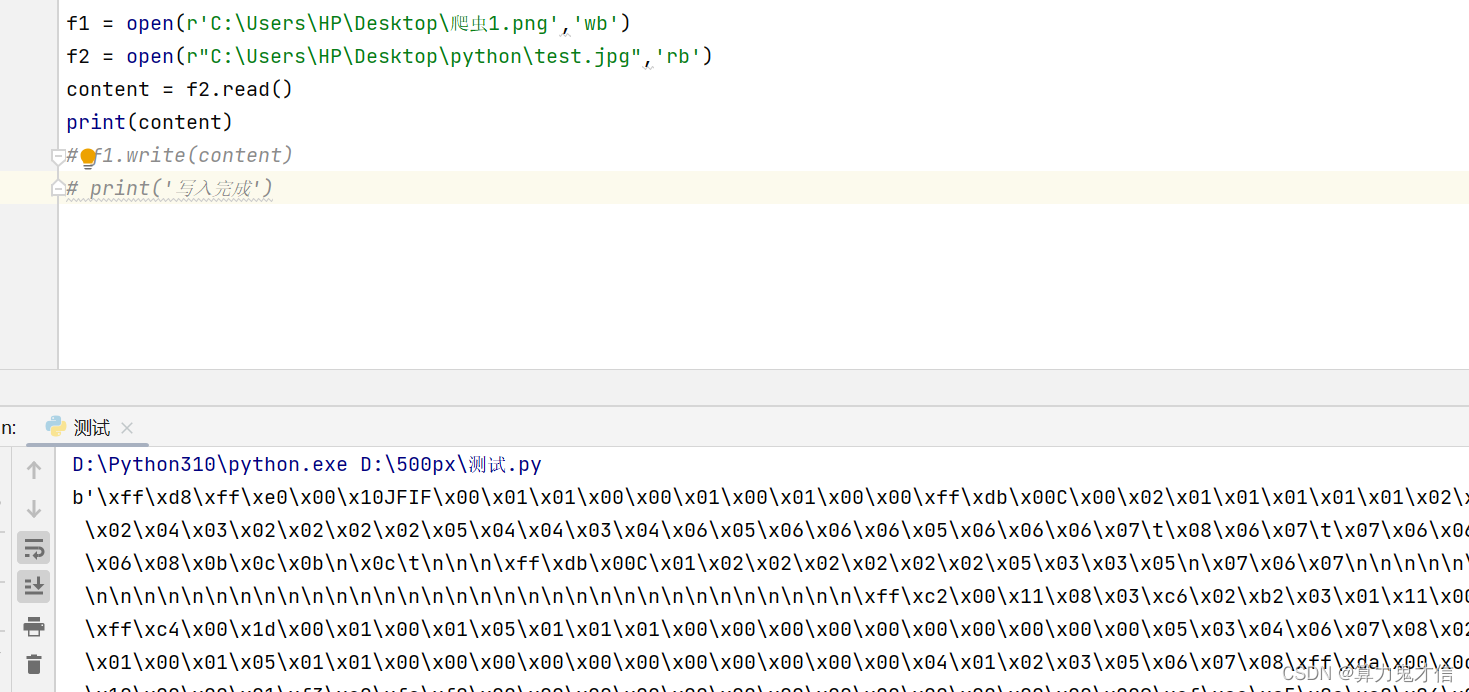
f1 = open(r'C:\Users\HP\Desktop\爬虫1.png','wb') #打开文件 写模式 f2 = open(r"C:\Users\HP\Desktop\python\test.jpg",'rb') #打开文件 读模式 content = f2.read() #读取test.jpg 中的字节流 f1.write(content) #将从test.jpg 中读取到的字节流写入到爬虫1.png中 f1.close() f2.close() print('写入完成') # 提示操作完成
爬虫1.png 本来是存在的 ,我对他做了写操作
经过 将test.jpg 字节流写入到 爬虫1.png 后 照片发生了变化,这恰好证实了,如果存在这么一个照片则会删除它,从开头写入图片的字节流

我这里说的字节流是指图片在磁盘中中的保存形式 ,每一张图片是由若干个以b开头的字节来表示我对图片文件做读写操作,其实就是对这一些byte数据做读写 比如:
文本和字节之间的转化
encode 编码 将字符串转换成 字节
decode 解码 将字节转换成 字符串
f = open('./python进阶/mydata.text','r')
content = f.read().encode() #我对读到的str做了编码转换成了字节
#对它进行读取,才能进行转码操作
print(content)
print(type(content))
f_f = content.decode() #我将转换的字节有通过解码还原回了str
# .encode('utf-8')
print(f_f)
print(type(f_f))
谨记:
r rb
w wb
a ab
统一来说,r和rb都是读取模式,如果文件不存在则会抛出错误,
w 和 wb 都是写入模式,如果文件存在,则会清空,文件内原有的内容,如果不存在,则会创建一个新的文件
a 和 ab都是追加模式,如果文件存在,文件的指针则会指向原始文件中内容的末尾,你新追加的内容的开头则会接续原文件内容的末尾,如果文件不存在,则会创建一个新的文件、
加 b 和 不加 b 的原因是 加了b(rb,wb....),是用来存储文件形式是bytes(比如图片 视频 音频),不加b(r,b..)是用于处理文本内容的
关于字节 和二进制的关系,我想赘叙几点:
一个字节(bytes ) = 8 个二进制 (bit) 字节就是 kb 中的 b 8个0 或者1 作为一个字节 在ANSI 编码方式下 一个英文(包括英文特殊符号)占用一个字节 、 中文(包含中文特殊字符号) 占用2 个字节 在 unicode 编码方式下 一个英文和中文 或者英文特殊符号和中文特殊符号 占用2个字节 在utf-8 编码格式下 一个英文符号占用一个字节, 中文占用3个字节