AIGC技术周报|ChatDoctor:哪里不舒服;HuggingGPT:连接大模型和机器学习社区;ChatGPT真的鲁棒吗?
AIGC通过借鉴现有的、人类创造的内容来快速完成内容创作。ChatGPT、Bard等AI聊天机器人以及Dall·E 2、Stable Diffusion等文生图模型都属于AIGC的典型案例。「AIGC技术周报」将为你带来最新的paper、博客等前瞻性研究。
1.ChatDoctor:哪里不舒服?
通用领域中的大型语言模型(LLMs),如 ChatGPT,在遵循指令和产生类似人类的响应方面取得了显著的成功。然而,此类语言模型并未针对医学领域量身定制,导致答案准确性较差,无法为医学诊断、药物等提供合理的建议。
为了解决这个问题,该研究收集了 700 多种疾病及相应症状所需要的医学测试和推荐的药物,从中产生了 5K 次医患对话。使用这些量身定制的医患对话对 LLMs 进行微调,由此产生的模型具有巨大的潜力来理解患者的需求,提供明智的建议,并在各种医疗相关领域提供有价值的帮助。

论文链接:
https://arxiv.org/abs/2303.14070
2.BloombergGPT:金融界的大模型
从情感分析和命名实体识别到问答,NLP 在金融技术领域的应用广泛而复杂。LLMs 已被证明对各种任务有效。
一项新研究展示了 BloombergGPT,这是一个具有 500 亿参数的语言模型,它在广泛的金融数据上进行了训练。该研究基于 Bloomberg 广泛的数据源构建了一个拥有 3630 亿个令牌的数据集,这可能是迄今为止最大的特定领域数据集,并增加了来自通用数据集的 3450 亿个令牌。
研究在标准 LLM 基准、开放金融基准和一套能准确反映预期用途的内部基准上验证了 BloombergGPT。
结果表明,BloombergGPT 在财经任务上显著优于现有模型,且不会牺牲通用 LLM 基准的性能。
论文链接:
https://arxiv.org/abs/2303.17564
3.HuggingGPT:连接大模型和机器学习社区
解决具有不同领域和模式的复杂 AI 任务是通向通用人工智能(AGI)的关键一步。虽然有丰富的 AI 模型可用于不同的领域和模式,但它们无法处理复杂的 AI 任务。
考虑到 LLMs 在语言理解、生成、交互和推理方面表现出非凡的能力,该研究提出了 HuggingGPT——一个利用 ChatGPT 等 LLMs 连接机器学习社区(如 HuggingFace)中的各种 AI 模型来完成任务的系统。
具体来说,在收到用户请求时使用 ChatGPT 进行任务规划,根据 HuggingFace 中可用的功能描述选择 AI 模型,用选择的 AI 模型执行每个子任务,并根据执行结果汇总响应。
借助 ChatGPT 强大的语言能力和 HuggingFace 丰富的 AI 模型,HuggingGPT 能够完成众多不同模态和领域的复杂 AI 任务,在语言、视觉、语音等具有挑战性的任务中取得令人瞩目的成果,开辟了一条加速迈向 AGI 的新道路。

论文链接:
https://arxiv.org/abs/2303.17580
4.自动音频描述模型,视障者的福音
“在所有艺术中,对我们来说最重要的是电影。”
——弗拉基米尔·列宁
一项新的研究开发了一种自动音频描述(AD)模型,它可以摄取电影并以文本形式输出 AD。由于描述对上下文的依赖性以及可用训练数据的数量有限,因此生成高质量的电影 AD 具有挑战性。通过利用预训练基础模型(如 GPT 和 CLIP),该研究只训练一个映射网络来桥接两个模型以生成视觉条件文本。下图展示了电影 AD 基于泰坦尼克号呈现的结果。

该研究的主要贡献为:
(1)结合了电影剪辑的上下文、之前的剪辑广告以及字幕;
(2)通过在视觉或上下文信息不可用的大规模数据集上进行预训练来解决缺乏训练数据的问题,如没有电影的纯文本广告或没有上下文的视觉字幕数据集;
(3)改进了当前可用的 AD 数据集,通过去除 MAD 数据集中的标签噪声,并添加字符命名信息;
(4)与以前的方法相比,这一模型在电影广告任务上获得了很好的结果。
参考链接:
https://arxiv.org/abs/2303.16899
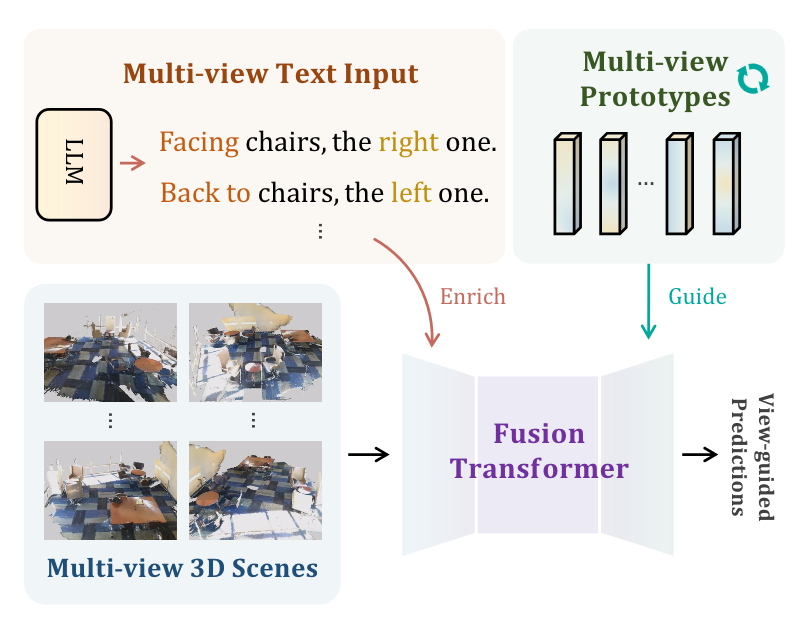
5.如何从多视图输入中理解3D场景?
一项新的研究提出了 ViewRefer,这是一个用于 3D 视觉基础的多视图框架,探索如何从文本和 3D 模态中掌握视图知识。对于文本分支,ViewRefer 利用 GPT 等 LLMs 的多样化语言知识,将单个基础文本扩展为多个几何一致的描述。另一方面,在 3D 模态中,引入了具有交互视图注意力的 transformer 融合模块,以增强对象跨视图的交互。
更重要的是,ViewRefer 采用了一个视觉 transformer 来有效地掌握多模态数据中的视图知识,并从两个角度增强了这一框架:用于更强大文本特征的视图引导注意模块,以及最终预测期间的视图引导评分策略。基于所设计的范例,ViewRefer 在三个基准测试中实现了很好的性能。
参考链接:
https://arxiv.org/abs/2303.16894
6.ChatGPT真的鲁棒吗?
ChatGPT 在过去几个月里受到越来越多的关注。虽然已经有很多研究对 ChatGPT 的各个方面进行了评估,但公众仍不清楚其鲁棒性,即对意外输入的性能表现。鲁棒性是负责任的 AI 特别关注的问题,尤其是对于安全关键型应用程序。
该研究从对抗性和 OOD 的角度对 ChatGPT 的鲁棒性进行了全面评估。通过选择几个流行的基础模型作为基线,结果表明,ChatGPT 在大多数对抗性和 OOD 分类和翻译任务上表现出一致性。然而,绝对性能远非完美,这表明对抗性和 OOD 鲁棒性仍然是对基础模型的重大威胁。
参考链接:
https://arxiv.org/abs/2302.12095