快排非递归 归并排序
递归深度太深会栈溢出
程序是对的,但是递归个10000层就是栈溢出
int fun(int n)
{
if (n <= 1)
{
return n;
}
return fun(n - 1) + n;
}

所以需要非递归来搞快排和归并,在效率方面没什么影响,只是解决递归深度太深的栈溢出问题
有的能直接改,例如斐波那契,知道第一个第二个的迭代,有的需要辅助,直接改不了
斐波那契数列非递归
// 计算Fibonacci的空间复杂度?
// 返回斐波那契数列的前n项
long long* Fibonacci(size_t n)
{
if(n==0)
return NULL;
long long * fibArray = (long long *)malloc((n+1) * sizeof(long long));
fibArray[0] = 0;
fibArray[1] = 1;
for (int i = 2; i <= n ; ++i)
{
fibArray[i] = fibArray[i - 1] + fibArray [i - 2];
}
return fibArray;
}
快排 非递归
思路:看递归栈帧保存了什么,就是两个区间的下标,用栈来辅助改循环
栈没法一下入两个,非要搞可以弄一个结构体保存两个区间的下标,但那样太麻烦,简单点就是可以每次入一个,入两次栈,也要注意先入右区间下标再入左区间下标
注意的就是区间入栈的顺序,先入右子树的区间,再入左子树,这样保证先序,并且正确模拟递归过程嘛
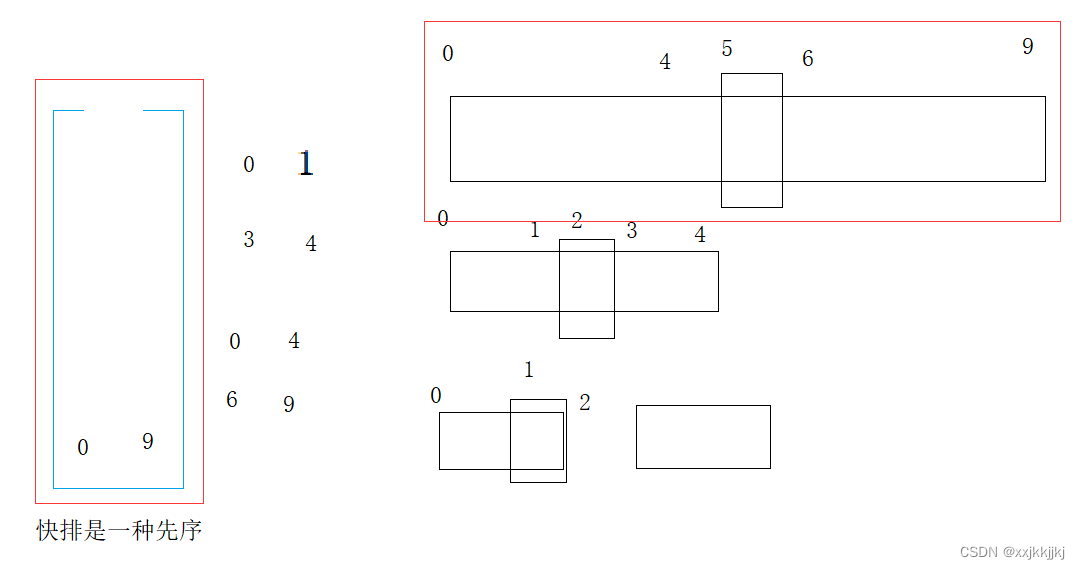
区间[0,9]单趟排选出一个key,就可以将[0,9]出栈,分出[begin, keyi-1] keyi [keyi+1, end]左右区间,左右区间如果只有一个值,或者区间不存在,就不需要再入栈了,不然就入栈,入栈顺序是右边区间先入栈,再左边入栈
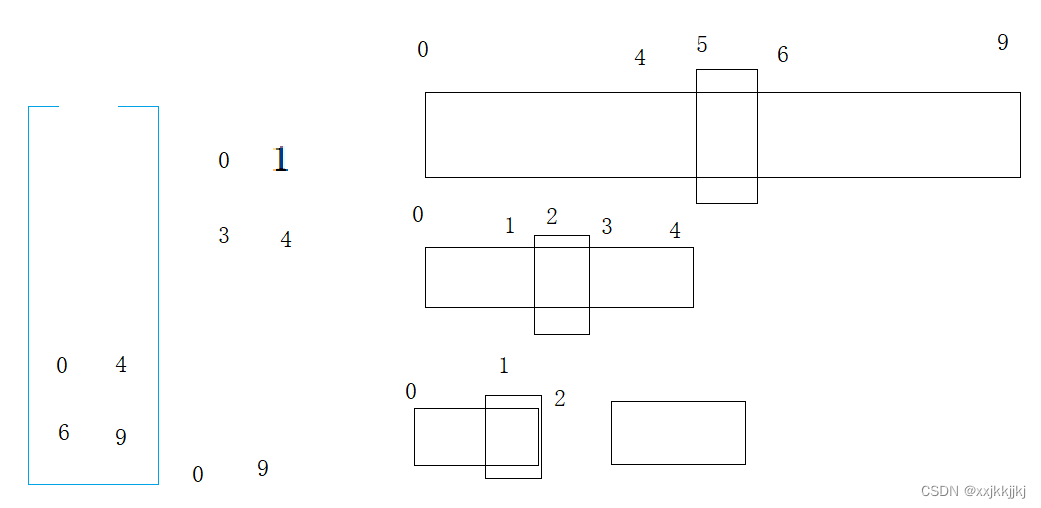
[0,9]出栈带入[0,4][6,9]继续出栈[0,4],选key单趟排,再入栈左右区间
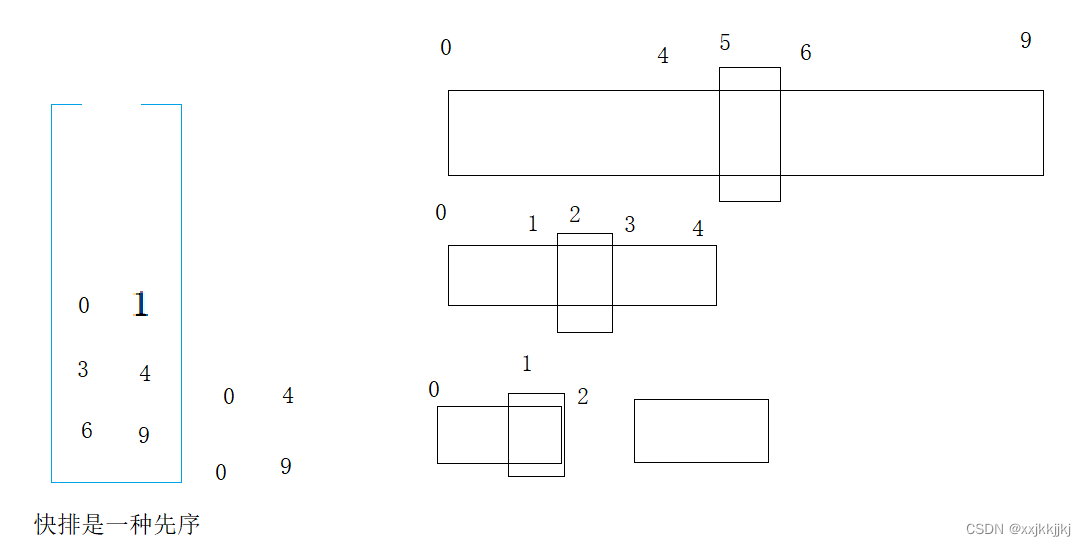
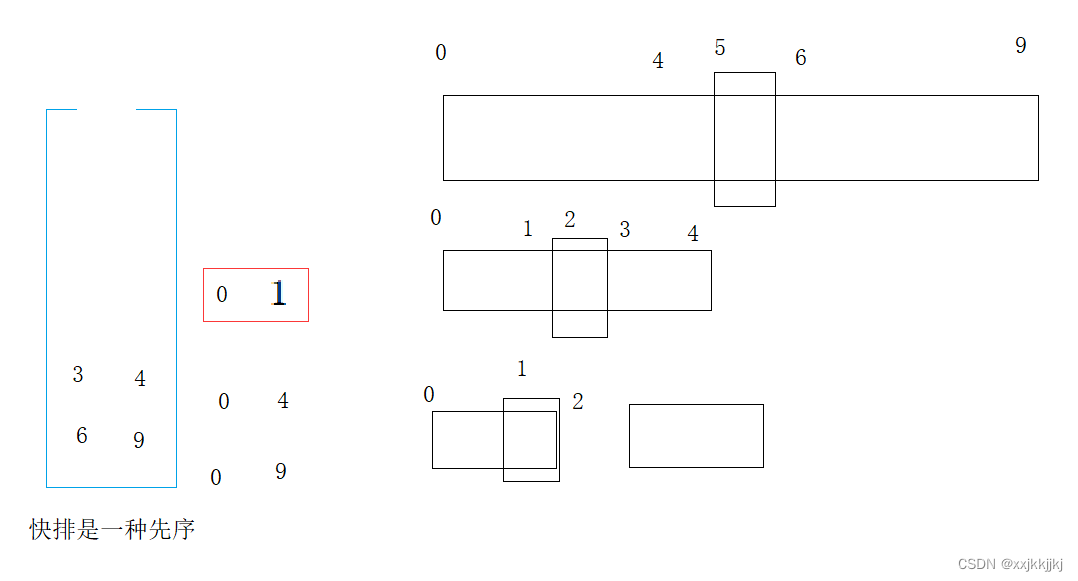

此时[0,1]出栈单趟选key后左右子区间不符合入栈条件,则继续出[3,4]
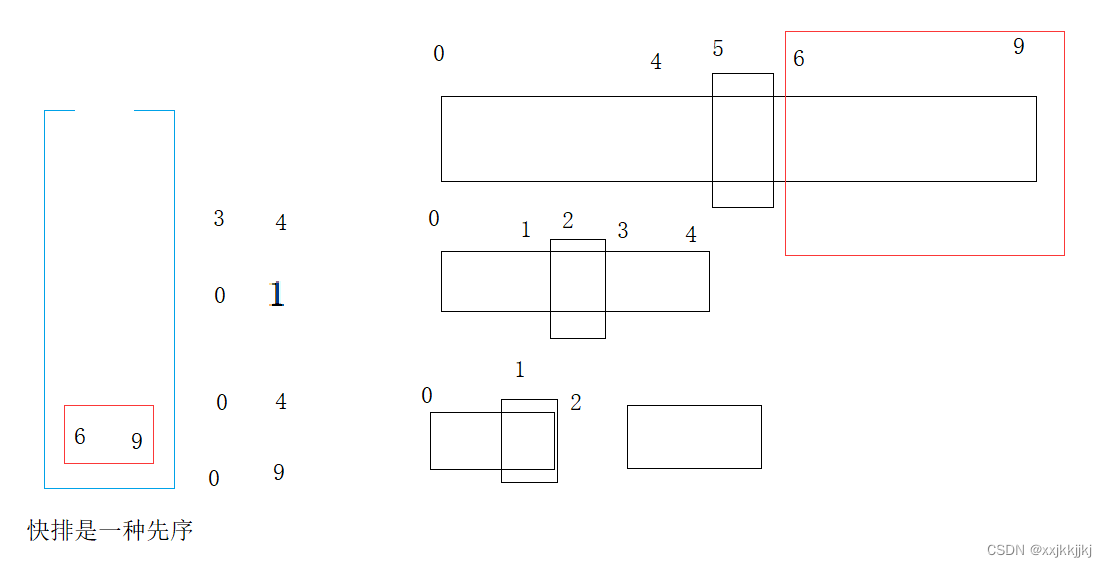
[3,4]处理完了就到了[6,9],再继续单趟,分左右区间…
如此循环下去,直到栈为空就结束
//非递归 效率和递归 无区别 只是解决了递归深度过高栈溢出
void QuickSortNonR(int* a, int left, int right)
{
ST st;
StackInit(&st);
StackPush(&st, right);
StackPush(&st, left);
while (!StackEmpty(&st))
{
int begin = StackTop(&st);
StackPop(&st);
int end = StackTop(&st);
StackPop(&st);
int keyi = PartSort3(a, begin, end);
//[begin, keyi-1] keyi [keyi+1, end]
if (keyi + 1 < end)
{
StackPush(&st, end);
StackPush(&st, keyi + 1);
}
if (begin < keyi-1)
{
StackPush(&st, keyi-1);
StackPush(&st, begin);
}
}
StackDestroy(&st);
}
归并排序
时间复杂度
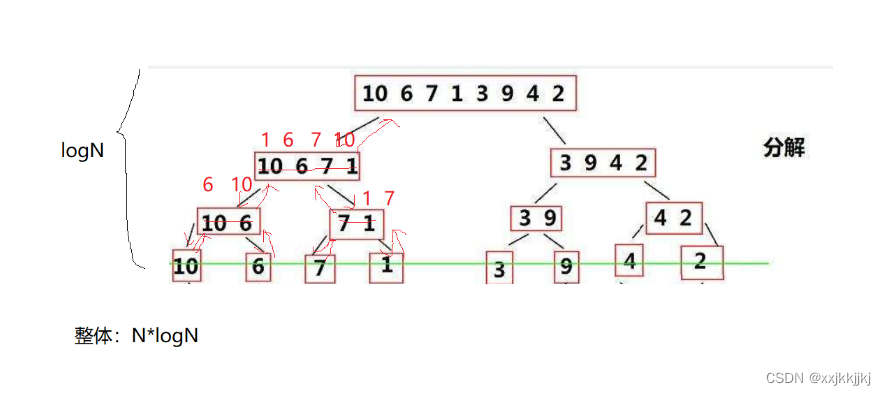
每层归并都是N,一共有logN层,就是O(NlogN)
思想
两个有序区间归并:
依次比较,小的尾插到新空间
前提是他们两个区间 都 有序
没序怎么办,平分变成子问题,继续让左区间有序,右区间有序
平分区间只有一个数,可以认为此时有序
开辟一个临时空间,将左区间1个数,右区间1个数归并,再拷贝回原数组
不开辟导致数据覆盖问题
左区间有序右区间有序再归并,这是后序
涉及开辟临时空间就需要在写一个子函数,不然每次递归调用自己都开辟空间
如何平分取中间下标也挺有意思
公式为 mid = (left + right) / 2。其中,left为左边界下标,right为右边界下标,mid为中间下标。
mid是左右边界的平均值,两个数加起来取个平均值嘛整形直接中间值,三数取中同理
结束条件是否有不存在的区间,还是只有一个数的情况呢?
根据递归图看出 只有[0,0][1,1]这种只有一个数的区间情况,并不存在不存在的区间
1.递归
递归过程-后序-先进入左子树,右子树,归并

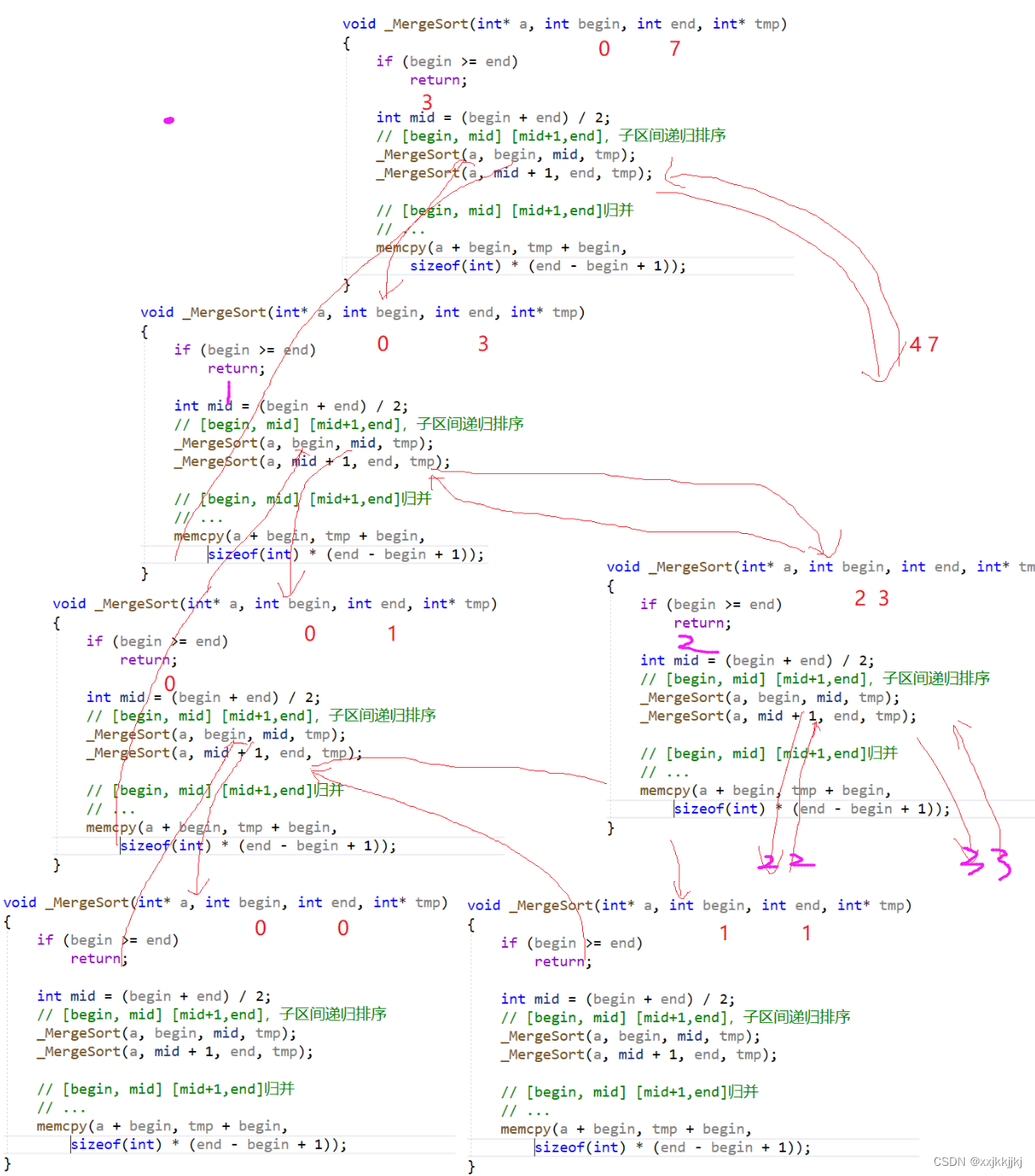
void _MergeSort(int* a, int left, int right,int* tmp)
{
if (left >= right)//不会有不存在的区间,这样写肯定没错
return;
int mid = (right + left) / 2;//左边界和右边界的平均值,整形直接中间值
//[left mid] [mid+1 right],子区间递归排序
_MergeSort(a, left, mid, tmp);
_MergeSort(a, mid+1, right, tmp);
int i = left;
int begin1 = left, end1 = mid;
int begin2 = mid + 1, end2 = right;
//归并
//[begin1 end1] [begin2 end2]//涉及left right 建议设置局部变量,不直接使用left right
while (begin1 <= end1 && begin2 <= end2)
{
if (a[begin1] < a[begin2])
{
tmp[i++] = a[begin1++];
}
else
{
tmp[i++] = a[begin2++];
}
}
while (begin1 <= end1)
{
tmp[i++] = a[begin1++];
}
while (begin2 <= end2)
{
tmp[i++] = a[begin2++];
}
memcpy(a+left,tmp+left,sizeof(int)*(right-left+1));
}
void MergeSort(int* a, int n)
{
int* tmp = (int*)malloc(sizeof(int) * n);
if (tmp == NULL)
{
perror("malloc fail");
return;
}
_MergeSort(a, 0, n - 1,tmp);
free(tmp);
}
注意i = left 和 memcpy(a+left,tmp+left,sizeof(int)*(right-left+1));
归并的区间在右边就不是从0 开始的,而是从left开始的,归并到tmp中也要归并到从left开始的位置,不可让i =0 会导致归并临时空间tmp都从0开始,调试时也不清晰。
2.非递归
归并排序 无法用栈保存区间 来搞非递归
因为归并后序 和快排栈辅助非递归的前序 顺序不一样,一开始的[0,9]上来就出栈了,归并排序后回到[0,9]你还得用[0,9]来归并,如果强行用栈来搞也不是不行,但是很困难,不建议