fiddler(抓包)的用法和HTTP 协议的基本格式
目录
fiddler(抓包)用法:
HTTP 协议的基本格式
HTTP请求:
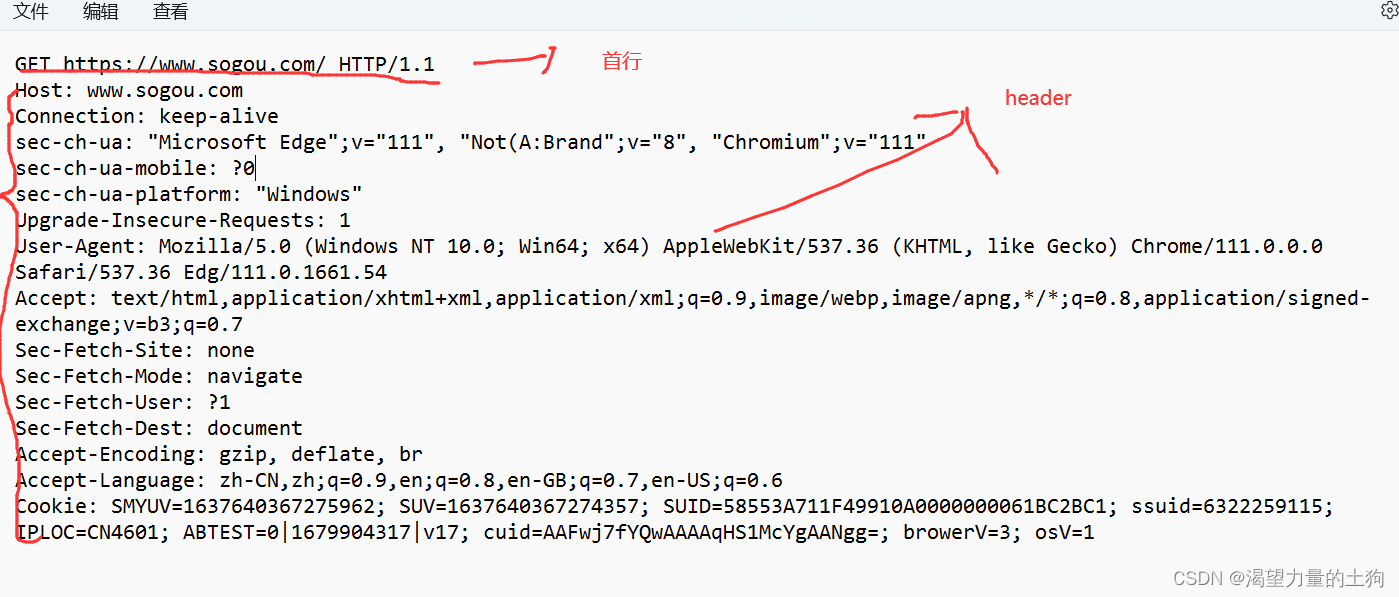
首行
认识HTTP方法
GET和POST的典型区别:
认识请求“报头”(header)
HTTP 响应
HTTP状态码:
状态码的分类:
认识响应 "报头" (header)
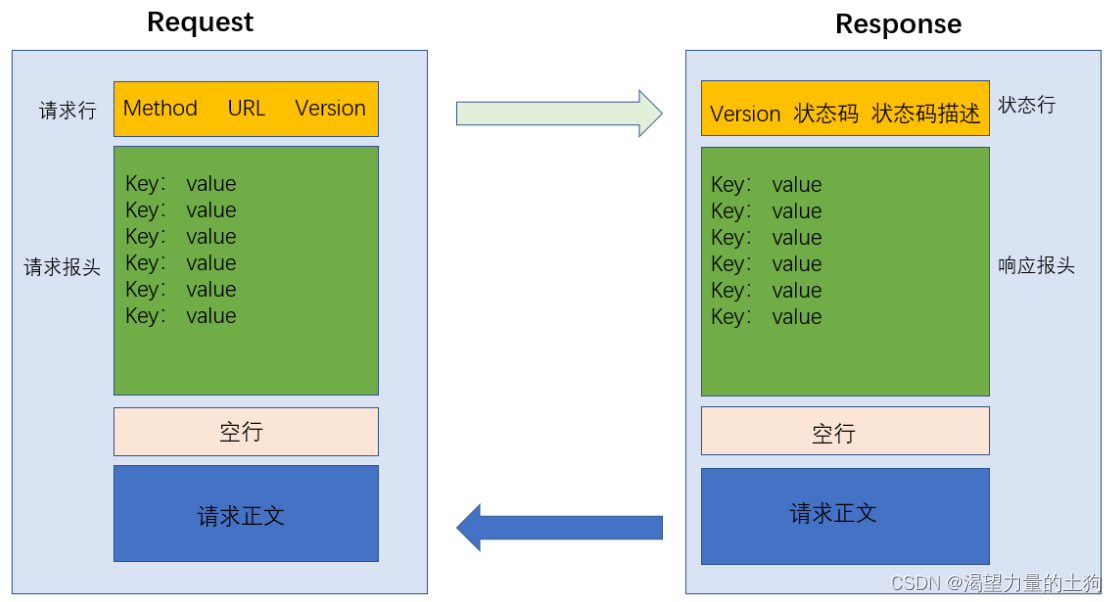
HTTP协议报文样式:
fiddler(抓包)用法:
 http请求是有一定的格式的,使用fiddler进行抓包可以查看一些相关的信息。
http请求是有一定的格式的,使用fiddler进行抓包可以查看一些相关的信息。
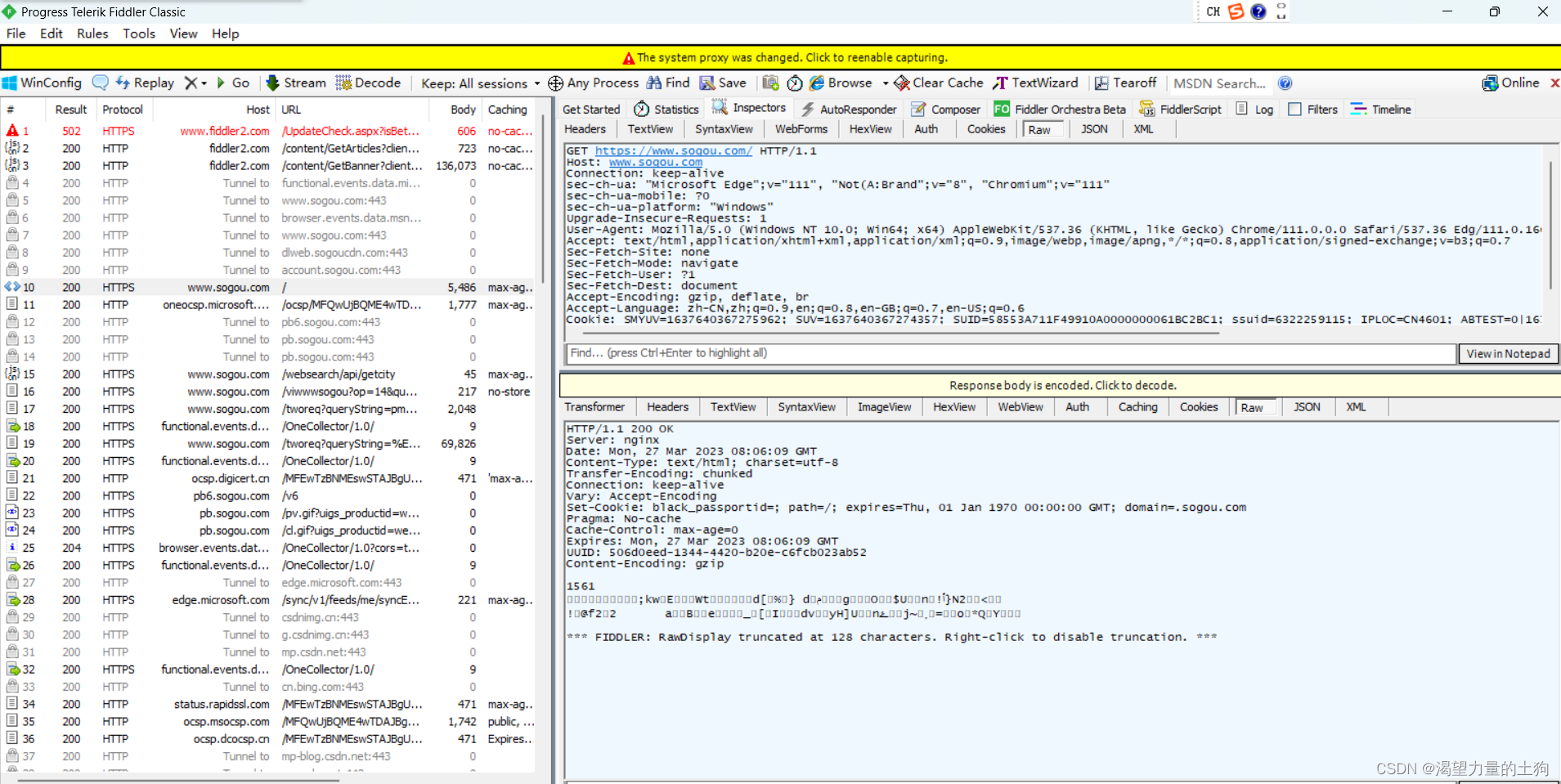
比如我们打开一个搜狗的页面:
 打开后fiddler就会自动抓包,然后我们点到fiddler进行查看:
打开后fiddler就会自动抓包,然后我们点到fiddler进行查看:
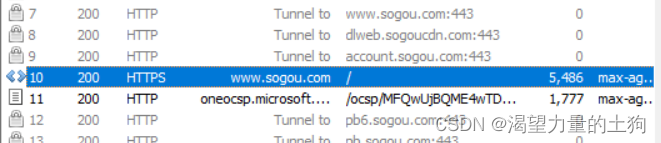
这个就是刚刚页面的请求,双击之后选择相关的信息进行查看,一般我们选择点击ROW之后在记事本中查看即可:
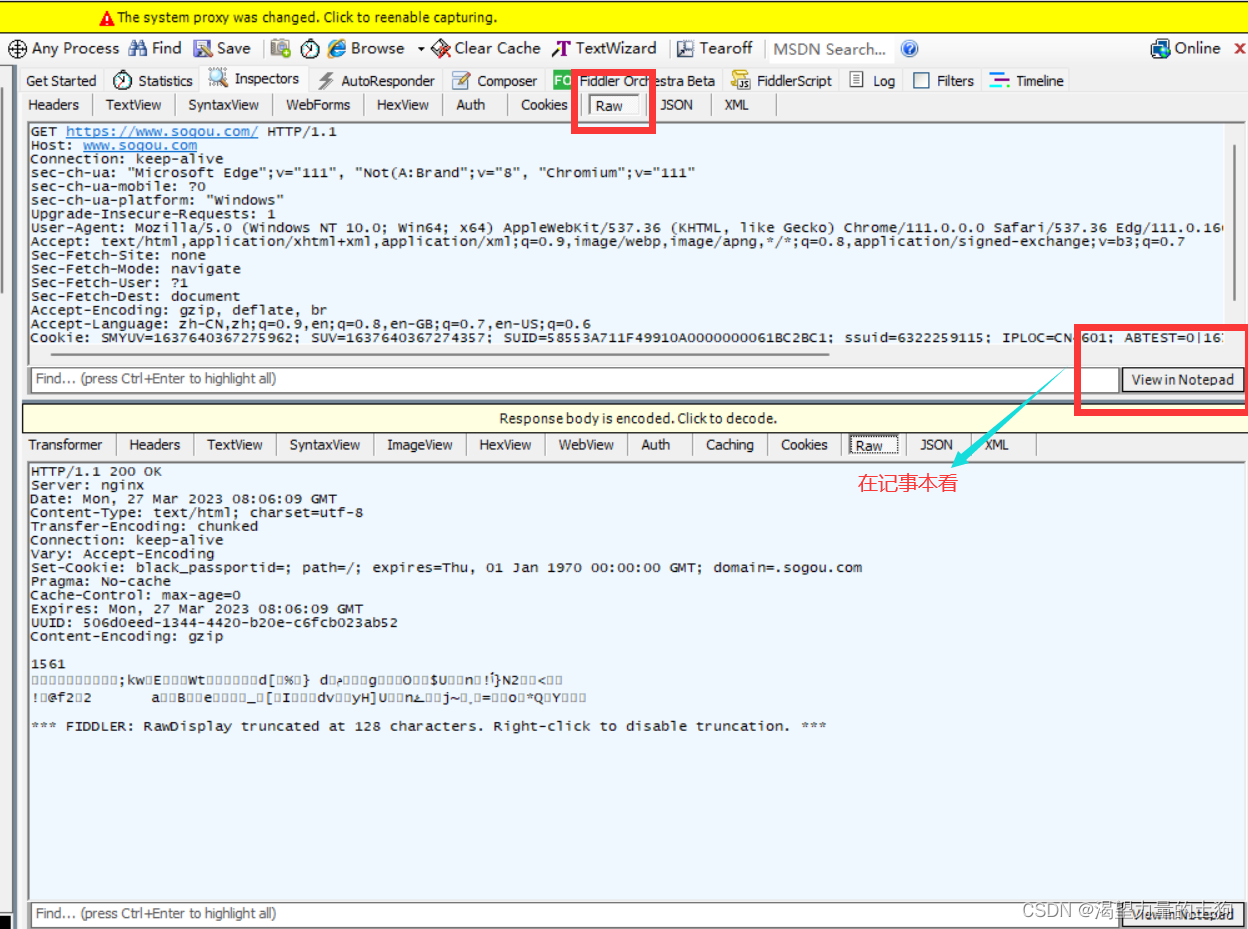 这个就是我们的抓包结果:
这个就是我们的抓包结果: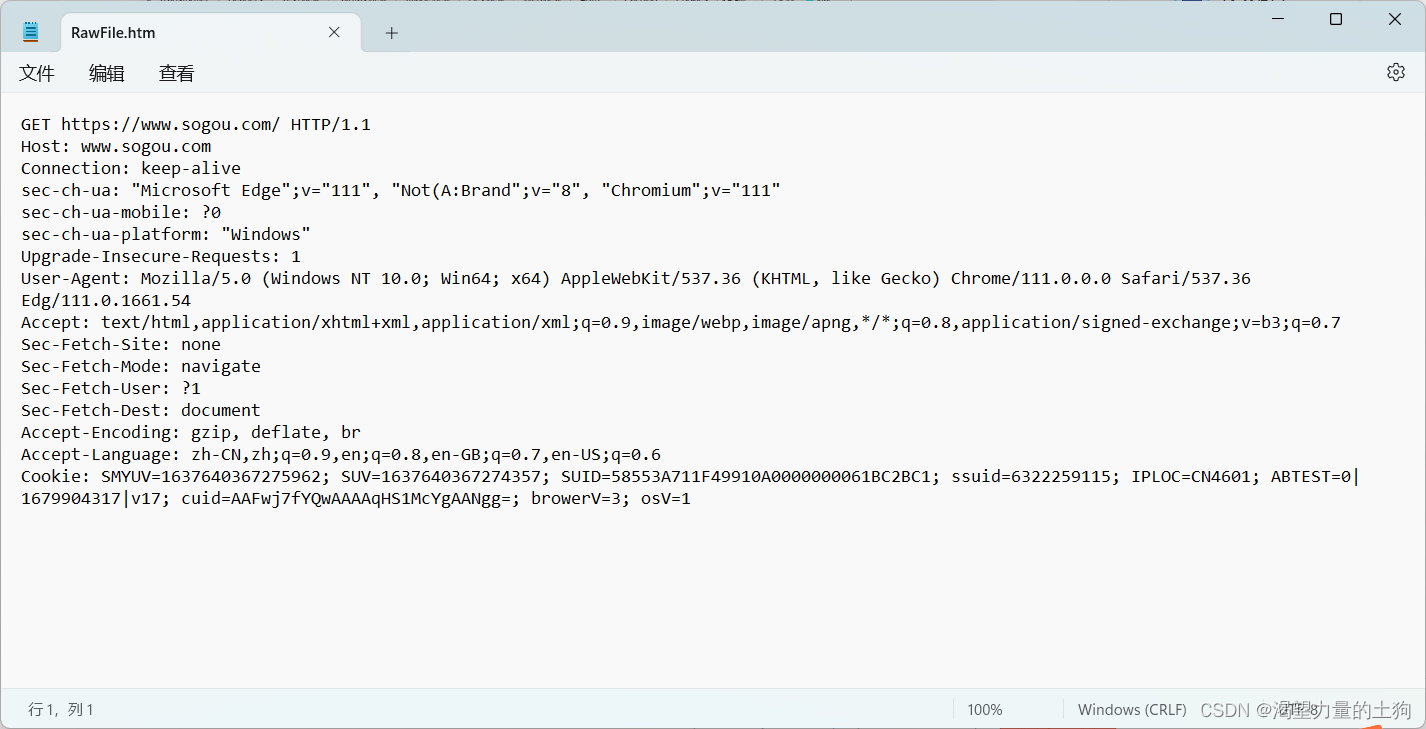
我们观察抓包结果,可以看到,当前http请求是行文本格式的数据。
然后我们可以使用记事本查看响应:
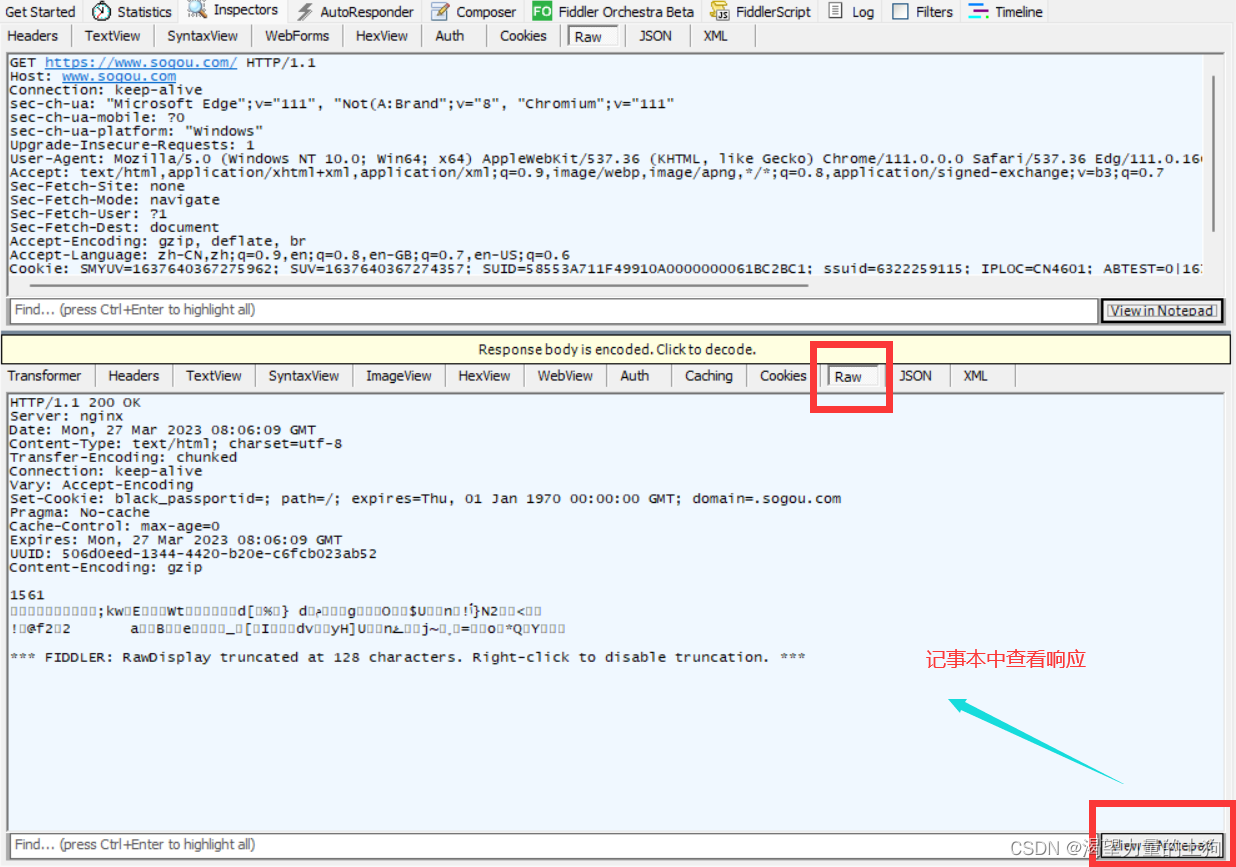 这个就是抓包的http响应:
这个就是抓包的http响应:
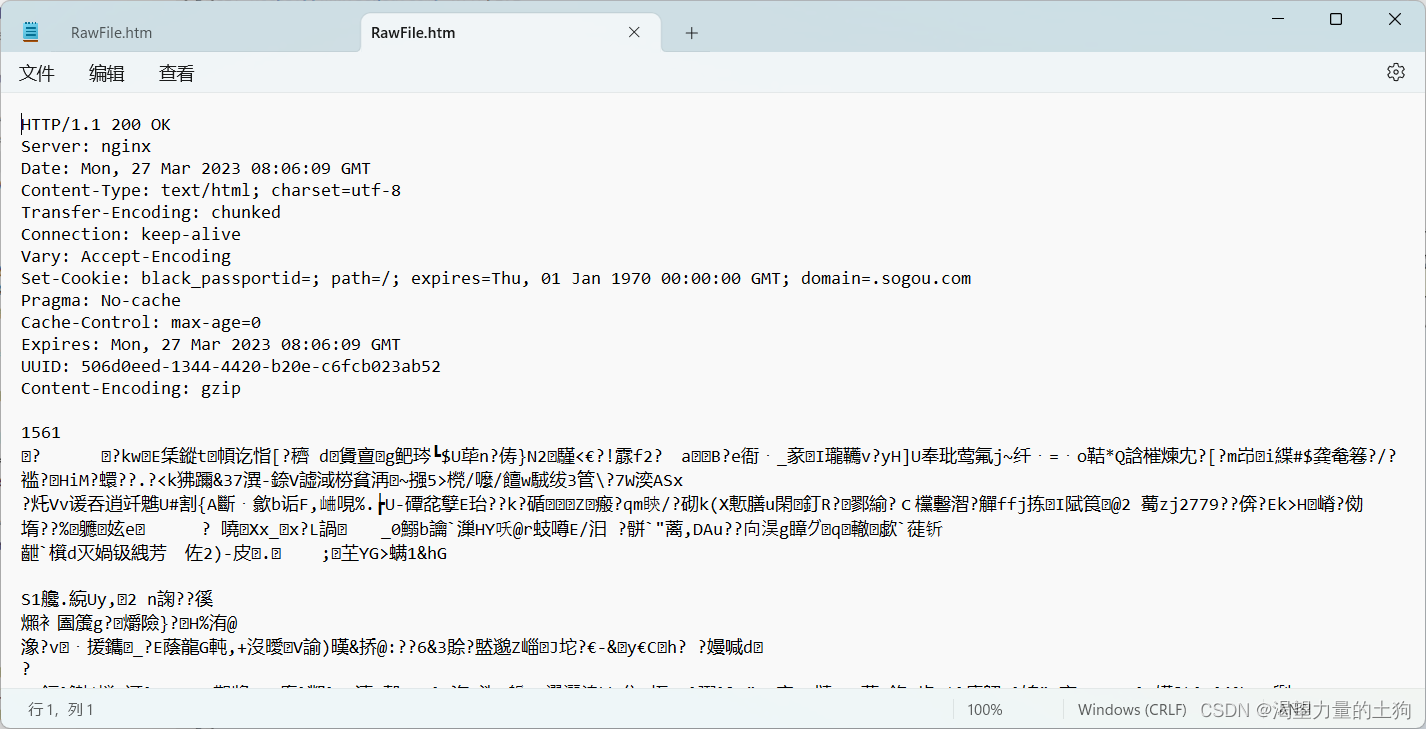 点击解压缩后就出现了原来的信息:
点击解压缩后就出现了原来的信息:
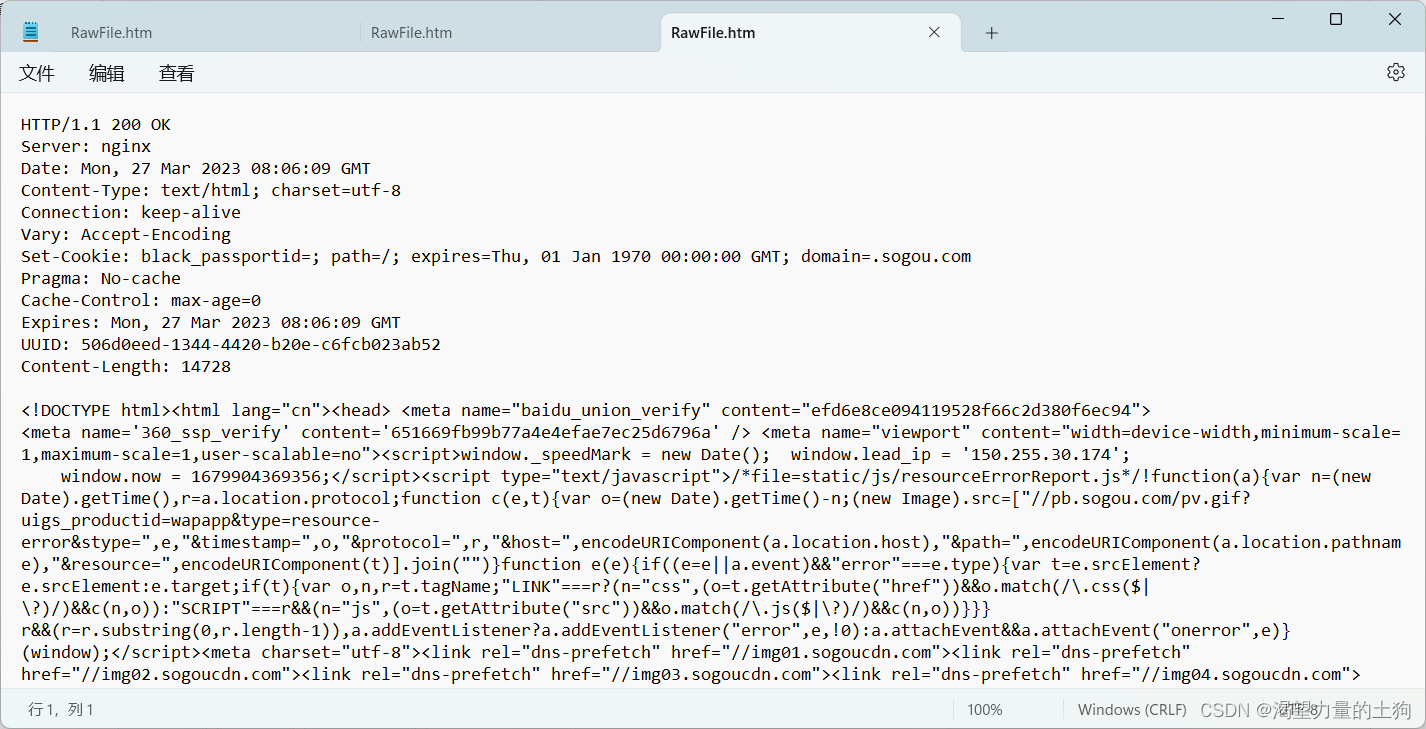 下面的文本数据就是搜狗首页html页面的内容。
下面的文本数据就是搜狗首页html页面的内容。
HTTP 协议的基本格式
下面就抓包信息进行解读:
HTTP请求:

首行
包含3个部分,之间用空格隔开
首先GET:HTTP中的方法
https://www.sogou.com/ 是URL(就是我们俗称的网址)URL就是唯一资源标识符(互联网上每个资源是不一样的,URL可以进行身份的识别和区别)

详细的如图:

URL最关键的四个部分:
1、服务器地址/域名/ip
2、端口号
3、带层次的路径
4、查询字符串
其中URL有些部分是可以省略的,比如端口(省略http端口80,https端口443),协议名: 可以省略, 省略后默认为 http://,ip 地址 / 域名: 在 HTML 中可以省略(比如 img, link, script, a 标签的 src 或者 href 属性). 省略后表示服务器的 ip / 域名与当前 HTML 所属的 ip / 域名一致,带层次的文件路径: 可以省略. 省略后相当于 / . 有些服务器会在发现 / 路径的时候自动访问/index.html,查询字符串: 可以省略,片段标识: 可以省略。
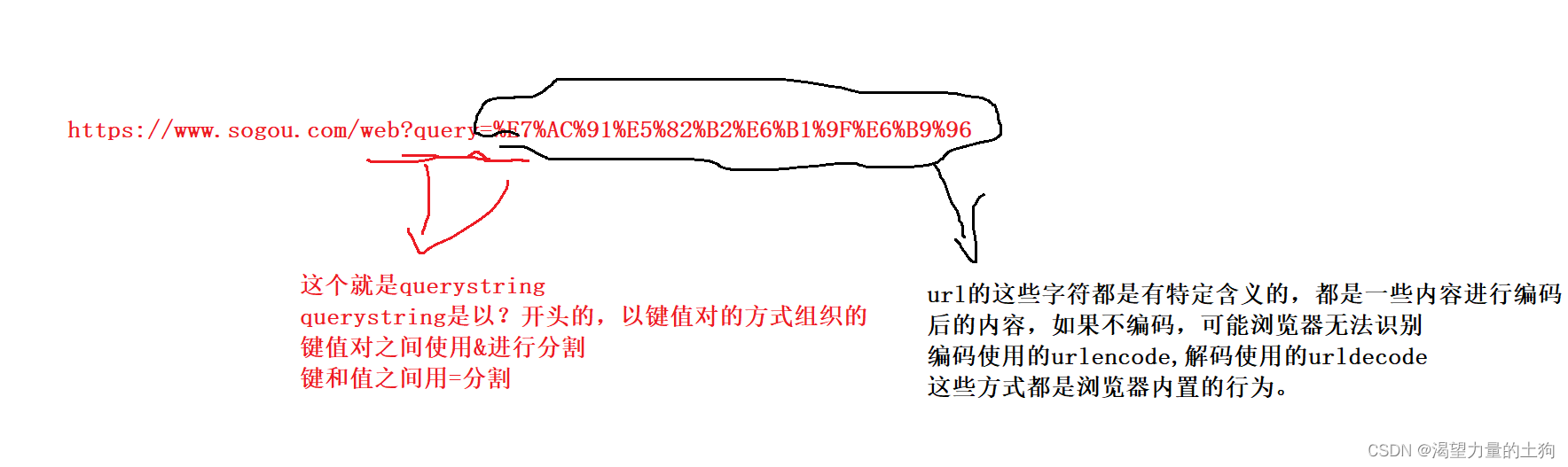
query string 中的内容是键值对结构. 其中的 key 和 value 的取值和个数, 完全都是程序猿自己约
定的. 我们可以通过这样的方式来自定制传输我们需要的信息给服务器。
认识HTTP方法
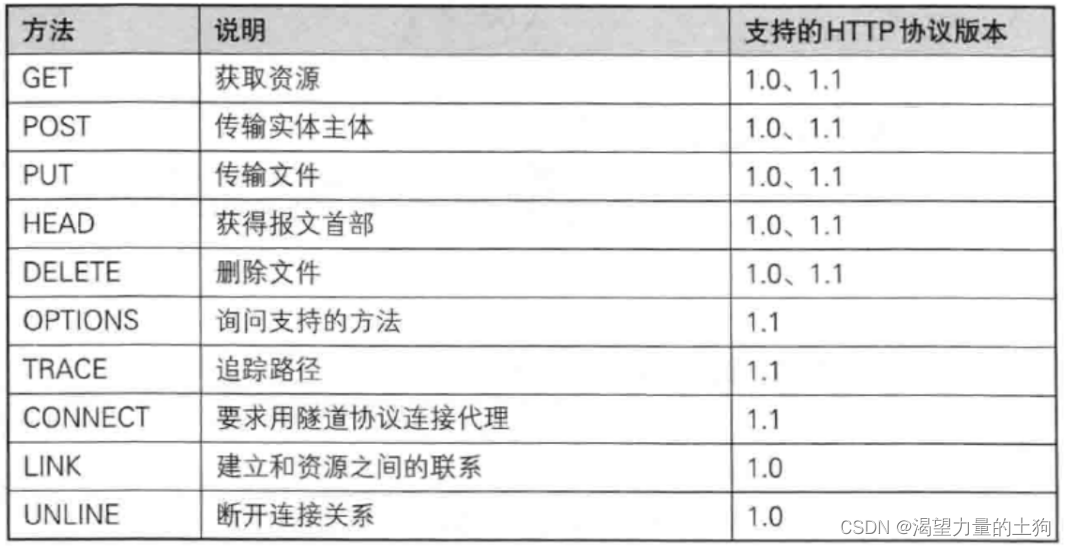 最常用的方法时GET和POST。
最常用的方法时GET和POST。
GET请求:
这几种会产生GET请求:
1、在浏览器直接输入url
2、html里的link,script,img,a....等等
3、通过js构造GET
POST请求
1、登录界面,登录跳转
2、上传图片等文件
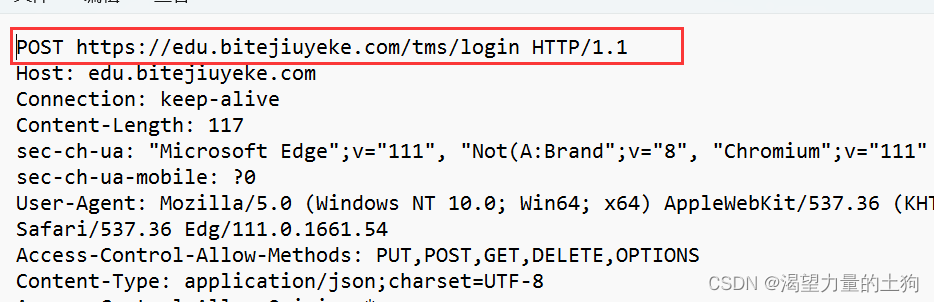
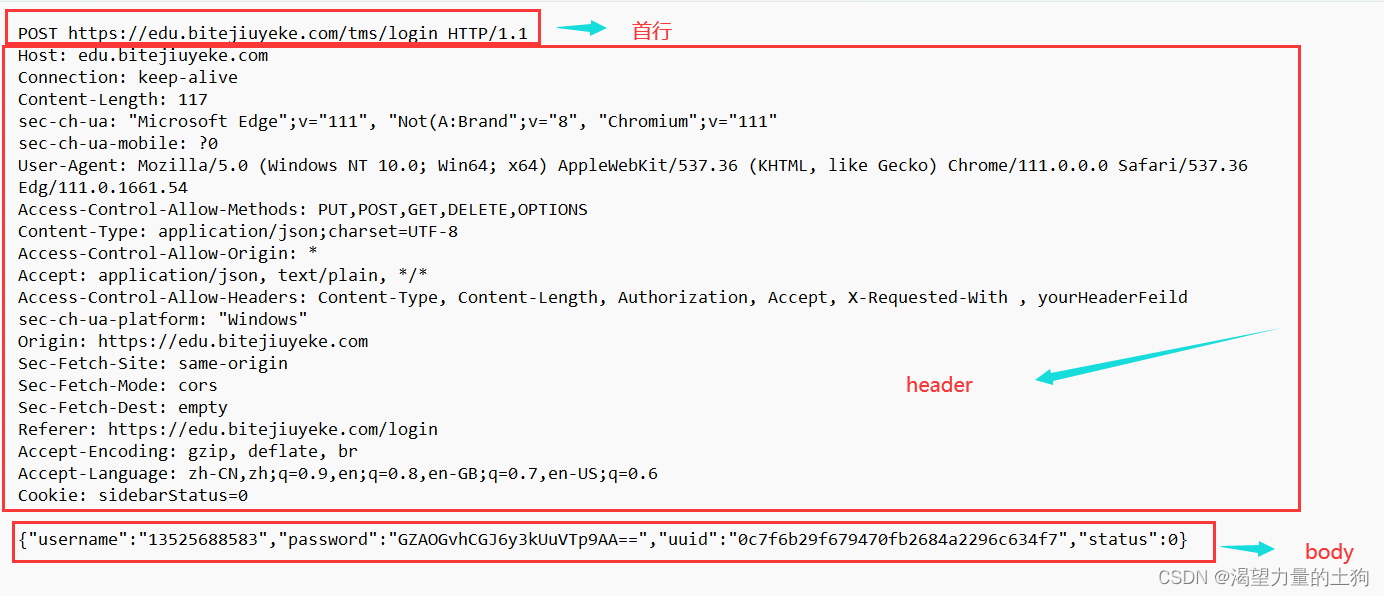 HTTP请求可以认为分成4个部分:
HTTP请求可以认为分成4个部分:
1、首行
2、请求头(header)
3、空行
4、正文(body)
 post的body中的内容是有程序员自定义的内容。其中uuid是唯一身份标识。
post的body中的内容是有程序员自定义的内容。其中uuid是唯一身份标识。
GET和POST的典型区别:
(实际没有本质上的区别,是可以相互替换的)
1、GET也可以使用服务器传递一些信息,GET传递的信息一般是放在querystring,POST传递信息则是通过body
2、语义上的区别:GET请求一般用于从服务器获取数据,POST一般用于给服务器提交数据
3、GET通常会被设计为幂等的,POST不要求幂等。(幂等简单理解就是结果稳定,输入是什么,输出就是相应的固定结果,是不能变得,类似于算法的确定性)
4、GET是可以被缓存的,POST一般不能被缓存(能够缓存的前提是要有幂等性)
其他方法:
PUT 与 POST 相似,只是具有幂等特性,一般用于更新
DELETE 删除服务器指定资源
OPTIONS 返回服务器所支持的请求方法
HEAD 类似于GET,只不过响应体不返回,只返回响应头
TRACE 回显服务器端收到的请求,测试的时候会用到这个
CONNECT 预留,暂无使用
认识请求“报头”(header)
请求报头(header)中有几个比较常用的种类:
Host: 表示服务器主机的地址和端口。
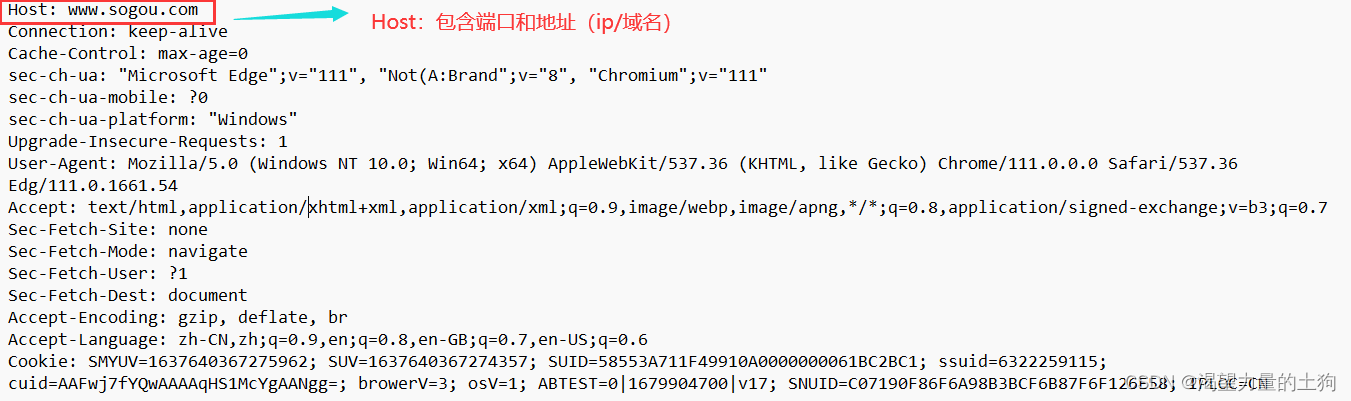
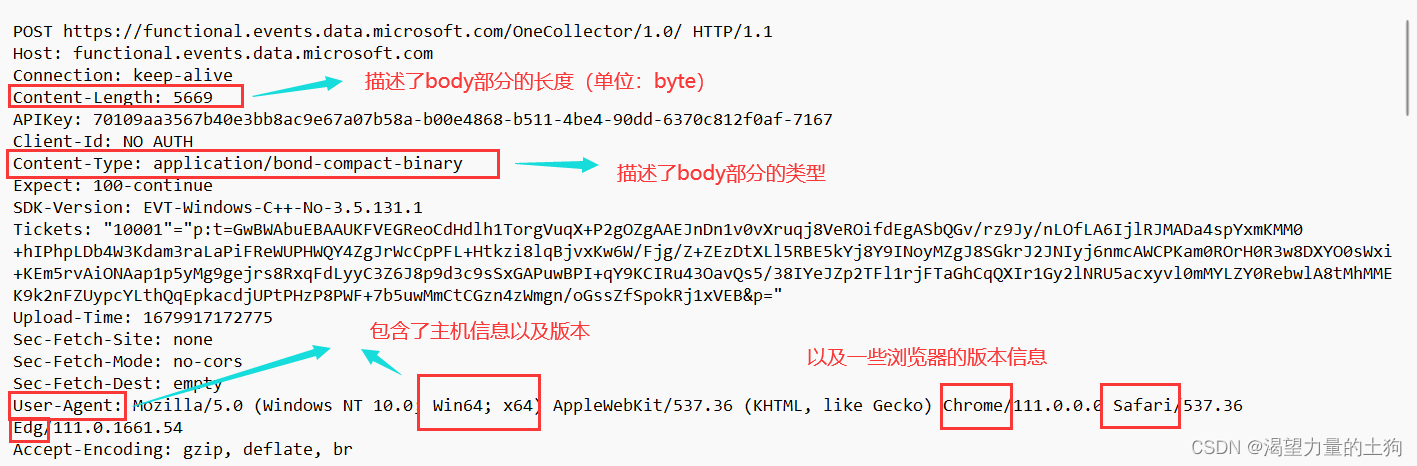
Content-Length表示 body 中的数据长度.
Content-Type表示请求的 body 中的数据格式.
User-Agent (简称 UA)表示浏览器/操作系统的属性
Referer表示这个页面是从哪个页面跳转过来的
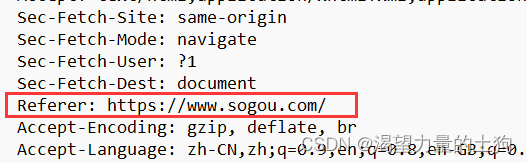
这个就表明了该搜索来源于www.sogou.com。
这就联系起来了我们所知道的运营商劫持的事情,运营商可以通过修改Referer来把连接修改,从而达成劫持。也就是因为运营商劫持等事件,后面就诞生了我们的HTTPS。
Cookie中存储了一个字符串, 这个数据可能是客户端(网页)自行通过 JS 写入的, 也可能来自于服务器(服务器在 HTTP 响应的 header 中通过 Set-Cookie 字段给浏览器返回数据)。往往可以通过这个字段实现 "身份标识" 的功能
Cookie本质上是浏览器给网页提供的本地存储数据的一种机制。
网页默认情况下是不允许访问本地硬盘的(为了安全)
但是又不得不访问本地硬盘,所以Cookie就允许网页进行少量的访问本地硬盘(进行了限制)。同时Cookie中的内容也是由程序员实现的。

Cookie里的数据是来自服务器的,通过HTTP响应获取的。
Cookie是存在于浏览器的,本地硬盘。有些是可以长期存在的,有些是短期的,有些是只限于登录,退出后就失效的等等。
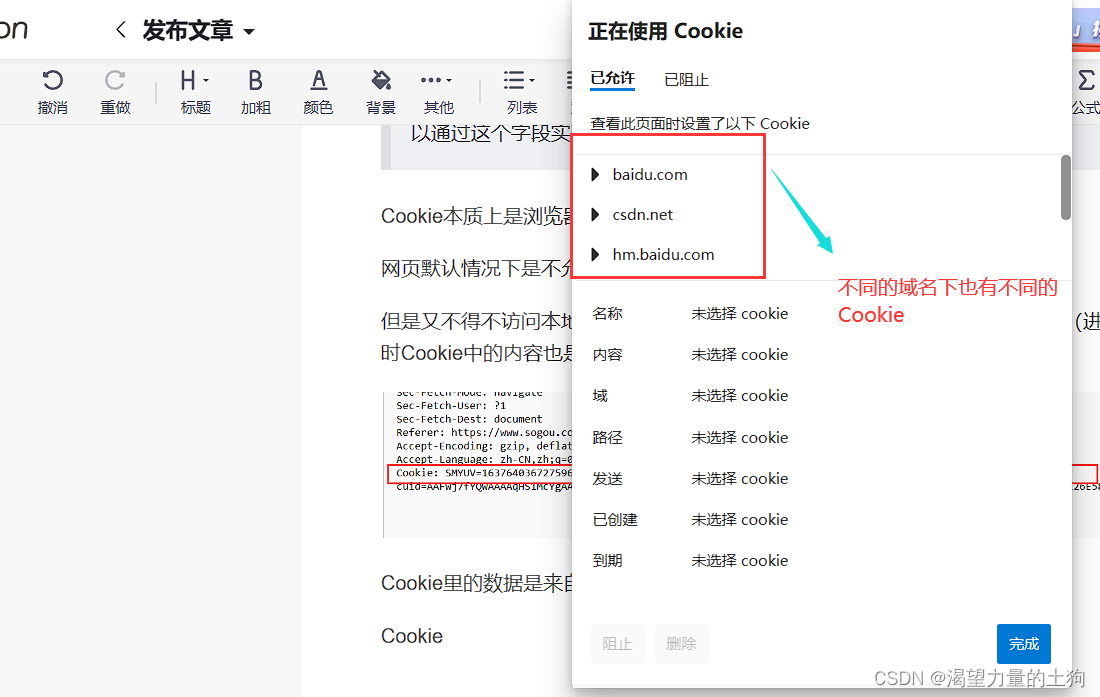
Cookie要到哪里?Cookie是要回到服务器的。
客户端这边会通过Cookie来记录当前浏览器的相关信息,保存其中间状态,客服端向服务器发送请求的时候会把Cookie夹带着发送给服务器,这样服务器就接受到了Cookie。这样服务器就知道了客户端现在是啥情况了。
当浏览器保存了Cookie后,以后在给服务器发送请求的时候就会自动带上Cookie。
HTTP 响应
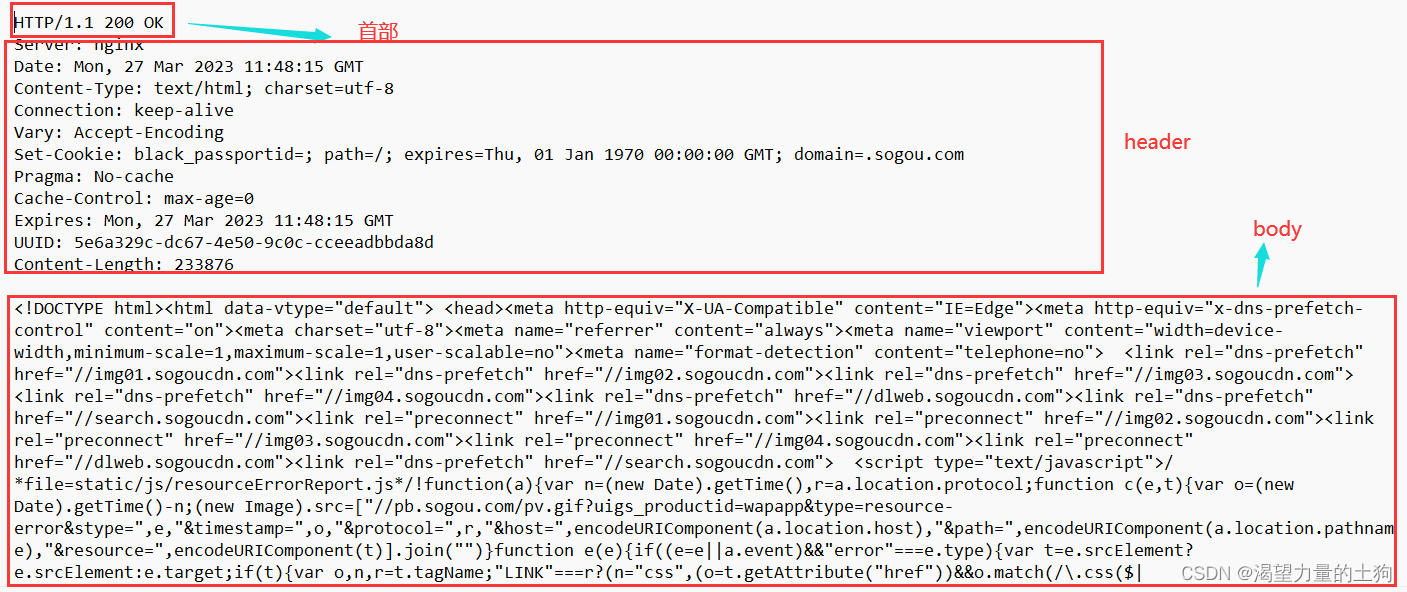
四个部分:
1、首部:
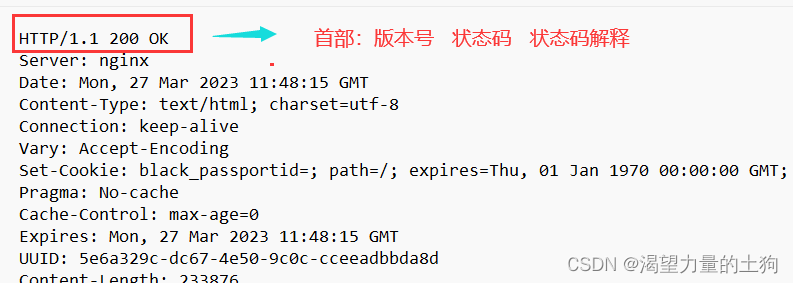 2、header
2、header
3、空格 表示header的结束标志
4、body(正文)
HTTP状态码:
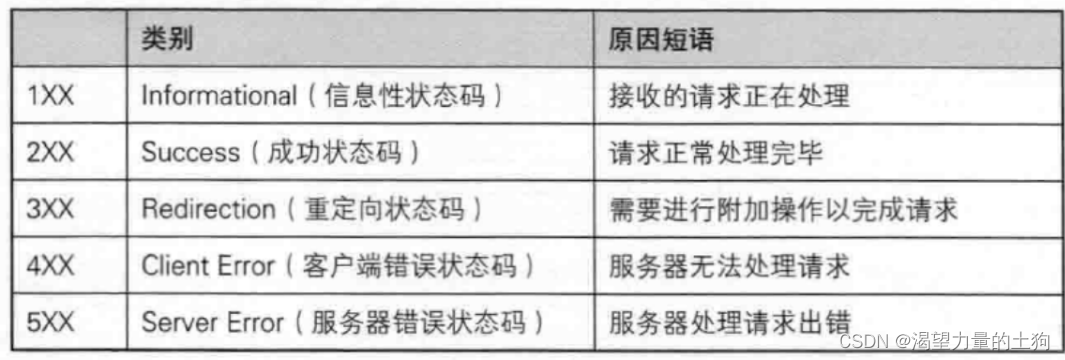
状态码表示访问一个页面的结果. (是访问成功, 还是失败, 还是其他的一些情况...)
200 OK 这是一个最常见的状态码, 表示访问成功
404 Not Found 没有找到资源
比如我们试着访问搜狗的abc.html

403 Forbidden 表示访问被拒绝. 有的页面通常需要用户具有一定的权限才能访问(登陆后才能访问)。如果用户没有登陆直接访问, 就容易见到 403
302 Move temporarily 临时重定向(这个相当于手机中的呼叫转移)
比如如果你的网站申请了新的域名,然后域名就变成了新域名,但是很多用户并不知道你改变了域名,就可以通过配置重定向临时转移,当用户访问旧的域名的时候,就跳转到新的域名进行访问即可。
301 Moved Permanently 永久重定向
500 Internal Server Error 服务器出现内部错误。 一般是服务器的代码执行过程中遇到了一些特殊情况(服务器异常崩溃)会产生这个状态码
504 Gateway Timeout (响应超时)当服务器负载比较大的时候, 服务器处理单条请求的时候消耗的时间就会很长, 就可能会导致出现超时的情况
状态码的分类:
认识响应 "报头" (header)
响应报头的基本格式和请求报头的格式基本一致
Content-Type
响应中的 Content-Type 常见取值有以下几种:
text/html : body 数据格式是 HTML
text/css : body 数据格式是 CSS
application/javascript : body 数据格式是 JavaScript
application/json : body 数据格式是 JSON
HTTP协议报文样式: