MySQL 索引常见问题汇总,一次性梳理
hello,大家好,我是张张,「架构精进之路」公号作者。

提到MySQL查询分析,就会涉及到索引相关知识,要想学好MySQL,索引是重要且不得不啃下的一环,今天就把MySQL索引常见问题进行汇总,一次性梳理清楚。
文章目录:
- 索引
- 什么是索引?
- 索引的优缺点?
- 索引的作用?
- 什么情况下需要建索引?
- 什么情况下不建索引?
- 索引的数据结构
- Hash索引和B+树索引的区别?
- 为什么B+树比B树更适合实现数据库索引?
- 索引有什么分类?
- 什么是最左匹配原则?
- 什么是聚集索引?
- 什么是覆盖索引?
- 索引的设计原则?
- 索引什么时候会失效?
- 什么是前缀索引?
索引
什么是索引?
索引是存储引擎用于提高数据库表的访问速度的一种数据结构。
索引的优缺点?
优点:
- 加快数据查找的速度
- 为用来排序或者是分组的字段添加索引,可以加快分组和排序的速度
- 加快表与表之间连接的速度
缺点:
- 建立索引需要占用物理空间
- 会降低表的增删改的效率,因为每次对表记录进行增删改,需要进行动态维护索引,导致增删改时间变长
索引的作用?
数据是存储在磁盘上的,查询数据时,如果没有索引,会加载所有的数据到内存,依次进行检索,读取磁盘次数较多。有了索引,就不需要加载所有数据,因为B+树的高度一般在2-4层,最多只需要读取2-4次磁盘,查询速度大大提升。
什么情况下需要建索引?
- 经常用于查询的字段
- 经常用于连接的字段建立索引,可以加快连接的速度
- 经常需要排序的字段建立索引,因为索引已经排好序,可以加快排序查询速度
什么情况下不建索引?
- where条件中用不到的字段不适合建立索引
- 表记录较少
- 需要经常增删改
- 参与列计算的列不适合建索引
- 区分度不高的字段不适合建立索引,如性别等
索引的数据结构
索引的数据结构主要有B+树和哈希表,对应的索引分别为B+树索引和哈希索引。InnoDB引擎的索引类型有B+树索引和哈希索引,默认的索引类型为B+树索引。
B+树索引
B+ 树是基于B 树和叶子节点顺序访问指针进行实现,它具有B树的平衡性,并且通过顺序访问指针来提高区间查询的性能。
在 B+ 树中,节点中的 key 从左到右递增排列,如果某个指针的左右相邻 key 分别是 keyi 和 keyi+1,则该指针指向节点的所有 key 大于等于 keyi 且小于等于 keyi+1。
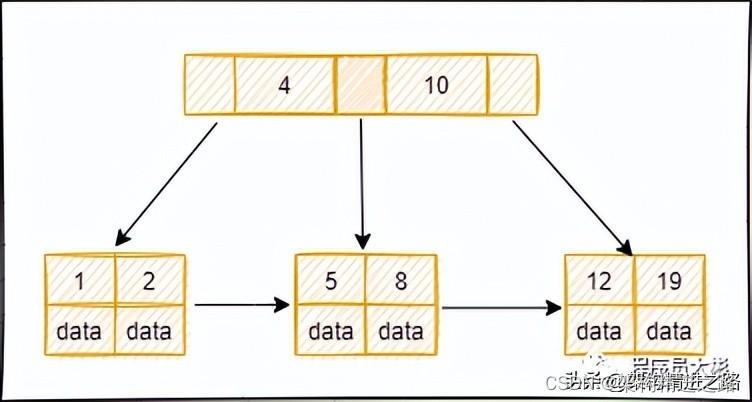
进行查找操作时,首先在根节点进行二分查找,找到key所在的指针,然后递归地在指针所指向的节点进行查找。直到查找到叶子节点,然后在叶子节点上进行二分查找,找出key所对应的数据项。
MySQL 数据库使用最多的索引类型是BTREE索引,底层基于B+树数据结构来实现。
mysql> show index from blog\G;
*************************** 1. row ***************************
Table: blog
Non_unique: 0
Key_name: PRIMARY
Seq_in_index: 1
Column_name: blog_id
Collation: A
Cardinality: 4
Sub_part: NULL
Packed: NULL
Null:
Index_type: BTREE
Comment:
Index_comment:
Visible: YES
Expression: NULL哈希索引
哈希索引是基于哈希表实现的,对于每一行数据,存储引擎会对索引列进行哈希计算得到哈希码,并且哈希算法要尽量保证不同的列值计算出的哈希码值是不同的,将哈希码的值作为哈希表的key值,将指向数据行的指针作为哈希表的value值。这样查找一个数据的时间复杂度就是O(1),一般多用于精确查找。
Hash索引和B+树索引的区别?
- 哈希索引不支持排序,因为哈希表是无序的。
- 哈希索引不支持范围查找。
- 哈希索引不支持模糊查询及多列索引的最左前缀匹配。
- 因为哈希表中会存在哈希冲突,所以哈希索引的性能是不稳定的,而B+树索引的性能是相对稳定的,每次查询都是从根节点到叶子节点。
为什么B+树比B树更适合实现数据库索引?
- 由于B+树的数据都存储在叶子结点中,叶子结点均为索引,方便扫库,只需要扫一遍叶子结点即可,但是B树因为其分支结点同样存储着数据,我们要找到具体的数据,需要进行一次中序遍历按序来扫,所以B+树更加适合在区间查询的情况,而在数据库中基于范围的查询是非常频繁的,所以通常B+树用于数据库索引。
- B+树的节点只存储索引key值,具体信息的地址存在于叶子节点的地址中。这就使以页为单位的索引中可以存放更多的节点。减少更多的I/O支出。
- B+树的查询效率更加稳定,任何关键字的查找必须走一条从根结点到叶子结点的路。所有关键字查询的路径长度相同,导致每一个数据的查询效率相当。
索引有什么分类?
1、主键索引:名为primary的唯一非空索引,不允许有空值。
2、唯一索引:索引列中的值必须是唯一的,但是允许为空值。唯一索引和主键索引的区别是:唯一约束的列可以为null且可以存在多个null值。唯一索引的用途:唯一标识数据库表中的每条记录,主要是用来防止数据重复插入。创建唯一索引的SQL语句如下:
ALTER TABLE table_name
ADD CONSTRAINT constraint_name UNIQUE KEY(column_1,column_2,...);3、组合索引:在表中的多个字段组合上创建的索引,只有在查询条件中使用了这些字段的左边字段时,索引才会被使用,使用组合索引时需遵循最左前缀原则。
4、全文索引:只有在MyISAM引擎上才能使用,只能在CHAR、VARCHAR和TEXT类型字段上使用全文索引。
什么是最左匹配原则?
如果 SQL 语句中用到了组合索引中的最左边的索引,那么这条 SQL 语句就可以利用这个组合索引去进行匹配。当遇到范围查询(>、<、between、like)就会停止匹配,后面的字段不会用到索引。
对(a,b,c)建立索引,查询条件使用 a/ab/abc 会走索引,使用 bc 不会走索引。如果查询条件为a = 1 and b > 2 and c = 3,那么a、b个字两段能用到索引,而c无法使用索引,因为b字段是范围查询,导致后面的字段无法使用索引。
如下图,对(a, b) 建立索引,a 在索引树中是全局有序的,而 b 是全局无序,局部有序(当a相等时,会根据b进行排序)。
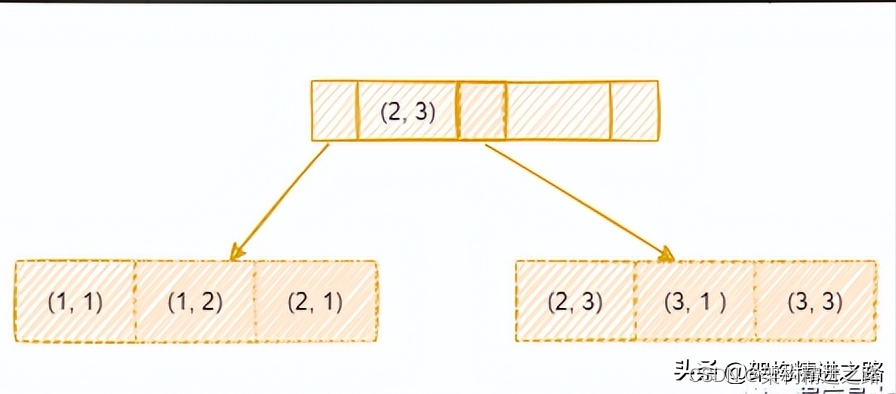
当a的值确定的时候,b是有序的。例如a = 1时,b值为1,2是有序的状态。当执行a = 1 and b = 2时a和b字段能用到索引。而对于查询条件a < 4 and b = 2时,a字段能用到索引,b字段则用不到索引。因为a的值此时是一个范围,不是固定的,在这个范围内b的值不是有序的,因此b字段无法使用索引。
什么是聚集索引?
InnoDB使用表的主键构造主键索引树,同时叶子节点中存放的即为整张表的记录数据。聚集索引叶子节点的存储是逻辑上连续的,使用双向链表连接,叶子节点按照主键的顺序排序,因此对于主键的排序查找和范围查找速度比较快。
聚集索引的叶子节点就是整张表的行记录。InnoDB 主键使用的是聚簇索引。聚集索引要比非聚集索引查询效率高很多。
对于InnoDB来说,聚集索引一般是表中的主键索引,如果表中没有显示指定主键,则会选择表中的第一个不允许为NULL的唯一索引。如果没有主键也没有合适的唯一索引,那么InnoDB内部会生成一个隐藏的主键作为聚集索引,这个隐藏的主键长度为6个字节,它的值会随着数据的插入自增。
什么是覆盖索引?
select的数据列只用从索引中就能够取得,不需要回表进行二次查询,也就是说查询列要被所使用的索引覆盖。对于innodb表的二级索引,如果索引能覆盖到查询的列,那么就可以避免对主键索引的二次查询。
不是所有类型的索引都可以成为覆盖索引。覆盖索引要存储索引列的值,而哈希索引、全文索引不存储索引列的值,所以MySQL使用b+树索引做覆盖索引。
对于使用了覆盖索引的查询,在查询前面使用explain,输出的extra列会显示为using index。
比如user_like 用户点赞表,组合索引为(user_id, blog_id),user_id和blog_id都不为null。
explain select blog_id from user_like where user_id = 13;explain结果的Extra列为Using index,查询的列被索引覆盖,并且where筛选条件符合最左前缀原则,通过索引查找就能直接找到符合条件的数据,不需要回表查询数据。
explain select user_id from user_like where blog_id = 1;explain结果的Extra列为Using where; Using index, 查询的列被索引覆盖,where筛选条件不符合最左前缀原则,无法通过索引查找找到符合条件的数据,但可以通过索引扫描找到符合条件的数据,也不需要回表查询数据。

索引的设计原则?
- 索引列的区分度越高,索引的效果越好。比如使用性别这种区分度很低的列作为索引,效果就会很差。
- 尽量使用短索引,对于较长的字符串进行索引时应该指定一个较短的前缀长度,因为较小的索引涉及到的磁盘I/O较少,查询速度更快。
- 索引不是越多越好,每个索引都需要额外的物理空间,维护也需要花费时间。
- 利用最左前缀原则。
索引什么时候会失效?
导致索引失效的情况:
- 对于组合索引,不是使用组合索引最左边的字段,则不会使用索引
- 以%开头的like查询如%abc,无法使用索引;非%开头的like查询如abc%,相当于范围查询,会使用索引
- 查询条件中列类型是字符串,没有使用引号,可能会因为类型不同发生隐式转换,使索引失效
- 判断索引列是否不等于某个值时
- 对索引列进行运算
- 查询条件使用or连接,也会导致索引失效
什么是前缀索引?
有时需要在很长的字符列上创建索引,这会造成索引特别大且慢。使用前缀索引可以避免这个问题。
前缀索引是指对文本或者字符串的前几个字符建立索引,这样索引的长度更短,查询速度更快。
创建前缀索引的关键在于选择足够长的前缀以保证较高的索引选择性。索引选择性越高查询效率就越高,因为选择性高的索引可以让MySQL在查找时过滤掉更多的数据行。
建立前缀索引的方式:
// email列创建前缀索引
ALTER TABLE table_name ADD KEY(column_name(prefix_length));·END·
希望今天的讲解对大家有所帮助,谢谢!
Thanks for reading!
作者:架构精进之路,十年研发风雨路,大厂架构师,CSDN 博客专家,专注架构技术沉淀学习及分享,职业与认知升级,坚持分享接地气儿的干货文章,期待与你一起成长。
关注并私信我回复“01”,送你一份程序员成长进阶大礼包,欢迎勾搭。