每日学术速递4.6
CV - 计算机视觉 | ML - 机器学习 | RL - 强化学习 | NLP 自然语言处理
Subjects: cs.CV
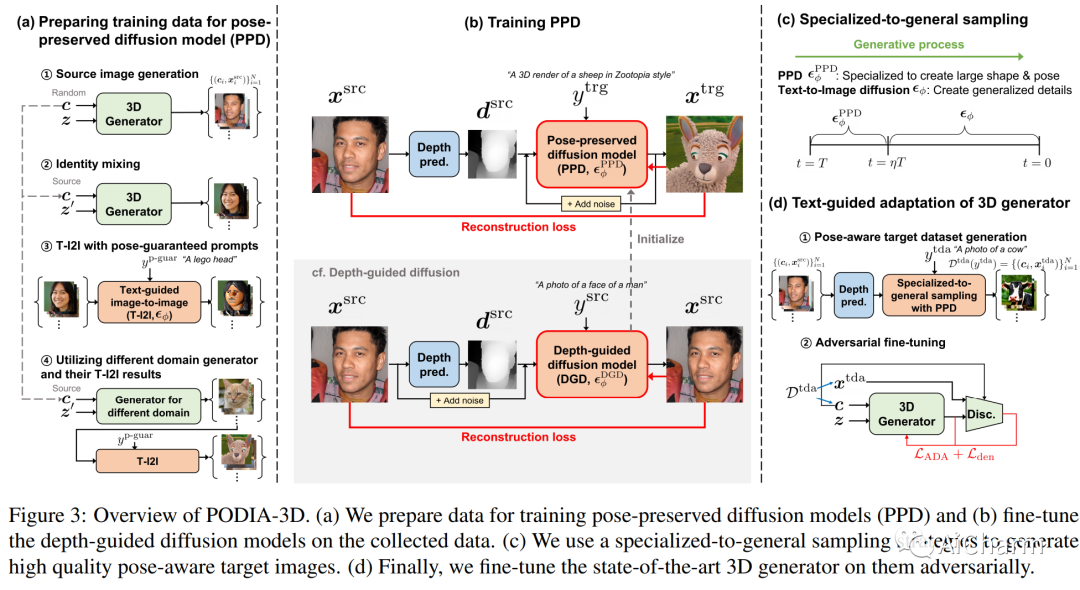
1.PODIA-3D: Domain Adaptation of 3D Generative Model Across Large Domain Gap Using Pose-Preserved Text-to-Image Diffusion

标题:PODIA-3D:使用姿势保持文本到图像扩散的 3D 生成模型跨大域间隙的域自适应
作者:Gwanghyun Kim, Ji Ha Jang, Se Young Chun
文章链接:https://arxiv.org/abs/2304.01900
项目代码:https://gwang-kim.github.io/podia_3d/

摘要:
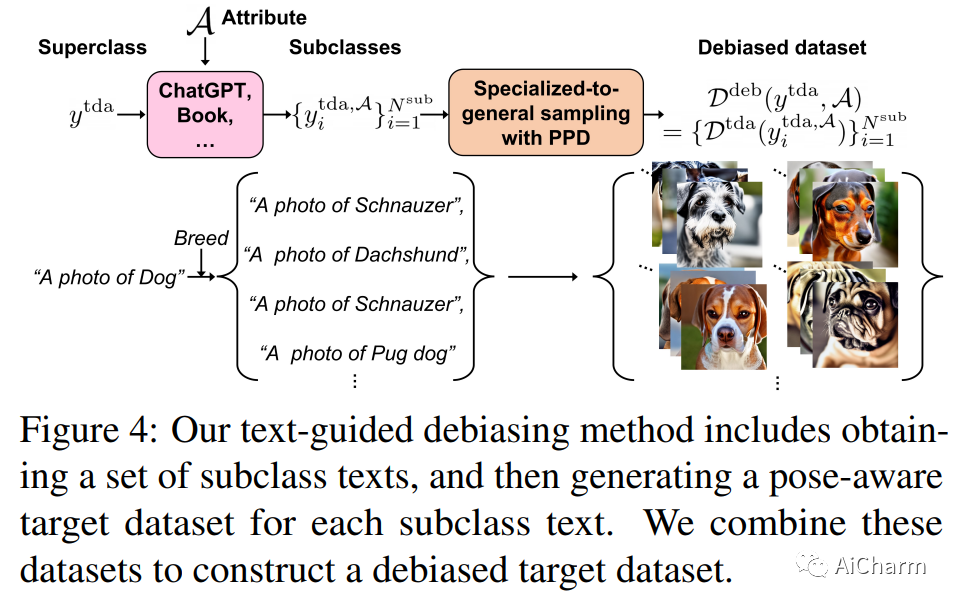
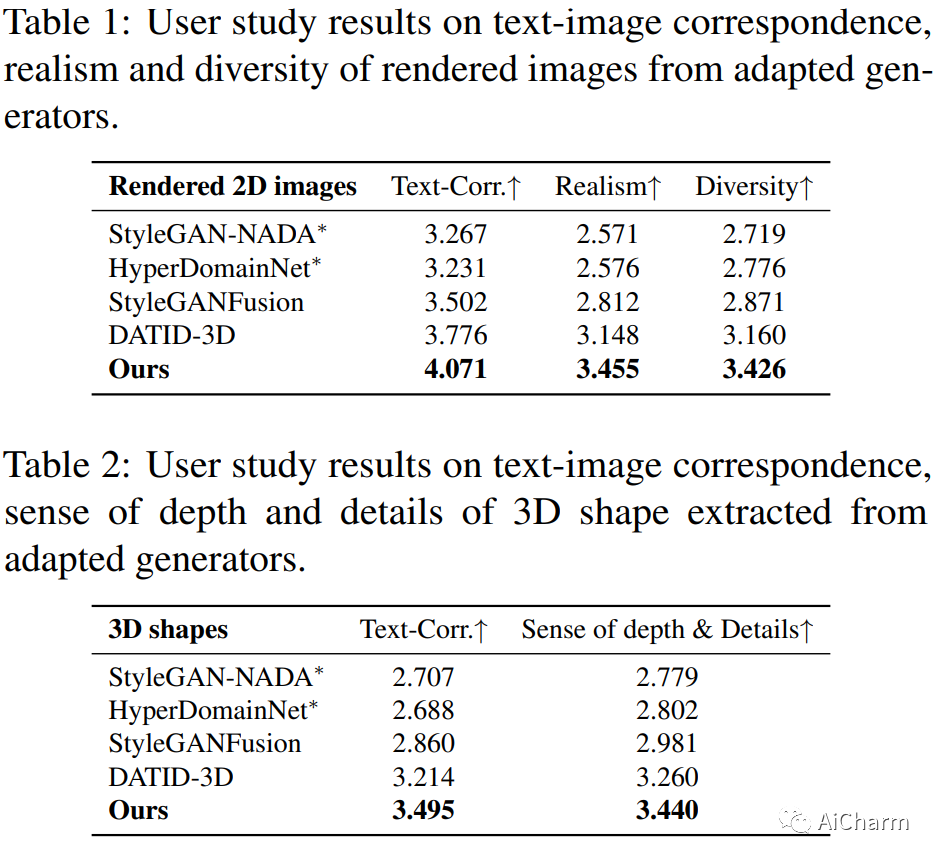
最近,3D 生成模型取得了重大进展,但跨不同领域训练这些模型具有挑战性,需要大量训练数据和姿势分布知识。文本引导域适应方法允许生成器使用文本提示适应目标域,从而避免组装大量数据的需要。最近,DATID-3D 在文本引导域中呈现出令人印象深刻的样本质量,通过利用文本到图像的扩散来保留文本的多样性。然而,由于当前文本到图像扩散模型中存在以下问题,使 3D 生成器适应与源域存在显着域差距的域仍然具有挑战性:1) 基于扩散的翻译中的形状-姿势权衡,2) 姿势偏差,以及 3) 目标域中的实例偏差,导致生成的样本中的 3D 形状较差、文本-图像对应度低和域内多样性低。为了解决这些问题,我们提出了一种名为 PODIA-3D 的新型管道,它使用基于姿势保留的文本到图像扩散的域适应 3D 生成模型。我们构建了一个保留姿势的文本到图像扩散模型,该模型允许对显着的域变化使用极高级别的噪声。我们还提出了专门到一般的抽样策略,以改善生成样本的细节。此外,为了克服实例偏差,我们引入了一种文本引导的去偏差方法,可以提高域内多样性。因此,我们的方法成功地适应了显着域差距的 3D 生成器。我们的定性结果和用户研究表明,我们的方法在文本-图像对应、真实感、渲染图像的多样性以及生成样本中 3D 形状的深度感方面优于现有的 3D 文本引导域自适应方法
2.Self-Refine: Iterative Refinement with Self-Feedback

标题:自我完善:通过自我反馈进行迭代完善
作者:Aman Madaan, Niket Tandon, Prakhar Gupta, Skyler Hallinan, Luyu Gao, Sarah Wiegreffe,
文章链接:https://arxiv.org/abs/2303.17651
项目代码:https://selfrefine.info/
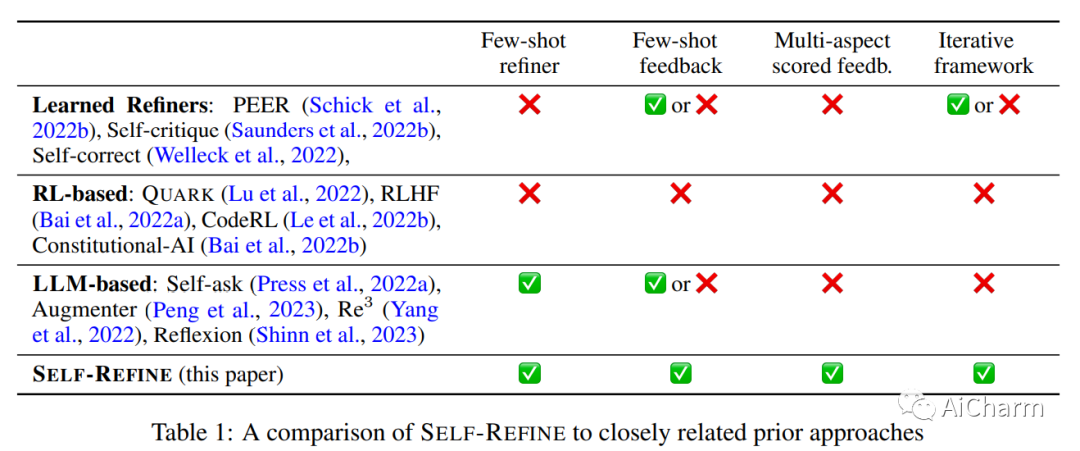
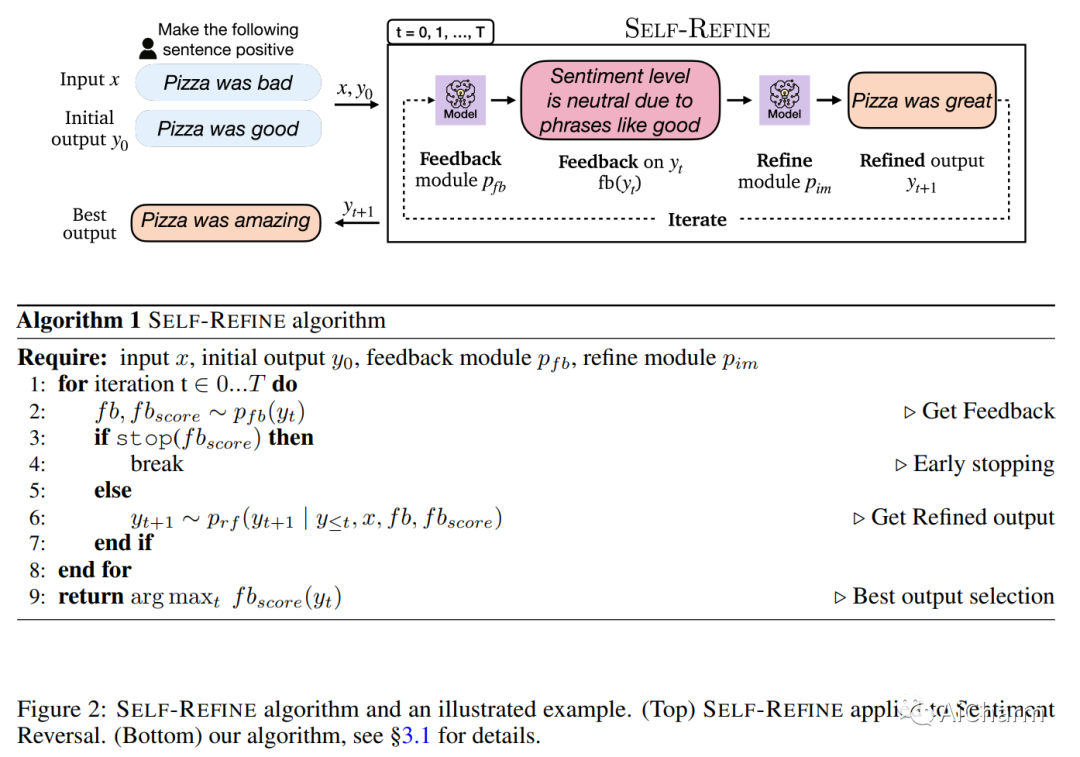

摘要:
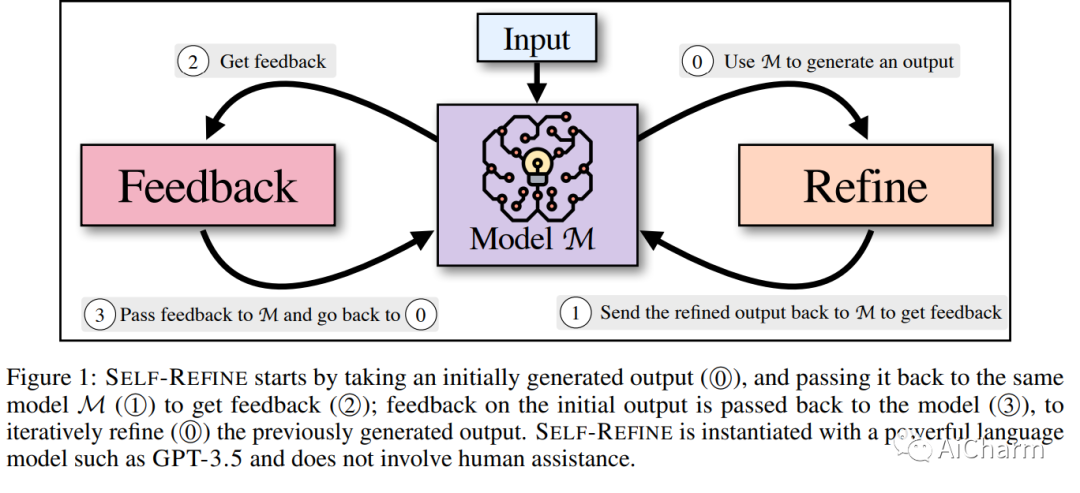
与人一样,LLM 并不总是在第一次尝试时就为给定的生成问题生成最佳文本(例如,摘要、答案、解释)。正如人们随后改进他们的文本一样,我们引入了 SELF-REFINE,这是一个通过迭代反馈和改进类似地改进 LLM 初始输出的框架。主要思想是使用 LLM 生成输出,然后允许同一模型为其自身的输出提供多方面的反馈;最后,同一模型根据自己的反馈改进其先前生成的输出。与早期的工作不同,我们的迭代优化框架不需要监督训练数据或强化学习,并且适用于单个 LLM。我们试验了 7 项不同的任务,从评论重写到数学推理,证明我们的方法优于直接生成。在所有任务中,使用 SELF-REFINE 生成的输出比直接使用 GPT-3.5 和 GPT-4 生成的输出更受人类和自动化指标的青睐,跨任务平均绝对提高 20%。

标题:LLM-Adapters:用于大型语言模型参数高效微调的适配器系列
作者:Zhiqiang Hu, Yihuai Lan, Lei Wang, Wanyu Xu, Ee-Peng Lim, Roy Ka-Wei Lee, Lidong Bing, Soujanya Poria
文章链接:https://arxiv.org/abs/2304.01933
项目代码:https://github.com/AGI-Edgerunners/LLM-Adapters
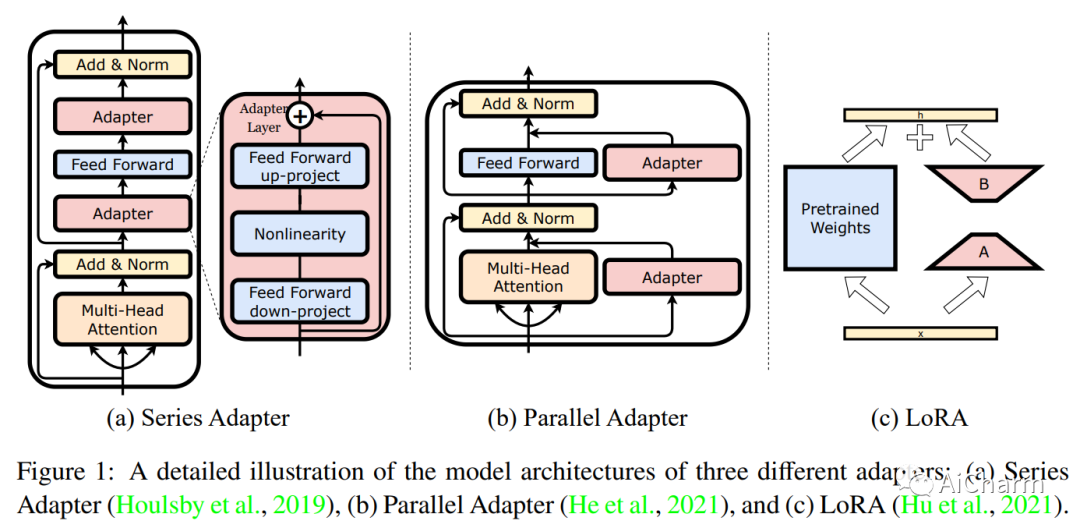

摘要:
大型语言模型 (LLM)(如 GPT-3 和 ChatGPT)的成功导致开发了许多具有成本效益且易于访问的替代方案,这些替代方案是通过使用特定于任务的数据(例如,ChatDoctor)微调开放访问 LLM 创建的) 或指令数据(例如,Alpaca)。在各种微调方法中,基于适配器的参数高效微调(PEFT)无疑是最吸引人的话题之一,因为它只需要微调几个外部参数而不是整个LLM,同时达到可比甚至什至更好的性能。为了进一步研究 LLM 的 PEFT 方法,本文提出了 LLM-Adapters,这是一个易于使用的框架,它将各种适配器集成到 LLM 中,并可以针对不同的任务执行这些基于适配器的 LLM PEFT 方法。该框架包括最先进的开放访问 LLM,如 LLaMA、BLOOM、OPT 和 GPT-J,以及广泛使用的适配器,如串行适配器、并行适配器和 LoRA。该框架旨在研究友好、高效、模块化和可扩展,允许集成新的适配器并使用新的和更大规模的 LLM 对其进行评估。此外,为了评估 LLMs-Adapter 中适配器的有效性,我们对六个数学推理数据集进行了实验。结果表明,在具有少量额外可训练参数的较小规模 LLM (7B) 中使用基于适配器的 PEFT 产生的性能与强大的 LLM (175B) 相当,在某些情况下优于简单数学推理数据集的零样本推理.总的来说,我们提供了一个有前途的框架,用于在下游任务上微调大型 LLM。 我们相信拟议的 LLMs-Adapters 将推进基于适配器的 PEFT 研究,促进研究管道的部署,并使实际应用程序能够应用于现实世界的系统。
更多Ai资讯:公主号AiCharm