DJ3-4 传输层(第四节课)
目录
一、TCP 概述
二、TCP 报文段的首部字段格式
三、TCP 往返时延的估计和超时
1. 估计往返时间
2. RTT 估计例子
3. 估计往返时间的偏差
4. 设置重传超时间隔
一、TCP 概述

全双工服务:允许在同一时间同一连接上,数据能够双向传输。注意:TCP 可从缓存中取出并放入报文段中的数据数量受限于最大报文段长度(maximum segment size, MSS)
点到点:一个发送者,一个接收者;可靠按序的字节流。
面向连接:在数据交换前握手(交换控制信息),初始化发送方和接收方的状态。
没有 “信息边界”:假设我们需要发三个数据包,TCP 可能会因受限于 MSS 而把这三个包截断并组合后再发出。而 UDP 不会这样做,首先 UDP 会限制分组的大小从而使其适合发送,其次分组之间是相互独立的。因此,在 UDP 传输中不会出现把数据包截断的情况。
流量控制:使发送方不会淹没接收方。
TCP 拥塞和流量控制:
- 设置窗口大小
- 设置收发缓冲区
二、TCP 报文段的首部字段格式
TCP 报文段的构成:
- 首部字段
- 一个数据字段,包含了一块应用数据
MSS 限制了报文段数据字段的最大长度。
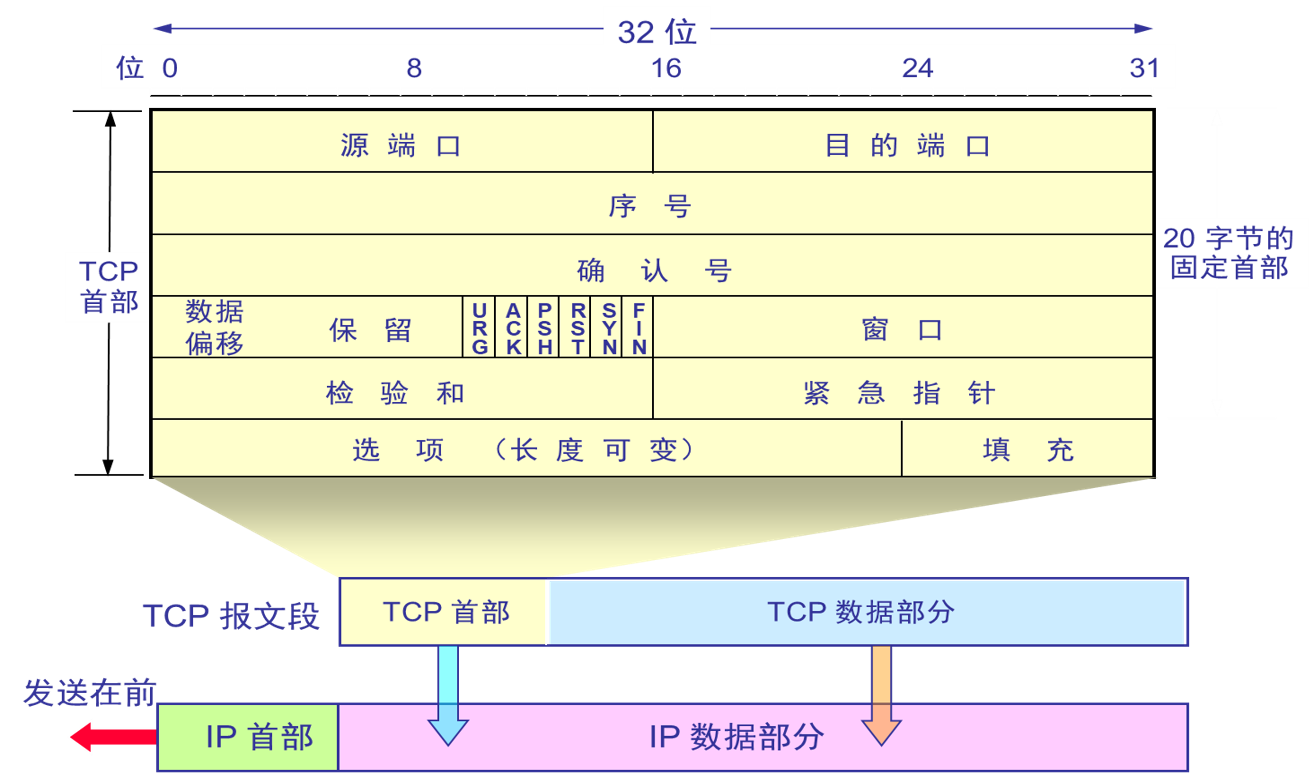

1. 源端口号和目的端口号
用于多路复用/分解来自或送到上层应用的数据。注意:发送时是多路复用,接收时是多路分解。
2. 序号和确认号
1)序号
序号 = 该报文段的第一个字节在字节流中的位置编号
一条 TCP 连接的双方均可随机地选择初始序号。
TCP 采用的是可靠按序的字节流:序号是建立在传送的字节流之上,而不是建立在传送的报文段的序列之上。换句话说,TCP 是以字节为单位来编号的,而不是以报文段为单位来编号。

2)确认号
主机 A 填充进报文段的确认号是主机 A 期望从主机 B 收到的下一字节的序号。换句话说,就是期望从主机 B 收到的下一报文段的序号。
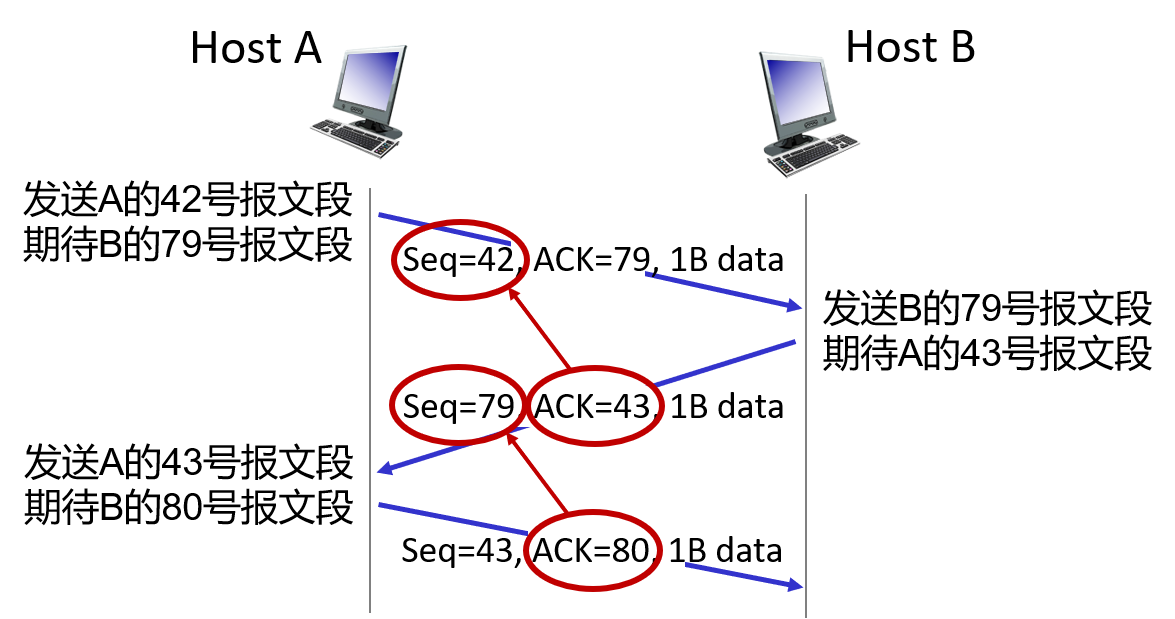
由于每次都传输的是一个字节的数据,因此序号每次只加一。
3)累积确认
TCP 只确认字节流中至第一个丢失字节为止的字节。
主机 A 接收到来自主机 B 的包含字节 0~535 的报文段、字节 900~1000 的报文段,还没有接收到来自主机 B 的包含字节 536~899 的报文段。因此,主机 A 将在下一个发送给主机 B 的报文段中,把确认号字段设置为 536 。
3. 数据偏移/首部长度
该字段指示了以 32bit 为单位(即以 4 字节为单位)的 TCP 首部长度,即 TCP 报文段数据字段的起始处距离 TCP 报文段的起始处有多远。
4. 保留字段
占 6 位,保留为今后使用,但目前应置为 0。
5. 标志字段

3)紧急 URG(URGent)
当 URG=1 时,表明紧急指针字段有效。它告诉系统此报文段中有紧急数据,应尽快传送(相当于高优先级的数据)。紧急数据放在该报文段数据字段的最前面。
4)确认 ACK(ACKnowledgment)
只有当 ACK=1 时确认号字段的内容才有效;当 ACK=0 时,确认号字段的内容无效。
6)复位 RST(ReSeT)
当 RST=1 时,表明 TCP 连接中出现严重差错(如主机崩溃或其它原因),必须释放连接,然后再重新建立运输连接。
7)同步 SYN(SYNchronize)
当 SYN=1 时,表示这是一个连接请求或连接接受报文。
8)终止 FIN(FINish)
用来释放一个连接。FIN=1 表明此报文段的发送方的数据已发送完毕,并要求释放运输连接。

6. 窗口字段
该字段用于流量控制。占 16 位,是让对方设置发送窗口的依据,单位为字节。
7. 检验和
占16 位,在计算检验和时,要在 TCP 报文段前加上 12 字节的伪首部。
- 伪首部
- 首部字段
- 数据字段
8. 紧急数据指针
占 16 位,指出在该报文段中紧急数据共有多少个字节,紧急数据放在该报文段数据字段的最前面。
9. 填充字段
该字段用于使整个首部长度是 4 字节的整数倍。
三、TCP 往返时延的估计和超时
Q:如何设置 TCP 的超时值?
A:显然需要比 RTT 长,但 RTT 是动态变化的,若时间
- 太短:导致不成熟的超时和不必要的重传
- 太长:导致对报文段丢失的响应慢
Q:需要设置几个定时器?
1. 估计往返时间
SampleRTT(样本RTT):测量从报文段发出到收到该报文段的确认信息的时间。
- TCP 不会为重传的报文段计算 SampleRTT
- TCP 仅在某个时刻为某报文段做 SampleRTT 测量,而非每一个
SampleRTT 是变化的,因此需要一个 SampleRTT 的均值,即 EstimatedRTT(均值RTT)
对收到的 SampleRTT 根据以下公式进行均值处理:
EstimatedRTT = (1 - α) * EstimatedRTT + α * SampleRTT以编程的思想来理解该公式:即每次按公式来更新 EstimatedRTT 的值。
上述均值计算被称为 “指数加权移动平均”,RFC 推荐的 α 取值是 α=0.125 。
2. RTT 估计例子
由图可知,通过计算得到的 EstimatedRTT,我们能够保证有一半的报文段避免不成熟的超时。但是,我们还想要更多的紫线上方的报文段能够避免不成熟的超时,因此引入了 “安全余量”。

3. 估计往返时间的偏差
DevRTT(偏差RTT):用于估算 SampleRTT 一般会偏离 EstimatedRTT 的程度。
与前面类似,SampleRTT-EstimatedRTT 是变化的,因此需要一个 SampleRTT-EstimatedRTT 的均值,即 DevRTT(偏差RTT)
对收到的 SampleRTT-EstimatedRTT 根据以下公式进行均值处理:
DevRTT = (1 - β) * DevRTT + β * |SampleRTT - EstimatedRTT|RFC 推荐的 β 取值是 α=0.25 。
4. 设置重传超时间隔
根据前面的分析可知,超时间隔应该等于 EstimtedRTT 加上 “安全余量” DevRTT,从而避免不成熟的超时。同时。若 EstimatedRTT 波动较大,则需要加上更大的 “安全余量”。
最终超时间隔的公式为:
TimeoutInterval = EstimatedRTT + 4 * DevRTT实际应用:
#init
TimeoutInterval = 1
EstimatedRTT = SampleRTT
DevRTT = SampleRTT/2
#update
TimeoutInterval = EstimatedRTT + max(G, 4*DevRTT) #G是用户设置的时间粒度
DevRTT = (1 - β) * DevRTT + β * |SampleRTT - EstimatedRTT|
EstimatedRTT = (1 - α) * EstimatedRTT + α * SampleRTT
每次先更新 DevRTT 再更新 EstimatedRTT,否则 DevRTT 使用的就是不是上一次的 EstimatedRTT 了。