redis源码解析(三)——dict
版本:redis - 5.0.4
参考资料:redis设计与实现
文件:src下的dict.c dict.h
- 一、dict.h
- 数据结构
- rehash(扩展/收缩)
- 操作
- 二、dict.c
- 1.dictGenericDelete
- 2.dictNext
- 3.dictScan
- 4._dictGetStatsHt
一、dict.h
dict(字典),又称为符号表,关联数组或映射。用于保存键值对。
- 字典使用哈希表作为底层实现。
- 使用两张表来进行大小的扩展。
- 用链接的方式处理冲突。新节点头插。
数据结构
//节点:key, v, next
typedef struct dictEntry {
void *key;
union {
void *val;
uint64_t u64;
int64_t s64;
double d;
} v;
struct dictEntry *next;
} dictEntry;
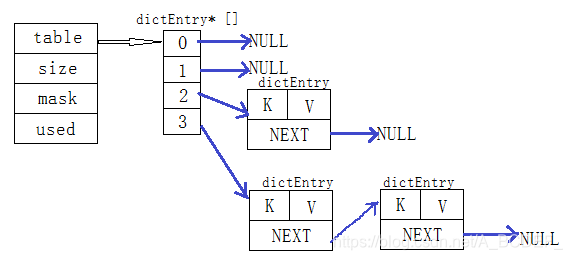
//hash表
typedef struct dictht {
dictEntry **table;//dictEntry数组
unsigned long size;//表大小
unsigned long sizemask;//表的掩码,等于size-1
unsigned long used;//已有的节点数量
} dictht;
//字典
typedef struct dict {
dictType *type;
void *privdata;
dictht ht[2];//两张表
long rehashidx; /* rehashing not in progress if rehashidx == -1 */
unsigned long iterators; /* number of iterators currently running */
} dict;
hash表的存储结构:
rehash(扩展/收缩)
字典中存储了两张hash表,先使用ht[0],rehash时:
- 为ht[1]分配空间:若是扩展,ht[1]的大小等于ht[0].used * 2的第一个2^n;若是收缩,ht[1]的大小等于第一个ht[0].used 的2^n
- 将ht[0]中的全部键值对rehash,存放到ht[1]中。
- 当ht[0]为空时,释放ht[0],将ht[1]设为ht[0],并在ht[1]创建一个空白hash表。
渐进式rehash:当键值对很多时,rehash很慢,甚至需要服务器在一段时间内停止服务,为了避免这样的事情,所以需要渐进式的,分多次rehash到ht[1]。
- 为ht[1]分配空间后,将字典中的rehashidx设为0,说明正在rehash。
- rehash期间,每次对字典增删改查时,除了执行指定操作,还要顺带把ht[0]在rehashidx索引上的全部键值对rehash到ht[1]。完成后,rehashidx加一。
- 当ht[0]为空时,设rehashidx为-1,表示rehash结束。
缺点是,rehash期间同时使用两张表,所以许多操作都需要执行两遍,在ht[0]没有找到的节点在ht[1]上还要再找一次。
操作
//迭代器
typedef struct dictIterator {
dict *d;
long index;
int table, safe;
dictEntry *entry, *nextEntry;
/* unsafe iterator fingerprint for misuse detection. */
long long fingerprint;
} dictIterator;
//参数为 (void *privdata, const dictEntry *de) ,返回值为 void 的函数建立别名 dictScanFunction。
typedef void (dictScanFunction)(void *privdata, const dictEntry *de);
typedef void (dictScanBucketFunction)(void *privdata, dictEntry **bucketref);
typedef的高级应用
/* API */
dict *dictCreate(dictType *type, void *privDataPtr);//生成
int dictExpand(dict *d, unsigned long size);//扩展
int dictAdd(dict *d, void *key, void *val);//添加节点
dictEntry *dictAddRaw(dict *d, void *key, dictEntry **existing);//生成一个空节点,加到dict中
dictEntry *dictAddOrFind(dict *d, void *key);//得到指定节点
int dictReplace(dict *d, void *key, void *val);//替换值
int dictDelete(dict *d, const void *key);//删除给定键的节点
dictEntry *dictUnlink(dict *ht, const void *key);//移除节点 但不释放
void dictFreeUnlinkedEntry(dict *d, dictEntry *he);//释放那个移除的节点
void dictRelease(dict *d);//释放d
dictEntry * dictFind(dict *d, const void *key);//查找
void *dictFetchValue(dict *d, const void *key);//得到值
int dictResize(dict *d);//重新设置大小
dictIterator *dictGetIterator(dict *d);//生成一个不安全的迭代器
dictIterator *dictGetSafeIterator(dict *d);//生成一个安全的迭代器
dictEntry *dictNext(dictIterator *iter);//获取迭代器中的下一个节点
void dictReleaseIterator(dictIterator *iter);//释放迭代器
dictEntry *dictGetRandomKey(dict *d);//随机得到一个节点
unsigned int dictGetSomeKeys(dict *d, dictEntry **des, unsigned int count);//随机取一些节点放在des中
void dictGetStats(char *buf, size_t bufsize, dict *d);//得到dict中的表的信息
//根据key和目标长度计算出索引值
uint64_t dictGenHashFunction(const void *key, int len);
uint64_t dictGenCaseHashFunction(const unsigned char *buf, int len);//hash算法
void dictEmpty(dict *d, void(callback)(void*));//清空
//判断能否重新设置值(表的大小有一个临界值)
void dictEnableResize(void);
void dictDisableResize(void);
int dictRehash(dict *d, int n);//rehash
int dictRehashMilliseconds(dict *d, int ms);//在给定时间内,循环执行哈希重定位
//设置 获取种子
void dictSetHashFunctionSeed(uint8_t *seed);
uint8_t *dictGetHashFunctionSeed(void);
//打印
unsigned long dictScan(dict *d, unsigned long v, dictScanFunction *fn, dictScanBucketFunction *bucketfn, void *privdata);
uint64_t dictGetHash(dict *d, const void *key);//得到key的hash
dictEntry **dictFindEntryRefByPtrAndHash(dict *d, const void *oldptr, uint64_t hash);//得到hash对应的指向节点的指针的地址
二、dict.c
1.dictGenericDelete
//用于移除节点,nofree判断移除的节点是否释放空间
//需要释放,则该函数就是删除节点函数
//不需要是否,就是移除节点函数,移除的节点之后还要使用,所以暂不释放,使用完后调用函数释放
static dictEntry *dictGenericDelete(dict *d, const void *key, int nofree) {
uint64_t h, idx;
dictEntry *he, *prevHe;
int table;
//表为空,没有节点
if (d->ht[0].used == 0 && d->ht[1].used == 0) return NULL;
//进行增删改查时 都顺便rehash一遍
if (dictIsRehashing(d)) _dictRehashStep(d);
h = dictHashKey(d, key);
//遍历两张表
for (table = 0; table <= 1; table++) {
//使用掩码,得到下标根据下标取出值
idx = h & d->ht[table].sizemask;
he = d->ht[table].table[idx];
prevHe = NULL;
while(he) {
if (key==he->key || dictCompareKeys(d, key, he->key)) {
//把节点移出链表
if (prevHe)
prevHe->next = he->next;
else
d->ht[table].table[idx] = he->next;
//是否释放节点
if (!nofree) {
dictFreeKey(d, he);
dictFreeVal(d, he);
zfree(he);
}
d->ht[table].used--;
return he;
}
prevHe = he;
he = he->next;
}
if (!dictIsRehashing(d)) break;//如果没有在rehash 则只处理一张表 否则处理两张
}
return NULL; /* not found */
}
这个函数比较简单 但其中出现的一些内容都是在各个函数中频繁出现的。
1. 进行增删改查时 都顺便rehash一遍
if (dictIsRehashing(d)) _dictRehashStep(d);
2. 根据key得到值
h = dictHashKey(d, key);
idx = h & d->ht[table].sizemask;
he = d->ht[table].table[idx];
3.遍历两张表
for (table = 0; table <= 1; table++) {
...
if (!dictIsRehashing(d)) break;//如果没有在rehash 则只处理一张表 否则处理两张
}
2.dictNext
//得到迭代器的下一个节点
dictEntry *dictNext(dictIterator *iter) {
while (1) {
if (iter->entry == NULL) {
dictht *ht = &iter->d->ht[iter->table];
//第一次
if (iter->index == -1 && iter->table == 0) {
if (iter->safe)
iter->d->iterators++;
else
iter->fingerprint = dictFingerprint(iter->d);//获取指纹
}
iter->index++;
//要处理的下标超出表的大小
if (iter->index >= (long) ht->size) {
//要么在rehash:处理下一个表
if (dictIsRehashing(iter->d) && iter->table == 0) {
iter->table++;
iter->index = 0;
ht = &iter->d->ht[1];
} else {//要么处理完全部节点,停止
break;
}
}
iter->entry = ht->table[iter->index];//当前节点指向下一个要处理的节点
} else {
iter->entry = iter->nextEntry;
}
if (iter->entry) {
/* We need to save the 'next' here, the iterator user
* may delete the entry we are returning. */
iter->nextEntry = iter->entry->next;//设置next
return iter->entry;
}
}
return NULL;
}
3.dictScan
听说这是一个很重要的函数 但是目前还不太懂为什么,以后再说吧。
/* dictScan() is used to iterate over the elements of a dictionary.
*
* Iterating works the following way:
*
* 1) Initially you call the function using a cursor (v) value of 0.
* 2) The function performs one step of the iteration, and returns the
* new cursor value you must use in the next call.
* 3) When the returned cursor is 0, the iteration is complete.
*
* The function guarantees all elements present in the
* dictionary get returned between the start and end of the iteration.
* However it is possible some elements get returned multiple times.
*
* For every element returned, the callback argument 'fn' is
* called with 'privdata' as first argument and the dictionary entry
* 'de' as second argument.
*
* HOW IT WORKS.
*
* The iteration algorithm was designed by Pieter Noordhuis.
* The main idea is to increment a cursor starting from the higher order
* bits. That is, instead of incrementing the cursor normally, the bits
* of the cursor are reversed, then the cursor is incremented, and finally
* the bits are reversed again.
*
* This strategy is needed because the hash table may be resized between
* iteration calls.
*
* dict.c hash tables are always power of two in size, and they
* use chaining, so the position of an element in a given table is given
* by computing the bitwise AND between Hash(key) and SIZE-1
* (where SIZE-1 is always the mask that is equivalent to taking the rest
* of the division between the Hash of the key and SIZE).
*
* For example if the current hash table size is 16, the mask is
* (in binary) 1111. The position of a key in the hash table will always be
* the last four bits of the hash output, and so forth.
*
* WHAT HAPPENS IF THE TABLE CHANGES IN SIZE?
*
* If the hash table grows, elements can go anywhere in one multiple of
* the old bucket: for example let's say we already iterated with
* a 4 bit cursor 1100 (the mask is 1111 because hash table size = 16).
*
* If the hash table will be resized to 64 elements, then the new mask will
* be 111111. The new buckets you obtain by substituting in ??1100
* with either 0 or 1 can be targeted only by keys we already visited
* when scanning the bucket 1100 in the smaller hash table.
*
* By iterating the higher bits first, because of the inverted counter, the
* cursor does not need to restart if the table size gets bigger. It will
* continue iterating using cursors without '1100' at the end, and also
* without any other combination of the final 4 bits already explored.
*
* Similarly when the table size shrinks over time, for example going from
* 16 to 8, if a combination of the lower three bits (the mask for size 8
* is 111) were already completely explored, it would not be visited again
* because we are sure we tried, for example, both 0111 and 1111 (all the
* variations of the higher bit) so we don't need to test it again.
*
* WAIT... YOU HAVE *TWO* TABLES DURING REHASHING!
*
* Yes, this is true, but we always iterate the smaller table first, then
* we test all the expansions of the current cursor into the larger
* table. For example if the current cursor is 101 and we also have a
* larger table of size 16, we also test (0)101 and (1)101 inside the larger
* table. This reduces the problem back to having only one table, where
* the larger one, if it exists, is just an expansion of the smaller one.
*
* LIMITATIONS
*
* This iterator is completely stateless, and this is a huge advantage,
* including no additional memory used.
*
* The disadvantages resulting from this design are:
*
* 1) It is possible we return elements more than once. However this is usually
* easy to deal with in the application level.
* 2) The iterator must return multiple elements per call, as it needs to always
* return all the keys chained in a given bucket, and all the expansions, so
* we are sure we don't miss keys moving during rehashing.
* 3) The reverse cursor is somewhat hard to understand at first, but this
* comment is supposed to help.
*/
unsigned long dictScan(dict *d,
unsigned long v,
dictScanFunction *fn,
dictScanBucketFunction* bucketfn,
void *privdata)
{
dictht *t0, *t1;
const dictEntry *de, *next;
unsigned long m0, m1;
if (dictSize(d) == 0) return 0;
if (!dictIsRehashing(d)) {
t0 = &(d->ht[0]);
m0 = t0->sizemask;
/* Emit entries at cursor */
if (bucketfn) bucketfn(privdata, &t0->table[v & m0]);
de = t0->table[v & m0];
while (de) {
next = de->next;
fn(privdata, de);
de = next;
}
/* Set unmasked bits so incrementing the reversed cursor
* operates on the masked bits */
v |= ~m0;
/* Increment the reverse cursor */
v = rev(v);
v++;
v = rev(v);
} else {
t0 = &d->ht[0];
t1 = &d->ht[1];
/* Make sure t0 is the smaller and t1 is the bigger table */
if (t0->size > t1->size) {
t0 = &d->ht[1];
t1 = &d->ht[0];
}
m0 = t0->sizemask;
m1 = t1->sizemask;
/* Emit entries at cursor */
if (bucketfn) bucketfn(privdata, &t0->table[v & m0]);
de = t0->table[v & m0];
while (de) {
next = de->next;
fn(privdata, de);
de = next;
}
/* Iterate over indices in larger table that are the expansion
* of the index pointed to by the cursor in the smaller table */
do {
/* Emit entries at cursor */
if (bucketfn) bucketfn(privdata, &t1->table[v & m1]);
de = t1->table[v & m1];
while (de) {
next = de->next;
fn(privdata, de);
de = next;
}
/* Increment the reverse cursor not covered by the smaller mask.*/
v |= ~m1;
v = rev(v);
v++;
v = rev(v);
/* Continue while bits covered by mask difference is non-zero */
} while (v & (m0 ^ m1));
}
return v;
}
4._dictGetStatsHt
/*
获取一个表的全部信息
*/
size_t _dictGetStatsHt(char *buf, size_t bufsize, dictht *ht, int tableid) {
unsigned long i, slots = 0, chainlen, maxchainlen = 0;
unsigned long totchainlen = 0;
unsigned long clvector[DICT_STATS_VECTLEN];
size_t l = 0;
if (ht->used == 0) {
return snprintf(buf,bufsize,
"No stats available for empty dictionaries\n");
}
/* Compute stats. */
//初始化该数组 每个都设为0
for (i = 0; i < DICT_STATS_VECTLEN; i++) clvector[i] = 0;
//遍历这个表ht
for (i = 0; i < ht->size; i++) {
dictEntry *he;
if (ht->table[i] == NULL) {
clvector[0]++;
continue;
}
slots++;
/* For each hash entry on this slot... */
chainlen = 0;
//得到对应下标的链,并处理
he = ht->table[i];
while(he) {
chainlen++;
he = he->next;
}
//长度作为下标,值是记录对应长度的链的数量
clvector[(chainlen < DICT_STATS_VECTLEN) ? chainlen : (DICT_STATS_VECTLEN-1)]++;
if (chainlen > maxchainlen) maxchainlen = chainlen;
totchainlen += chainlen;
}
/* Generate human readable stats. */
l += snprintf(buf+l,bufsize-l,
"Hash table %d stats (%s):\n"
" table size: %ld\n"
" number of elements: %ld\n"
" different slots: %ld\n"
" max chain length: %ld\n"
" avg chain length (counted): %.02f\n"
" avg chain length (computed): %.02f\n"
" Chain length distribution:\n",
tableid, (tableid == 0) ? "main hash table" : "rehashing target",
ht->size, ht->used, slots, maxchainlen,
(float)totchainlen/slots, (float)ht->used/slots);
for (i = 0; i < DICT_STATS_VECTLEN-1; i++) {
if (clvector[i] == 0) continue;
if (l >= bufsize) break;
l += snprintf(buf+l,bufsize-l,
" %s%ld: %ld (%.02f%%)\n",
(i == DICT_STATS_VECTLEN-1)?">= ":"",
i, clvector[i], ((float)clvector[i]/ht->size)*100);
}
/* Unlike snprintf(), teturn the number of characters actually written. */
if (bufsize) buf[bufsize-1] = '\0';
return strlen(buf);
}
基本弄清楚了每个函数的功能,但是有一些函数不知道为什么存在,也将会在什么地方使用。